面向海量数据的相对波速变化计算的并行化方法
2022-02-19司冠南周风余
张 赛 司冠南* 周风余 蔡 寅
1(山东交通学院信息科学与电气工程学院 山东 济南 250300) 2(山东大学控制科学与工程学院 山东 济南 250100) 3(山东省地震局 山东 济南 250014)
0 引 言
目前,相对波速变化的计算在与火山活动和地震相关的地下结构变化研究领域应用非常广泛。波速变化计算的实质就是通过对两接收点上的地震台站背景噪声数据进行互相关运算[1-3],可以提取两点之间的格林函数[4-5],通过测量当前经验格林函数与参考经验格林函数的相对走时偏移来计算相对波速的变化。随着计算机技术与地震学研究的飞速发展,地震台站数量大大增加,测量数据量也急剧增长。传统的串行化处理方式是在单台计算机上多次迭代,实时性较低,处理数据的速度远远落后于数据获取的速度,导致大量的数据无法及时转化为可用的信息,显然这种处理数据的方式已不能满足现有的需求。针对处理海量数据时相比并行方式存在计算速度慢、消耗时间长等问题,将大数据应用到地震行业的数据处理中成为一种趋势。谢玮等[6]基于Hadoop的大数据技术构建的大型地震勘测软件平台。王秀英等[7]利用大数据的研究思想,提出了一种前兆识别方法。张加庆[8]针对传统空间模型在地震数据处理过程中造成地震损失评估结果偏差大的问题,基于大数据设计了一种地震损失价值评估模型。随着数据量的不断增加,数据的存储管理、共享服务达到了性能瓶颈,郭凯等[9]基于大数据技术提出了相应的分布式管理和计算架构。陈湉等[10]根据地震灾区的物资需求和伤员的病情的需要,基于大数据提出了震后物资和人员的调度模型。现阶段,国内外关于波速计算的并行化计算研究较少,可以把大数据应用到波速计算当中,作为一个研究方向。目前一些相关算法的并行化的研究有: Rizvandi等[11]提出了基于hadoop框架实现PKTM算法,通过使用映射规约模式方法把原始地震数据集转换成键值,然后进行数据处理,尽管改进了处理速度,但导致了过多的I/O开销。Kurte等[12]基于多核GPU和MPI的并行方法处理遥感灾害的数据,提出的并行方法虽然可以实现快速处理数据的目的,但是计算过程中进程的开销较大。因此,本文针对常规方法面向海量数据的相对波速变化计算速度较慢的特点,结合Spark[13-15]优势提出一个基于分布式框架[16-17]的模型,将原始地震数据移植到计算框架中,并充分利用并行计算思想加速处理。
1 模型设计
模型设计的目的是将存储在HDFS上的对应波形数据分发到Spark框架的计算节点上进行并行计算来提高相对波速变化计算的速度。
1.1 分布式波速计算流程
分布式波速计算流程如图1所示。

