基于VGGish 网络的音频信息情感智能识别算法
2022-02-27张志超李晓燕
张志超,李晓燕
(1.延安大学鲁迅艺术学院,陕西延安 716000;2.延安大学数学与计算机科学学院,陕西延安 716000)
音乐是人类情感交流的一种方式,移动互联网的普及,使得人们能够随时随地享受音乐。音乐中蕴藏着丰富的情感,作为人类精神生活的重要部分,借助计算机和人工智能技术实现对音乐所表达的情感进行智能化分析、识别及分类,对音乐数据的深度应用具有重要意义[1-3]。然而目前对音频情感的研究仍相对较少,缺乏一套完整的体系对其进行智能化处理。
针对上述问题,文中设计了一种对音乐情感自动分析和识别的算法,该算法主要由音频信息采集、数据标注、数据转换等模块组成。其中,音频信息采集模块主要用于获取原始的音频信息;数据标注模块用于对获取到的音频信息进行二次情感划分;数据转换模块则是将原始数据转换为VGGish 网络可用的数据。该算法可用于对海量音频数据的智能化自动分类,并形成音频数据库。同时,可以将各类音频文件片段分类存储,用于辅助创作。
1 VGGish网络
VGG(Visual Geometry Group)网络是英国牛津大学提出的一系列以VGG 开头的卷积网络模型,也称为VGGish 网络[4]。目前已被广泛应用于图像识别等人工智能领域,在音频情感分析领域仍应用较少。但有研究表明,VGGish 网络能够提取到数据更全面、复杂的特征,这能为智能分析音频信息情感奠定良好的基础[5]。
截至目前,VGGish网络共推出了6种网络结构[6-8],分别是VGG11(A)、VGG11(ALRN)、VGG13(B)、VGG16(C)、VGG16(D)和VGG19(E)。VGG16(D)是其中应用最为广泛的网络结构,也是被认为架构层次最深的一种网络结构,但是在加深卷积网络深度的同时,算法所涉及的参数也会相应增加。VGGish 网络模型为了降低这一问题带来的影响,在卷积层采用多个小的卷积核代替大卷积核,同时将卷积步长设置为1。这样不但有效减少了网络训练所需的参数,而且等效于在网络中增加了非线性映射,可以有效提高网络的综合性能[9]。6 种VGGish 网络的具体结构如图1 所示。
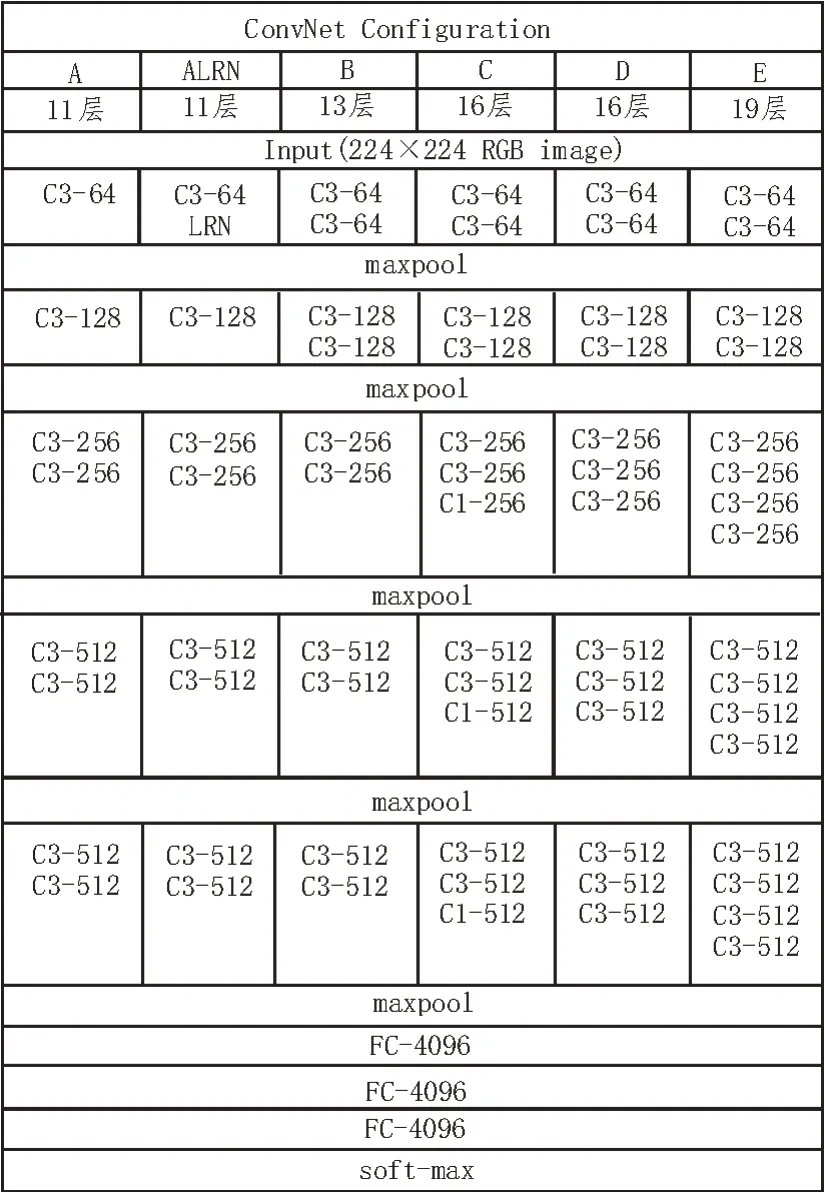
图1 VGGish网络结构
