基于Di-LSTM 算法的注意力缺陷多动障碍症分类
2022-02-27张淼陈宏涛
张淼,陈宏涛
(太原理工大学信息与计算机学院,山西晋中 030600)
ADHD[1]是一种以多动、注意力不集中和行为冲动为特点的精神障碍,在儿童和青少年中常被诊断出来,并且最近有记录证明其可能会持续到成年期,这种疾病在男孩中更为普遍。通常,ADHD 的诊断是基于使用不同版本的精神疾病诊断和统计手册(Diagnostic and Statistical Manual of mental disorders,DSM)或国际疾病分类(International Classification of Diseases,ICD)的标准进行的,由于诊断是通过教师、家长和行为科学家进行的主观观察来完成的,因此寻找有助于诊断ADHD 的定量技术已经引起人们的关注。
近些年来,静息态功能磁共振成像(resting statefunctional Magnetic Resonance Image,rs-fMRI)因其无创、无辐射、时空分辨率高且不需要被试完成复杂的任务,已经被广泛地用于精神疾病的研究[2]。已有许多在fMRI 上使用机器学习来研究ADHD,杜海鹏等人[3]提出一种基于多目标支持向量机的分类模型,经过对比,其准确率显著提高,达到了75.3%。但是由于传统的机器学习模型大多是浅层模型,对于高维fMRI 数据的拟合效果并不理想,并且大多需要人工进行特征选择,一些相关性较弱的体素会被忽视。所以,深度学习逐渐被引入相关研究,2017 年毛振宇、苏怡等人[4]基于静息态fMRI 数据,提出了一种基于4-D CNN 的深度学习模型用于ADHD 的分类,得到实验结果准确率为71.3%,AUC 为0.8;2020 年张涛、李存波等人[5]通过将分离通道卷积神经网络(SC-CNN)与基于注意力的网络(SC-CNN-attention)相结合,提出了一种新的两阶段网络结构,以大规模区分ADHD 和健康控制多站点数据库,分类结果为68.6%。
“深度空间”的卷积神经网络(Convolutional Neural Network,CNN)和“时间深度”的递归神经网络(Recursive Neural Network,RNN)是两个经典的深度学习分支。RNN 模型(例如长短期记忆(Long Short Term Memory,LSTM)[6])和门控循环单元(Gated Recurrent Unit,GRU[7])已被大量用于精神疾病的识别与分类,例如使用fMRI 识别孤独症谱系障碍[8]和阿兹海默症[9]等。
文中提出了将字典学习和长短期记忆网络相结合的方法对rs-fMRI 数据进行处理,最终用来预测ADHD 患者和正常人。
1 材料和方法
ICA(Independent Component Algorithm)由于其可以很好地处理稀疏分量[10]被广泛应用于rs-fMRI 数据的处理,但是由于其具有一定的限制和局限性。字典学习算法有着更为稀疏的表示,因此受到学者们的重视[11]。
首先利用ADHD 和正常被试数据相结合,基于FastICA 初始化的在线字典学习获取ROI 时间序列,结合LSTM 对于序列类数据处理的优势,再将获得的时间序列输入提出的LSTM 模型中进行训练,然后进行预测。实验流程如图1 所示。

图1 实验流程
1.1 在线字典学习
在线字典学习算法可以在线解决字典学习矩阵分解问题,通过求解式(1)找到用于近似数据矩阵的最佳字典和相应的稀疏编码。
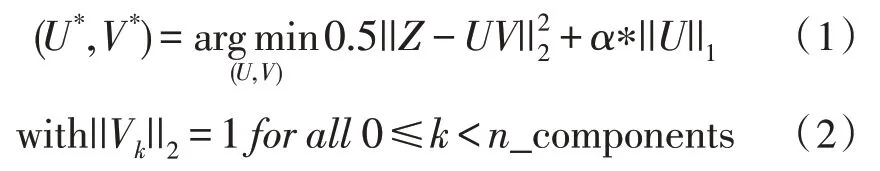
式中,V是字典,U是稀疏编码,Z是数据矩阵,α为正则化参数。显然,式(1)的第一项是希望很好地重构Z,第二项则是希望U尽量稀疏,k为字典V的行索引。
在线字典学习需要获得稀疏编码和学习字典矩阵,文中采用交替优化的策略来求解式(1),包括稀疏编码和更新字典两个阶段,其中,利用最小角度回归法来解决Lasso 问题,迭代次数设为100,批量大小为η(值为3),通过批量处理可以加快算法的收敛速度。在在线字典学习开始之前,已经通FastICA 结合岭回归获得了字典初始化矩阵,以此来初始化式(1)中的V。在之后的每次迭代顺序循环选择3 行数据进行计算。
1)稀疏编码与更新辅助变量
创建矩阵A以及矩阵B来保存辅助变量(零矩阵),方便后续的迭代更新。Ut的计算如式(3)所示:

