面向人脸检测MTCNN网络的加速硬件设计
2022-03-01孙庆斌
孙庆斌,何 虎
(清华大学 微电子学研究所,北京 100084)
0 引 言
在众多的人脸检测算法[1]中,MTCNN神经网络算法兼具准确率高和速度快的优点,并且MTCNN在小目标检测上很有优势,所以在当今工业界中应用十分广泛。但是,包括人流量较大的场所进行体温监测、过马路违章行人检测等在内的许多场景都需要检测的实时性,而在通用CPU上运行推理算法不能满足实时性的要求。目前,工业界中很多用通用GPU对神经网络推理进行加速,但是GPU能耗高、价格贵,尤其不适用于移动充电设备。专用神经网络硬件加速器能耗低、成本小,是加快神经网络推理速度最理想的选择。比如哈弗大学学者Bradley McDanel等基于FPGA设计了全硬件全栈优化的卷积加速器[2],Mateja Putic等设计了可以动态配置的DNN(deep neural network)加速器[3]。清华大学刘雷波实验室针对MTCNN神经网络做了专门优化的硬件并进行了流片[4]。密歇根大学的Cong Fu等基于FPGA ZYNQ 706开发板设计了针对MTCNN网络的加速器[5]。由于做MTCNN加速硬件的并不多,所以本文基于FPGA zcu102针对MTCNN人脸检测神经网络设计了专门优化卷积和全连接加速器。相对于前人,加速器接口部分采用了动态分块算法减小卷积分块后数据的重复量,极大减小了数据的传输时间。同时,本设计在能耗和路径延迟方面也做了很多优化。测试结果表明,本设计在没有DMA的情况下就能把MTCNN网络推理加速到ARM CPU的6倍以上。
1 MTCNN算法
MTCNN算法是一种多任务的人脸检测算法,可以同时进行人脸以及人脸关键点在图片中位置的检测。MTCNN是由三级网络:P-Net(proposal network)、R-Net(refine network)、O-Net(output network)级联而成,每个网络都有多个检测任务,包括人脸分类、边框回归和关键位置检测。如图1所示,P-Net之前对图片每次乘以缩放系数z,缩放到设置的最小尺寸,得到N张图片,形成图像金字塔。把所有放缩之后的图片输入P-Net,获得每个最小尺寸区域是人脸的概率和纠正值,利用非极大值抑制(NMS)算法合并重叠区域较多的候选框,最后结合纠正值把坐标回归到原图;O-Net之前把P-Net检测出的人脸区域从原图中截取出来,统一放缩成24*24,所有的图片输入R-Net,同样得到每个最小尺寸区域是人脸的概率以及纠正值。通过非极大值抑制以及坐标回归得到更少的接近正确结果的候选人脸坐标区域;O-Net与R-Net网络类似,把R-Net检测出区域从原图中截取出来输入O-Net,最终获得人脸区域候选框以及人脸上5个关键点的位置。
