改进YOLOv3的道路小目标检测方法
2022-03-03罗建华白鑫宇
罗建华,黄 俊,白鑫宇
(重庆邮电大学 通信与信息工程学院,重庆 400065)
1 引 言
随着近年来计算机技术的快速发展,计算机视觉领域也得到了充分发展.作为计算机视觉的基本问题之一,目标检测在视频领域与图像领域发挥着重大作用,与人脸识别、人类行为分析,自动驾驶等技术息息相关.但通用的目标检测算法在检测小目标物体时由于分辨率较低、图像模糊等原因导致特征表达能力弱,提取特征不足,在实际应用中存在着漏检、误检及定位精确度不高的情况,严重影响目标检测精度,是目标检测领域待解决的一个重要问题[1].
传统的目标检测方法主要采用手动提取体征,然后通过滑窗的方式来进行检测.通常采用方向梯直方图(Histogram of Oriented Gradients,HOG)[2]、尺度不变特征变换(Scale-invariant Feature Transform,SIFT)[3]、可变形部件模型(Deformable Parts Model,DPM)[4]等方式提取物体特征.而真实场景下,常常由于遮挡,距离太远等因素导致难以提取特征,检测时常会出现漏检和误检等情况,无法满足实际需求.随着深度学习的兴起,其提取到的深度特征相比于传统的手工特征具有更强大的表征能力,基于深度学习的目标检测算法逐渐成为目标检测算法的主流.主流的目标检测算法主要分为两大类,第1类为两阶段目标检测算法(two stage),代表为R-CNN(region-convolution neural network)[5]、Fast-RCNN[6]、Faster-RCNN[7]等模型,这类算法将目标检测分为两步,首先利用滑动窗口在图片上获得候选区域,并且提取候选区域的特征向量,然后利用回归等方法对候选区域进行分类和位置预测,该类算法在一定程度上提升了目标检测的准确率.第2类为单阶段目标检测算法(one stage),代表为SSD(single shot multibox detector)[8]、YOLO(you only look once)[9]、YOLOv2[10]、YOLOv3[11],该类算法采取直接回归目标类别的方式,在一定程度上提升了目标检测的速度.
尽管目标检测算法在传统方式及深度学习方式上已经取得不错的成绩,但仍存在以下问题:对小目标检测的研究还不成熟,小目标分辨率低、像素占比少.小目标物体其自身占有固定的低分辨率,在目标检测过程中提取到的有效信息十分有限;卷积神经网络中深层感受野大,经过多次下采样后特征图不断减小,更难提取特征,导致小目标检测存在严重的物体漏检、误检等情况[12].
本文基于改进的YOLOv3模型,针对道路检测中小目标检测时效果不佳及漏检率较高等问题,首先对YOLOv3网络结构进行修改,将检测尺度扩展到4种尺度.并且利用DIOU损失代替YOLOv3算法中预测框平方损失,保持置信度交叉熵损失以及类别概率交叉熵损失函数不变.同时对目标边框应用K-means++算法进行维度聚类,选取更为合适的Anchor Box.在混合数据集上与其他目标检测算法进行对比试验,结果表明改进后的YOLOv3模型在不影响实时性的情况下,小目标的漏检率有了明显下降,平均精度有了明显的提升.
