基于水化学场与水动力场示踪模拟耦合的矿井涌(突)水水源判识
2022-02-12曾一凡梅傲霜华照来
曾一凡,梅傲霜,武 强,华照来,赵 頔,杜 鑫,王 路,吕 扬,潘 旭
(1.中国矿业大学(北京) 国家煤矿水害防治工程技术研究中心,北京 100083;2.陕西陕煤曹家滩矿业有限公司,陕西 榆林 719000;3. 北矿大(南京)新能源环保技术研究院,江苏 南京 210005)
煤炭是我国重要的基础能源,受制于我国缺油、少气、相对富煤的能源禀赋影响,在今后相当长的一段时间内,以煤炭为主体的能源格局将在我国长期存在[1-2]。随着煤炭资源开采强度、深度、规模和资源量的日益增大,与煤矿开采有关的水害问题愈发突出,由此引发的水害事故也愈发严重[3]。在深入系统地查明矿区水文地质条件的基础上,利用多种方法对矿井涌(突)水进行准确判识是确保煤矿防治水工作有效开展、降低煤矿水害事故损失的前提和基础,对保障煤矿安全生产具有重要意义。
目前,基于不同含水层(水体)水化学特征上的差异性,运用模糊数学[4]、Fisher判别分析[2,5-6]、Piper三线图[7]、距离判别分析[8-9]等多种方法对涌(突)水及其可能来源含水层(水体)的水化学数据进行处理对比分析,是较为常用的方法。随着计算机技术的发展,近年来机器学习,特别是支持向量机(support vector machine,SVM)被广泛应用于矿井涌(突)水的水源判别中[10-12]。另一方面,随机森林(random forest,RF)由于其良好的稳定性和鲁棒性,近年来也被逐渐应用采空区自燃预测、矿井涌(突)水水源判别等方面[13-14]。上述方法本质都是利用数学方法对涌(突)水及其可能来源含水层(水体)的水化学数据进行处理,忽略了涌(突)水可能来源含水层(水体)间的循环演化过程,使判识结果缺少实际水循环情况的支撑与验证;另一方面,上述方法仅对来源进行判识,缺少对实际采矿过程中涌(突)水现象与矿井立体水文地质模型等结合。