VGGish 网络根据不同的层数进行区分(层数=卷积层数+全连接层数),以VGG19(E)为例,该网络由16 个卷积层和3 个全连接层组成。每种网络均包含了5 个池化层(maxpool),并合理置于卷积层之间。但是,并非所有的卷积层都需要搭配池化层,具体位置也要根据实际情况来确定[10]。在图1中,C3-64 的全称是Conv3-64,表示该卷积层有64个大小为3×3 的卷积核。FC 代表全连接层,后面的4096 表示该全连接层的大小。但无论是哪种网络模型,其最后一层均为soft-max 层[11]。该层是实现分类功能的关键,通常被置于网络的最后,起到归一化的作用。在VGGish 网络的训练过程中,通过对训练集的学习,不断对该层中的损失函数(代价函数)进行求导。同时,对卷积层中的相关参数进行微调,从而得到使损失函数达到最小值的最优解,因此该过程也可看作是对损失函数不断拟合的过程。
得益于上文所述小卷积核的设计,虽然6 种网络结构的深度不同,但其所包含参数数量的差异却不大,具体如表1 所示。

表1 VGGish网络参数数量
虽然VGGish 网络解决了卷积神经网络深度不能超过10 层的问题,但其深度也不能无限加深,在超过一定的阈值后会出现梯度爆炸、模型训练效果急剧降低等问题。因此在加深网络深度的同时,也需要兼顾模型的应用效果。
VGGish 网络所具有的特点主要包括:
1)结构简单、层次分明:整个结构只有较小的卷积核,连续的卷积层通过5 个池化层隔开,虽然层数较多但功能明确;
2)小卷积核:卷积层中用较小的卷积核来代替大核,这样做的优势在于减少训练所需参数,增加非线性映射的强度[12],同时还能够降低感受野;
3)通道数更多、特征度更宽:通道代表着特征,VGG 网络最多提供512 个通道,可以挖掘出数据中更多的深层次特征,增强结果的准确度。
2 识别算法设计
2.1 算法架构
该文利用VGGish 网络所设计的音频信息情感智能识别算法,用于实现对海量音频数据的智能化分类。算法设计结构及算法工作流程如图2 所示。

图2 算法设计结构及工作流程
该算法流程:首先是音频信息收集,收集的内容除了最重要的音频数据之外,还包括其平台原有的情感化划分信息,便于该文进行初步筛选;然后是数据标注,其是对获取到的音频信息进行二次情感划分,由于原有的划分种类有一定的重合与包含关系存在,因此还需要进一步调整;接下来是数据转换,音频初始信息不能直接输入VGGish 网络,需要对原始数据进行处理,通常采用梅尔频率倒谱频率(MFCC)对信息进行转换,得到符合网络模型要求的输入数据[13];VGGish 网络通过不断学习与训练可以得到音频数据的Embedding 特征;此外,为了避免人为标注带来的误差还需要将提取到的音频特征进行降维可视化,不断调整不同情感音乐数据集分布,从而达到缩小组内差异,增加组间差异的目的,使得模型更加准确;最终经支持向量机(SVM)[14]和长短记忆模型(LSTM)[15]两种方式对Embedding特征进行分类,得到最为符合该首音乐的情感。下面将对其中涉及到的关键过程进行进一步深入分析。