分析算法可知,P-Net具有通道少、图片数量多而且大小不同的特点,P-Net的用时大约占整个网络推理用时的80%。O-Net以及R-Net具有网络规模小,多张图片并行且图片大小相同的特点。所以,对应的加速器硬件设计的特点为:
(1)并行的通道数目少,同时图片分块送入加速器片上RAM时,并行计算的图像块数目多;
(2)计算核心的规模小,同时计算核心的数目多;
(3)图片并行计算时不需要彼此等待同步之后再进行下一步计算。
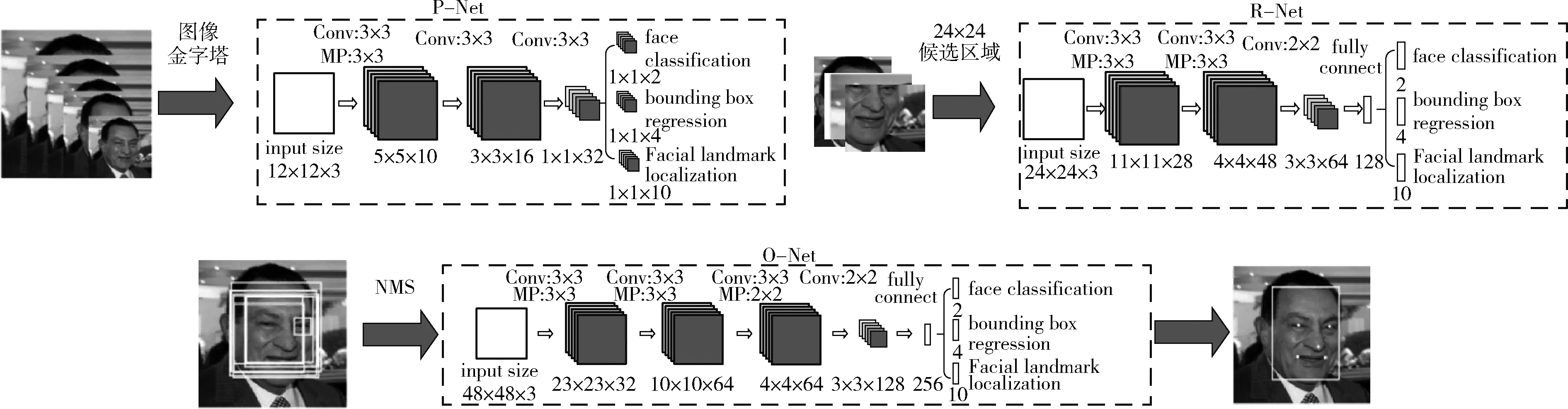
图1 MTCNN网络推理过程[6]
2 SoC软硬件设计
上一节分析了MTCNN算法以及其加速硬件的特点。所以,本设计基于以上分析针对MTCNN网络进行了软硬间协同的优化。其分别体现在嵌入式软件代码编写、加速器硬件架构以及软硬件接口的设计上。下面从这3个方面对整个加速器嵌入式系统进行介绍。
2.1 嵌入式软件
MTCNN网络包含了卷积、全连接、池化、非极大值抑制(NMS),坐标回归(bound box regression)等诸多算法,但是卷积、全连接占用了大部分推理时间,所以本设计仅把卷积、全连接用加速硬件实现,其它算法在ARM CPU上运行。在原始算法中,P-Net每张图片串行运算,而在本设计的嵌入式软件中,三级网络所有图片都是并行运算的。如此网络参数只需传输一次而且被多张图片使用而不用重复传输,大大增加参数的复用率减少了参数的传输时间。在PC的matlab程序中,图片缩放算法采用的Piotr Dollar工具箱中的resample函数。在调试嵌入式C语言程序时,需要把ARM上跑出来的中间数据和matlab跑出来的程序进行对比。对比发现错误之处需要使嵌入式软件预处理数据和matlab数据完全一致。因此,本设计的嵌入式软件移植了工具箱中的图片缩放算法,即用嵌入式C语言实现和matlab Piotr Dollar工具箱中放缩算法函数完全一致的运算过程。这也使得本设计的运行结果和原始matlab官方算法运行结果0误差。
2.2 加速器SoC
2.2.1 SoC整体架构
图2所示即为加速器SoC组成框架,FPGA的上位机把交叉编译好的程序从JTAG接口传输到PS端的DDR中[7]。神经网络参数和图像在PC中转换为二进制文件提前存放在开发板的SD卡中。当程序开始运行时,利用BSP包中的FATFS文件系统从SD卡中读取参数和图像到DDR中。当需要进行卷积和全连接计算时,ARM通过64位的AXI总线把中间数据、图像或者权重、prelu、bias参数从DDR传输到加速硬件的局部RAM中,待所有的一块图像计算完成后,ARM处理器把加速器的计算结果从局部RAM传输到DDR。当前DDR和加速器之间的数据传输完全由ARM处理器控制,ARM不能同时控制传入传出数据,如此传入数据就会浪费很多时间。以后也会有对应的解决方案加入。而在进行计算之前,ARM将会通过AXI-lite总线把每一层卷积以及全连接的配置信息传输到控制器中的寄存器中。控制器根据配置信息控制局部RAM输出到数据通路的数据以及数据通路流水线中的操作。
