基于社区网络的大气污染源定位算法
2022-02-19宿兵畅张亚娟张素琪
宿兵畅 张亚娟 张素琪
1(河北工业大学人工智能与数据科学学院 天津 300401) 2(河北省大数据计算重点实验室 天津 300401) 3(天津商业大学信息工程学院 天津 300134)
0 引 言
随着工业的发展和城镇化速度的不断加快,我国大气污染问题由间歇性突发问题逐渐演变成常态性多发问题[1],只有从复杂的污染数据中分析出污染源,才能从根本上解决大气污染问题,因此污染源定位对于治理大气污染具有重要意义。
传统的污染源定位算法是基于气体浓度衰减模型的定位方法。这类方法以气体扩散理论为基础,通过气体扩散过程中污染物浓度和扩散距离的关系,计算出污染源的位置[2]。2006年匡兴红等[3]基于气体污染源浓度衰减模型,利用最小二乘法和极大似然预估算法,对污染源定位进行了研究。2009年朱勇等[4]提出一种基于无线传感器网络的加权组合三边算法来对气体源进行定位。2013年杨一帆等[5]通过构建突发型大气污染源位置识别的空间反演算法对污染源位置进行了识别。2014年吴正佳等[6]假设各监测点为PM2.5扩散源,求解每个监测点扩散到其他站点的PM2.5浓度,最后根据各监测点位的PM2.5浓度和,定量分析确定污染源位置。上述基于气体浓度衰减模型的污染源定位算法是在不考虑风向、风速、污染物释放速率、大气压强、温度和地表状况等环境因素影响的理想化条件下进行的,然而环境因素对气体浓度衰减模型的结果会产生很大影响。
为了解决气体浓度衰减模型在污染源定位中易受环境因素影响的问题,近年来,部分学者将社区网络分析方法(Social Network Analysis,SNA)应用于研究大气污染问题。2015年薛安等[7]以161座城市作为节点,以城市间PM2.5质量浓度的相关性与距离的比值作为边的权重,构建加权网络,并采用Girvan Newman算法对网络进行划分,得到了不同季节中国的污染区域分布情况。2017年孙亚男等[8]通过分析长三角地区的空气质量指数AQI,证明了大气污染城市联动网络的存在,并从时空的角度揭示了55个城市在大气污染联动机制中表现出的内在科学规律。2018年马博宇等[9]通过构建污染网络,并根据节点重要性综合评价结果从整个大网络中提取出联系最为紧密、相关性最强的一个雾霾污染网络。2019年肖琴等[10]通过分析由66座城市组成的污染网络的社区结构、模体等性质得出了网络中的主要污染区域。上述利用社区网络的方法对大气污染的研究仅停留在发现污染区域的层面,对具体污染源的定位研究还相对较少。