因此,笔者提出一种基于水化学场机器学习分析与水动力场反向示踪模拟耦合的矿井涌(突)水水源综合判识技术,结合陕西榆林曹家滩煤矿工程背景,在已有数据资料的支撑下,利用水文地球化学的原理和方法对矿井涌(突)水及其可能来源含水层(水体)的水化学特征进行分析,一方面利用特征上的相似性,定性对涌(突)水来源进行判识,另一方面水化学特征方面的分析赋予了机器学习定量判识结果的实际意义;此外,结合实际情况,建立地下水渗流场,利用GMS软件中MODPATH反向示踪涌(突)水水源,实现了涌(突)水路径的可视化及对水化学机器学习判识结果的验证,为矿井涌(突)水来源判识提供了一种新的思路。
1 研究区概况
陕西省榆林市曹家滩煤矿,地处陕北黄土高原北部,鄂尔多斯高原东北部,毛乌素沙漠东南缘,为沙丘沙地和风沙滩地、黄土梁峁地貌。曹家滩煤矿位于我国西北内陆,为典型的温带干旱、半干旱大陆性季风气候,多年平均降水量535.51 mm,多年平均蒸发量1 916.1 mm,蒸发量远大于降水量[15]。曹家滩煤矿内NW—SE向的分水岭大致将矿区潜水划分为东西2个面积大致相等且相对独立的水文地质单元,西南部属榆溪河流域,东北部属秃尾河流域。煤矿东南有属秃尾河支流的野鸡河、高羔兔沟两小沟流,为季节性沟流,在沟流的下游因老乡农灌截流常出现断流,区内原有一些海子多数已经干枯,现存的一些海子水位不深,蓄水量不大。

按照含水介质的不同,曹家滩井田含水层自2-2煤层向上可分为侏罗系中统延安组第5段孔隙裂隙承压含水层、侏罗系中统直罗组孔隙裂隙承压含水层、侏罗系中统安定组孔隙裂隙承压含水层、风化岩基岩裂隙承压水含水层、第四系中更新统离石黄土弱含水层和第四系上更新统萨拉乌苏组孔隙潜水含水层。隔水层主要是新近系保德组红土,其次为基岩中的泥岩和粉砂岩。