WSN中能耗均衡的非均匀分簇路由算法
2022-03-01苗俊先赵一帆杨俊东丁洪伟
苗俊先,赵一帆,李 波,杨俊东,丁洪伟+
(1.云南大学 信息学院,云南 昆明 650500;2.云南民族大学 电气信息工程学院,云南 昆明 650500)
0 引 言
无线传感器网络(wireless sensor network,WSN)是由许多微型传感器节点通过自组网形成[1],主要用于环境参数的监测[2,3]。近些年,其广泛应用在农业、医疗、工业生产等领域[4,5]。节点能量的利用率取决于路由协议,因此,研究高效的路由协议已成为传感网面临的重大挑战[6]。
LEACH协议簇首选择、簇群规模和分布随机性强[7],LEACH-C协议簇首选择忽略位置因素,导致簇内通信能耗不均衡。文献[8]中以网格划分方式分簇,但是单簇首负载过大。石美红等[9]优化分簇方法和引入双簇首提升网络能耗均衡,但簇间以最小能耗选择中继节点,加快中继节点的死亡。文献[10]提出非均匀分簇的双簇首协议,缓解单簇首的通信压力,副簇首选择未考虑与主簇首的距离。黄利晓等在文献[11]中提出能耗均衡的LEACH改进协议,用间距、剩余能量和密度因子竞选簇首。文献[12]中EBRAA算法通过层次聚类提高分簇的均匀性。文献[10-12]3种算法簇首竞选时加权值固定不变,各因子的权值缺乏动态调整并且未考虑簇群规模对簇间能耗均衡的影响。
综上所述的路由协议未综合考虑簇首工作量、成簇规模、簇内和簇间通信传输等对能耗均衡的影响,且簇内节点能耗均衡性缺乏衡量标准,为此提出一种能耗均衡的非均匀分簇路由算法(a non-uniform clustering routing algorithm for balanced energy consumption,ANRB)。通过改进的K均值算法和成簇半径调整簇群规模实现非均匀分簇,并以双簇首减缓簇首通信压力;利用基尼系数对簇内节点能耗均衡性评估,选择更利于能耗均衡的节点为主簇首,使用动态权值调整副簇首竞选中各因子的影响;增加转发次数和节点数等因子优化中继节点选择,均衡簇间能量消耗。
1 系统模型
1.1 网络模型
WSN中各传感器节点以随机的方式抛撒在监测区域内,且位置不随时间发生变化,每个节点具有唯一的ID号和位置信息相对应[13];传感器节点可以感知自己的位置及剩余能量等信息,可以进行简单的信息处理,能够根据传输距离自动调整发射功率;Sink节点能量无限且处理数据能力强大;所有节点的初始能量、计算能力、数据传输能力等性能完全相同,当能量消耗殆尽时节点将自动退出网络系统。