针对上述问题,本文提出了基于社区网络分析的大气污染源定位算法。算法首先采用Granger因果检验方法[11]分析各监测点处AQI的时间序列,得出任意两个监测点的AQI之间的影响关系,并且以这些影响关系作为两个监测点之间的关联关系,监测点作为节点,构建由监测点组成的污染网络[12];然后,通过改进的标签传播算法(ILPA)将污染网络划分成多个污染区域;最后,采用社区网络分析方法对划分后的每个污染子网络进行中心性分析,根据分析结果预测污染源的位置。本文以273个监测点的AQI作为样本数据,构建了由监测点组成的污染网络,并通过对网络的聚类划分,以及对各子网络中节点的度中心度、出度和入度的计算与分析,将污染源的定位范围由污染区域进一步缩小到了具体的监测点附近,提高了定位的精确性,实验表明本文方法可准确定位污染源位置。
本文算法流程如图1所示。

图1 算法流程
1 模型建立
1.1 关联关系矩阵的构建
从大气污染的扩散性角度分析,一些先被污染的监测点处的污染物浓度变化很可能是引起其他监测点处污染物浓度变化的原因,即一个监测点处空气质量的变化可能会影响其他监测点处空气质量的变化。因此,分析AQI时间序列之间因果关系,可以得出哪些监测点污染的变化引起了另外一些监测点污染的变化。本文通过Granger因果关系检验方法来计算任意两个监测点处AQI变化的因果关系。
Granger因果关系检验是用于判断两个时间序列之间是否存在因果关系的一种方法。在时间序列的情形下,两个变量a1和a2之间的Granger因果关系定义如下:
定义若在包含了变量a1和a2的过去信息的条件下,对a2的预测效果要优于只单独由a2的过去信息对a2进行的预测效果,即变量a1有助于解释a2的将来的变化,则认为变量a1是a2的Granger原因[13]。
进行Granger因果关系检验的一个前提条件是:参与检验的时间序列是平稳序列,对非平稳时间序列需要进行差分处理直到时间序列平稳,否则可能会出现虚假回归问题,因此在进行格兰杰因果关系检验之前首先应对各时间序列的平稳性进行检验。
平稳性指的是监测点v处的AQI的时间序列{AQIv,t}的特性不随时间t的变化而变化,即均值、方差和协方差都是与时间t无关的常数。常用ADF检验来分别对各指标序列的平稳性进行检验。具体的Granger因果检验步骤如下:
构建两个监测点v1和v2处AQI的关联关系方程,表示为:
(1)
式中:AQIv1,t和AQIv2,t分别表示监测点v1和监测点v2在t时刻的具有平稳性的AQI的数据值;αj、βj、γj(j=1,2)是待测参数;{εj,t}(j=1,2)为残差项;m、n、p、q为滞后阶数。