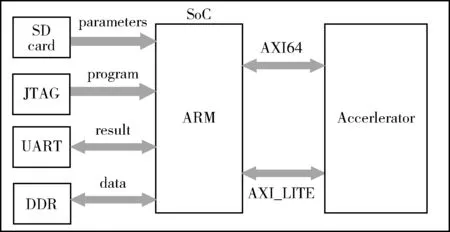
图2 加速器SoC组成框架
2.2.2 加速器计算通路
图3所示为加速器计算基本单元的结构图,每个基本单元中有4个乘法器可以并行计算图像的4个channel,然后加法树将结果累加起来。由于多数卷积层输入图像不止4个channel,计算出来的中间结果需要暂存在输出的RAM中,例如,卷积输入图像有16个channel,每次并行计算4个channel,计算核心循环4次才能把图像的所有channel累加起来,所以在没有计算完所有channel之前,channel累加的中间结果都存储在输出RAM中。因此在加法树之后需要累加单元将之前暂存的中间结果累加起来。卷积和全连接共用同一个计算通路,而不用再添加额外的计算资源。若是卷积计算,由于同一个视野中的像素的计算结果要在很多个周期之后才需要,中间计算结果也要存放在输出的RAM中,所以累加单元的累加数据来自于输出的RAM;若是全连接计算,由于其相当于只有一个视野,同一个视野中一个像素的中间结果在下一个周期要立刻累加进下一个像素点中,全连接的同一个视野中像素的计算中间结果不再存储在输出的RAM中,而是立刻返回来作为下一时刻累加单元的累计数据。所以全连接计算中累加数据来自于累加单元的输出。一个计算核心包含4组基本电路,4组基本电路之间共享输入图像数据,但是权重、prelu和bias这些参数来自不同kernel的同一个位置,即4组电路同时并行运算4个kernel的图形的同一个视野位置。综上可知,一个计算核心包含16个乘法器、20个加法器、4个激活单元,乘法器用于权重和图像的相乘、加法器用于通道之间的累加以及bias参数的累加、激活单元中有乘法器,如果输入数据小于0则与prelu参数相乘,如果输入数据大于0或者不需要进行prelu激活计算则直接乘1。
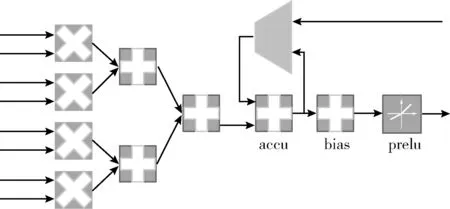
图3 计算基本单元
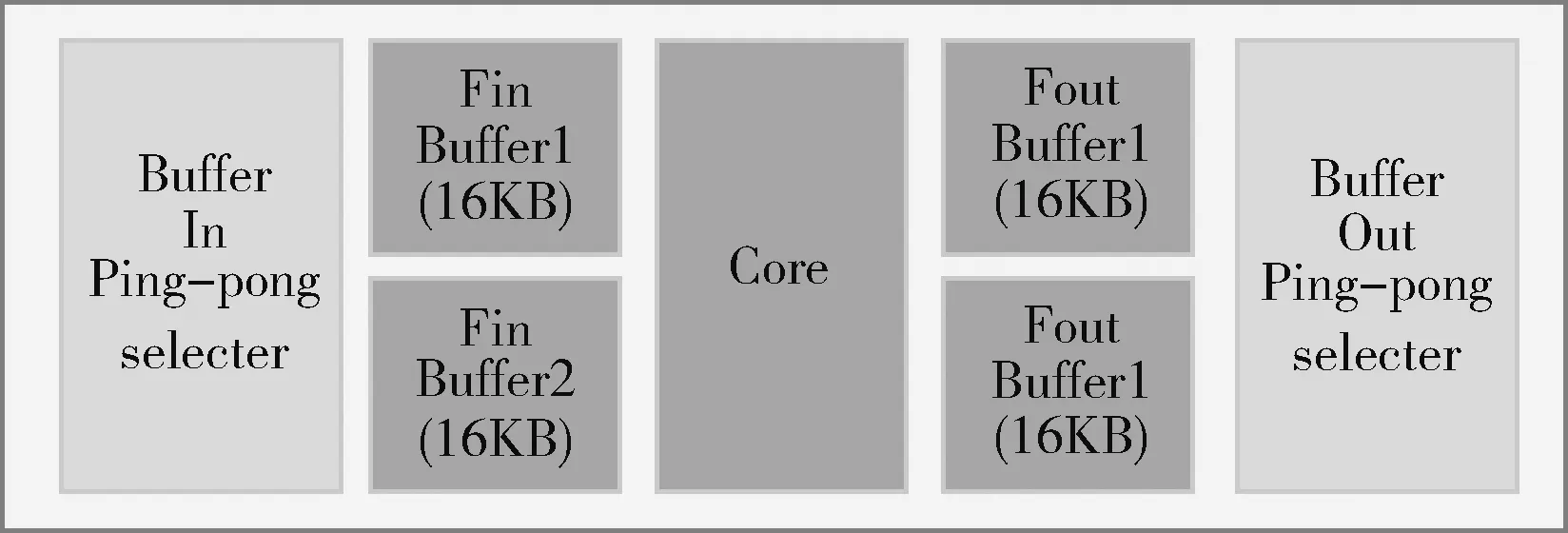
图4 数据通路组成
图4说明了整个数据通路的结构组成,除了4组基本计算单元之外,还有两个ping-pong的存放输入图像的RAM,之所以用ping-pong的RAM,是因为在一个输入图像RAM准备好数据之后,计算核心开始计算,ping-pong RAM中的另一个RAM可以同时传输数据,如此计算时间和传输分块图像数据的时间两者中时间长的操作便把时间短的操作的时间覆盖,节约了很多时间。两个存放中间结果及最终结果的RAM,目前在ARM从存放中间结果RAM获取计算结果的操作和计算并不同时进行,在加入DMA之后可以实现并行操作。两个接受控制器信号,选择ping-pong RAM的模块可以根据控制器的控制信号决定输入图像数据输入到哪个RAM之中以及计算结果从哪个RAM获取并对相应的RAM进行选通。