1.2 能耗模型
在能耗计算方面提出的算法与LEACH协议都采用一阶无线电能耗模型[14],数据传输和融合能量消耗较大,其中数据传输又分为接收和发送两部分,假设相距为d的两节点间有lbit的数据需要传输,数据传输能耗计算公式为
(1)
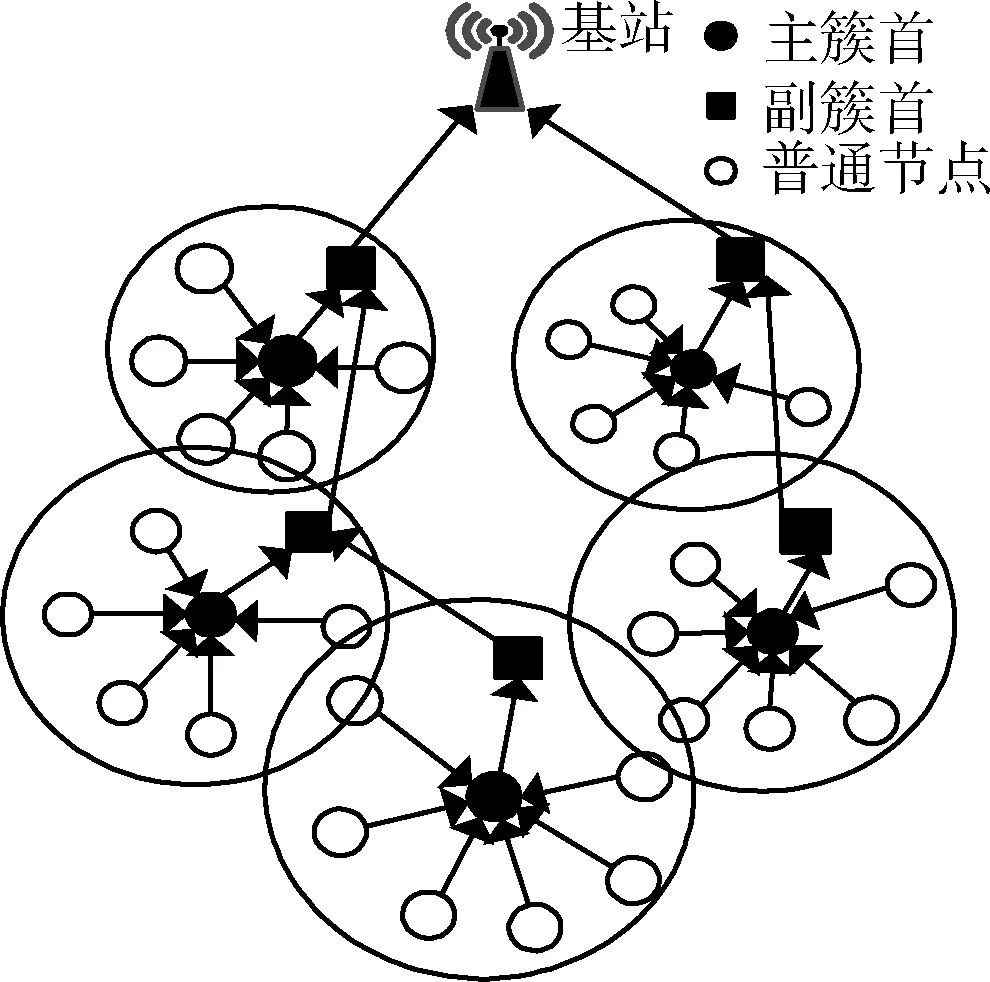
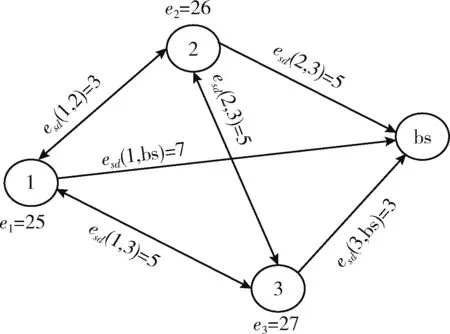
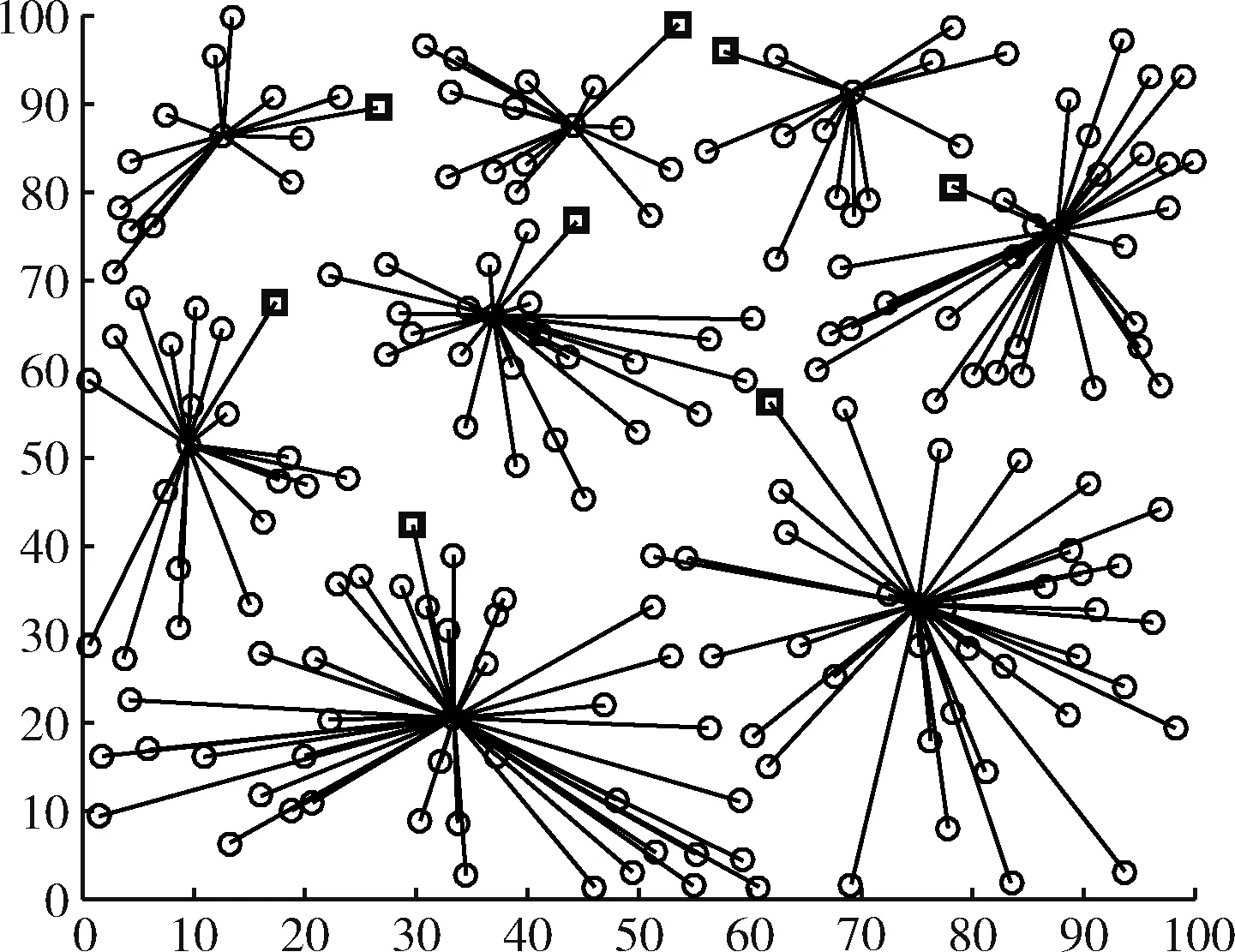
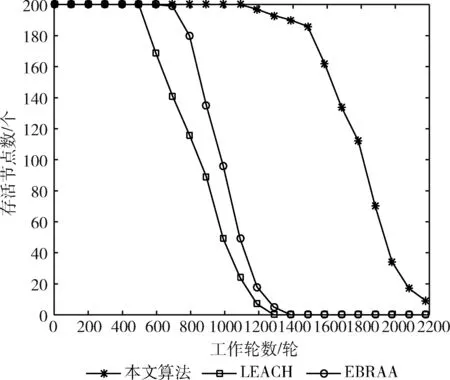
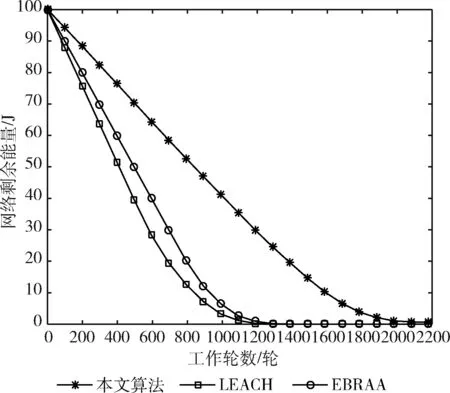
其中,d0为距离阈值常量,当d (2) 节点接收数据能耗只考虑与接收数据包的大小关系,其接收能量计算公式为 ERx(l)=lEelec (3) 考虑到簇间数据的相似性低,簇内数据相关性大且具有冗余性,因此在簇首接收完簇内数据后进行必要的数据融合,且假设融合后的数据量长度不变,融合1 bit数据能耗为Eda。 ANRB路由算法按照轮的思想运行工作,包括聚类分簇、双簇首竞选、簇间路由构建以及数据传输4个阶段。网络运行初始化时,各节点将自身的位置和能量信息向基站汇报,基站将接收到的信息汇总后采用改进的K均值算法进行聚类划分并将分簇结果和聚类中心广播出去,各簇首广播通知入簇消息,各节点根据收到广播信号的强弱入簇。从第二轮起,每一轮使用基尼系数对节点能耗均衡性预测,选取最有利簇内能耗均衡的节点担任主簇首,当本轮和上一轮的主簇首(临时簇首)相同时,无需进行广播,否则交换两个簇首的成员节点信息,广播告知其余节点。各节点竞选副簇首,主簇首依据簇内节点数目建立TDMA时隙表并通知簇内各节点。之后,进入簇间路由构建阶段,各个副簇首根据自身到基站的距离,进行单跳或者多跳的路径构建并形成自己的路由表,中继节点按照事先规定的原则选择。最后各簇按照规划的簇间路由进行数据传输,簇内各节点在对应的时隙表向主簇首发送数据,空闲时隙自动进入休眠状态,簇间数据传输采用载波监听多路访问,系统数据传输模型如图1所示。为了及时更新各节点的自身信息,在每一轮的最后各簇节点将剩余能量等信息以控制信息的形式告知主簇首,主簇首经过传输向基站进行汇总更新。 