图1 波速计算流程
波速计算流程主要包括以下内容:
1) 对地震原始数据进行数据处理,数据缺失时采用数据插补的方式,即采取前后相邻几个数据的平均值作为插值。
2) 对处理后的数据进行波形的整理,得到所需的SAC文件。
3) 将上述SAC文件进行归一化处理,将分布式归一化后的文件集合作为下一步并行计算的输入。
4) 对上述数据集在Spark平台上并行计算,最后把生成的数据文件存储到HDFS中。
5) HDFS能提供高吞吐量的数据访问,适合存储处理完的大量地震数据文件,用于数据的共享和调度。
1.2 模型主要步骤
1.2.1数据准备阶段
对源数据进行数据处理之后,整理对应波形,得到我们所需的不同时点上的各分量波形SAC文件,之后将两个台站在不同时点上的各分量波形SAC文件一一对应起来,每个时点的对应关系组成一个二元组,形如:
1.2.2分布式时域归一化
传统的波速计算首先在波形中取一系列的小窗口,计算速度扰动前后该窗口内的走时扰动Δτi;根据上述模型,对上述操作中构成的波形对应集合进行分布式处理,方便下一步Spark的模型对归一化的数据进行分布式数据计算,达到快速计算的目的。
1) 以每个二元组为一个数据单元,均匀分布到M=S×C个算法执行队列中并行执行波形数据转换,其中:S为计算节点的数量;C为计算节点的CPU核心数。
2) 提取二元组各波形文件的数据,执行多频段进行时域归一化,并叠加这些归一化的曲线来生成1个宽频带数据,然后进行互相关运算,在时域和频域得到更加均匀的能量分布。
3) 最后每个数据单元形成名为“Station1_Station2_Time .dat”的数据文件,并将所有文件的集合作为输入执行下一步计算,其中:Station1、Station2为台站名称;Time为选取的时点。
1.2.3分布式数据计算
在传统的波速计算中,假设在流逝时间处的小窗口,其长度为2tw,计算窗口内fcur与fref的互相关函数的相位谱φ(f),其相位误差为:
(1)
式中:c为相干系数;Bω为信号的频谱宽度。若窗口内的走时偏移Δτi为常数,则φ(f)的线性函数为:
φ(f)=2πΔτif
(2)
因此可用互相关函数的相位谱的斜率计算Δτi,即:
(3)

(4)
其中:
(5)
针对上述传统的计算波速的问题,提出以下并行计算的框架,此模型设计的分布式计算的框架如图2所示。

图2 分布式计算的框架
1) 数据处理后的数据存储在HDFS中,便于数据资源的调度和共享。
2) Spark框架对数据源的分布式计算,得到最后的结果。
3) 将结果集存储到HDFS中。
上述模型将数据集均匀分布到多个算法执行队列中并行计算。然后按照波速计算的原理,通过以下步骤计算出上述整合的分布式数据集。
1) 将分布式时域归一化所形成的文件集合整合成分布式数据集,数据集的数量应满足:
(6)
M≤S×C,M≤N≤ND
(7)
式中:TA为所有数据集计算总时间;TP为系统进行并行调度的损耗时间;N为分布式数据集的数量;TD为每个数据文件的计算时间;ND为数据文件的数量;M为计算队列数量;S为计算节点的数量;C为计算节点的CPU核心数。TA、N、M未知,且TA需要取值最小。
2) 根据数据文件的数量ND,通过非线性规划法求得N、M的值。
3) 将数据集均匀分布到M个算法执行队列中并行执行。
4) 每个数据文件形成名为“Station1_Station2_.txt”的结果文件。
本文方法的优点在于通过对数据集的划分与算法的调度,并行执行相对波速变化计算,在多个计算节点的支持下可以大大提高相对波速变化计算的速度。
2 实 验
2.1 实验过程
采用50个计算节点进行地震波速计算处理,每个计算节点配置3核心CPU和16 GB内存,数据量分别为131天、181天、231天、281天。
1) 将两个台站LAW和TIA在不同时点上的各分量波形SAC文件一一对应起来。每个时点的对应关系组成一个二元组,形如:
<2019.001_LAW_BHE.SAC, 2019.001_TIA_BHE.SAC>
所有二元组组合起来构成一个波形对应集合,并将此集合作为分布式数据集。
2) 将上述生成的分布式数据集以每个二元组为一个数据单元,均匀分布到150个算法执行队列中并行执行。提取二元组各波形文件的数据,执行多频段进行时域归一化,并叠加这些归一化的曲线来生成1个宽频带数据,然后进行互相关运算,在时域和频域得到更加均匀的能量分布。每个数据单元形成名为“LAW_TIA_2019.001.dat”的数据文件,并将所有文件的集合作为输入执行下一步计算。
3) 将文件集合整合成分布式数据集。经测量,系统进行并行调度的损耗时间为5 min,每个数据文件的计算时间为3 min。数据集的数量应满足:
(8)
M≤150M≤N≤ND
(9)
TA、N、M未知,且TA需要取值最小。根据数据文件的数量,ND分别取值131、181、231、281。
4) 把每个数据文件形成名为“LAW_TIA_.txt”的结果文件,将最终的数据文件整合到一起上传到HDFS中存储,使得数据共享和 I/O 的效率更高。
2.2 结果分析
处理131天、181天、231天、281天分布式、单机MATLAB需要的时间并行化效果如图3所示。