2 YOLOv3 模型
YOLOv3算法是基于YOLOv2算法的基础上,融合特征金字塔网络(feature pyramid network,FPN)[13]、残差网络(ResNet)[14]等方法提出来的单阶段目标检测算法,它将目标检测问题转换为回归问题,将图片输入后即可直接得到目标位置以及类别信息,实现了端到端的检测.YOLOv3主要由Darknet-53特征提取网络及预测网络两部分组成,Darknet-53包含5个残差块,为了避免网络层数的加深引起的梯度爆炸现象,其借鉴了残差网络的思想,使用了大量的跳跃连接保证避免梯度弥散的现象.Darknet-53与传统的CNN结构不同,不含有全连接层与池化层,为全卷积网络,其中包含众多1×1卷积层和3×3卷积层,共包含53个卷积层.在进行道路目标检测时,由于车辆和摄像头的距离有远有近,车辆在图片上呈现的大小也不等,最后一层输出的特征图的尺寸仅为13×13,是原始图像的1/32.网络层数越深,导致丢失的小物体的特征越多.在深度神经网络中,语义信息往往包含在深层次网络结构中;而浅层网络结构中具有更大的分辨率并保留了更多的位置信息.YOLOv3网络由大量DBL结构组成,其中包含卷积层,批量标准化层和激活函数.网络结构如图1所示.
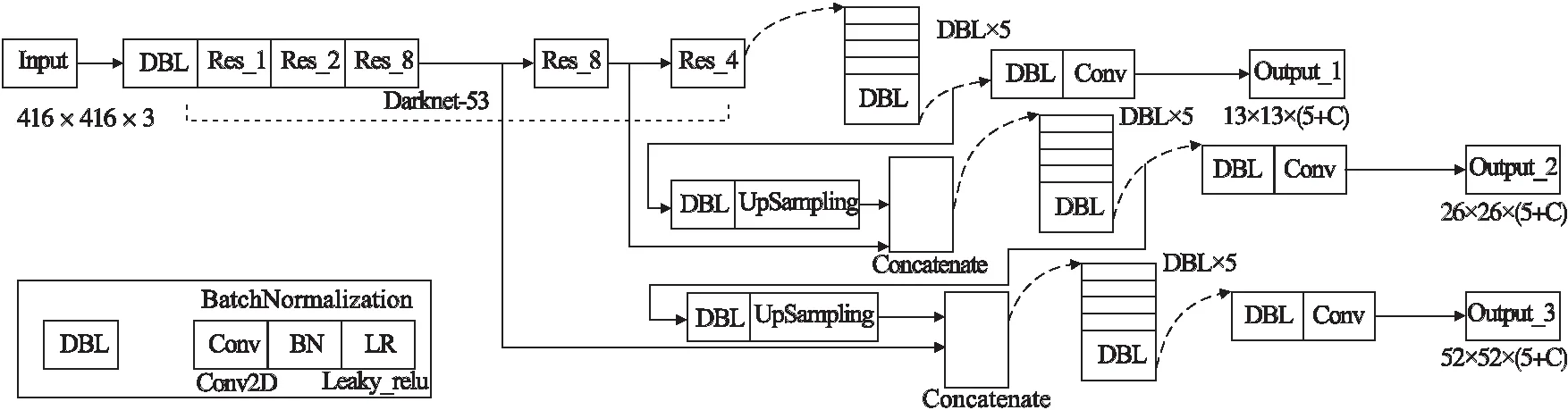
图1 YOLOv3网络结构Fig.1 YOLOv3 network structure
YOLOv3在预测方面,利用FPN选取主干网络上3个不同尺度的特征图进行预测,分别为13×13、26×26、52×52,每种规模可以预测3个目标边框.由于多次卷积后小物体的特征容易消失,因此52×52的网格用来检测小物体.对于一张图片,初始将其划分为K×K的网格,如果一个物体的中心落在某个单元格上,那么这个单元格就负责检测这个物体.最终特征图输出的张量大小为K×K×(3×(4+1+C)).其中包括了确定一个目标边框中所需要的4个中心点坐标、置信度得分以及物体类别.然后将置信度得分小于阈值的边框得分置为0,最后采用NMS(非极大值抑制)算法去除重复的边界框,保留得分最大的边界框为最后的预测框.
不同于YOLOv2算法,YOLOv3算法中选取9个Anchor Box作为人工选取的初始侯选边框.Anchor Box的大小由K-means聚类算法对数据集进行聚类得到.预测过程中,网络输出相对于Anchor Box的偏移量分别为tx,ty,tw,th,Anchor Box和Bounding Box的关系图如图2所示.