图1 系统传输模型 2.2.1 非均匀分簇 文献[12]中的AGNES协议以层次算法分簇,当数据量大时该算法运行复杂,同时该协议未考虑成簇规模,考虑到远离基站的节点需要寻找临近簇群转发数据,距离基站近的簇群应尽量减少簇内通信能耗,采用相对较小的规模来预留更多的能量作为其它簇群的数据转发能耗,同时远离基站的节点应减少分簇数目,以增大簇群规模减少向基站数据传输的次数。本文引入节点成簇竞争半径[15]以及邻居节点数,并通过非均匀分区的方式,调整簇群规模的大小,实现距离基站的簇群规模较小,远离基站的簇群规模较大,具体分簇过程如下: 步骤1 初始化:在监测区域(L×L)内,L=100,基站设置在(50,150),成簇竞争半径值R0=30, 各节点的竞争半径计算如式(4),Tr=10表示邻居节点半径,分簇聚类个数k=8。 以纵坐标为基准,将监测面积分成3个区域(节点纵坐标大于80,节点纵坐标小于40,节点纵坐标位于40和80之间),针对不同区域内的节点,其邻居节点半径有所不同,统计各节点的邻居节点数,具体分区以及邻居半径计算如式(5) (4) 其中,w∈(0,1) 表示距离权重因子,dmax,dmin表示各传感器节点到基站距离的最大和最小值。di是节点i到基站的距离,Ri表示节点i的成簇竞争半径,由式(4)可知其值会随距离基站的大小而变化 (5) yi表示节点i的纵坐标,Tr1,Tr2,Tr3表示3种不同区域内节点的邻居半径取值。结合式(4)和式(5)可知距离基站近的簇群邻居半径大,其邻居节点数多,靠近基站的节点在簇群中心初始化时被选中的概率增大,即在基站附近会有更多的簇群。 步骤2 优化初始中心:假设传感器网络中有N个节点,节点集合s={s1,s2,…,sN}, 每个节点都是二维坐标点即si=(xi,yi), 与传统的K均值算法随机产生k个初始中心不同,本文只随机产生一个初始中心,初始中心需要同时满足两个条件:所选节点的邻居节点数大于平均每个节点的邻居数,所选节点与所在区域内已有的初始中心节点i的距离要大于2Ri。节点的选择如下:每个非初始中心节点寻找与已知初始中心最短距离的平方,记为D2(i), 由式(6)计算所有节点最短距离的和记为sum以及各节点当选为初始中心的概率值,同时获取各节点的累加概率。