其中,保德组红土为研究区隔水性能较好且较稳定的隔水层,其沿分水岭两侧最厚,自东向西、西南逐渐变薄。位于井田东翼的122108工作面和西翼的122109工作面所开采的2-2煤煤厚均为10 m左右,同为综采放顶煤开采工艺且已完成回采,2个工作面面积相近,分别为1.67,1.56 km2。但根据涌水量数据统计显示,井田东翼122108工作面平均涌水量约为341.21 m3/h,而西翼122109工作面平均涌水量约为758.33 m3/h,涌水量差异较大。笔者尝试通过基于水化学场机器学习分析与水动力场反向示踪模拟耦合的矿井涌(突)水水源综合判识技术,对两工作面的涌水来源进行判识。其中,122109工作面走向方向剖面示意如图1所示。
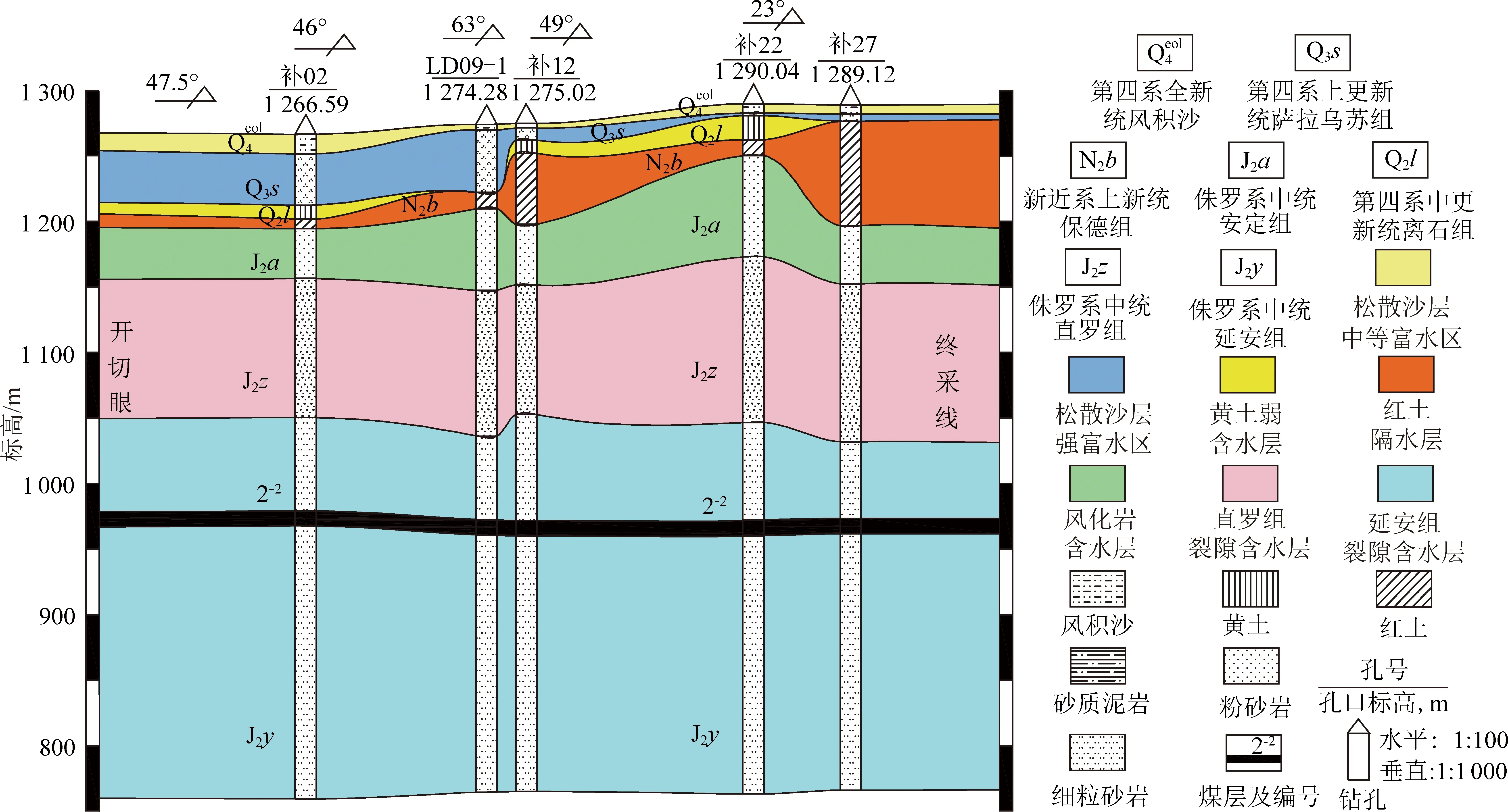
图1 122109工作面走向水文地质剖面示意Fig.1 Hydrogeologic profile of No.122109 working face advancing direction

2 研究区地下水化学特征成因分析
地下水中各离子的质量浓度是不同含水层信息表征的载体,具有化学指纹识别的功能[2]。不同含水层地下水与含水介质发生着不同的水文地球化学作用,使其具有不同的水化学特征,这些差异是水化学特征可作为水源判别依据的根本原因。涌(突)水水源判别中,掌握当地水化学特征的成因,了解不同含水层之间的演化关系,是保证判别结果准确的基础。
2.1 水化学参数统计特征
运用SPSS软件对研究区地表水和各含水层地下水水样的水化学成分进行统计分析,结果见表1。
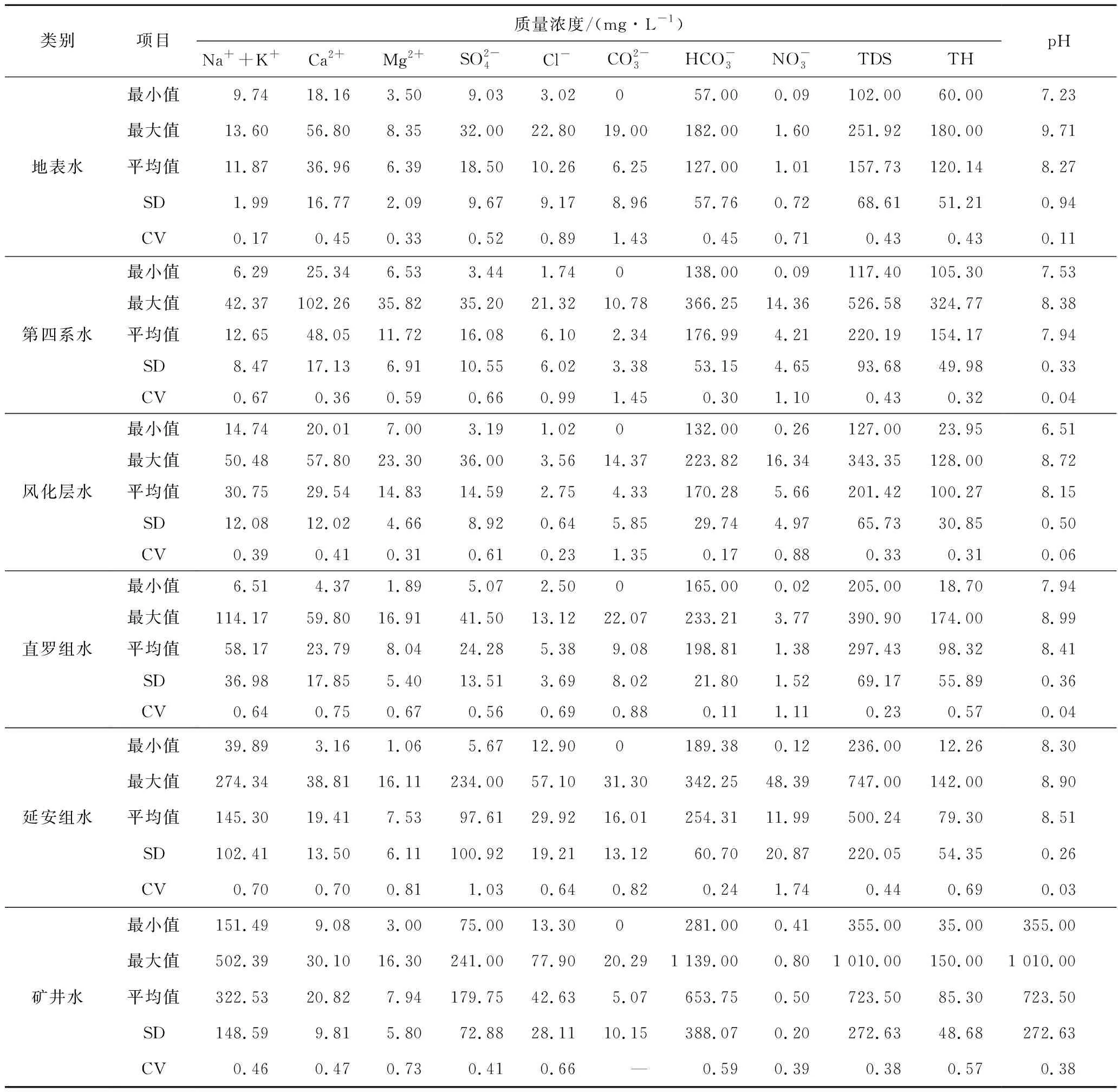
表1 水化学参数统计特征值Table 1 Statistical summary of hydrochemical parameters

