基于模式挖掘的智能楼宇能源消耗量预测方法
2022-02-27陈景琪丁凌
陈景琪,丁凌
(国网上海市电力公司,上海 200122)
能源是人类生产活动的物质基础,也是经济发展与国防安全的战略物资。随着经济的高速发展与人口的爆炸式增长,各国能源消耗量大幅增加,其中建筑能耗在总能耗中占据较大比例,是温室气体排放的主要来源之一。现阶段,全球资源紧缺,能耗控制已经成为每个国家关注的焦点。智能楼宇是一些特大城市建筑的主要方式,也是节能改造优化的重点目标。为了顺利开展节能工作,必须将历史能耗数据作为基础,对智能楼宇能耗进行准确预测。
文献[1]提出基于回归分析的能耗预测模型。以较为寒冷区域的建筑为例,通过单因素敏感性分析挑选出10 个关键设计参数,再利用正交试验对能量需求进行仿真计算。根据计算结果作多重线性回归,构建多因素耦合作用下的能耗预测模型。最后采用Java Script 脚本语言开发了Doep 软件,验证了此预测模型的可靠性。文献[2]在建筑信息模型(Building Information Modeling,BIM)环境下对建筑能耗进行预测。将用户行为划分为移动行为与用能行为,利用事件机制分析移动行为,通过BIM 模型与Agent 技术构建基于事件的用户移动行为与用能行为模型。
但是上述两种预测方式未考虑到历史数据中蕴藏的价值,导致预测结果与实际偏差较大。海量的能耗数据并未发挥出应有的作用,而是带来了“数据灾难”。为此,该文利用模式挖掘方法对智能楼宇能源消耗量进行预测。
1 智能楼宇集群数学模型构建
1.1 智能楼宇系统结构
智能楼宇系统结构如图1 所示,主要由楼宇、可再生能源发电系统[3]、控制器与通信链路[4]组成。

图1 智能楼宇系统结构图
1.2 楼宇集群建模
结合抽象化思想,根据微观到宏观的方式,对单个楼宇和楼宇群进行建模。
楼宇制热区域中的热阻与热熔组成了热熔热阻(Resistance Capacitance,RC)网络,使楼宇存在一定储热与传热能力。在此网络中一般存在室内节点与墙体节点,不同节点之间利用热阻进行连接,同时采用热熔接地。该网络表示的是单独制热区域,将这些区域组合在一起即为楼宇集群,每个智能楼宇屋顶都安装一个发电系统。所以楼宇的制热区域结构相似,且在同样外部参数下,每个制热区的功率相同。再通过HVAC 系统调整送风温度,实现集中控制。
楼宇墙体的热平衡约束条件[5-7]为:

制热区域平衡等式约束表示为:

将式(1)与(2)变换为下述状态方程:
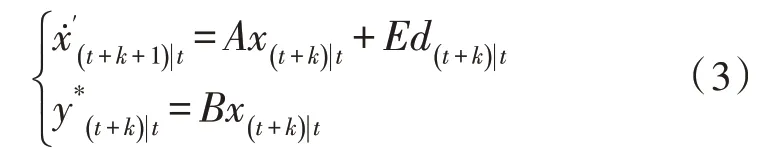

则智能楼宇集群的数学模型表示为:

2 基于模式挖掘的楼宇能耗量预测
2.1 能耗历史数据模式挖掘
序列模式挖掘即为寻找数据库中数据之间的先后顺序。
以某阶段楼宇能耗历史数据库S(min_sup=2)为例,利用序列模式挖掘算法对其进行挖掘,具体步骤如下:
步骤一:寻找长度是1 的序列模式。对数据库进行初始扫描,挑选出全部长度是1 的频繁序列,获得频繁序列模式。因为的支持度低于最小支持度min_sup,因此属于非频繁项,必须删除。
步骤二:将长度是1 的频繁项当作X轴与Y轴,确立6×6 的三角矩阵S。
步骤三:从矩阵S中找出全部支持度大于或等于2 的序列模式,建立与其相对应的投影数据库,对频繁序列的子集进行递归挖掘。
步骤四:重复操作步骤二与步骤三,找出全部长度的频繁序列[10-12]。
步骤五:针对全部挖掘得出的频繁项集,对其序列模式值进行计算,同时按照从大到小的顺序排序,若出现模式值相同的情况,则根据字母表顺序排序,得出历史能耗序列数据库中任意一项权重值,其中权重值越高的数据越具有挖掘价值。
2.2 能源消耗量预测模型构建
模糊模型是一种结构型非线性模型[13],具有较强的适应性与泛化能力。而模糊集合的本质是将经典集合中的绝对隶属关系进行模糊化处理。。

模糊控制因素包含i′时刻第j′个预测结果的误差与预测目标在i′时刻的实际值对于之前k′个时刻的实际值变化量c(i′),上述参数可通过下述公式计算:

式中,j′=1,2,…,n,i′=1,2,…,k′,k′为一个确定值,取决于具体预测目标,y′(i′)是目标在i′时刻的真实值,代表i′时刻第j′种方法的预测值[14-16]。