依据轮盘法则和初始中心选择条件筛选合适的初始中心,这样不仅考虑节点的邻居节点数,也参照与现有初始中心的距离,既可以避免初始中心的边缘化又可以使选出的中心彼此分开,使得所选簇群在分布上具有均匀性,按照此方法依次将k个初始聚类中心选出记为c={z1,z2,…,zk} (6) (7) 在所有聚类中心更新完毕后,每个簇群计算各自的数据点与聚类中心距离的平方和,Jt是聚类目标函数,其代表所有簇群内距离平方的总和,目标函数计算公式为 (8) 步骤4 迭代计算:重复计算步骤3中式(7)和式(8),直到前后两次聚类目标函数差值满足 |Jt-Jt+1|≤ε或者迭代次数满足t=T时完成聚类。 步骤5 输出聚类结果:各聚类中心依据自身竞争半径选择本簇成员节点,不属于任何簇群的节点,按照就近原则加入相应的簇群。各簇群求取距离的平均值,以平均值作为本簇群的中心点,距离中心点最近的节点选择为本簇群的簇群中心。 2.2.2 双簇首竞选 在簇首选择方面,选择合理的簇首有利于减少网络的能耗,从而增加网络的稳定性。本文算法在能耗均衡方面和网络的生命周期上进一步改进,将经济学中衡量收入差距的基尼系数作为节点能耗均衡性优劣的标准,在此将节点的剩余能量代替个人收入,得到均衡节点能量差距大小的计算式(10) (9) (10) fitbv(i)=1-Gv(i) (11) 其中,nv表示簇群v内包含的节点个数,u表示该簇群内所有存活节点能量的平均值,ei,ej代表标号不同的节点当前剩余能量,Gv(i)表示节点i当选本簇主簇首时各节点剩余能量对应的基尼系数,且Gv(i)∈(0,1)。 将式(11)作为衡量簇内节点能量均衡性的指标,该值越大表示簇内节点能耗越均衡,反之簇内节点能耗均衡性差。 为了简化讨论和分析能耗预测的过程,假设簇群v中只有3个节点,各节点的位置关系以及初始能量如模型图2所示。暂且仅考虑数据传输能耗,定义每个节点接收数据的能耗为1个单位,esd(1,2)=3,esd(1,bs)=7代表节点1分别到节点2和基站的传输能耗值,ei代表节点运行到当前轮的剩余能量,实际ANUR算法在传输能耗和接收数据能耗计算时通过式(1)和式(3)进行,在图2中分别计算候选节点担任主簇首的剩余能量,代入式(10)、式(11),求取基尼系数最小的节点与临时主簇首进行对比,如果临时簇首的基尼系数就是最小值,则临时簇首当选为最终主簇首,否则临时簇首当选为普通节点。