其中Bounding Box的坐标计算公式如式(1)所示:
bx=σ(tx)+cx
by=σ(ty)+cy
bw=pwetw
bh=pheth
(1)
式(1)中bx,by,bw,bh,分别为Bounding Box的中心坐标及框的宽高;cx,cy分别为当前网格坐标偏移量;pw,ph分别为对应Anchor Box的宽高,利用 sigmoid 函数将偏移量限制在当前网格中,利于收敛;tw和th代表预测框的宽高偏移量.

图2 Anchor Box与Bounding Box关系图Fig.2 Relationship between Anchor Box and Bounding Box
损失函数一般用来评价模型的预测值和真实值的误差,在网络学习速度的快慢及最终模型预测效果的好坏起着关键的作用.YOLOv3中loss由边界框损失、置信度损失及分类损失3部分组成,如式(2)所示:
(2)
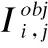

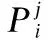
λcoord和λnoobj分别代表边界框损失和置信度损失的权重.
3 相关工作
3.1 数据集
针对本文所提出的问题,使用目前国际上最大的道路场景下计算机视觉数据集KITTI,其中包括了市区、乡村和高速公路等场景下采集的真实图像数据,每张图像中多达15辆车和30个行人,并且进行了不同程度的遮挡和截断[15].KITTI数据集中一共包含8个类别:car、van、truck、pedestrian、pedestrian(sitting)、cyclist、tram以及misc.从KITTI官方网站所下载来的数据集中,训练集中包含7481张有标注信息的图片.同时本文将car、van、truck、tram合并为car类,pedestrian(sitting)、cyclistc、pedestrian合并为pedestrian类,并且删除misc,即本文只需检测行人及车辆.
由于KITTI中行人样本相比于车辆样本较少,可能会导致过拟合问题,导致最终模型泛化能力差.本文在KITTI数据集的基础上,融合CQUPT-data,形成混合数据集.其中CQUPT-data为自制数据集,图片的获取来源为校园内手机摄像头实拍,总共拍摄了1000张图片,采取人工手动标注的方式进行标注.本文所采用的混合数据集中共包含8481张图片,其中7000张用于训练验证数据集,1481张图片用于测试数据集.数据集中部分图片如图3所示.

图3 数据集示例Fig.3 Example of data set
3.2 特征融合结构改进
本文提出的改进的YOLOv3模型在传入数据时选用宽、高均为416个像素点,整体像素为416×416的预处理图像.
YOLOv3利用FPN结构,利用3个不同的尺度的Anchor Box检测物体,针对大目标物体检测效果较佳,因其对浅层信息的提取不充分,在经过多次卷积后小目标物体特征信息丢失,在实际场景中对于小目标物体依旧存在漏检情况.
针对上述情况,在原有基础上新增一个检测尺度,为104×104的特征层,用于将浅层信息提取出来.将104×104的特征层与其他3个特征层进行融合,形成新的特征提取网络.使得浅层的特征具有较强的位置信息,深层的特征具有较强的语义信息,在降低小目标的漏检率的同时还增强定位的精度.
改进后的YOLOv3网络结构如图4所示,在YOLOv3网络中进行多次卷积操作,将尺寸为13×13的特征层经过上采样扩张成26×26的大小,同时与26×26的特征层进行融合,将融合的结果输入到下一特征层,直到4个检测尺度相融合.本文设计的4个检测尺度同时利用浅层高分辨率及深层高语义信息,且在并没有显式的增加网络复杂度的情况下,增强了网络结构的表征能力,改进后的YOLOv3网络结构能够更好适应小目标物体的检测.

图4 改进后YOLOv3网络结构Fig.4 Improved YOLOv3 network structure
3.3 边界框损失函数改进
IOU是目标检测中最常用的指标,可以用来评价输出框与真实框的距离,如公式(3)所示:
(3)
式(3)中A,B分别代表预测框和真实框.IOU具有尺度不变性,但如果两个框没有相交,如图5所示.