2.2 水化学参数相关性分析

表2 研究区地下水水化学参数相关性系数矩阵Table 2 Pearson’s correlation coefficients of groundwater chemical parameters in study area
2.3 水化学类型及其空间分布
研究区各含水层地下水的Piper三线图(图2)显示,从空间上来看,研究区内地表水和各含水层地下水中阳离子主要成分变化较大,地表水和第四系地下水以Ca2+为主导,风化层水无主导阳离子,直罗组水分布覆盖Ca2+主导、无主导和Na++K+主导3种情况,延安组水分布覆盖无主导和Na++K+主导2种情况,矿井水以Na++K+为主导,随着水样深度的增加,阳离子含量呈现由Ca2+为主导过渡到Na++K+为主导的趋势。
从图2中读取了它们的水化学类型见表3(M801,M802和M901,M902分别为122108和122109工作面涌水)。地表水和第四系水的水化学主要类型均为HCO3-Ca型(75%和69%),代表这2类水之间水力联系较强。风化层水的水化学类型比较复杂,没有占明显主导作用的水化学类型,部分阳离子以Ca2+(Mg2+)为主导,部分阳离子以Na+(K+)为主导,也可能是由于部分地区存在红土薄弱区,使风化层水与第四系水存在水力联系。直罗组水的水化学类型以HCO3-Na(50%)为主,可能和阳离子交替吸附作用及硅酸盐矿物的溶解有关。

表3 研究区水样水化学类型统计Table 3 Statistical table of hydrochemistry types in study area
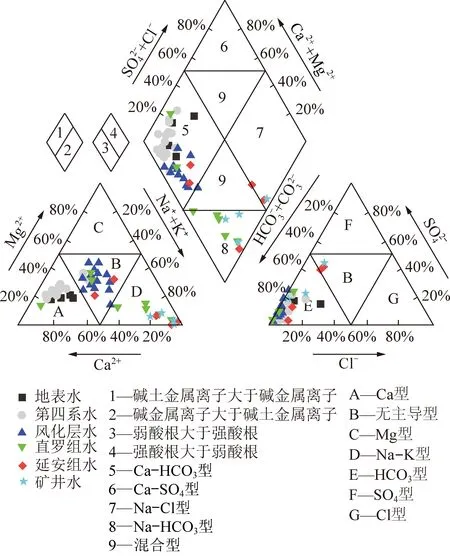