当节点1当选主簇首时u1=20.67, Δ1=2.67,fitbv(1)=0.935; 当节点2当选为主簇首时u2=21.33, Δ2=0.89,fitbv(2)=0.979; 当节点3当选主簇首时u3=21.33, Δ3=1.11,fitbv(3)=0.974, 各节点当选为主簇首的剩余能量分布如图3所示,计算并分析3个节点当选主簇首后对应的能耗均衡函数值fitbv, 节点2的能耗均衡函数值最大,同时从图3剩余能量值的柱形图可以看出,以节点2为主簇首得到的簇内节点剩余能量更均衡,从簇内节点的总能耗方面分析,节点1,2,3分别当选主簇首簇内节点的总能耗为16,14,14个单位值,选择2,3节点当选总能耗相同,但是节点2更有利于能耗均衡。由此可知能耗均衡函数可以反映簇内节点的均衡性,每一轮各簇在上一轮簇首的基础上按着上述方法对簇内节点进行能耗预测,选出均衡性更高的节点担任簇首。 图2 节点间的能量消耗 图3 节点当选簇首能耗分析(已添加横纵坐标及单位) 考虑到单簇首工作任务不仅包含数据的接收、融合,还包括发送、中继、成簇广播等,每一轮能量消耗较多,不利于网络能耗的均衡。在主簇首选择完成后,通过引入副簇首分担主簇首的发送和中继任务,减少主簇首的通信能耗。根据副簇首的功能,将综合考虑其与基站和主簇首的距离以及剩余能量进行选举,定义选举副簇首的公式如下 (12) γ=g/e(1-g),g=ei/e0 (13) 其中,di为节点到基站的距离,dmax,dmin分别表示簇内节点与基站相距距离的最大和最小值,节点和主簇首间的距离用ditoc表示,γ∈[0,1] 是关于能量比值g的函数,其值动态可变,节点的初始能量用e0表示,中继节点在转发数据时能量消耗大,因此从能量大于平均值的节点中选择副簇首。由式(12)可知,距离基站近,剩余能量高且相距主簇首近的节点f(i) 值较大,相比之下容易被选为副簇首。网络中节点的剩余能量会随运行时间不断减少,γ的值将逐渐变小,副簇首选择将加大能量因子在选举中的影响作用。 2.2.3 簇间路由的构建 (14) 在满足(14)条件下,将综合分析节点能量,传输距离,节点转发次数以及所在簇群节点数量等因素选择中继节点。因此,定义候选中继节点j的权重 (15) 其中,dij,djm,dim分别是节点i到中继节点j, 中继节点j到目的节点m, 节点i到目的节点m的距离。k(j),kav分别表示中继节点j的簇群成员数和平均每一簇群所包含的节点数,t(j) 为中继节点j运行到当前轮时累计转发i节点所在簇群数据的次数,tall是i节点的所有侯选节点总计转发来自i簇群数据的次数,其初始值为1,其值由每一轮统计累加得到,qi为加权因子,其和为1,根据网络环境将其值分别设置为q1=1/3,q2=1/3,q3=1/6,q4=1/6, 经分析可知,剩余能量充足,中继节点所在簇群成员节点数越多,承担转发次数少的副簇首越容易被选为i的中继节点,每一次中继都是按照最小权值原则选择,为了及时更新路由表信息,在每一轮数据传输的最后,各簇将剩余能量、中继次数等信息传输给基站,由基站以控制信息的形式反馈给各簇中的节点。 