基于时空特征的动态手势识别方法研究
2022-02-27赵雅李建军
赵雅,李建军
(内蒙古科技大学信息工程学院,内蒙古包头 014010)
手势识别是计算机视觉、虚拟现实、人机交互和手语翻译的一种重要的交互模式[1]。手势识别可以分为接触式[2]手势识别和基于视觉的手势识别[3]。接触性手势识别因为其设备较复杂、价格较昂贵,限制了手势的自然表达,不利于高效的手势交互应用。而基于视觉的手势识别无需复杂且价格高昂的设备,操作简便,更符合人机交互的发展趋势,真正实现了从复杂、低效到简单、高效的转变,因而具有广阔的应用前景。
手势识别根据是否具有时序性,可分为静态手势识别和动态手势识别。静态手势识别指单帧静止的手势图像。文芳等人[4]采用融合深度信息和彩色信息的手势分割算法分割手势区域,并提取静态手势轮廓的圆形度、凸包点及凸缺陷点等特征向量,采用SVM 进行分类。Prachi Sharma 等人[5]在深度图像中分割手部区域,提取几何形状特征,并计算举起手指数目和手掌中心距离作为特征向量,采用高斯SVM 核函数分类器进行识别分类。
相比静态手势识别,动态手势识别更加复杂,不仅需要关注手部手形的变化,还要关注手指在时间、空间中的运动趋势。随着Microsoft Kinect 等深度相机的广泛使用,人们很容易获得精准的骨架数据。手部骨胳关节点的变化趋势通常可以很好地反映不同动态手势的特征。LiuXing 等人[6]提出采用几何代数的方法从骨骼序列中提取形状和运动特征,构造时空视图不变模型。吴佳等人[7]提出动作特征,保存相关编码信息,采用改进编辑距离对手势动作进行分类。
针对动态手势识别过程中可变性的问题,文中提出动态手势关键帧的提取方法,采用基于运动的分析算法,利用图像序列中像素在时间域上的变化,以及相邻帧之间的相关性,找到上一帧跟当前帧之间存在的差值信息,根据阈值选出最合适的关键帧,去除动态手势中的冗余帧。
1 动态手势识别方法
文中从动态手势运动的内在特征出发,结合时间域和空间域手势所具有的个体性差异,提出了一种新的动态手势识别框架,如图1 所示。

图1 动态手势识别框架
首先对输入的视频序列,通过运动分析算法提取有效的关键帧,然后通过OpenPose 获取关键帧序列中手部的21 个关节点的坐标和置信度,最后采用阈值法和XGBoost 分类算法进行动态手势识别。该框架结合时空连续性,有效解决手势的时序问题,使动态手势识别变得更加高效、简洁。
1.1 关键帧提取
对于动态手势视频序列,若简单地选取每一帧作为关键帧,容易出现相邻两帧变化甚微的情况,且容易出现严重的信息冗余,导致算法效率降低。单帧提取手势视频序列变化情况如图2所示。
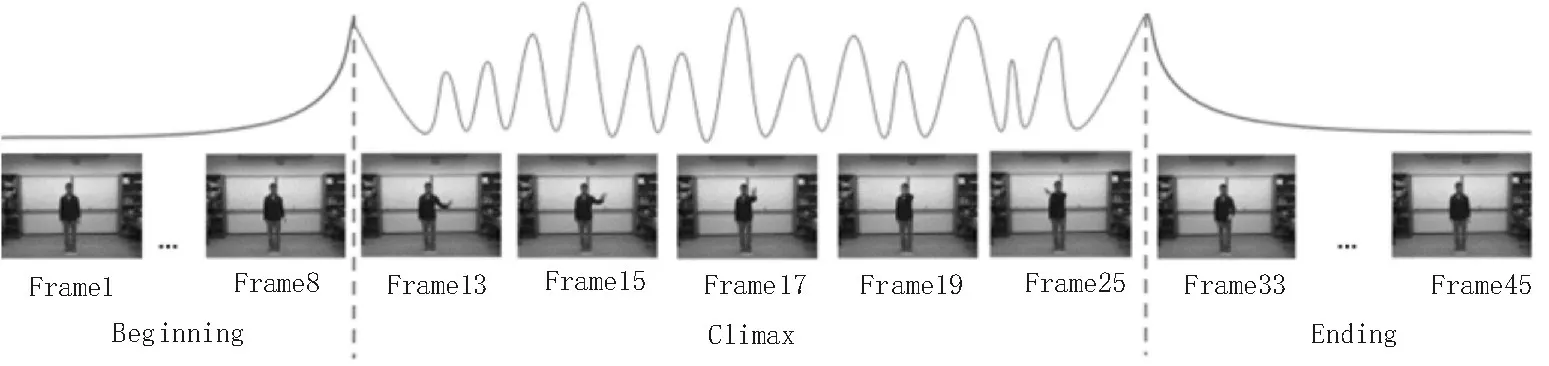
图2 关键帧分析
手势可以分为3 个阶段:起始、高潮、结束。可以看出从视频序列的第1 帧到第8 帧基本没有什么动作,可以看成是静止不动的,属于起始阶段。从第13 帧开始到第25 帧,手部动作开始频繁变换,属于高潮阶段,包含丰富的动作信息。从第33 帧到第45 帧同样手部动作变化不明显,属于结束阶段。因此,手势的变化阶段主要在高潮阶段,包含了丰富的运动变化信息,在判别手势过程中起到了决定性作用。
因此,为了提高算法效率,在完整识别出动态手势序列的前提下有效减少视频序列中的冗余帧,文中采用基于运动分析的方法来提取关键帧。具体算法描述如下:
1)读取视频,遍历数据集中的所有视频数据,并创建目录;
2)提取视频中的每一帧图像,并对每一帧提取灰度信息之后作高斯模糊处理,计算每一帧参数和相邻帧的差别,并保存到字典list中;
3)统计每一帧与上一帧的差值,记录最大值、最小值、平均值、标准差等信息,保存到字典list中;
4)根据字典list 中的信息(主要是平均值和标准差)计算阈值,当相邻帧之间的差距大于阈值时就把这一帧保存为关键帧。
根据上述算法所提取出的关键帧如图3 所示。