图2 研究区地表水和地下水Piper三线图Fig.2 Piper diagram of surface water and groundwater in study area
延安组的水化学类型主要为HCO3·SO4-Na(40%)和HCO3-Na·Mg·Ca(20%),可能和含水层中石膏的溶解以及Ca2+,Na+发生阳离子交替吸附作用有关。矿井水中122108,122109工作面水化学类型主要为HCO3-Na,矿井水的水化学类型与直罗组和延安组地下水的水化学类型相近,与地表水和第四系水的水化学类型不同,与部分风化层水的水化学类型相似。初步判断,矿井水来源于直罗组和延安组裂隙含水层的补给,可能有少量风化层水的来源。
3 机器学习判别模型
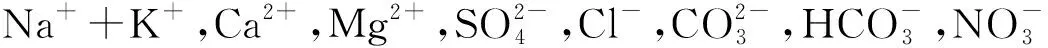
SVM基于统计学习理论基础和结构风险最小化原理实现模式分类和非线性回归[18]。对于模式分类问题,其主要思想是建立一个超平面作为分类的决策曲面,使类域边界之间的隔离距离最大,进而将不同类别数据分开。SVM的结构如图3所示,其中K为核函数,种类主要有线性核函数、多项式核函数、径向基核函数和sigmoid核函数等。本文中SVM核函数选取最为常见且已被证实具有最优水源判别能力的径向基核函数[11],其形式为
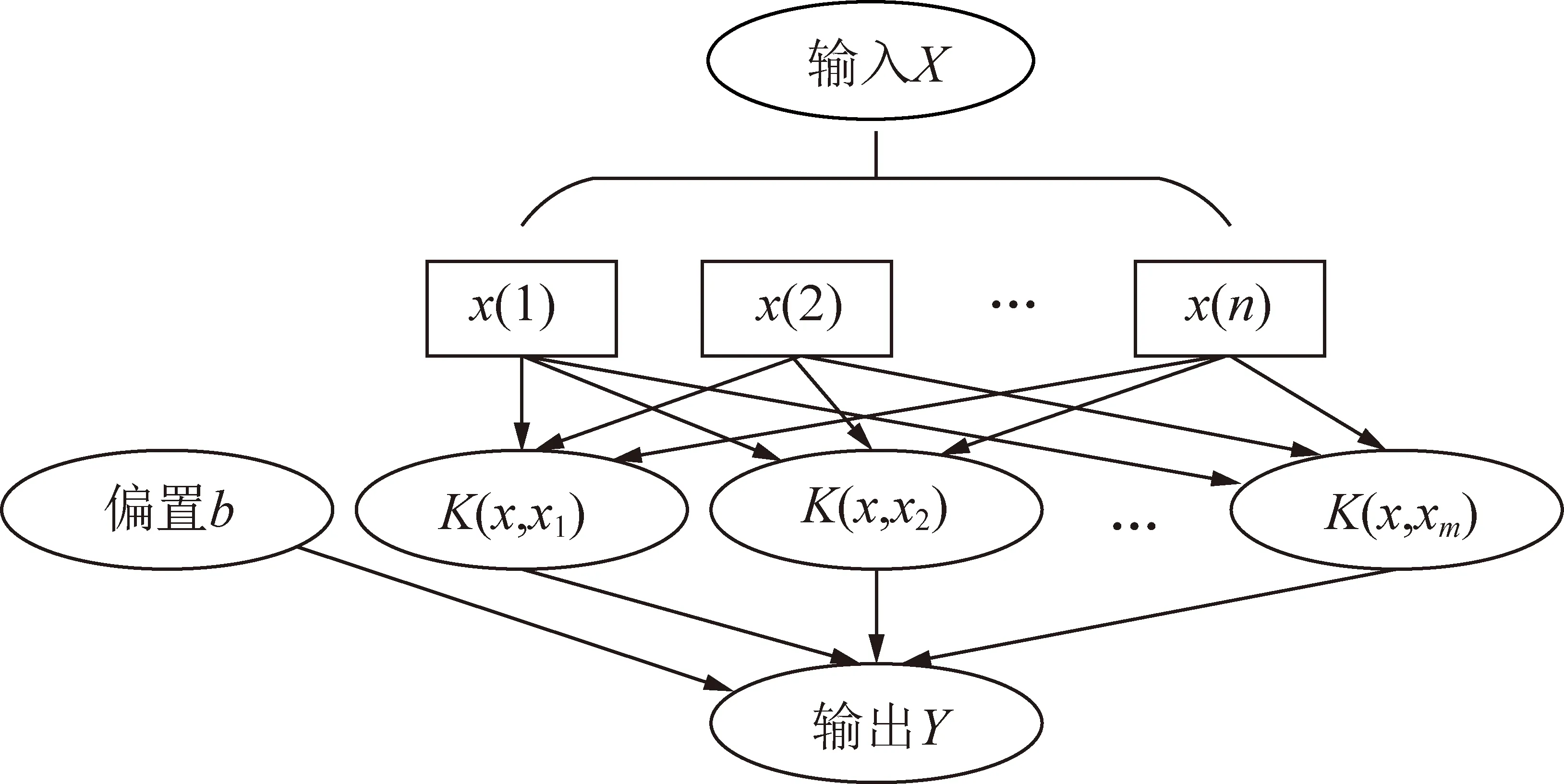
图3 SVM结构示意Fig. 3 SVM structure diagram
(1)
式中,σ为核宽度。
RF是一种包含若干个决策树的模型,这些随机树的形成采用的是随机的方法。其基本原理是输入测试数据后,首先让每一个决策树进行单独分类,最后选取分类结果最多的那个类别作为最终输出结果。RF结构如图4所示,具体流程:
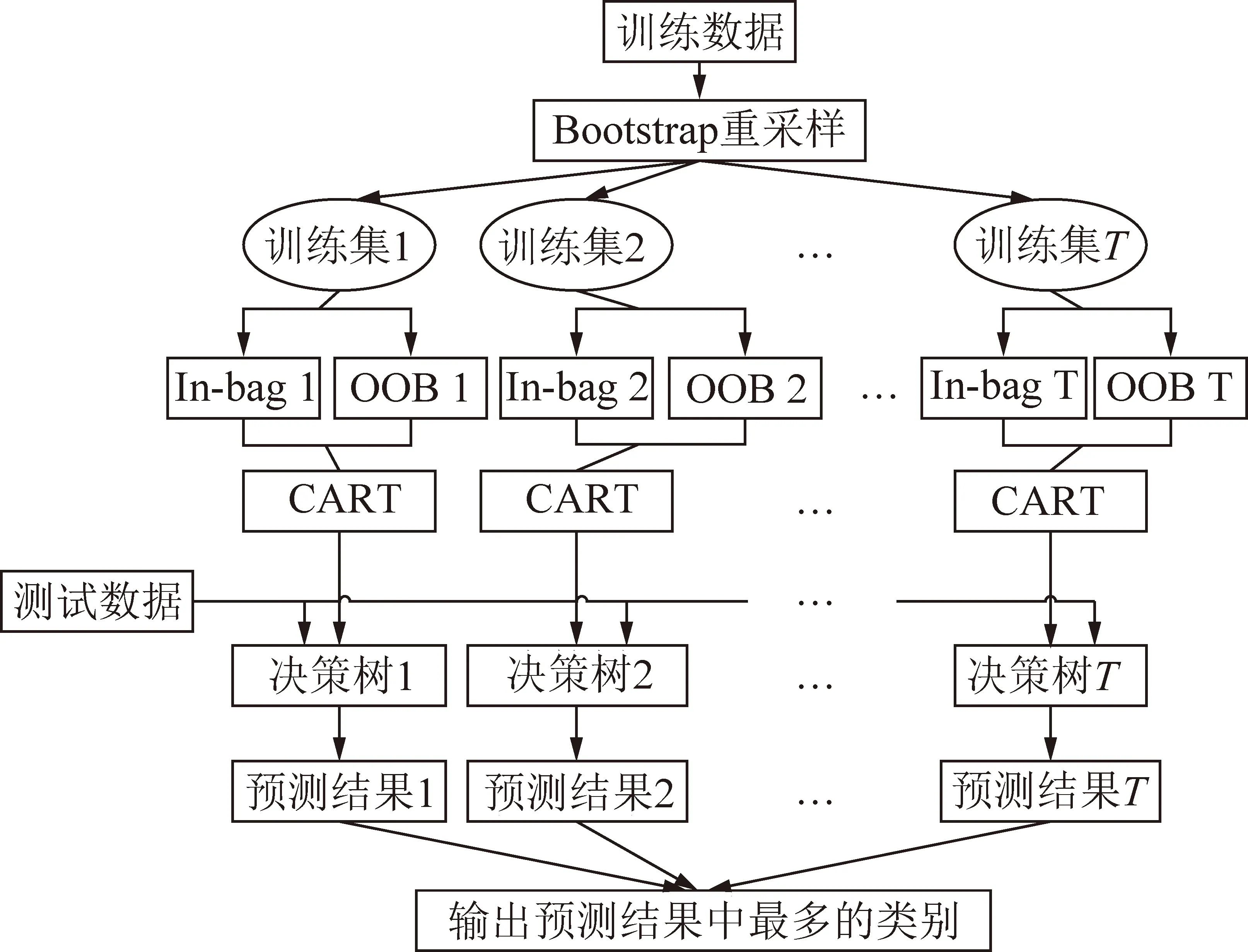