根据参数γ1,i和参数γ2,i是否全为0,检验结果存在以下四种可能的情况:
(1) 若γ1,i至少有一项不为0,γ2,i全部为0,则表示:{AQIv2,t}是{AQIv1,t}的Granger原因,且{AQIv1,t}不是{AQIv2,t}的Granger原因,两监测点之间的污染影响情况关联关系表现为{AQIv2,t}→{AQIv1,t},即v2监测点处的大气污染对v1监测点处的大气污染有单向影响。
(2) 若γ1,i全部为0,γ2,i至少有一项不为0,则表示:{AQIv1,t}是{AQIv2,t}的Granger原因,且{AQIv2,t}不是{AQIv1,t}的Granger原因,两监测点之间的污染影响情况关联关系表现为{AQIv1,t}→{AQIv2,t},即v1监测点处的大气污染对v2监测点处的大气污染有单向影响。
(3) 若γ1,i和γ2,i全部满足至少有一项不为0,则表示:{AQIv1,t}是{AQIv2,t}的Granger原因,且{AQIv2,t}是{AQIv1,t}的Granger原因,两监测点之间的污染影响情况关联关系表现为{AQIv1,t}→{AQIv2,t}且{AQIv2,t}→{AQIv2,t},即v1监测点处的大气污染和v2监测点处的大气污染存在有双向影响。
(4) 若γ1,i和γ2,i全部为0,则表示:{AQIv1,t}不是{AQIv2,t}的Granger原因,且{AQIv2,t}也不是{AQIv1,t}的Granger原因,即v1监测点处的大气污染和v2监测点处的大气污染不存在互相影响。
根据Granger检验结果,如果v1监测点处的大气污染对v2监测点处的大气污染之间的关联关系表现为{AQIv1,t}→{AQIv2,t},则在监测点间的污染影响情况邻接关系矩阵中Rv1,v2的值为1,否则在监测点间的污染影响情况的邻接关系矩阵中Rv1,v2的值为0。因此可以构建如式(2)所示的监测点之间的污染影响情况的关联关系矩阵R。
(2)
式中:Ri,j表示第vi个监测点和第vj个监测点之间的关联关系值,Ri,j等于1或0。规定当i=j时,Ri,j的值为0。
1.2 污染网络的构建与划分
如图2所示,以监测点作为网络的节点,以监测点间的污染影响情况的邻接关系矩阵R作为网络中节点间的关联关系连边,构建监测点间的污染网络结构图G。
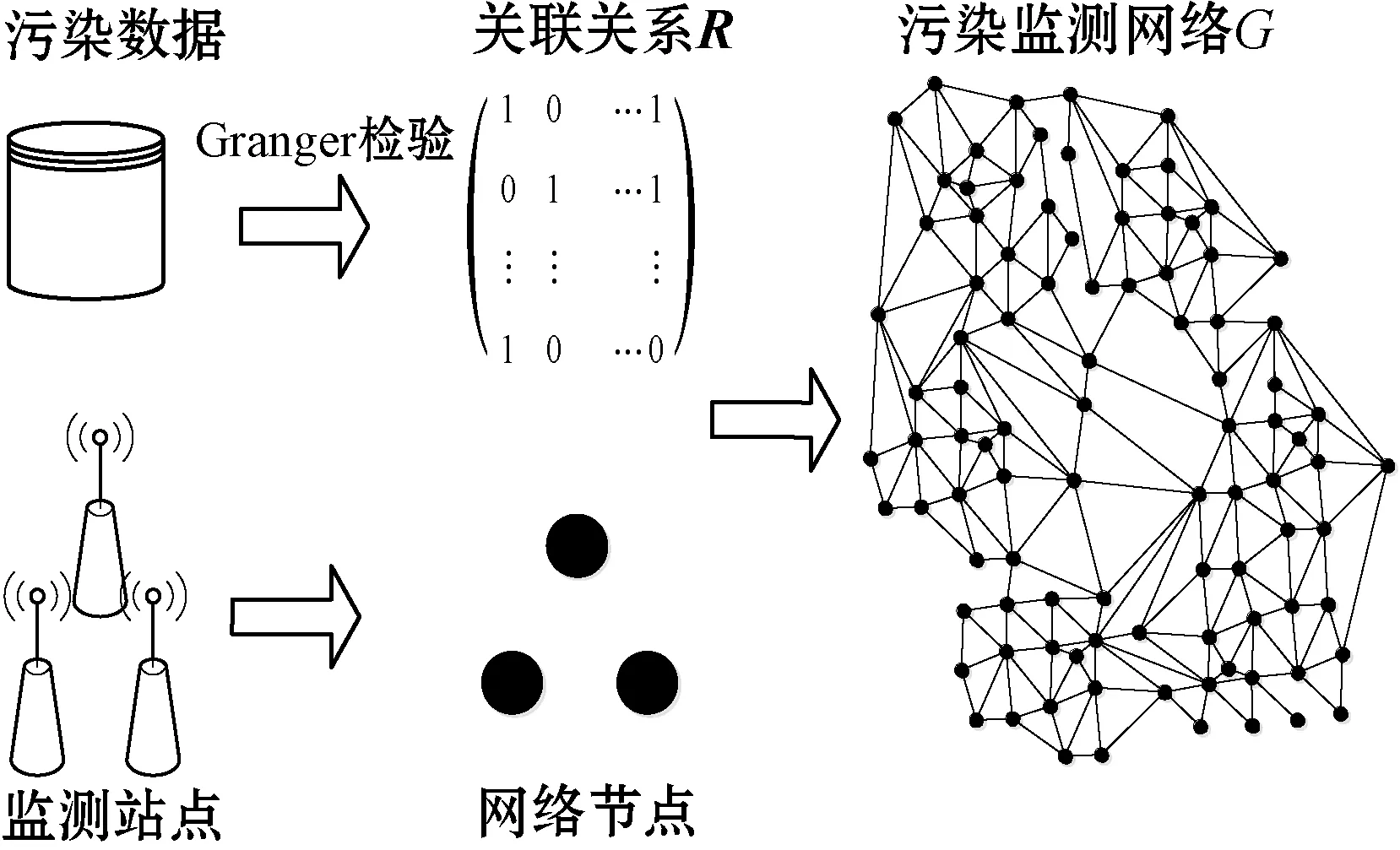
图2 污染网络构建过程