2.2 算法关键过程
1)数据标注
文中采用的音频信息来源于国内某音乐网站,选取了9 个大类共计1 442 首音频数据,具体数据集如表2 所示。

表2 音频数据原始数据集
可以发现,原始的情感分类有些界限比较模糊,有些则是笼统地包含了其他分类,例如怀旧。因此需要将原始数据进行重新分类,使其具有相对明确的界限,分类标准:第一类为激动兴奋类,主要为气势磅礴、令人慷慨激昂、节奏感强的音频;第二类为快乐类,主要是小清新、令人高兴快乐、节奏轻快的音频;第三类为轻松类,是令人心情放松舒畅、节奏舒缓的音频;第四类为伤感类,以令人伤感、节奏沉闷的音频为主;第五类为恐惧类,以奇怪诡异和令人感到不适的音频为主。经重新调整后,各类别对应的音频数量如表3 所示,同时按6∶2∶2 的比例将数据集分为训练集、测试集和验证集。

表3 经调整后的各类情感音频数据集
2)数据转换
该文利用MFCC 方法对数据进行转换,具体步骤如下[16]:
①预处理:将原始音频数据重新采样为16 kHz的数据格式;
②加窗:将每一帧数据乘以汉明窗,以增加连续性;
③快速傅里叶变换(FFT):对每20 ms 的数据片段进行FFT,得到频谱数据;
④频谱映射:将得到的频谱数据映射到75~7 500 Hz窗口区间;
⑤分帧:将音频信息按照每480 ms 为一帧,帧内再以每10 ms 进行细分,从而得到48×64 的MFCC 特征数据。
3)VGGish 网络
该文采用VGG11(A)网络进行模型的训练,具体设计结构如图3 所示。
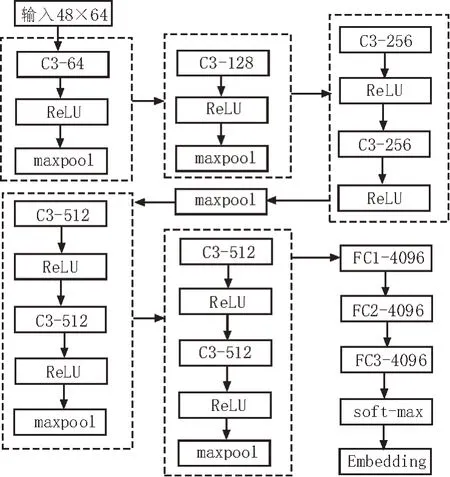
图3 VGG11(A)设计结构
该模型的作用是将输入到模型中的48×64 MFCC特征数据转换为128 维的Embedding 特征。
4)降维可视化
目前对数据进行降维可视化的方法主要包括邻接图法、LDA法、PCA法、基于切空间法和t-SNE法等,该文选用其中处理效果最优的t-SNE 法进行处理。t-SNE(t-distributed Stochastic Neighbor Embedding)由传统的SNE 发展而来,适用于将高维数据降为二维或三维,再进行可视化展示。
3 算法测试
为了测试该文所提算法在音频信息情感智能识别中的表现,在完成对VGGish 网络模型的训练后,利用测试集对算法性能进行测试。测试分为两组,两组的区别在于分类器的选择,第一组采用传统的支持向量机(SVM),第二组采用长短记忆模型(LSTM)。