图4 RF模型计算流程Fig. 4 RF model calculation process
(1)重采样。利用bootstrap方法对训练数据进行重采样,随机产生T个训练集,每次没有被抽到的训练数据组成T个袋外数据(out-of-bag,OOB),抽到的训练数据为袋内数据(In bag);
(2)生成决策树。从每个训练集样本中的M个属性中随机挑选m个属性,作为节点分裂属性集,然后从属性集中选出最优属性进行节点分裂,构建出每个训练集对应的CART树,且每棵树都保持完整成长,不进行任何裁枝,即m保持不变;
(3)决策。由于每个CART树在训练集选择和属性选择上都是随机的,因此,这T个决策树是独立的,将测试集输入每个决策树,得到T个预测结果,对于分类问题,利用少数服从多数的原则,选择输出结果最多的类别为测试集所属的类别。
3.1 数据预处理
数据是否采用归一化处理,以及不同的归一化方式对模型的准确性有着不同的影响[19]。交叉验证(Cross Validation,CV)是一种测试分类器性能的统计分析方法,其基本原理是将原始数据在某种意义下分组,一部分作为训练集,一部分作为验证集,然后用训练集训练出分类模型并用验证集检验模型的准确率。其中K折交叉验证(K-fold Cross Validation)的方法可以有效避免欠学习或过学习状态的发生,能得到具有说服力的结果。笔者利用K折交叉验证对不同数据预处理方式得到的模型验证集准确率进行计算,进而对不同归一化方式进行选取。结果(表4)表明,RF和SVM采用[-1,1]归一化方式对本文的数据进行预处理,可以有效提高模型的精度。
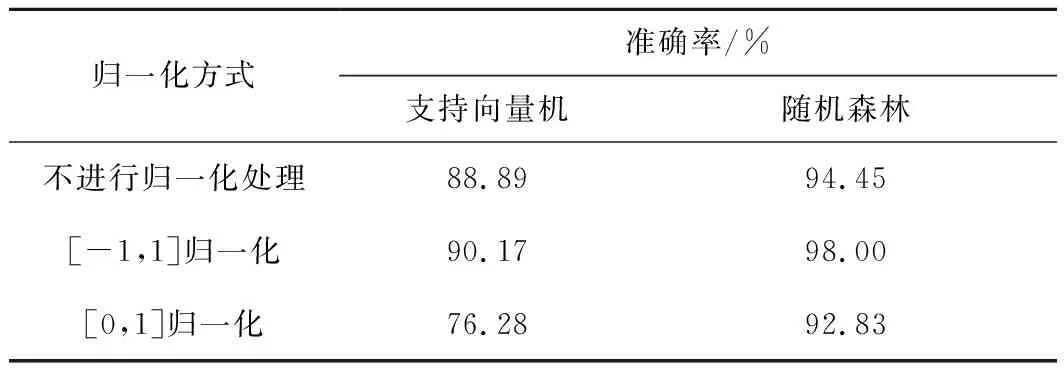
表4 采用不同归一化方式准确率对比Table 4 Accuracy comparison of different normalization methods