式(3)中,t为第几次迭代,k即为设定的成分数目,每次迭代过程都选择数据中的η行。
2)字典更新
字典更新开始时使用Vt-1进行热启动。Vt的计算如式(4)所示:
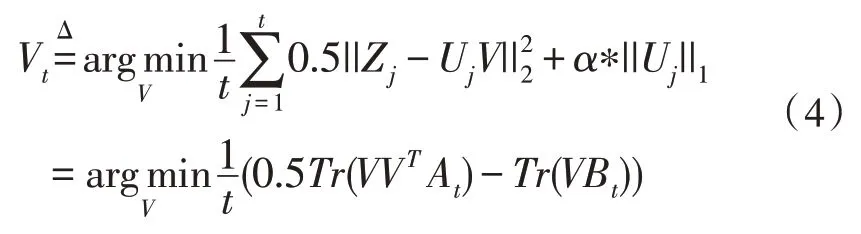
在字典更新中循环k次,k为成分数,即字典的行数。
1.2 长短期记忆模型
长短期记忆(Long Short Term Memory)模型属于一种特殊的RNN 模型,它的提出是为了解决RNN 模型梯度弥散的问题,由重复的单元组成,这些单元接收来自前一个单元的输入以及当前时间步长t的数据输入xt。每个LSTM 单元包含一个单元状态ct和隐藏状态ht,它们由控制进出单元存储器的信息流的4 个神经网络层进行调制。控制LSTM 的方程为:

具体来说,输入门控制输入xt和ht-1对当前存储单元的影响程度(式(5));遗忘门ft控制前一个存储单元ct-1对当前存储单元ct的影响程度(式(6));输出门控制当前单元ct对隐藏状态单元ht的影响程度(式(7));存储单元ct是两个分量的总和:前一个存储单元ct-1由ft和gt调制(式(8)),输入门it调制的当前输入和先前隐藏状态进行加权组合(式(9));同样,用输出门ot过滤单元状态,用于隐藏状态更新,这是LSTM 单元的最终输出(式(10))。
2 数 据
2.1 数据集
选择NeuroBureau 为ADHD-200 竞赛发布的北京大学站点预处理后的数据。该数据由rs-fMRI 数据以及每个被试的不同表型信息(非成像数据)组成。其中,训练集中有144 个被试,测试集中有50 个被试,所有被试都是右利手。数据集信息如表1所示。