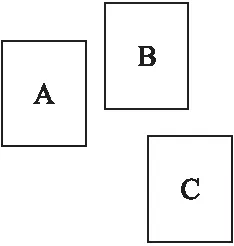
图5 IOU为0的情况Fig.5 Condition where IOU is 0
此时A框与B框,A框与C框的IOU都为0.但A框与B框的距离小于A框与C框的距离.此时IOU无法衡量两边界框的距离.YOLOv3算法在计算边界框损失时采或L2范数来计算位置回归损失,在评测时却采用IOU判断是否检测到目标.如果直接将IOU作为损失函数,此时loss=0,没有梯度回传,无法进行学习训练.
Rezatofighi等[16]提出了GIOU的思想,先计算两个框的最小闭包区域面积Ac,再计算出IOU,然后计算闭包区域中不属于两个框的区域占闭包区域的比重,最后利用IOU减去所述比重得到GIOU,如公式(4)所示:
(4)
与IOU类似,GIOU也是一种距离度量,并且GIOU是IOU的下界,在两个框无限重合的情况下,IOU=GIOU=1.与IOU只关注重叠区域不同,GIOU不仅关注重叠区域,还关注非重合区域,能够更好的反映两者的重合度.YOLOv3中边界框损失由L2范数评估,由于L2范数对物体的尺度比较敏感,SSD论文中直接采用distance losses,即以IOU代替边界框损失,但IOU无法直接优化没有重叠的Bounding Box.
GIOU针对两框不相交的情况,提出了一种解决思路.Zheng等人[17]指出,GIOU仍然存在局限性.GIOU实际上通过增大预测框的大小来使其与目标框重叠,如果两框是相交的,此时GIOU退化为了IOU,即GIOU仍然存在收敛速度慢,并且回归不准等问题.由此引出了DIOU的思想,与GIOU类似,DIOU在与目标框不重叠时,仍然可以为边界框提供移动方向.而DIOU可以直接最小化两个目标框的距离,因此比GIOU收敛的更快.
DIOU表达式如式(5)所示:
(5)
式(5)中,d=ρ2(b,bgt)表示预测框与实际框中心点之间的直线距离,c表示两者矩形闭包的对角线长度.
本文使用DIOUloss代替YOLOv3中边界框损失函数:
DIOUloss=1-DIOU
(6)
当两边界框DIOU越大时,DIOUloss越小,网络会朝着预测框与真实框重叠度较高的方向去优化.修改后的损失函数如式(7)所示:
(7)
为了验证改进后损失函数的有效性,使用改进后的损失函数代替原YOLOv3中的损失函数,Anchor Box大小保持不变.表1分别展示了使用IOU、GIOU、DIOU边界框损失函数在混合数据集上目标检测效果对比.从表1中可以看出,使用GIOU改进损失函数的YOLOv3算法在混合数据集上目标检测的平均精度为90.32%,相比于原始YOLOv3算法没有实质性的提升,这是由于检测过程中存在大量重叠的边界框,此时GIOU并没有进行实质性的优化.而使用DIOU改进损失函数的YOLOv3算法的平均精度有显著提升,达到了92.17%,检测速度为42.88f·s-1.

表1 YOLOv3改变损失函数后检测效果Table 1 YOLOv3 detects the effect after changing the loss function
3.4 Anchor Box聚类算法改进
YOLOv3中每一个输出尺度都采用3个不同的Anchor Box进行预测,Anchor Box尺寸是针对数据集而变化的,需要通过聚类方式得到.原始YOLOv3算法中的Anchor Box尺寸是根据COCO数据集聚类得到,由于COCO数据集中类别太多,且尺寸不一,因此聚类出的Anchor Box形状不一.本文仅仅针对车辆以及行人,需要重新对混合数据集进行聚类,选出更有代表性的Anchor Box.原始YOLOv3算法采用K-means[18]算法选取Anchor Box,但由于 K-means算法中对初始点的选取比较敏感,需要多次聚类才能得到结果,并且结果不一定是全局最优,只能保证局部最优.本文采取K-means++[19]算法,在选取初始点时进行改进,能够使得聚类中心之间距离足够远,并且将距离定义为:
d=1-GIOU(box,centroid)
(8)
K-means++算法步骤如下:
1)从数据集X中随机选取一个样本作为聚类中心Ci.