3.2 模型参数的选取优化
在使用SVM做分类预测时,需要调整惩罚系数c和核函数参数g,以得到比较理想的分类准确率。与传统的网格搜索(Grid search)算法寻优相比,启发式的遗传算法(Genetic Algorithm,GA)寻优不必遍历网格内的所有参数点,具有较强的鲁棒性,且已被证实可以在复杂的参数空间中快速选取到最佳c,g值[10,12]。因此,笔者利用GA算法对SVM的参数进行优化,建立参数优化的GA-SVM模型。利用LIBSVM工具箱[20]、Sheffield遗传算法工具箱和gaSVMcgForClass函数[21]实现惩罚系数c和核函数参数g的寻优,计算得到最优惩罚系数c=1.996 8,最优核函数参数g=4.093 6。
由RF模型的计算流程可知,每棵决策树在生成时,没有被抽到的样本数据被保留在了OOB子集中,利用OOB子集数据中的样本可以计算得到每棵树的OOB错误率,则模型中所有决策树的OOB错误率均值可以对RF模型的性能进行评价。此外,在决策树生长过程中,节点预选变量m过多可能导致模型过拟合,预测精度下降[13]。笔者利用MATLAB对不同决策树棵树T和节点预选变量m对应的OOB错误率进行计算,结果如图5所示。由图5可以看出,随着决策树棵数的增加,运算量增大,但是OOB错误率的降低并不明显,因此,本文所使用的RF模型中选取决策树棵数T=150,节点预选变量m=1。
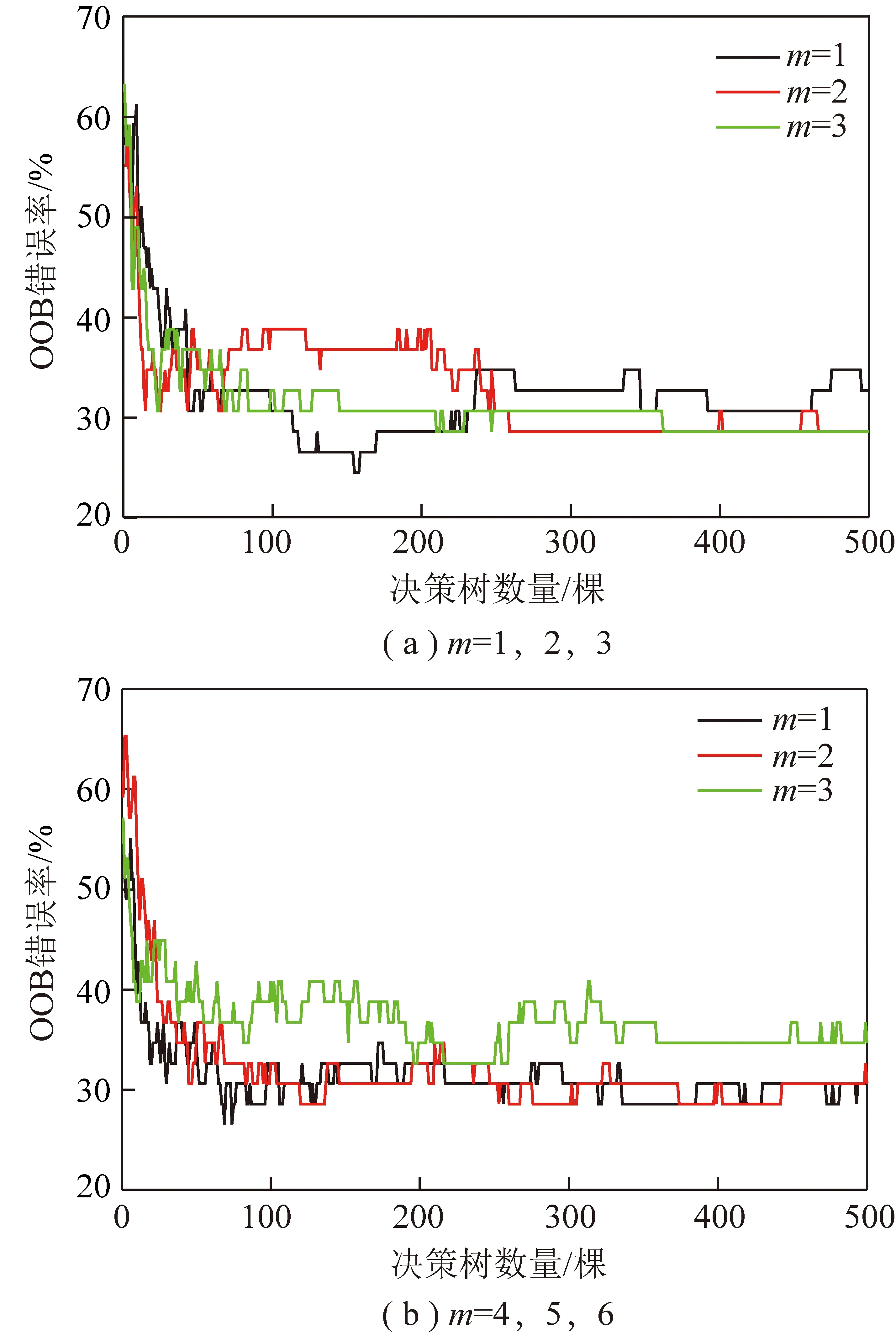
图5 随机森林OOB错误率Fig.5 OOB error rate of random forest
3.3 模型选取与水源判别
将原始数据输入模型进行10次十折交叉验证,得到GA-SVM模型和RF模型的训练集与验证集准确率如图6和表5所示。