图3 提取手势关键帧
1.2 OpenPose手部关键点提取
OpenPose[8]可实现人体动作、面部表情、手指运动等姿态估计,适用于单人和多人,具有极好的鲁棒性。
OpenPose 中CPM(单人姿态估计)的算法流程如下:
首先,对图像中所有出现的人进行回归,回归每个人的关节;
然后,根据center map 去除掉对其他人的响应;
最后,通过重复地对预测出来的heatmap 进行refine,得到最终的姿态估计结果。在进行refine 时,OpenPose 引入了中间层的loss,从而保证较深的网络仍然可以完成训练,避免出现梯度弥散或爆炸现象。通过coarse to fine 逐渐提升回归的准确度。
文中采用开源的OpenPoseDemo 文件读取图片中的姿态信息,并将读取的信息保存为json 文件。针对手势识别只需要关注json 文件中的两个键hand_left_keypoints_2d、hand_right_keypoints_2d。每个键对应手部21 个关键点,节点有3 个值(X,Y,置信度),其中一帧的关键点数据如表1 所示。
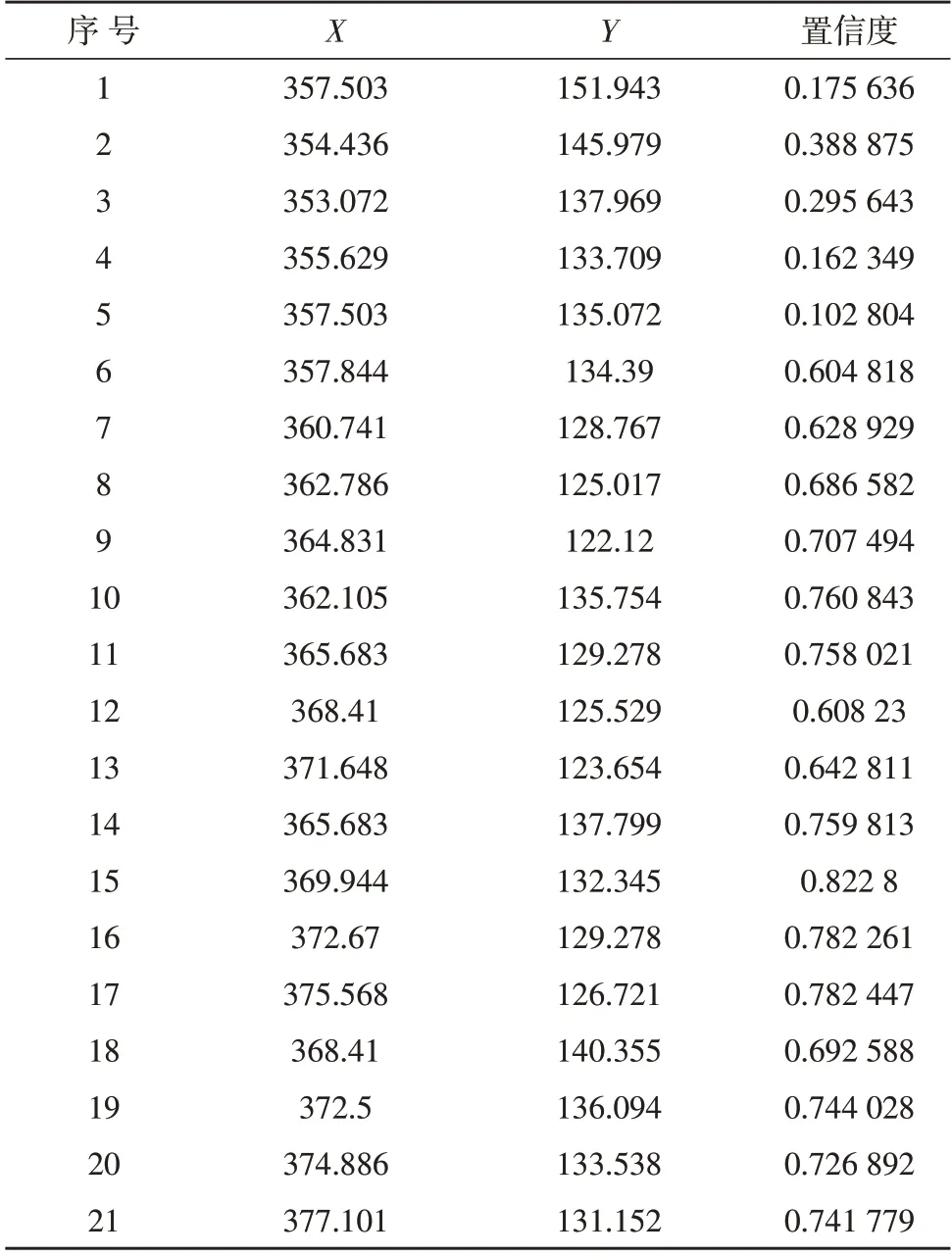
表1 关键点数据
由于部分手势动作左右手的动作相差无几,或者只有一只手处于运动状态,故不区分左右手,只识别手势的动作。文中通过对某个节点保持Y坐标不变,X坐标变为-X来进行数据增强。为了方便读取,将最终的样本整合为一个csv 文件,该文件有65 列(21(关键点)×3(X,Y,置信度)+左手/右手+动作标志)。
1.3 XGBoost分类算法
XGBoost[9]是一种专注于梯度提升的机器学习算法,被广泛应用在Kaggle 竞赛及其他机器学习竞赛中,取得了不错的成绩。不但在识别率上较传统梯度提升树要高,在识别效率上也有一定的优势。
XGBoost 本质上属于梯度提升树,其算法的基本思想是让新的模型(GBDT 以CART 分类回归树为基模型)去拟合前面模型的偏差,从而不断地将加法模型的偏差降低。
相比于经典的GBDT 算法,XGBoost 作了一些改进,因而在效果和性能上有非常明显的提升:
1)XGBoost 加入了叶子权重的L2 正则化项来平滑各叶子节点的预测值,因此模型可以获得更低的方差。
2)GBDT 将目标函数泰勒展开到一阶,而XGBoost 将目标函数泰勒展开到了二阶。保留了更多有关目标函数的信息。
3)GBDT 是给新的基模型寻找新的拟合标签,而XGBoost 是给新的基模型寻找新的目标函数。
XGBoost 算法中的正则项,目标函数定义如下:

XGBoot 的预测模型同样可以表示为式(3):

对于目标损失函数中的正则项(复杂度)部分,当从单一的树考虑时,对于其中每一棵回归树,其模型可以写成式(4):

式中,ωq(x)是叶子节点q的分数,q(x)是叶子节点的编号,f(x)是其中一棵回归树。即任意一个样本x,其最后会落在树的某个叶子节点上,其值为ωq(x),正如上文所说,新生成的决策树用于拟合上一棵树预测的残差,故当生成t棵树时,预测分数可以写成:
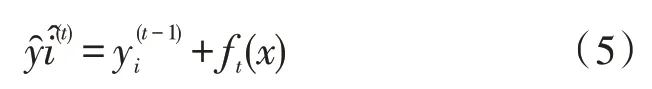
同时,目标函数可以改写成ft(xi)为当前树上某个叶子节点的值:
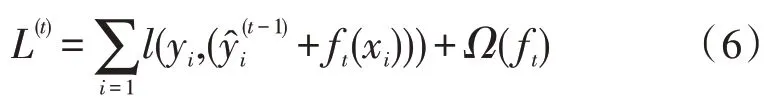
然后,需要找到能够使目标函数最小化的ft。XGBoost 是利用其在ft=0 处的泰勒公式的二阶展开式来近似求解的。故目标函数可以近似为如下公式:
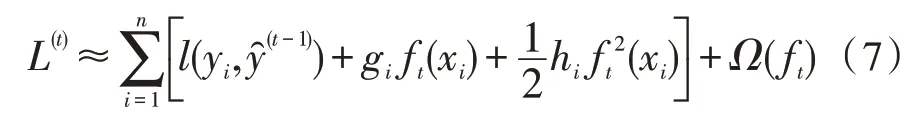
其中,gi为一阶导数,hi为二阶导数,hi前面的为泰勒二阶展开式二阶导的系数