2.2.3 加速器架构
如图5所示,加速器的整体架构是参照英伟达GPU GeForce 8800的架构来进行设计,加速器含有一个控制模块控制数据流以及数据通路中的算子操作。加速器的数据通路中有4个group,对应英伟达统一计算设备架构CUDA中的block。每个group中有5个计算核心。每个计算核心都含有局部的存储输入图像和输出结果的RAM。4个group共享存储weight、激活以及bias参数的RAM。综上所述,整个加速器含有20个核、一个控制器、3个共享的RAM。

图5 加速器架构
其中,加速器的控制器和数据通路都针对MTCNN做了特殊的优化。①支持输入图像的动态分块:输入图像块的大小不再固定,而作为配置信息由AXI-lite总线传入控制器,因此支持输入图像大小的改变;②能耗优化,每次计算输入图像的总块数作为配置信息传入控制器,控制器把闲置的group关闭,以节约能耗;③共享存储器的数据在group之间进行广播,在group内部脉动传输[8,9],参数在核之间经过一级寄存以减小RAM 的扇出,提高频率。
加速器中的控制器负责控制所有核的运算,其接受ARM通过AXI lite总线传输过来的控制信息。这些控制信息包括:权重weight的大小、通道数目、kernel的数目,传送入加速器的图像块的长宽以及通道数,本次计算传入的总的图像的块数,图像数据是否传输完成以及计算结果是否全部取完的握手信号,20个计算核心各自计算完成一次之后以及整层卷积或者全连接计算完成之后的同步复位信号。同时,为了便于数据的复用以及数据的并行计算,加速器中的卷积和全连接的计算顺序和原算法的计算顺序有所差异[10]。
2.3 软硬件接口
由于加速器中的存储图像的局部RAM的容量是有限的,所以图像要分块传入。同时,要把分块后的图像和参数按照加速器的计算方式重新排列。对于weight参数,PC中的排列顺序为长、宽、channel、kernel,重新之后的weight参数的排列顺序为4个channel、4个kernel、长、宽、分块后channel数目、分块后kernel数目。同样,图像分块后也需要按照4个channel、分块后长度、分块宽度、分块后通道数的顺序重新排列。其中,分块前通道如果不是4的倍数,则用0补足;kernel的数目如果不是4的倍数,则用0补足。
软硬件接口函数的功能主要包括:对参数和图像分块、重新排序、发送控制信息、发送图像和权重数据、取回加速器运算结果。接口中包含了针对MTCNN所做的特殊优化。第一,完全自主设计了对卷积输入图像的动态分块算法。接口函数中,分块的图像的大小由存放输入图像和运算结果的RAM的大小以及所有待测图像的最长边的最小值来确定最大的分块,极大减小了重复传输数据量,节约了数据的传输时间。如式(1)所示