一个污染源产生污染的影响范围是有限的,在这个有限的范围内,各个监测点的污染变化情况互相影响较大,而不同的污染范围之间的污染情况的相互影响相对较小。在污染网络中表现为:在一个污染区域的内部,监测点之间的具有直接的、较强的、相对紧密的关联关系,而不同的污染区域之间的关联关系相对较弱。根据这一性质,可利用标签传播的思想将污染网络划分,如图3所示。
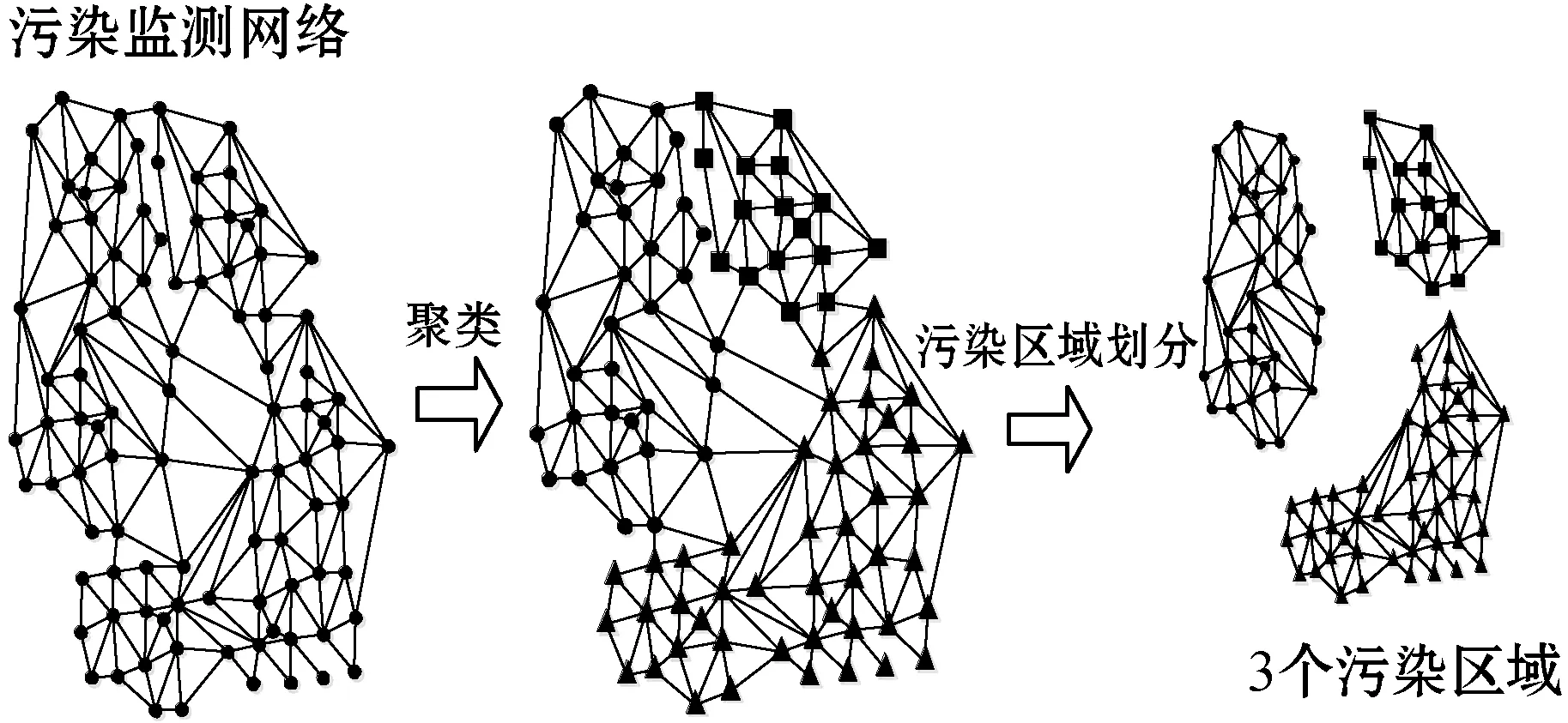
图3 污染网络的划分图
在实际情况中,污染网络结构图中所涵盖的污染区域存在两类情况,如图4所示,其中,单一污染区域情况指所构建的污染网络中仅存在一个污染区域;多污染区域情况指所构建的污染网络中存在多个污染区域。
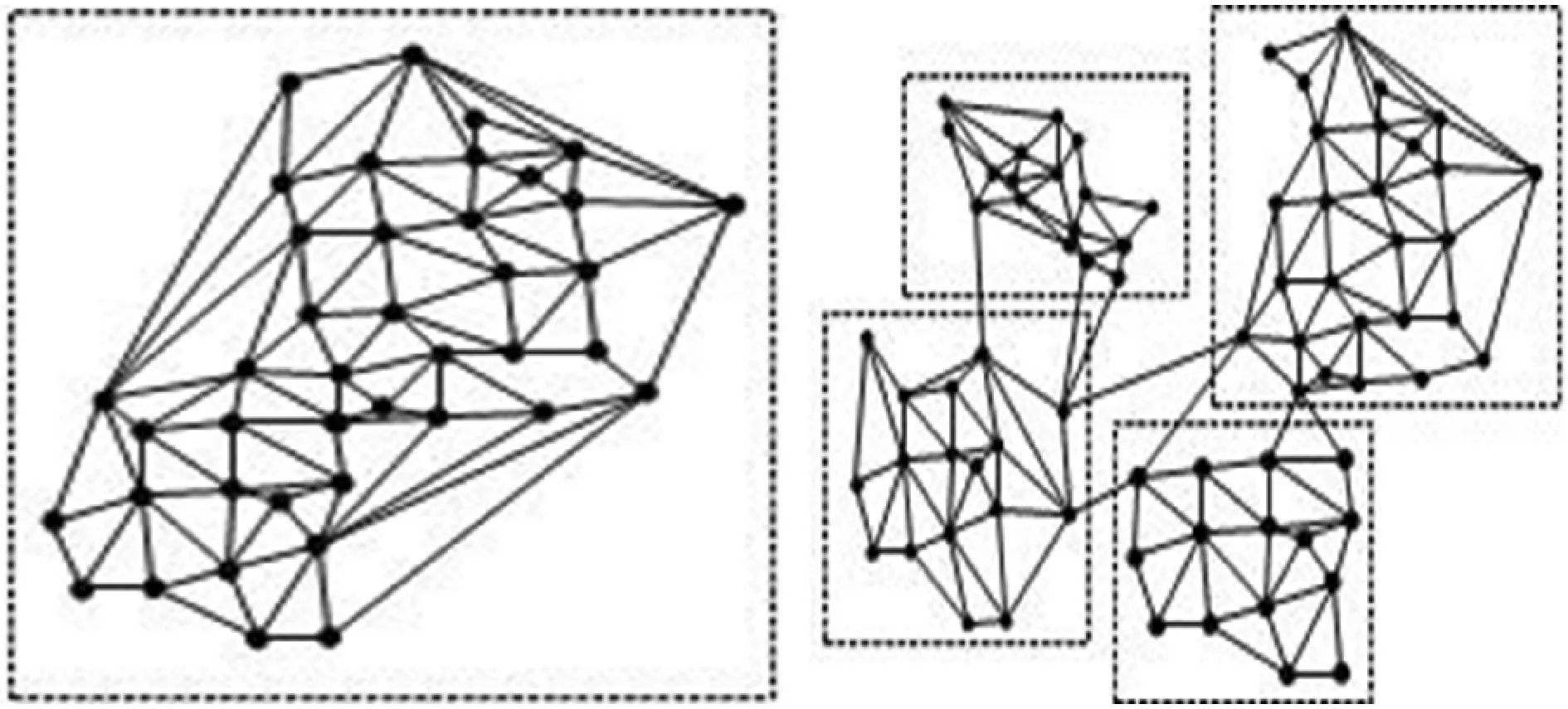
(a) 单一污染区域 (b) 多污染区域图4 两类污染区域图
传统的标签传播方法(LPA)仅从网络的结构特征来决定标签的传播[14],在标签传播的过程中,节点根据式(3)选择其邻居节点中出现次数最多的标签更新自身的标签。
(3)
式中:Ni(l)表示节点i的标签为l的邻居节点的集合;Ui(l)表示节点i的邻居节点中标签l出现的次数;li表示节点i的标签,此处Ri,j取1。
然而LPA在真实的污染网络中并不完全适用。如图5所示,若网络中有标签分别为A、B、C的三个节点1、2、3,其中节点2和节点1在现实的情况里距离较近,节点2与节点3的距离较远。由于距离较远,节点3处的污染对节点2处的污染的影响可以忽略不计,因此节点2和节点1应该在同一个污染区域,节点3单独处于一个污染区域。然而,传统的LPA并没有考虑实际情况中的距离因素对于污染扩散的影响。因此,更新节点2的标签时,可选择标签A或标签C中的任意一个,若选择将节点2的标签更新为C时,最终将会造成与实际情况不符的污染网络的划分,即将节点2和节点3划分到一个污染区域,从而影响对于真实的污染网络的划分的准确度。
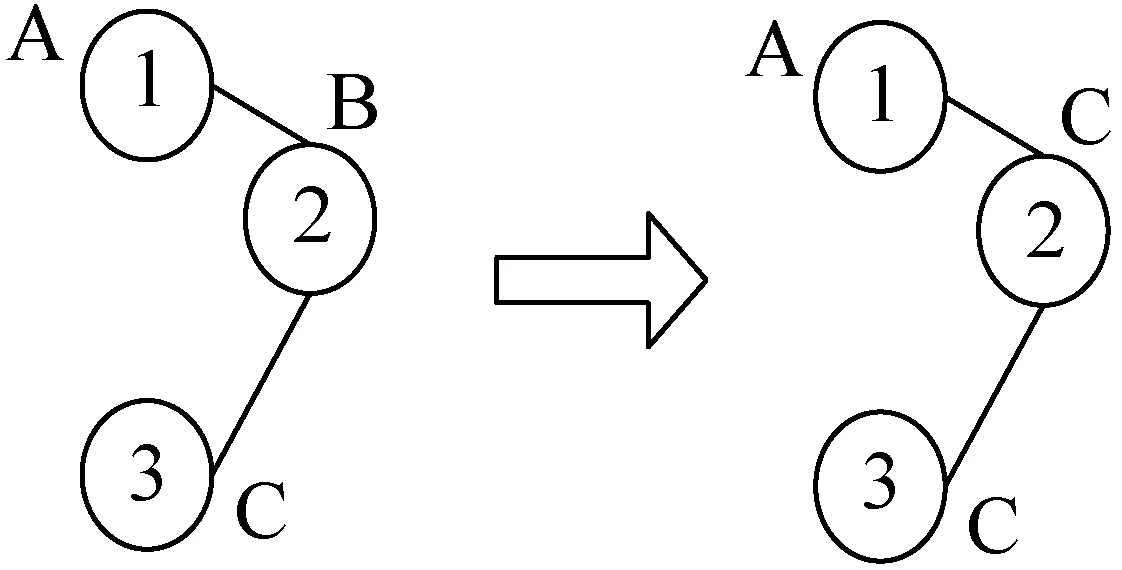
图5 LPA标签传播过程示意图
因此,本文引入污染影响因子I(i,j)来优化标签的更新过程。针对污染网络的划分,本文基于传统的LPA算法,提出了一种基于污染影响因子的改进ILPA算法。污染影响因子计算式为:
(4)
式中:(xi,yi)和(xj,yj)分别表示节点vi和vj的纬度坐标及经度坐标。
基于污染影响因子I(i,j)优化后的更新节点标签的计算式为:
(5)
ILPA算法具体步骤如下:
Step1为每一个节点初始化一个唯一的标签。