首先,利用传统的SVM 算法对VGGish 网络所得到的Embedding 特征进行分类,SVM 算法的各参数设置如表4 所示。
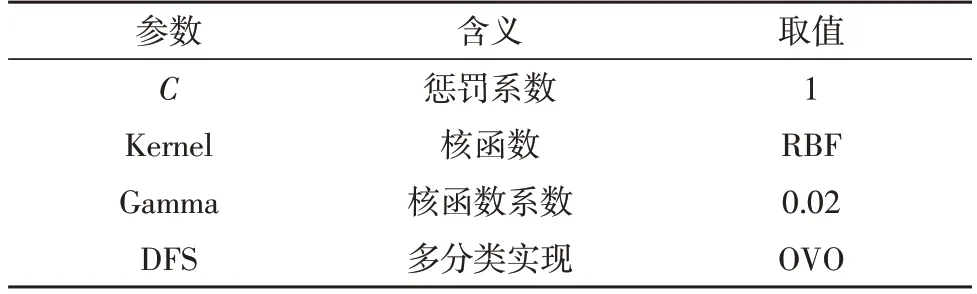
表4 SVM参数设置
其中,C代表惩罚系数,用来对损失函数进行一定控制,通常取值范围为[0.000 1,10 000],C值越大,虽然可以使训练出的模型在对训练集进行测试时的准确度有所提高,但对测试集进行测试时的准确度不足,因此仅适用于特定数据集,其泛化能力欠缺,容易形成过拟合;C值过小则会增强模型的容错率,因此泛化能力较强,但容易形成欠拟合,所以文中将C值设置为1;根据可视化的结果确定核函数Kernel为RBF 高斯核,同时在将Gamma 设置为0.02 时得到的模型效果最优,文中选用了一对一的OVO 方法。最终的试验结果如表5 所示。
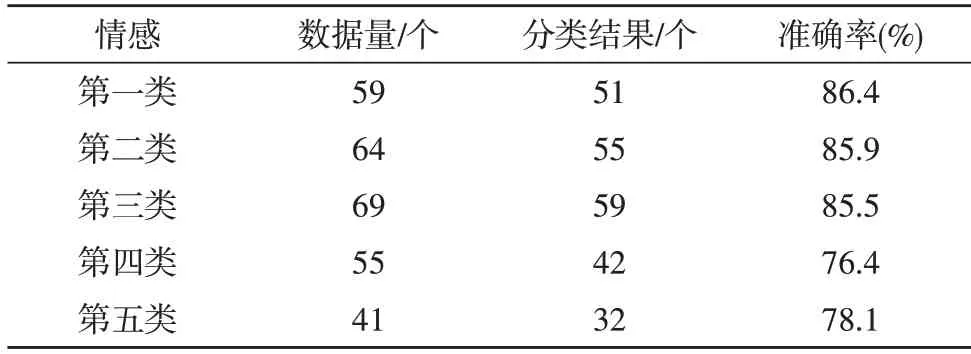
表5 SVM分类试验结果
从结果可以看出,传统的SVM 方法总体表现良好,能够达到82.46%的平均准确率。从单一类别来看,对第一类(激动兴奋类)的情感分类效果是最优的,准确率能够达到86.4%。但对于第四类(伤感类)的准确率却较低,仅为76.4%。
然后采用LSTM对VGGish网络得到的Embedding特征进行分类,分类试验结果如表6 所示。

表6 LSTM分类试验结果
从结果可以看出,LSTM 分类方法总体表现优秀,平均准确率能够达到90.12%。同时,从单个类别来看,对第五类(恐惧类)的情感分类效果最优,准确率可达92.7%;而对于第三类(轻松类)的处理效果相对较差,但仍能达到88.4%。由上述结果可知,该文所提算法能够进行音频信息情感的智能识别。尤其是当采用LSTM 分类方法时,其分类的平均准确率可达到90%以上,具有良好的识别效果。
4 结束语
该文通过介绍和分析VGGish 网络,提出了基于VGGish 网络的音频信息情感智能识别算法。算法主要由音频信息采集、数据标注、数据转换、VGGish模型训练、降维可视化、分类等模块组成,各模块之间相互配合共同完成对音频信息情感的智能识别。两项算法测试结果充分验证了文中所提算法的可行性与有效性,两种分类方法中,SVM 方法表现良好,平均准确率能够达到82.46%;LSTM 分类方法则表现优秀,平均准确率可达90.12%。为海量音频信息的智能化分析与情感识别分类提供了解决方案。