2)对于数据集X中的每一个样本点Xi,计算出它与最近聚类中心的距离D(Xi).其中:
D(Xi)=1-GIOU(Xi,Ci)
(9)
3)计算每个样本被选为下一个聚类中心的概率:
(10)
依此选出下一个聚类中心.
4)重复步骤2)和步骤3),直到K个聚类中心被选出.
5)利用上述步骤选定的K个聚类中心运行标准的K-means算法.
依据聚类中心选取9个Anchor Box,使用logistic回归函数对不同尺度上的每个Anchor Box进行置信度回归,预测出Bounding Box,然后根据置信度选出最合适的类别.
本文使用优化后的K-means++聚类算法,对混合数据集进行聚类分析.保持K值为9不变,经聚类算法迭代后选取的对应Anchor Box的宽高分别为(14,37)、(8,77)、(23,53)、(18,136)、(37,76)、(60,108)、(38,261)、(93,173)、(147,291).

表2 YOLOv3改变聚类算法后检测效果Table 2 YOLOv3 detects the effect after changing the clustering algorithm
对混合数据集分别使用不同的聚类算法进行聚类得到Anchor Box,其检测效果如表2所示.从表2中可以看出,使用改进K-means++的YOLOv3算法在混合数据集上的平均精度为91.23%,检测速度为43.23f·s-1.
4 实验结果分析
4.1 实验环境及参数设置
本次实验基于Linux平台通过Python语言实现,配置Ubuntu 18.04系统,应用深度学习框架Tensorflow1.13.2搭配Keras2.1.5搭建网络模型,硬件环境为Inter(R)Core(TM)i7-8750H CPU、16GB内存、NVIDIA GeForce GTX1080Ti 11G显存.数据集采用自制混合数据集.
对YOLOv3算法和改进的YOLOv3算法分别采用批梯度下降的方式进行训练,使用迁移学习的思想,加载darknet53.conv.74预训练权重进行训练.样本总共进行50000次迭代,其中批量大小设置为64,初始学习率设定为0.001,动量为0.95,权重衰减系数为0.0002.在网络迭代40000次和45000次时将学习率分别下降为0.0001和0.00001,使得模型尽快收敛,图6为训练过程中平均损失函数收敛曲线.

图6 avg_loss收敛曲线Fig.6 Avg_loss convergence curve
4.2 评价指标
本文使用均值平均精度(mAP)与每秒检测帧数(FPS)两项指标对模型进行评价,小目标漏检率通过对比YOLOv3算法前后的预测效果评估.其中精确率与召回率的定义为:
(11)
(12)
准确率表示某一类别预测目标中预测正确占总正确样本的比例,召回率表示预测目标正确占总预测样本的比例.以召回率为横坐标,准确率为纵坐标,绘制出P-R曲线,曲线下的面积即为AP.由于本文数据集中只包含两个样本,mAP计算如式(13)所示:
(13)
4.3 实验结果
选取6组城市道路图片,并且分别使用改进后的YOLOv3算法和原始YOLOv3算法进行检测.实验结果如图7所示.

图7 检测结果示意图Fig.7 Schematic diagram of detection results
在第1、2组实验中,由于距离较远,靠后的车辆像素较小,原始YOLOv3算法仅仅只能检测出常规物体,而漏掉了最后两辆车.得益于本文所提出的改进YOLOv3算法,本文算法成功的检测出了漏检的车辆.