上述公式能够完全体现权重系数的模糊语言预测规则,避免了预测准则中的空档与跳变状况发生,计算过程较为简便。
3 仿真实验数据分析与研究
利用基于云计算平台Hadoop 进行仿真实验,Hadoop 版本号为0.20.2。其包括一个主控节点与3个数据节点。主节点配置:六核CPU,Xeon E5-2430,内存为128 GB,操作系统是Centos 6。模式挖掘的数据来自某开源数据平台。共有两个预测目标,分别为某24 小时营业的大型车站与办公楼。
为了更好地对各预测方法进行评估,仿真实验中利用Pearson 相关系数与可决系数,分别记作r和R2,其计算公式如下:
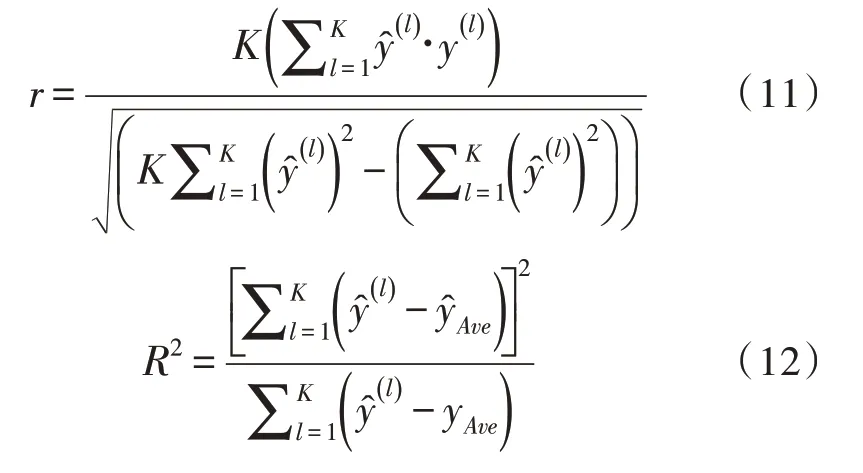
式中,K表示测试数据个数,和yAve分别代表预测值和实际值的平均值。
皮尔森相关系数r是有关实际值和预测值之间线性相关性的度量指标,其取值范围是[-1,1],-1 代表完全负相关,1 指完全正相关。可决系数R2是可以评判模型预测实际值能力的指标。该值越大,预测能力越好。
针对文献[1]方法、文献[2]方法与该文方法进行仿真实验,获得大型车站类型的智能楼宇耗能量预测的皮尔森系数与可决系数,如表1 所示。
表1 是针对大型车站建筑的能耗量预测结果,从中能够看出该文方法的皮尔森系数与可决系数更接近1。这表明该文方法的预测能力较强,获得的预测值和实际值之间的相关性较大。

表1 大型车站能耗量预测结果
此外,又对某工作日的办公楼能耗量进行预测,得出的皮尔森系数与可决系数的结果和上述结果相似。为了更加直观地证明该文预测方法的性能,绘制如图2 所示的折线图。
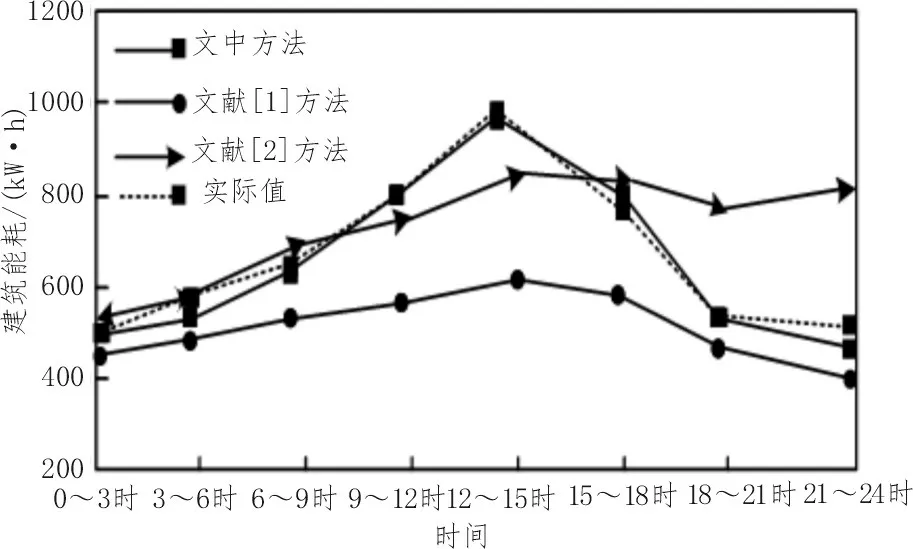
图2 不同方法对于办公楼的能耗量预测结果图
从图2 可以看出,所提方法的预测值与实际值更加接近。该文方法的预测结果能够明显看出这种趋势,证明了该文模式的挖掘算法可以很好地挖掘出关键历史数据,有助于提高预测精度。
4 结论
智能楼宇能耗量预测是提升建筑管理水平与提高设备调度合理性的必要手段。该文利用序列模式挖掘方法对历史数据进行挖掘,同时采用泛化能力与适应性较强的模糊理论构建预测模型,获得预测结果。仿真实验证明,该方法可以达到精准预测的目的,对多样化的智能楼宇有较好的预测能力。