a=min(max(width,height)image0,…, max(width,height)imagei)
(1)
计算出待测图像最长边的最小值,式(2)和式(3)计算出输入和输出RAM容量允许的最大分块尺寸
(2)
(3)
如式(4)所示求三者的最小值即可得到该层卷积计算的最大尺寸
tile_size=min(a,b,c)
(4)
在进行卷积运算时,同样尺寸的图像分两块传入比分3块传入加速器,重复传输的数据要少很多。第二,由于级联的3个网络中有多个图像并行传入,P-Net输入的图像大小不等,R-Net和O-Net输入的图像大小相等。如果每个图像独立并行运算,总需要彼此等待同步之后才能进入下一步运算,耗费大量的时间。本设计接口函数使用了图像间混合运算的方法。如图6所示,图像分块之后,把每个图像的分块数目,按照顺序存放进图像池;计算完成之后,从输出图像池按照之前的顺序,按照相应的数目分配回去,这样便不再用处理图像并行计算的问题。即把图像并行计算转化成图像块并行计算的问题。控制器和数据通路不必再得知图像块属于哪个图像,只需获取其进行卷积运算还是全连接运算的配置信息即可。
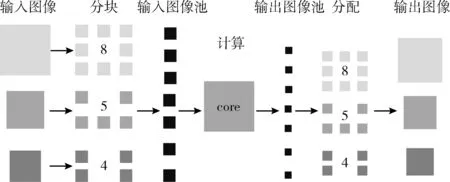
图6 图像间混合计算
3 加速器验证和性能分析
3.1 加速器设计和验证
整个加速器的设计全部在Xilinx Vivado开发软件中进行,编写Verilog在Vivado中用进行了全面的仿真功能验证。首先,写硬件描述语言Verilog进行加速器中计算基本单元和控制器的设计。计算基本单元中的乘法器和加法器调用Xilinx vivado设计工具中的IP并调用FPGA的BSP资源。控制器全部用HDL实现。产生相应位数的随机数进行计算核心单元的验证。给定控制器设定好的控制信号,通过检验控制器输出信号是否符合相应的功能设计来验证控制器的功能。控制器和数据通路功能验证正确之后,将MTCNN算法全部用嵌入式C语言实现,与matlab程序跑出来的结果完全一致;然后编写软硬件接口函数,接口函数中调用了对图像和参数排序的子函数。调式排序子函数时,把排序前后的数据通过串口打印出来,把打印出来的数据复制到EXCEL表格之中,把排序之后的数据对应到其排序之前的相应位置看是否正确。接口函数中卷积和全连接的排序子函数是不同的,通过参数对进行全连接或者卷积计算进行控制,同时进行相对应得排序。接口函数中还有接受发送数据的子涵数,可以串口打印出发送的数据和matlab程序的数据进行对比调试。整个嵌入式C语言程序首先从SD卡中读取参数和数据,三级网络之前都要用ARM对图像进行截取和缩小等预处理。预处理中的截取和缩小图片的运算过程完全和matlab程序运算过程一致。用验证过的软硬件接口函数替换嵌入式C语言的卷积和全连接函数,此时整个的MTCNN算法便可以在ARM和加速器上进行软硬件的协同验证了。