表1 数据集信息
2.2 数据预处理
数据是基于NIAK 管道预处理的,使用了MINC工具包和自定义Matlab/Octave 脚本[12]。预处理步骤包括去除前3 个时间点、时间层校正、头动校正、校正时间漂移和生理噪声,将功能数据配准到3×3×3 mm3分辨率的蒙特利尔神经病学研究所(Montreal Neurological Institute,MNI)的标准空间模板,最后采用6 mm 全宽半高(Full Width at Half Maximum,FWHM)高斯核空间对图形进行平滑化处理。在后续的实验中,学习大脑ROI 是在训练集上进行的,防止过拟合[13]。
3 实 验
3.1 字典学习提取ROI
ROI 的常见确定方法:一种是基于各种大脑模板图谱的自动解剖标记(Automated Anatomical Labeling,AAL),这是一个大脑结构图谱,包括116 个ROI。稳定集群自举分析(Bootstrap Analysis of Stable Clusers,BASC)是一个多尺度的功能图谱,具有不同数量ROI 图谱的选择,包括36、64、122、197、325 和444。另一种是通过数据驱动的方式来获取ROI,包括k-means、ward 和最近提出的ReNA 聚类算法[14],以及ICA 方法和字典学习方法,后两者在fMRI 数据上表现比前者更好。基于大脑图谱的方法在获取被试的大脑网络时可能存在一定的偏差,选择数据驱动的方法来获取所需的ROI 时间序列。与经典批处理算法相比,在线字典学习有着更好的性能,且能获得更好的字典,文中提出将FastICA 应用到在线字典学习的初始化环节,使得分类效果有所提升。
3.1.1 计算字典初始值
除了比较常见的利用SVD 来构建初始化字典,还可以通过已知的脑网络来获取初始化的字典[15]。文中利用FastICA 算法获取相应的脑网络并计算出字典初始值。每个被试的rs-fMRI 数据是形如(49,58,47,232)的四维图像,其中第四维是时间点,前三维构成了包含3D 大脑的立方体。
在对rs-fMRI 图像预处理之后,利用训练集所有被试的图像获得共同的大脑掩模,大脑掩模可以提取3D 立方体空间中只属于大脑内部的体素,结合大脑掩模将每个被试的rs-fMRI 图像转换为形如(28 546,232)的二维时间序列,28 546 为体素个数。对每个被试的体素时间序列进行PCA 降维,再将所有被试降维后的数据叠加到一起形成了组成级别分析所需的数据Z,如(28 546,n*60),其中n为被试个数,60 为指定的降维数目。在对数据Z进行标准化以及典型相关分析之后,利用FastICA 算法即可获取相应的脑网络成分,即独立成分。
利用FastICA 获取的脑网络成分(即独立成分)和数据Z结合岭回归即可获取相应的回归系数,使之作为字典初始值。岭回归相比最小二乘法获得的回归系数更切合实际、更可靠,通过对回归系数增加惩罚项来实现。
3.1.2 在线字典学习
实验中对字典更新迭代100 次便得到了更新后的字典V,结合数据Z可以计算得到所需要的稀疏编码U,即在线字典学习脑网络成分。在线字典学习获取的众多成分中每一个都可以称为脑网络,并且所有脑网络可以被概念化为脑功能图谱,如图2 所示。获取的时间序列如图3 所示。

图2 使用字典学习获得的ROI图谱
图3 获取的时间序列
依据训练集学习到的功能图谱,对被试相应ROI 区域内体素时间序列求平均值即可获得被试的ROI 时间序列。
3.2 扩充时间序列
在得到每个受试者的平均时间序列之后,为了得到更多的输入样本防止过拟合,选择提取长度T=30 的一系列子时间序列[16-17],从每个被试的时间序列里截取10 个长度为T的序列,这样我们就得到了原来数据10 倍的时间序列,总共1 940 个数据作为模型的输入。
3.3 模型训练
文中提出了一种LSTM 体系结构,该体系结构将功能磁共振成像即上面所获得的1 940 个时间序列作为输入。
提出的LSTM 模型总共有4 层,采用最基本的框架,如图4 所示。在给定来自前一个时间点T的时间序列数据的情况下,预测在时间T+1 时的fMRI 时间序列数据。测试数据被输入到LSTM 层,最后一层输出被送到完全连接层。使用Kears 对LSTM 进行了相应的训练和测试,并且使用了自适应矩估计(Adam)优化器来最小化真实标签和预测标签之间的损失值,将batch size 设置为32,学习率从0.001开始,并在每个时期后以10-2的衰减率衰减,损失函数为交叉熵损失。
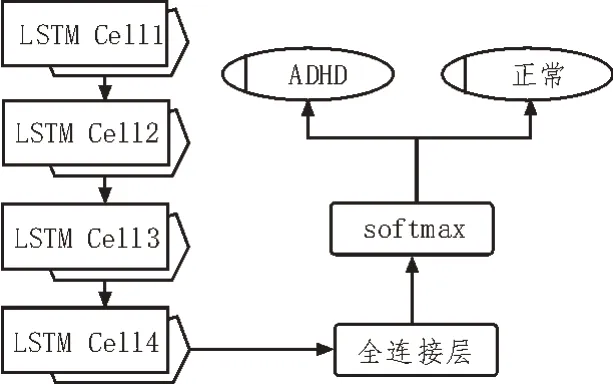
图4 模型结构
为了提高模型的泛化性能并克服过度拟合,还使用了dropout(dropout=0.5)和L1,2-范数正则化(L1=0.000 5,L2=0.000 5)来调节模型参数。当验证损失停止减少50 个epoch 或执行了最大epoch(1 000 个epoch)时,训练过程就停止了,显著性检验采用双尾配对t检验,α=0.05。
为了对模型进行评估,文中使用了10 倍的交叉验证,对数据集进行了分割,对25%进行测试,75%进行训练。
4 结果与分析
4.1 评估指标
根据交叉验证的结果,选择了灵敏度(sensitivity)、特异性(specificity)以及分类准确率(accuracy)3 个分类结果评估指标。指标计算方法如下:

式中,TP为真正例,FN为假反例,FP为假正例,TN为真反例,SN为灵敏度,SP为特异性,ACC为分类准确率,FPR为假阳性率,ROC 曲线下的面积可以反映分类器的性能,面积越大分类器的性能越好。
4.2 TC提取策略的分类比较
除了使用文中所提出的基于在线字典学习的方式提取时间序列之外,传统方式还可以通过各种脑区模板来对时间序列进行提取。为了验证方法的有效性,通过使用概率图谱(MSDL)、自动解剖标签(AAL)和史密斯地图集(Smith Atlas)3 种模板来提取时间序列,并和提出的方法做对比,不同模板提取时间序列结果比较如表2 所示。

表2 不同模板提取时间序列结果比较
通过实验可知,基于已知模板的方式直接提取相应时间序列,该方式与文中提出的基于FastICA 初始化的在线字典学习算法提取前期的ROI 相比,文中方式在准确率上达到了79.01%,在灵敏度和特异性方面也分别达到了62.70%和88.90%,很明显Di-LSTM 方法得到的大脑ROI 图谱更加稳定和精确,分类效果也较优。
4.3 不同方法分类性能比较
目前,对于ADHD 分类的研究,很多方法是基于功能连接结合机器学习的算法。为了验证方法的有效性,基于ADHD-200 数据集设计了3 个对比实验:对基于多尺度SVM、SC-CNN-Attention、Di-DNN 3种分类方法结果作对比。
Di-DNN 将字典学习和深度神经网络相结合,利用ADHD 和正常被试数据结合基于FastICA 初始化的在线字典学习获取ROI 时间序列,之后结合深度神经网络(Deep Neural Networks,DNN)算法进行分类,得到的分类结果为另一组对比实验,表3 是文献中方法与Di-DNN 以及Di-LSTM 方法进行对比的结果。深度神经网络由4 层全连接层构成,每层的神经元个数分别为512、256、128、2,每个全连接层之后均有一个dropout 层,且前三层的激活函数为LeakyReLU(alpha=0.05),最后一层为softmax。

表3 不同方法分类对比结果
由表3可知,Di-LSTM算法准确率达到了79.01%,而相应的ROC 图如图5 所示,达到了0.88,整体表现较好。

图5 使用Di-LSTM方法分类ROC图
文献[3]使用多目标支持向量机对ADHD 进行分类,准确率为75.30%;文献[5]使用了带有注意力网络的分离通道卷积神经网络(SC-CNN-Attention),处理了基于AAL 模板提取的时间序列信号,最后得到的准确率为68.6%;字典学习和深度神经网络(DNN)相结合达到的分类结果准确率为70.1%;Di-LSTM 用字典学习和LSTM 相结合的方法对ADHD疾病进行预测分类,最终得到的平均准确率达到了79.01%,分类的结果分别比文献[3]、文献[5]、字典学习和DNN 结合的方法提高了3.71%、10.41%、8.91%。实验结果验证了Di-LSTM 算法在ADHD 疾病领域分类的可用性。
5 结论
文中提出了一种基于在线字典学习和LSTM 的方法对多动症进行功能磁共振成像分类。文中的时间序列利用FastICA 初始化的在线字典学习算法获取被试数据的稀疏表示,其次使用LSTM 模型对所获得的时间序列进行训练。由此产生的网络实现了在注意力缺陷多动症ADHD-200 数据集上对典型个体和注意力缺陷多动症患者进行分类的先进性能。在未来,定位注意力缺陷多动症的典型脑运动模式,并构建更深入的学习模型,以用于注意力缺陷多动症和其他精神障碍的诊断,将是一个有意义的方向。