Step2随机对网络中的节点进行排序。
Step3根据Step 2中的节点排列顺序更新节点,根据式(5)在待更新节点的所有邻居节点中确定更新后的标签li。当li不唯一时,随机选择一个标签作为更新后的标签。
Step4当网络中的所有节点的标签稳定不变时,算法结束,否则返回Step 3继续。
1.3 污染子网络中污染源的判断
在一个社交网络中,描述节点特征的属性一般有出度、入度等。节点的出度表示的是从该节点出发的指向其他节点的有向线段的条数,它在污染监测网络中描述了该监测点处污染的变化情况影响的监测点数量,若其出度越大,表示该监测点处的污染情况影响的监测点数量越多。节点的入度表示的是从其他节点出发指向该节点的有向线段的条数,它在污染监测网络中,描述了对监测点处污染产生影响的监测点数量,若其入度越大,表示对该监测点污染产生影响的其他监测点数量越多。此外,在社交网络分析中常常采用度中心度这一属性来描述整体网络中一个节点与网络中其他节点的关联程度。其中,度中心度表示的是与该节点直接相连的节点的个数[15]。在污染网络图中,度中心度越大,表示该监测点处污染情况与网络中其他监测点处污染情况的关联程度越大。
根据网络中节点的特征属性,在一个污染区域内污染源的判断标准如下:若一个监测点的度中心度较大,且该站点的出度大于入度,则该监测点在污染网络处于中心位置,与其他监测点的关联程度最大,且该监测点处的污染情况对其他站点处的污染情况的影响程度大于其他站点处的污染情况对该站点处污染情况的影响,那么该监测点附近存在污染源。如图6所示,节点6的度中心度相对较大,且出度大于入度,因此在节点6的附近存在污染源。
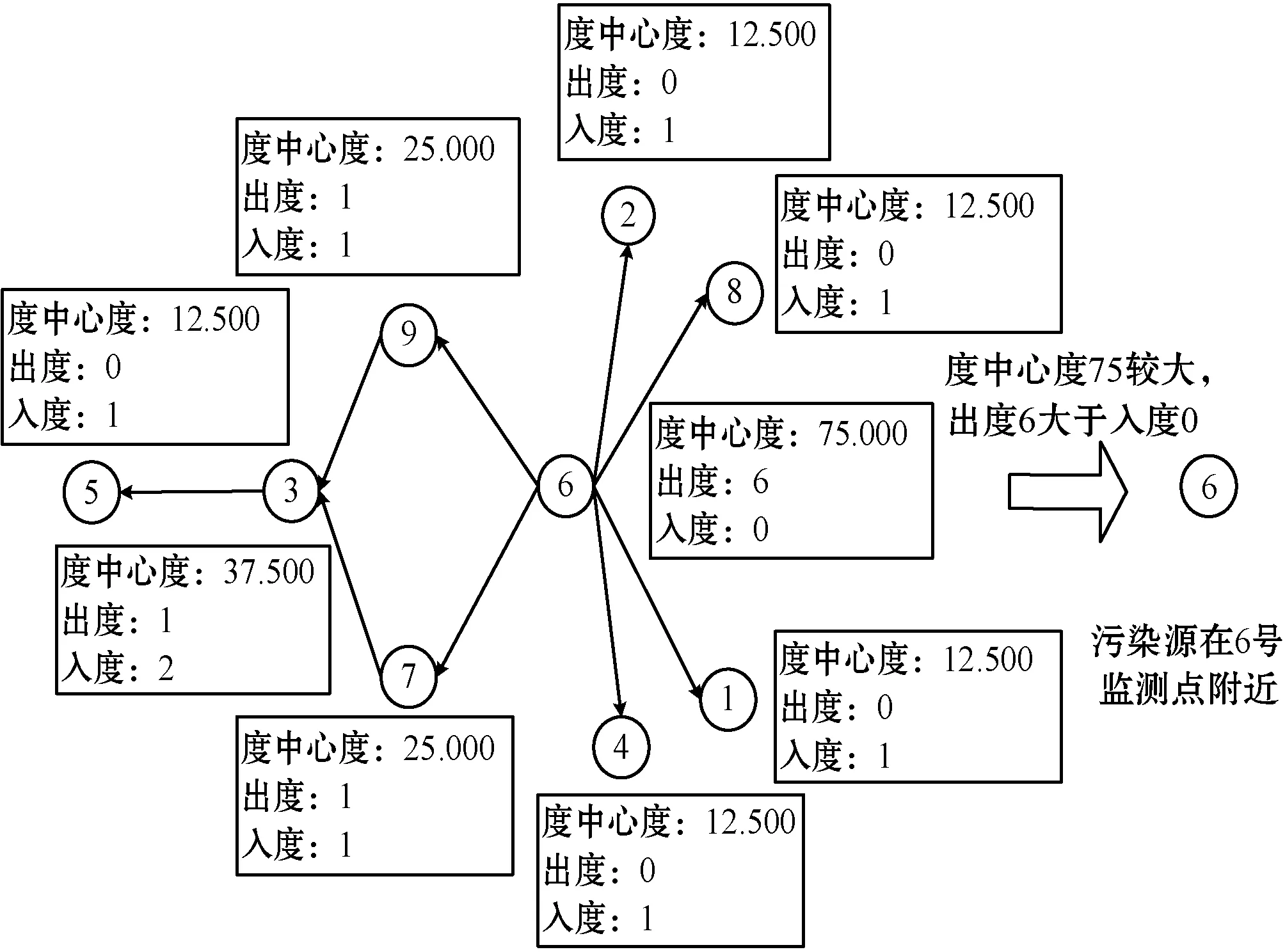
图6 污染源分析示意图
2 实 验
实验所采用的原始数据为2018年3月273个监测点的污染物数据,该污染数据主要包括站点名称、经度、纬度、时间和AQI。
2.1 数据预处理
对各监测点每小时监测到的AQI的数据进行规范化处理,得到各监测点的AQI的时间序列:
(name,x,y,AQIt1,AQIt2,…,AQItn,…,AQItN)
其中,name是监测点的名称;x和y分别是监测点的纬度坐标值和经度坐标值;AQItn是该监测点在tn时刻监测到的AQI的值。
2.2 活跃监测点的筛选
为了降低实验的复杂度,提高污染源定位的效率,需要将一些明显不会对其他站点处的污染产生影响的监测点排除,因此需要对规范化后的大气污染物数据的进行分类处理。
根据下式分别计算n个监测点在各时刻所监测到的AQI的均值AQItE:
(7)
将AQItE与相应时刻第k个监测点监测到的空气质量指数AQIk,t比较,根据结果将监测点划分为不活跃监测点和活跃监测点,划分标准如表1所示。

表1 不活跃与活跃监测点
如图7所示,在每一个时刻,由于不活跃监测点的污染水平都低于所有监测点的污染的平均水平,所以这些监测点处的污染对其他监测点处的污染影响能力较小,而活跃监测点的污染水平高于所有监测点的污染平均水平,这些监测点对其他监测点处的污染影响能力较大,活跃监测点中存在大气污染源的可能性较大,因此利用筛选出的活跃监测点的大气污染物信息的AQI的时间序列数据进行的实验。
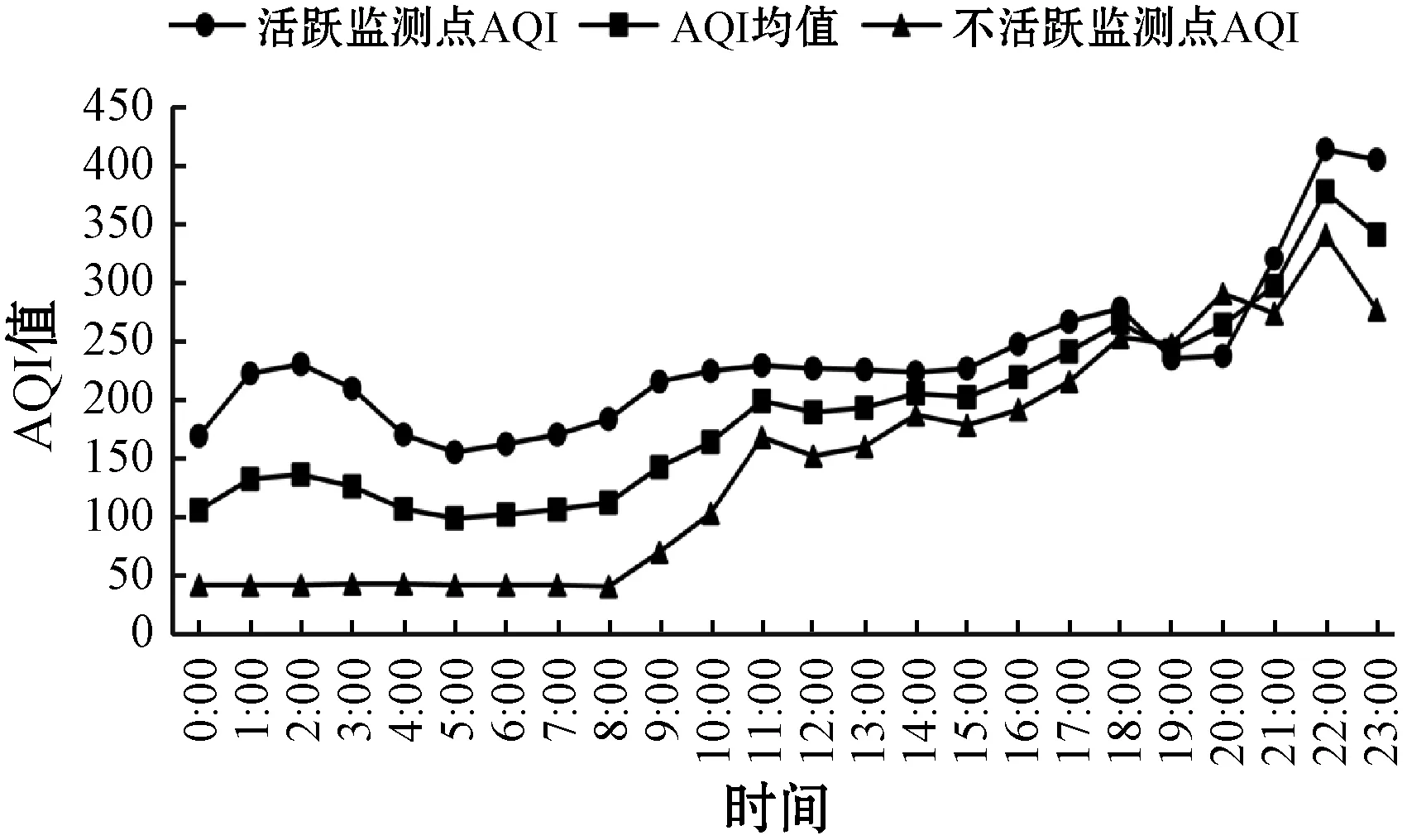
图7 不同类型监测点AQI对比
实验在273个监测点中筛选出210个活跃监测点及63个不活跃监测点。
2.3 实验结果分析
本文对筛选出的210个活跃监测点的AQI时间序列两两之间进行Granger因果关系检验,其中对式(1)中的回归项系数的显著性检验的原假设如下:
原假设1:γ1,i全为0。
原假设2:γ2,i全为0。
对于上述假设的检验结果,根据显著性水平α来确定关联关系。对于原假设1,若式(1)中第一个方程回归项系数的显著性检验结果P值小于α,则表示在α的显著性水平下拒绝了原假设1,否则接受原假设。对于原假设2,若式(1)中第二个方程回归项系数的显著性检验结果P值小于α,则表示在α的显著性水平下拒绝了原假设2,否则接受原假设。若在α的显著性水平下拒绝原假设,则关联关系为1,否则为0。
因此,根据α=5%的显著性水平确定参与检验的两个监测点之间关联关系,部分节点的关联关系矩阵,如表2所示。
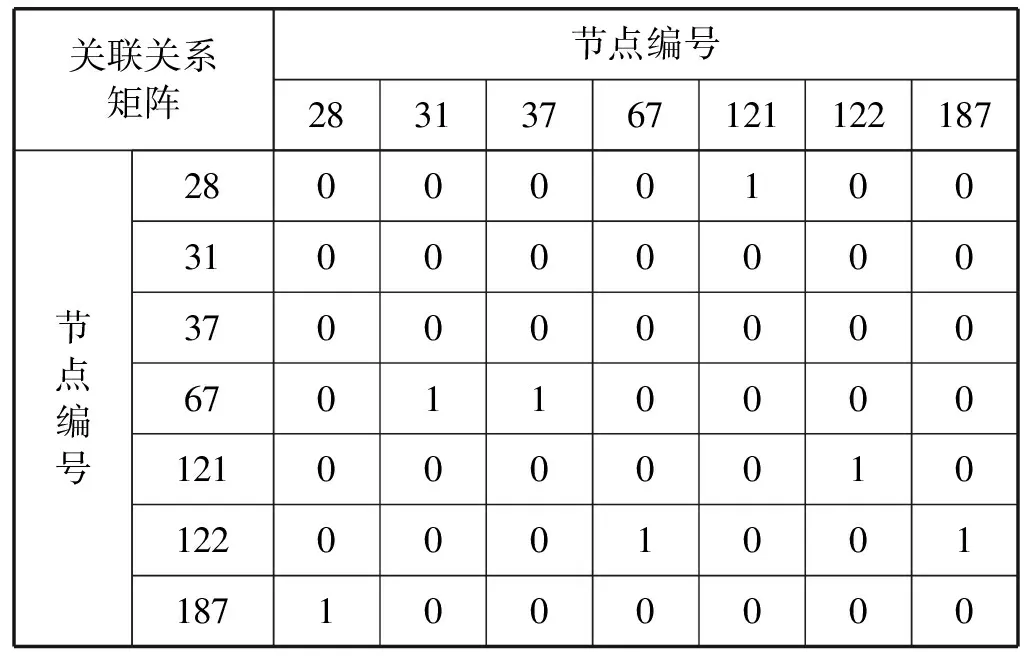
表2 关联关系矩阵表
通过社会网络分析软件Ucinet对关联关系矩阵进行了可视化,得到污染网络图,图8为上述7个节点组成的污染网络图,图9为全部节点组成的污染网络与局部放大图。图中的节点表示监测点,数字表示监测点的编号,有向线段表示监测点间污染的影响关系。
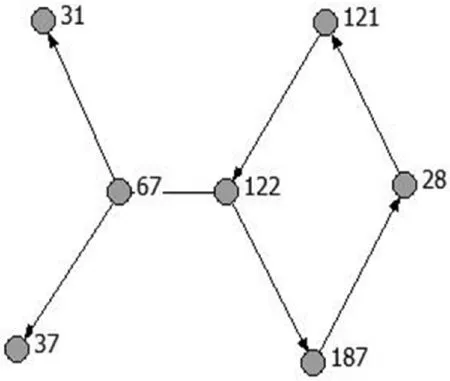
图8 部分节点污染网络图
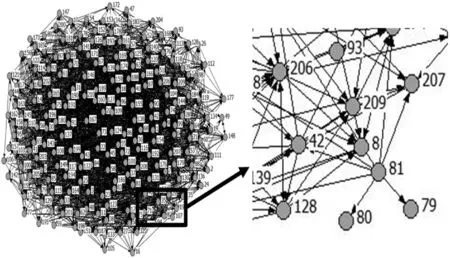
图9 污染网络与局部放大图
以图8中节点为例,用ILPA算法对其进行社区划分,节点的纬度和经度信息如表3所示,节点的更新顺序为节点31、节点37、节点67、节点122、节点121、节点187、节点28。