用Matlab2014a作为实验仿真平台,将ANRB算法、LEACH以及EBRAA算法3种算法分别运行2200轮,模拟在监测区域为100×100 m2的场景下,随机生成200个数据点作为传感器节点,实验仿真中用到的其它参数设置如下:节点收发数据能耗Eelec=50 nJ/bit, 节点融合能耗Eda=5 nJ/bit, 自由空间模型放大系数εfs=10 pJ/bit/m2, 多径衰落模型放大系数εamp=0.0013 pJ/bit/m4, 节点数据包长度l=4000 bit, 控制包长度l=200 bit,w=0.8, 节点的初始能量e0=0.5 J, 距离阈值d0=87.7 m。 图4是本文算法的仿真成簇图,簇中心为主簇首节点,每一簇的黑色方形为副簇首节点,其余黑色圆圈代表普通传感器节点,从成簇可以看出,靠近基站的簇群成簇规模小,反之簇群规模大,相比文献[12]中的EBRAA算法在簇群实现均匀分布的前提下,各簇群规模得到了调整。 图4 本文算法成簇 3.2.1 存活节点数 存活节点数指标是描述网络系统中节点数目随着网络运行时间变化的情况,各算法网络初始设置均相同,网络运行时间变化,系统中存活节点数越多则表示网络的完整性好即系统越稳定。3种不同算法的存活节点数和运行轮数仿真对比分析如图5所示,对各算法第一节点,第100节点以及第180个节点的死亡轮数进行统计得到图6所示的柱状图。我们定义各算法的第一死亡节点所对应的轮数作为网络的生命周期。从图5、图6综合分析可以得出ANRB协议的生命周期为1162轮,相比LEACH协议的生命周期明显延长649轮,与EBRAA算法相比也推迟470轮;分析一半数量的节点死亡情况,ANRB算法是1796轮,约为LEACH协议的2倍,是EBRAA算法的1.8倍;从80%的节点死亡分析,本文算法相当于另外两种算法的1.8倍。在运行结果的基础上表明本文算法能较好延长生命周期,均衡网络能耗,与EBRAA算法对比,本文算法优势是引入了能耗均衡评估函数,在每轮簇首竞选时减少了簇内通信能耗而且各节点能耗得到均衡,其次双簇首工作机制,也能减少单簇首通信负担,优化中继节点的选择使得簇间传输能耗得到均衡,这些改进均可以延长网络生命周期。 