图3 波速计算并行化时间对比
如图3所示,随着时间天数的增加,此方法并行计算得到数据的时间明显小于采用单机MATLAB计算得到相应数据时间,当数据量达到281天的时候,利用本文方法时间为7.5 min,而采用单机MATLAB计算得到相应数据时间为92.24 min,这较好地显示出所设计模型的并发调度的优势,且模型具有较好的稳定性和可扩展性。
图4为分布式与单机时间比的趋势走向。
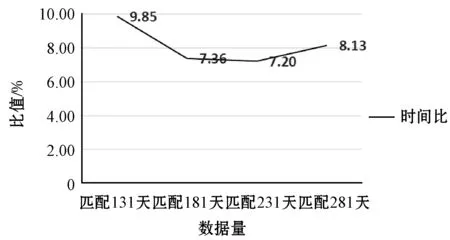
图4 分布式与单机MATLAB时间比
如图4所示,曲线存在整体下降的趋势,说明并行计算的速度较快,从131天的数据量到231天的数据量的过程中,分布式与单机的时间比从9.85%下降到7.20%,分布式与单机的时间比越来越小,与小数据量计算任务相比,大数据量的计算任务的效率更高。181天到231天这段曲线相对平滑,没有明显下降的趋势,原因有以下三点:
1) 两次数据集的数据量比较接近。
2) 等待入队的数据集相差不多,一个为31天的数据集,一个为81天的数据集。
3) 计算节点处理数据的情况相同,没有出现计算节点处理速度过慢或过快的问题。
随着数据量的增加,等待入队的数据集增加,抵消了基于负载均衡并行策略带来的快速计算的效果,可以看到231天到281天分布式与单机MATLAB的时间比出现了上升的趋势,曲线上升的原因有以下两点:
1) 计算的数据集比较大。
2) 处理281天数据集时,有的计算节点处理速度较慢,长时间占据计算节点,导致其他的数据集不能入队进行计算。
图5为基于负载均衡的并行策略。

图5 基于负载均衡的并行策略
由图5可知:
1) 因为该模型采用50个计算节点进行处理,每个计算节点配置3核心CPU和16 GB内存,所以一共150个计算节点。
2) 当对131天的数据集进行计算时,131天的数据可以同时放到150个计算节点中进行计算,这个时候会有19个计算节点空闲出来,导致资源的浪费。
3) 当对181天的数据集进行计算时,前150天的数据集进入队列进行计算,当任意一个计算节点处理完数据空闲出来之后,剩余的31天数据集会基于负载均衡的并行策略及时入队到计算节点完成的队列中去,直到最后计算完成。
4) 当对231天,281天的数据集进行计算时,入队原理同3)。
实验表明,通过对数据集的划分与算法的调度,并行执行相对波速变化计算,在多个计算节点的支持下可以提高相对波速变化计算的速度。
3 结 语
本文从并行化的角度,研究了面向海量数据的相对波速变化计算的方法,以地震波速计算为例,采用了并行计算的思想,利用分布式计算的算法对波速进行了并行计算,解决了传统的串行化相对波速变化计算方法面向海量数据时存在计算速度慢、消耗时间长等问题,此外展示了分布式与单机实现相比的可行性和性能收益。实验表明,随着数据量的不断增加,相对波速变化计算比相对于单机计算效率明显提高。
模型的流程中还存在人工干预的环节,如:1) 数据的处理;2) 计算节点数的选取。今后可以从模型的流程的一体化方向以及计算节点数的选取做进一步的研究。