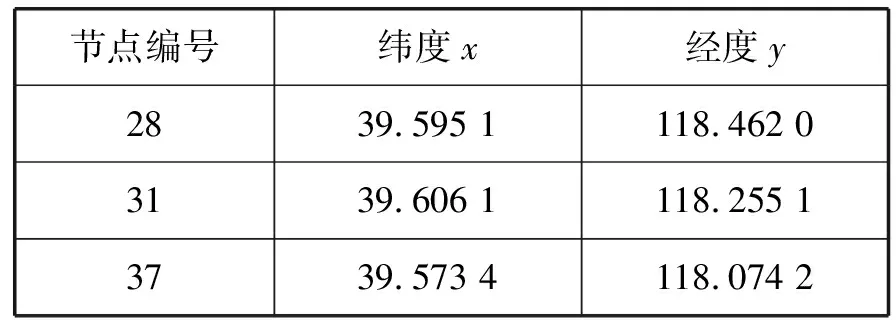
表3 节点经、纬度信息表
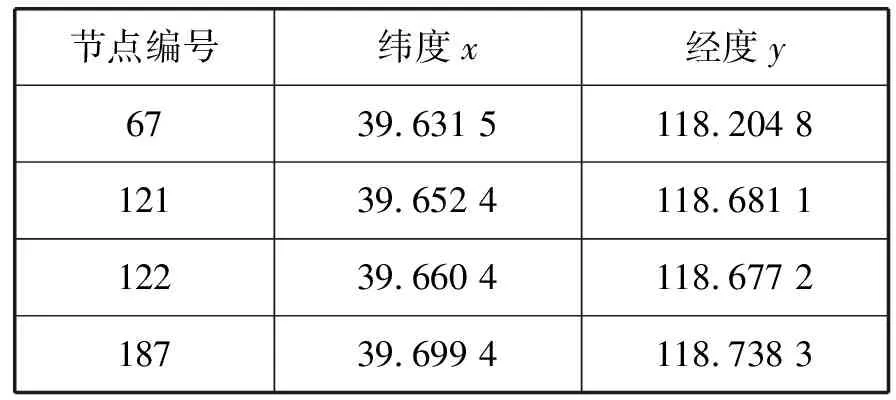
续表3
根据式(5)确定各节点更新后的新标签的计算过程如表4所示。
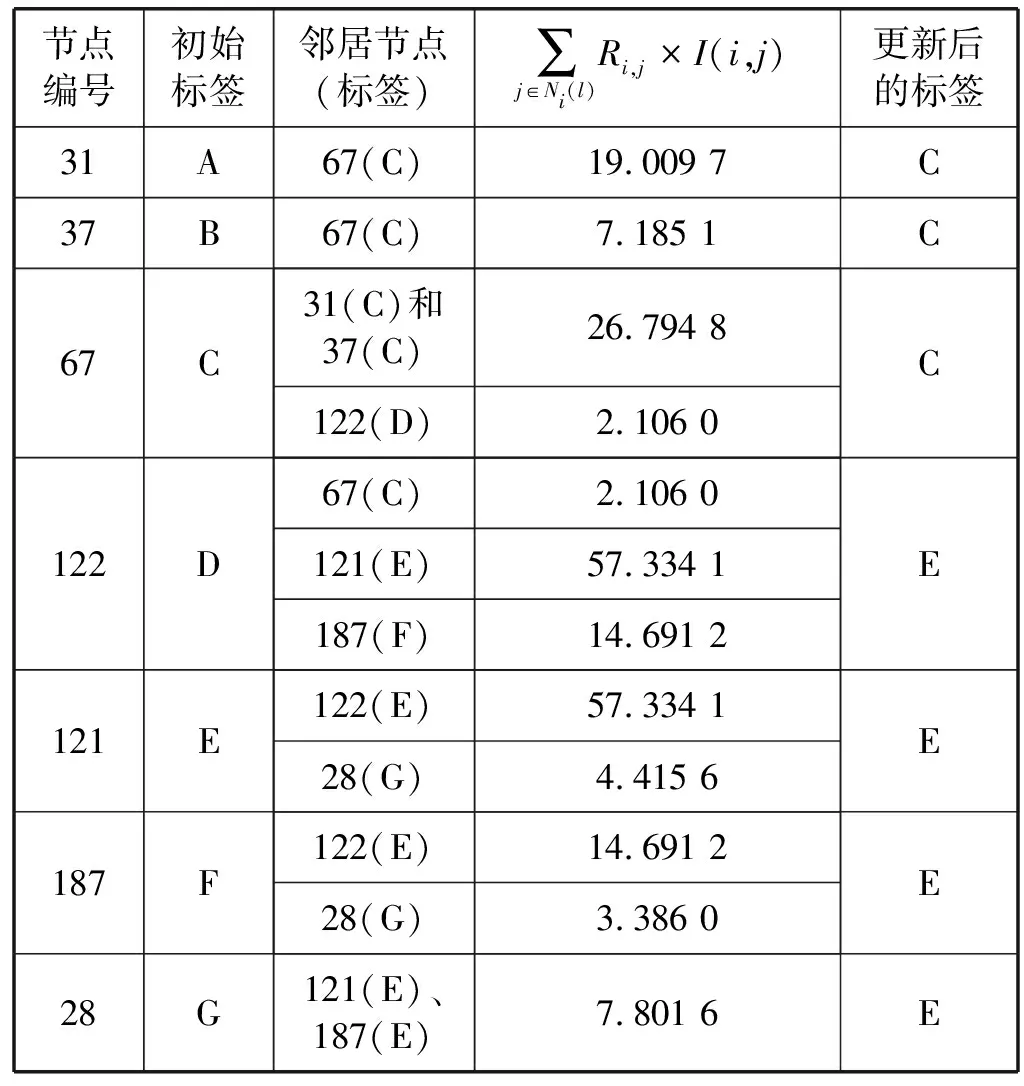
表4 标签更新计算过程表
标签传播过程如表5所示,根据结果最终的社区划分结果为{31,37,67}和{28,121,122,187}。
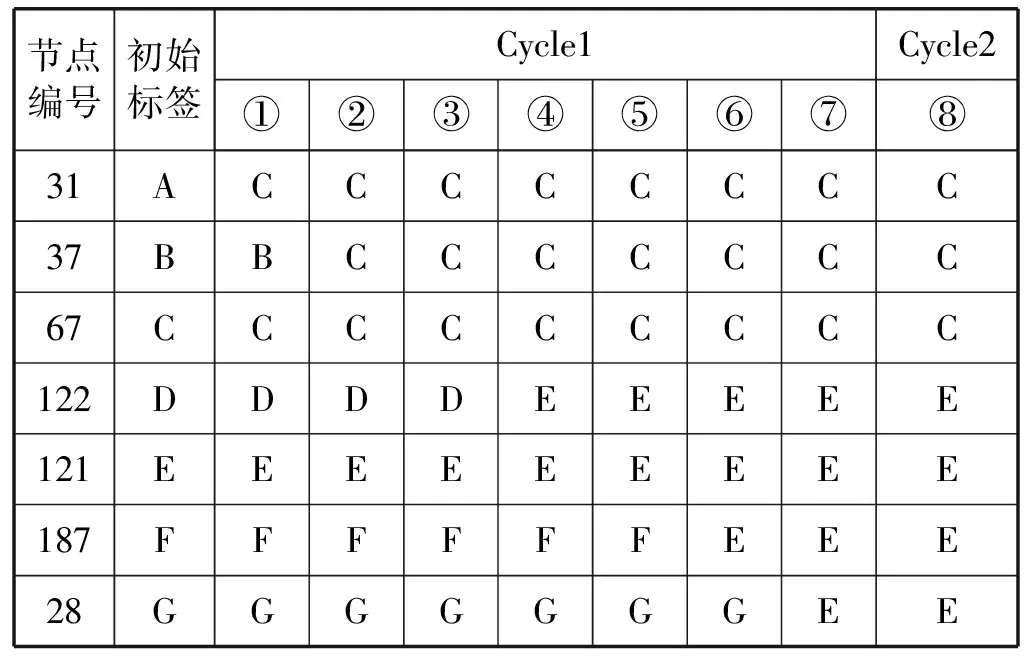
表5 部分节点标签传播过程表
根据ILPA对整体污染网络的划分结果,污染网络中含有4个内部联系紧密污染区域,即整个污染网络被划分成4个污染子网络,此时模块度的值最大为0.647。图10至图13分别表示污染子网络1至4的分布图。
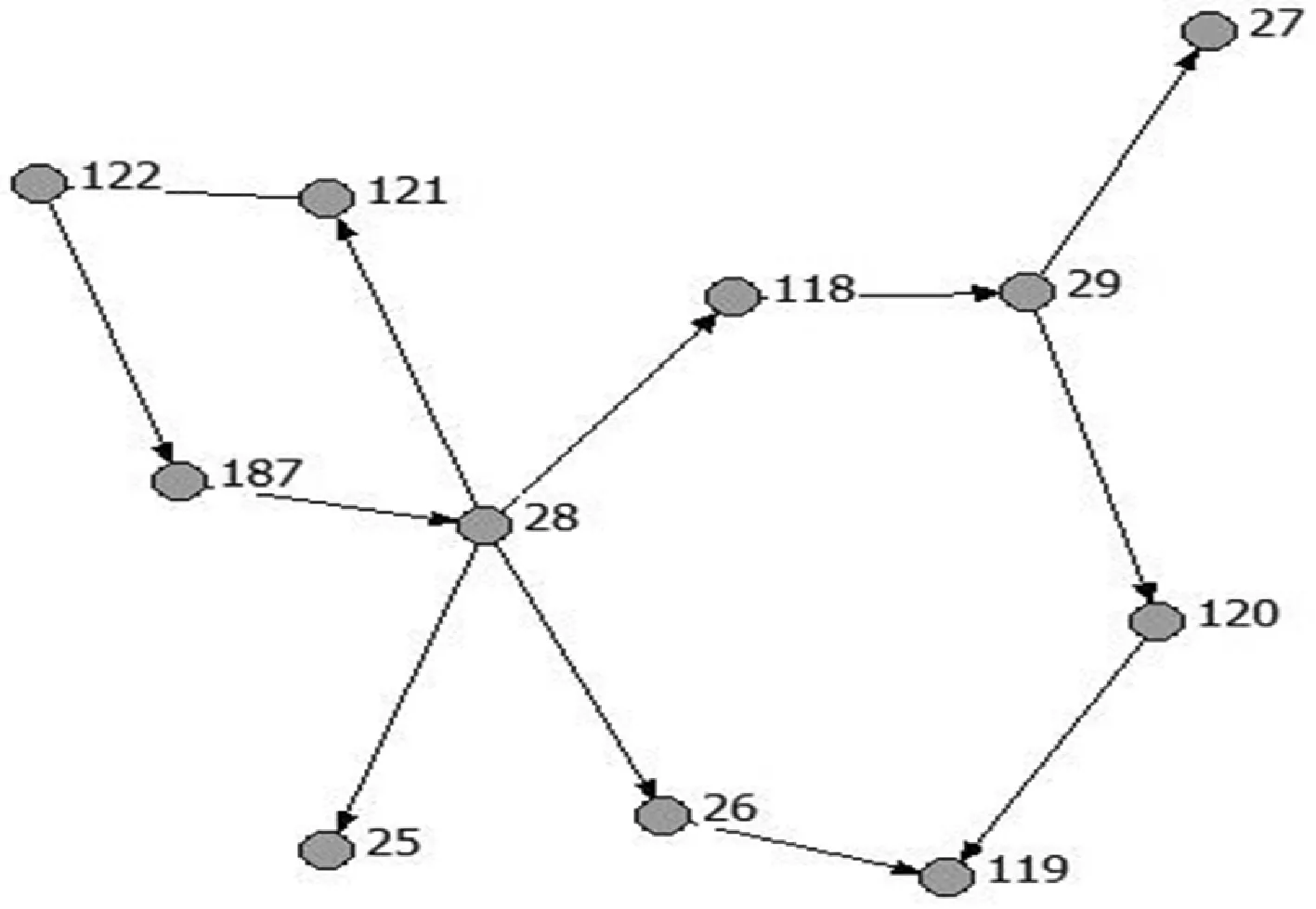
图10 污染子网络1的分布图
图11 污染子网络2的分布图
图12 污染子网络3的分布图
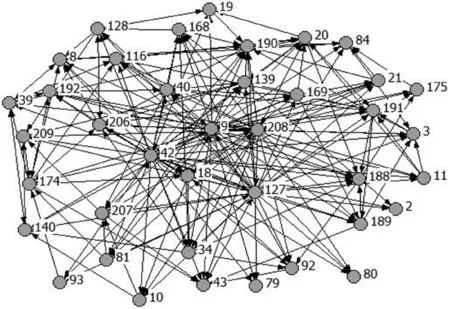
图13 污染子网络4的分布图
结合污染监测网络中各站点的经度和纬度坐标值,对划分的结果进行分析可知,4个污染子网络的主要特征呈现区域性分布,统计结果如表6所示。
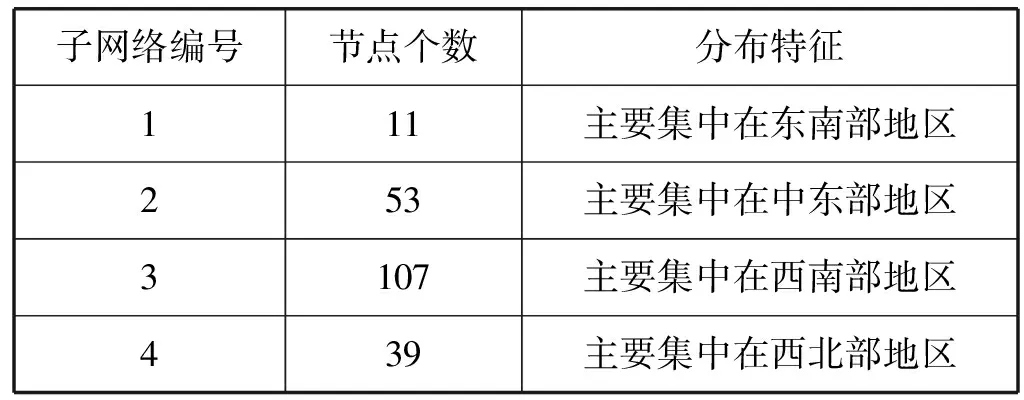
表6 污染子网络特征情况表
根据污染源判断标准,分别对四个子网络计算其节点的度中心度、出度和入度。表7反映了污染子网络1中度中心度排名前10位的节点特征情况。根据污染源判断标准可知,监测点“(28)东海特钢西南”的度中心度较大且出度明显大于入度,说明在子网络1中监测点“(28)东海特钢西南”处于污染的中心位置,与其他监测点的交互影响最为直接,且该站点处的污染情况对其他站点处的污染情况影响最大,则在监测点“ (28)东海特钢西南”附近存在大气污染源。
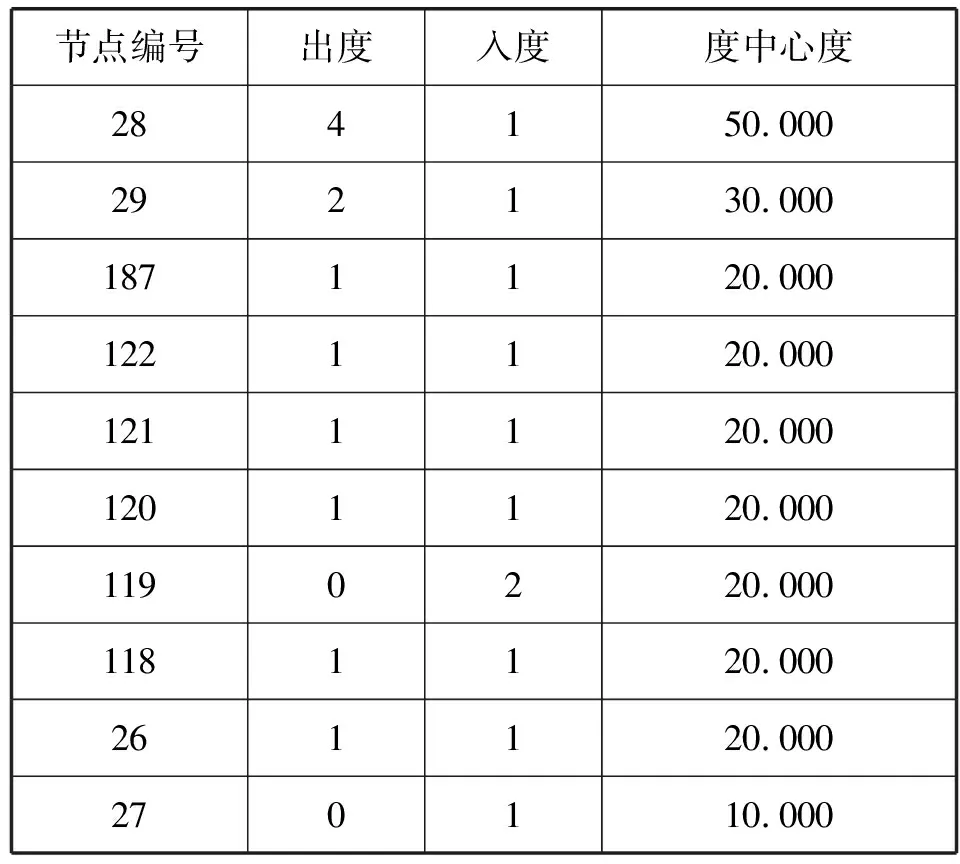
表7 子网络1中节点特征情况表
表8反映了污染子网络2中度中心度排名前10位的节点特征情况。根据污染源判断标准可知,监测点 “(138)三兴化工西北”“(83)冀东水泥三友2号”、“(137)三兴化工东南”的度中心度较大且出度明显大于入度,说明在子网络2中,上述3个监测点处于污染的中心位置,与其他监测点的交互影响最为直接,且这3站点处的污染情况对其他站点处的污染情况影响最大,则在以上3个监测点附近存在大气污染源。