在第3组实验中,由于树干的遮挡,并且右侧行人的像素较小,原始YOLOv3算法仅仅检测出正前方的车辆,而漏掉了右侧行人.而改进的YOLOv3可以正确定位到右侧行人,并且成功的检测出来该目标.表明本算法在进行小目标检测时具有良好的抗遮挡能力.
在第4、5组实验中,最后的车辆距离较远,原始YOLOv3算法只能检测出正前方的小轿车,并不能定位较远的目标.而本文算法在图像模糊和像素占比少的情况下,依旧能够成功检测出漏掉的小目标.
在第6组实验中,原始YOLOv3算法在检测过程中漏掉了右侧一个行人目标.而本文算法不仅成功检测出该行人,而且成功检测出最后的小车.
基于上述分析,原始YOLOv3算法对于小目标检测均存在漏检的情况,而本文所提出改进的YOLOv3算法不仅可以有效检测出遗漏的行人及车辆,并且在检测小目标时具有良好的抗遮挡能力.

表3 YOLOv3算法改进前后效果对比 Table 3 YOLOv3 algorithm before and after the improvement of the effect comparison
为了进一步验证本文提出方法的有效性,本文通过检测精度及召回率对改进的YOLOv3算法进行评价.表3中展示了YOLOv3算法在混合数据集上前后对比实验的结果.从表中可以看出,相比于原始YOLOv3算法,改进后的YOLOv3算法在混合数据集上的精度及召回率均有提升,对小物体检测的召回率提高了1.57%,达到90.05%,有效的降低了小物体的漏检率.
4.4 与其他目标检测算法对比试验
本文还将改进的YOLOv3算法与Faster-RCNN、SSD、YOLOv2,YOLOv3等目标检测算法进行对比,均采用自制混合数据集进行车辆与行人检测.同时选取mAP和检测速度两项指标对算法进行评估,为了进一步对目标检测算法进行评估,还引入F1-score指标.
(14)
F1-score是对精度和召回率的调和平均,可以更准确的反映模型的好坏.
表4中展示了其他目标检测算法与改进的YOLOv3算法对比实验结果.

表4 改进后算法与其他目标检测算法对比 Table 4 Comparison between the improved algorithm and other target monitoring algorithms
从表4中可以看出,YOLOv3的平均精度达到了92.82%,检测速度达到了42.87f·s-1,满足实时性的要求.同时,本文所提出的改进YOLOv3模型的F1-score排名第一,同时兼顾了高准确率与高召回率,优于其他对比试验.
5 结束语
针对传统目标检测算法在检测小目标物体时漏检率较高,检测精度低的问题.本文基于原始YOLOv3算法进行了改进,首先新增了一个检测尺度,用于降低小目标的漏检率,并且使用K-means++聚类算法对数据集重新进行聚类,得到合适的Anchor Box,提高了检测的平均精度和速度.然后使用DIOU损失替代边界框损失,提高了定位准确度及平均精度.将改进的YOLOv3算法在自制混合数据集上与原始YOLOv3算法进行对比实验.实验结果表明改进的YOLOv3能够有效的降低小目标的漏检率,并且在不影响检测速度的情况下,提高检测的平均精度.本实验检测的平均精度达到92.82%.
道路小目标检测在很多领域具有重要作用,例如交通安全,智能交通,无人驾驶等等,目前该研究依然具有一定的挑战性.本文主要通过改变特征融合结构、即新增一个检测尺度,从而更有利于小目标物体检测.但不同检测场景下的小目标信息各不相同,即多尺度融合方法的可迁移性较差,并不适合迁移学习,在某个具体场景进行小目标检测时,要选择合适的特征融合结构[22].随着深度学习的发展及硬件设备的更新,未来可以采用更具优势的YOLOv4网络来进行道路小目标检测[23],进一步提升算法的性能.