图5 存活节点数统计 图6 第1,100,180节点死亡统计 (已添加横纵坐标及单位) 3.2.2 网络能耗 网络的剩余能量是衡量系统稳定的一个重要指标,在同等条件下传感网中剩余能量的多少将直接决定着网络生存期的长短。图7仿真了3种算法网络剩余能量和运行轮数的关系对比图,分析可知ANRB协议的剩余能量总是比其余两种算法的剩余能量高,其主要原因是ANRB算法簇内以最大能耗均衡值为依据选举主簇首,用动态权值调整副簇首的选择,同时远离基站的簇群规模相比EBRAA算法要大,可以减少远距离传输的次数,从而节省能耗。LEACH协议的频繁分簇和随机分簇导致能耗消耗较多,与之对比本文算法在能耗上较少。 图7 网络剩余能量统计 3.2.3 吞吐量 吞吐量表现在监测者通过网络可接收监测区域信息量的多少,本文定义从网络开始运行到全部节点死亡基站在整个过程接收的数据包个数作为吞吐量。为了体现算法的稳定性,将各算法分别运行10次,并分别取平均值作为算法吞吐量的统计值,如图8所示,ANRB算法在吞吐量统计值上明显高于其它两种算法,分别是LEACH协议的1.66倍,EBRAA算法的1.42倍。这主要是因为本文算法能够较好均衡簇内和簇间的能耗,网络的生存时间上要比其余算法长,在相同的初始能量环境下,基站将会接收更多的数据包数。因此,ANRB算法具有很好的稳定性。 图8 网络吞吐量统计(已添加横纵坐标及单位) 本文算法为了均衡节点能耗,从成簇规模、簇首竞选、引入簇内能耗均衡函数,以及优化中继节点选择等几个方面进行能耗均衡的提升,副簇首节点担负数据的发送和中继,主簇首的通信负载得到减轻,簇首节点的能量得到均衡,并通过能耗均衡函数预测簇内能耗均衡性,簇间路由优化中继节点的选择,进一步考虑中继点的转发次数以及其所在簇群的节点数量,有效避免中继节点在每一轮运行中由于承担过多的转发次数而消耗较大的能量,从仿真结果分析可知ANRB算法的生命周期比LEACH和EBRAA协议要长,相比而言分别延长649轮和470轮,在吞吐量方面是LEACH协议的1.66倍,EBRAA协议的1.42倍,表明本文算法在能耗均衡上得到进一步提升。下一步将在最优跳数方向进行研究,在满足能耗均衡的基础上以最小跳数来减少数据传输延时。2 ANRB算法
2.1 算法思想
2.2 算法实现


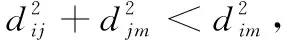
3 仿真与结果分析
3.1 仿真环境设置
3.2 仿真结果分析


4 结束语