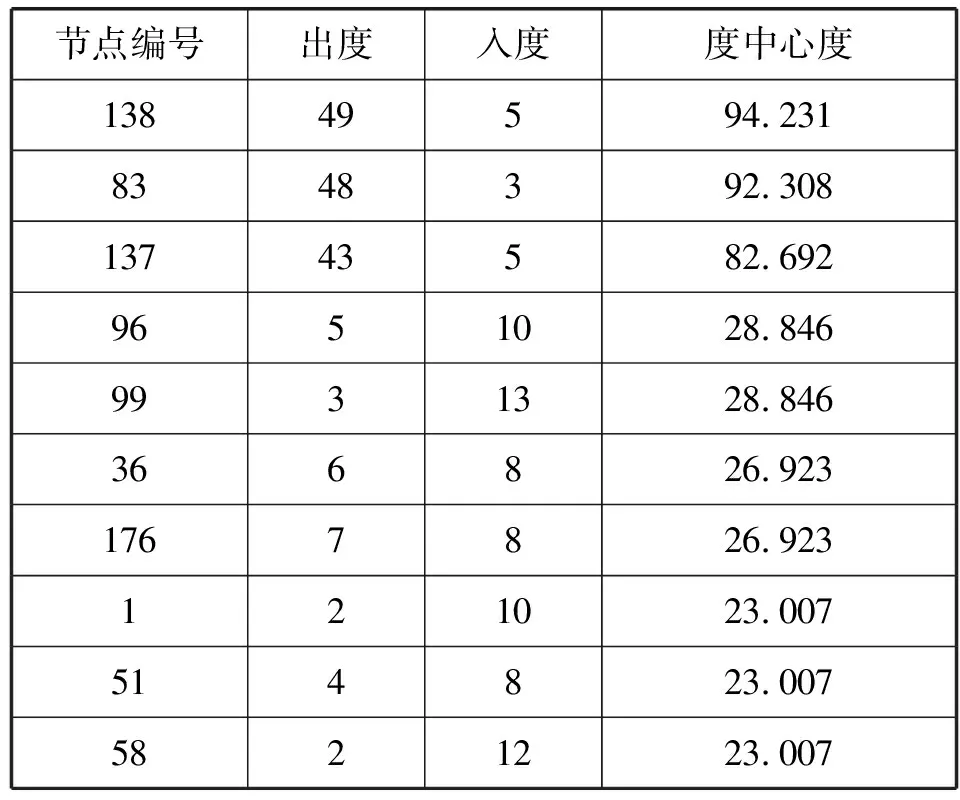
表8 子网络2中节点特征情况表
表9反映了污染子网络3中度中心度排名前10位的节点特征情况。根据污染源判断标准可知,监测点“(146)十二中正南”“(61)国丰钢铁东南”“(72)环城北路与银河路交口东南”的度中心度较大且出度明显大于入度,说明在子网络3中,上述3个监测点处于污染的中心位置,与其他监测点的交互影响最为直接,且这3站点处的污染情况对其他站点处的污染情况影响最大,则在以上3个监测点附近存在大气污染源。
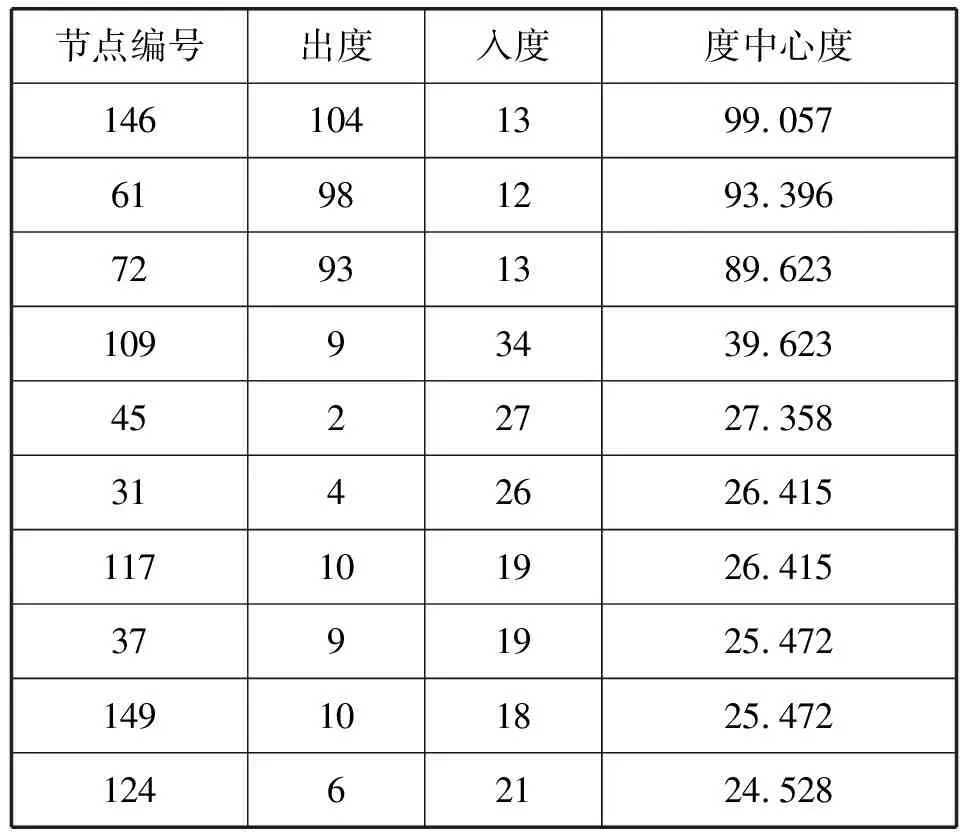
表9 子网络3中节点特征情况表
表10反映了污染子网络4中度中心度排名前10位的节点特征情况。根据污染源判断标准可知,监测点“(42)丰润污水处理厂东南”“(9)曹雪芹西道与G102国道交口”“(127)仁润印刷东南”“(208)中车西北”的度中心度较大且出度明显大于入度,说明在子网络4中,上述4个监测点处于污染的中心位置,与其他监测点的交互影响最为直接,且这4站点处的污染情况对其他站点处的污染情况影响最大,则在以上4个监测点附近存在大气污染源。
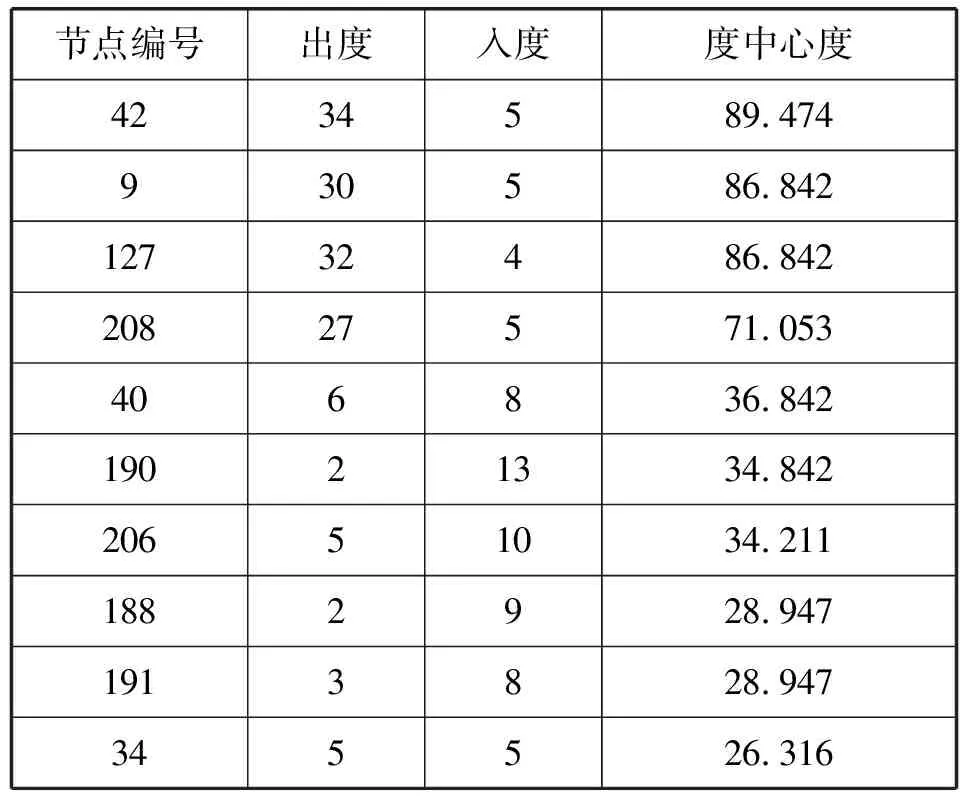
表10 子网络4中节点特征情况表
为了验证实验结果的准确性,查证上述11个监测点处的PM2.5的均值及平均空气质量等级情况,如表11所示。
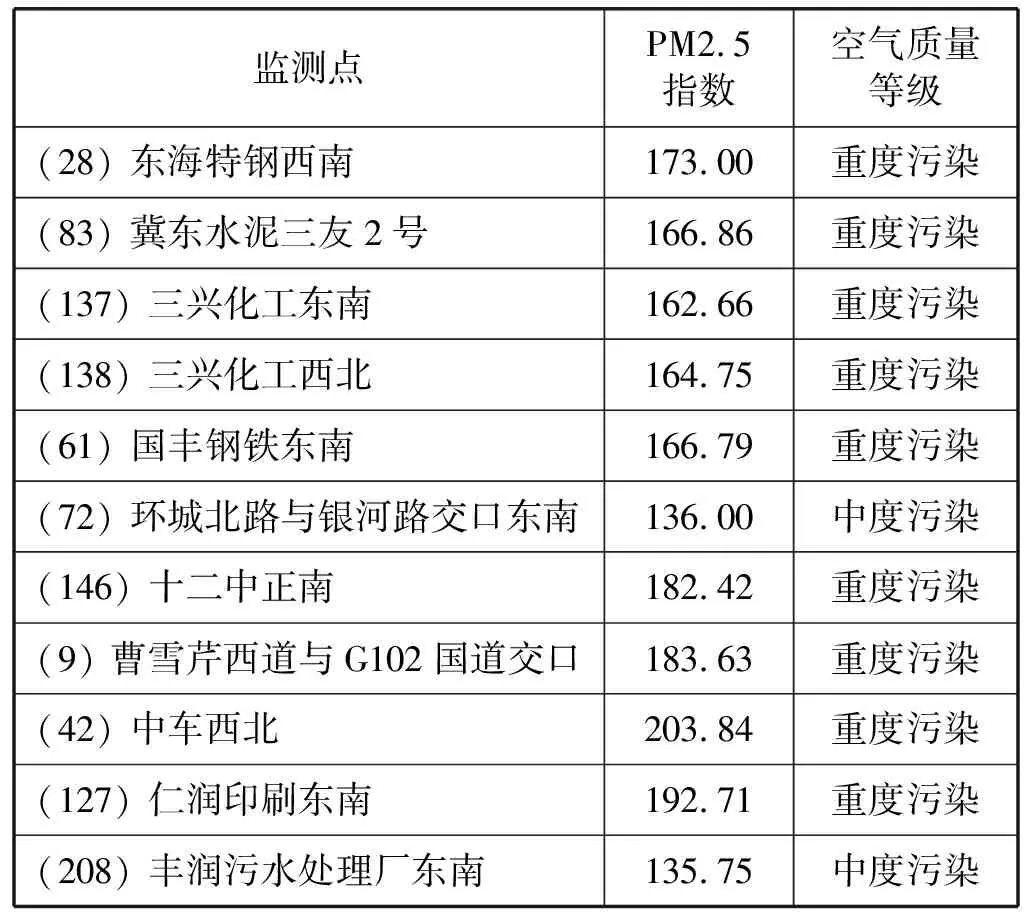
表11 11个监测点的PM2.5情况表
结合表11可知,实验结果较为准确,编号为9、28、42、61、72、83、127、137、138、146和208的11处监测点处的PM2.5值普遍较高,且空气质量等级多为重度污染,因此这些监测点附近存在污染源,在污染治理的过程中,应该着重在这些监测点附近排查污染原因,并采取相关措施进行治理,从而达到从根本上解决大气污染问题的目的。
3 结 语
本文针对多发的大气污染环境问题,提出一种基于社区网络的大气污染源定位算法,该算法利用Granger因果检验法挖掘各监测点之间污染变化的相互影响,然后将影响关系转化为监测点网络结构图,利用社区分析的方法在构建的监测点网络结构图中进行污染区域的划分和污染源的定位。实验表明,本文提出的大气污染源定位算法,不仅能够在复杂的环境中找到相应的污染区域,而且能够将污染源的定位范围进一步精确到具体的监测点附近,从而进行高效、准确的大气污染源定位。