2 算法流程
根据以上分析,文中采用的算法流程如图4所示。

图4 算法流程
3 实验结果与分析
为了验证该算法的有效性,分别采用静态数据集Microsoft Kinect and Leap Motion[10]和动态数据集UTD-MHAD 进行实验验证。
Microsoft Kinect and Leap Motion 数据集包含了14 位不同受试者执行的10 个不同的手势动作,总共为1 400 个不同的样本执行10 次。每个样本包括深度和RGB 图像、原始深度数据和CSV 数据。文中选择RGB 图像进行手势动作识别,其10 个手势动作如图5 所示。最终识别结果采用混淆矩阵表示如图6 所示。混淆矩阵可以表明,识别率可达98.23%,从中发现手势G0 和G6、G3 和G4、G5 和G8、G9 和G6 容易发生识别混淆。和其他实验方法进行实验对比,实验结果如表2 所示。

图5 静态手势动作

图6 Microsoft Kinect and Leap Motion数据集上的识别结果

表2 基于Microsoft Kinect and Leap Motion数据集不同方法的识别率对比
文献[11]中提出CSRP 算法,且递归模型可解决手势边缘序列不等长、起始点匹配问题,可有效区分不同手势,提高识别效率。文献[12]中采用Leap Motion 设备获取3D 手势数据,定义6 个新的特征描述符,使用Random Regression Forest 进行手势识别,识别率可达到100%,高于文中识别率。由于使用了3D 手势数据,相比RGB 图像的数据,可以更加准确地对各位受试者的不同手势进行描述,但Leap Motion 设备采集的数据相对复杂,而RGB 图像更加直观,相反,3D 的手势数据增加了空间复杂度和计算时间。
文中采用OpenPose 提取手部的21 个关键点,无需考虑光照环境、人的肤色、周围环境等外界因素,可以较精确地提取到手部关键点信息,而后使用XGBoost 进行手势分类的算法,可达到98.23%的识别率。通过上述的对比实验,文中提出的算法有较好的识别效果。
UTD-MHAD 数据集中选择RGB 视频数据,其中包含8 位不同受试者执行的27 个不同的动作,每个动作重复4次,共861个RGB视频序列。从中选择了16个动作,分别为Wave、Clap、Throw、Arm cross、Draw X、Draw circle(counter clockwise)、Bowling、Boxing、Baseball swing、Tennis swing、Arm curl、Push、Catch、Jog、Walk、Squat,共512 个视频序列。最终的识别结果采用混淆矩阵表示,如图7 所示。

图7 UTD-MHAD数据集上的识别结果
由以上混淆矩阵可以表明,识别率可达95.84%,从中发现Jog 与Squat 较容易发生识别混淆。在该数据集上和其他方法进行实验对比,如表3所示。

表3 基于UTD-MHAD数据集不同方法的识别率对比
文献[16]中,提取3 个通道的深度信息DMM(Front DMM、Side DMM 和Top DMM)及RGB 图像数据,通过VGG 分别进行训练预测,最终将4 个通道的预测分数进行融合,达到了95.74%的识别率。DMM由三维结构组成,故3 个通道的DMM 可充分表示各维度特征。经过预测,结合RGB 图像的预测结果进行融合,由于深度图像和RGB 图像提取特征的互补性,可实现较高的识别率。文中提出的算法,不仅能够对动作的关键帧进行选取,去掉冗余信息、提高效率,同时还能够获得理想的识别效果,充分说明该方法的有效性和可行性[17]。
4 结束语
通过实验结果表明,文中提出的动态手势识别框架,具有一定的可行性,该关键帧提取方法能够有效地提取到动态手势序列中的关键动作,并利用关键帧替代全部的动态手势帧,避免了数据的冗余。然后通过OpenPose 提取手部的关键点坐标及置信度,有效地减少了传统上对RGB 图像的预处理过程,在不同光照、环境下有很好的识别效果,可准确提取到手势的信息。