在软硬件协同验证时,把比特流烧写进FPGA,首先用串口打印的方式调试接口函数。此时可以把打印出的加速器的计算结果和matlab的计算结果进行对比,如果返回结果不对则可以用Vivado开发工具中的ILA IP实时观测卷积和全连接在加速器上运行时的计算通路和控制器的信号波形,对每个控制信号、其中一个核的数据以及接受到的控制信号进行观测,进还原得子函数进行验证,在接口函数中要通过排序还原函数把行硬件的debug,直到最后从加速器取回的计算结果和matlab程序的计算结果完全一致。计算结果完全一致以后还要对排序计算结果排序还原成MTCNN原算法计算的排列顺序即宽、高、通道的顺序。此时,整个加速器已经完全能有正常的功能输出完全正确的数据了。之后,把MTCNN嵌入式C语言程序中的卷积核全连接函数全部换成接口函数,用串口打印出识别出的人脸框的坐标和人脸关键点的坐标。把串口打印出加速器的运行的结果和PC运行的结果进行对比,结果正确。如图7所示,图片是PC中matlab运行结果,第一张图片中框出一张人脸,并标出人脸中关键点位置。右侧文字部分是ARM和加速器运行串口打印的结果,可以看到检测到一张人脸,并得到人脸框和人脸关键点在图中的坐标位置。第二张图片有两张人脸,matlab运行结果框出两张人脸并对人脸关键点进行标记。同样,ARM串口打印出的结果显示有两张人脸,并给出了两张人脸的关键点的坐标。而且串口打印出的数据和matlab跑出的数据完全一致,误差为0。

图7 运行结果对比
3.2 加速器性能分析
在时钟为100 MHz时,对整个SoC工程布局布线,成功生成比特流,表1显示了整个加速器SoC的资源利用情况。从图中可以看出,资源利用在合理的范围内。之后,对全部由嵌入式C语言实现的MTCNN程序和ARM以及加速器实现的程序在各种优化条件下测量性能。用ARM中的Timer对识别一张具有两张人脸的图片进行计时。整个代码运行在Xilinx ZCU102开发平台上。ARM的处理器为Cortex-A53,频率为1.2 GHz,加速器为100 MHz。表2显示了不同平台下检测此图片的时间、对应的能耗以及该平台的工作贫频率。经过测试,ARM和加速器运行的程序比ARM O2下快6倍,比ARM O0条件下快104倍。其中加速器的功耗也是ARM O2优化的将近1/4。另外,在测试过程中也对传输数据、获取结果以及计算的时间单独做了分析,以了解当前加速器瓶颈所在,利于进一步的优化。下面以20块18*18*4的图像块的传输、计算以及20块16*16*12的输出的获取时间为例,分析传输和计算时间以解决瓶颈问题。如图8所示,20块18*18*4的图像的计算时间是98 μs,传入总时间为520 μs,20块16*16*12的计算结果传回DDR的时间为6720 μs。计算可以得出总的计算量为4 423 680个操作,用时一共98 μs。计算峰值为45 GOPS,计算性能良好。从图中可以看出,计算和核心在进行计算的同时,ARM给输入图像ping-pong RAM中的未用RAM传输数据,传输计算并行,节约了时间。但是由于DDR中数据的传输全部用ARM控制,传输获取数据便不能并行起来。由于,计算时间被掩盖,目前来看加速器耗费的时间全部用来传输数据。综合以上得出,目前的性能的限制在于图像的传入和计算结果取出时间。此后,考虑加入scatter-gather模式的DMA,这种模式的DMA在对所有的核心传输图像块时,即使地址不连续也可以只配置一次而把所有的数据传输完,这样ARM就可以把传输数据的任务分担给DMA,多通道DMA也可以实现传入图像和获取计算结果同时进行,如此将大大提高操作的并行度减少传输数据的成本提高本设计的性能。同时目前的MTCNN网络没有经过量化,即仍然使用浮点数进行运算,如此传输数据的量大大增加,而且浮点计算单元占用的资源多延时长,支持的工作频率低。此后将在尽可能小的损失精度的情况下把MTCNN网络参数量化为整型,传输数据量将成倍减小,浮点乘法和加法转化为int型乘法和加法也将大大减少资源的利用,有利于加速器在相同的资源下增大规模,同时加法器和乘法器的路径延迟也将大大缩小,将成倍提高加速器的时钟频率[11]。如此加速器得性能将成倍得提升。
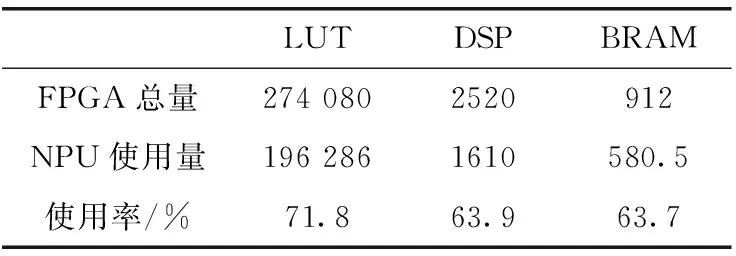
表1 SoC系统资源利用率
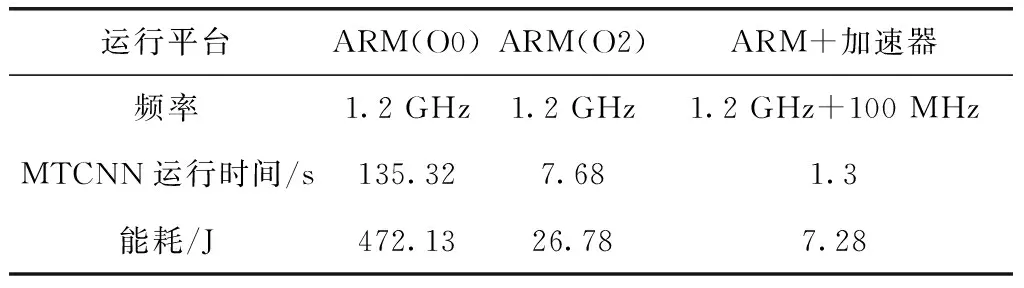
表2 不同平台性能对比

图8 传输和计算时间对比
4 结束语
本设计针对MTCNN人脸检测神经网络做了专门优化的基于Xilinx FPGA ZCU102平台的硬件加速器,加速器采用了类似GPU的多核架构,硬件上采用多而小的这种众核的架构,极度适应了MTCNN网络卷积和全连接输入图像多通道少的特点。软硬件接口中采用动态分块算法、图像间混合计算,group内参数脉动传输、闲置组可关断等多种策略优化加速器的延时、能耗,解决了由于MTCNN网络图像多,如果串行运算需要多次传输参数以及即使并行运算也需要彼此同步的问题,尤其图详间混合运算使得运算没有了图像的概念而只有图像块的概念。经过设计仿真验证等步骤成功得出和单纯ARM运行相同的结果,由于移植matlab工具箱中的算法到嵌入式ARM平台上,算法运算过程与matlab完全一致,使得最终结果误差为0。经过性能测试评估,本加速硬件峰值计算性能达到45 GOPS。能耗相比ARM运行大大降低。此后,本设计将加入scatter-gather模式的DMA增大操作的并行度,优化数据传输时间。量化网络模型参数,由于整形计算模块占用资源大大减少,因此也可以增大计算核心规模[12],并把MTCNN算法中比较占用时间的池化和图片放缩算法用硬件实现。优化结束之后将加入摄像头、显示器构建嵌入式系统,方便此设计直观地进行验证以及此后的商业落地。