从图6可以看出,GA-SVM和RF的训练集和验证集准确率均处于高位,说明2种模型的预测分类结果均具有一定的可信度。GA-SVM的训练集正确率在接近100%处小范围波动,验证集的正确率在接近100%处波动较大,产生了较大的预测误差,RF训练集正确率均为100%,验证集正确率在接近100%处小范围波动,说明与GA-SVM相比,RF可以更好地降低噪声对预测分类结果的影响,具有更好的鲁棒性,也说明了RF具有优于GA-SVM的稳定性。从表5可以看出,RF的训练集准确率和验证集准确率分别为100%和98.00%,分别高出GA-SVM训练集和验证集准确率1.37%和7.83%。此外,SVM在进行模型训练时,参数c和g对模型分类准确率影响较大,需要额外利用GA算法等方法对其进行优选,增加了模型的复杂度,而RF无需复杂的参数设置和优化便能得到较为满意的性能,且决策树为非线性处理器,可将RF视为若干个非线性关系组合形成的更为复杂的非线性关系处理器。总之,[-1,1]归一化后的RF模型在研究区矿井水水源判别方面与GA-SVM相比具有更优的性能。
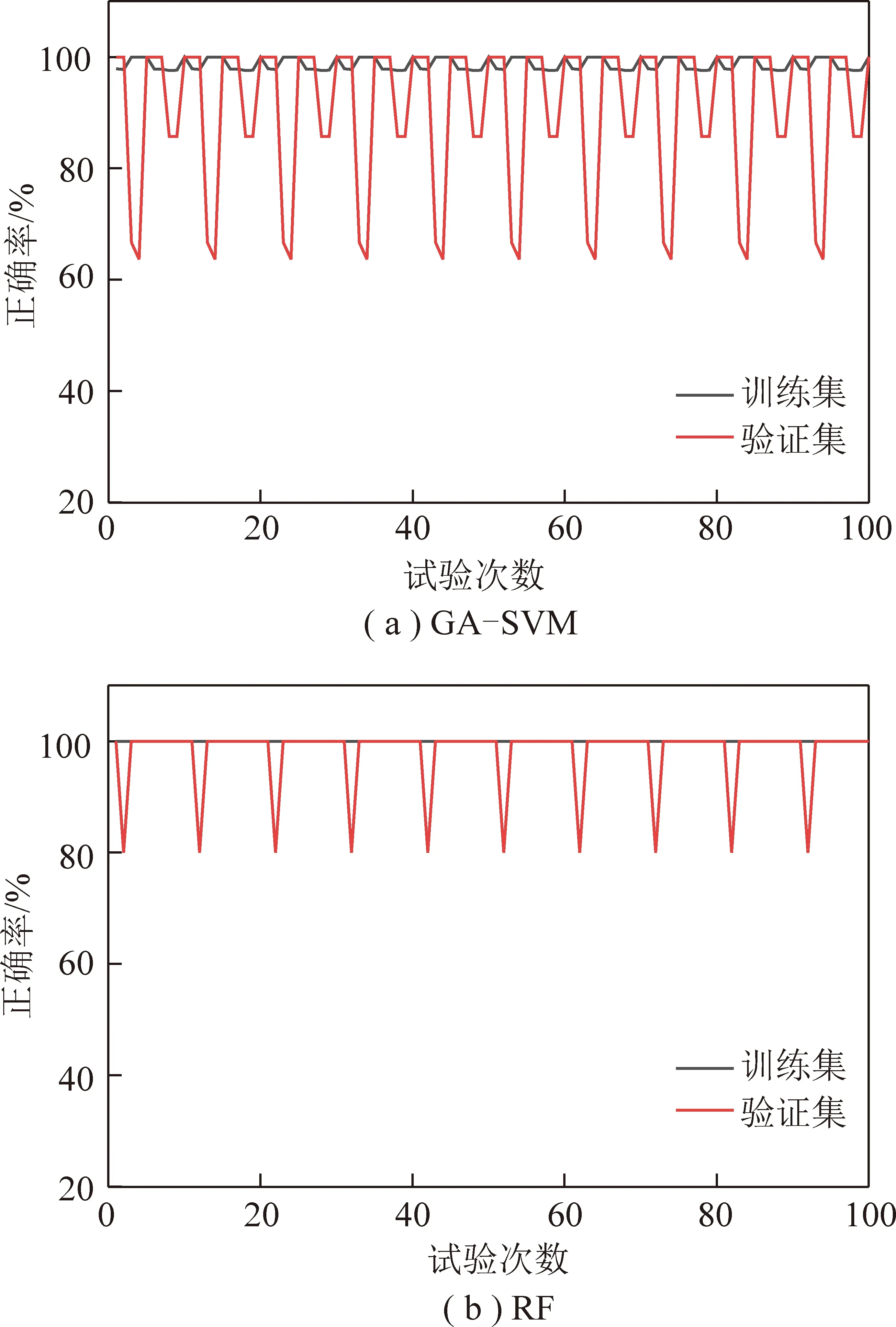
图6 GA-SVM和RF10次十折交叉验证结果对比Fig.6 Comparison of GA-SVM and RF 10-fold cross validation results

表5 10次十折交叉验证正确率对比Table 5 Comparison of 10-fold cross validation accuracy
将待判别的122108和122109工作面的矿井水水化学数据进行[-1,1]归一化后输入训练好的RF模型,即可快速得到预测结果。RF利用各个决策树对数据进行预测分类,且每个决策树给出一个预测分类结果,将每个预测分类结果与所有预测结果的比值称为得分,得分最高的那个预测分类结果即为最终预测类别。预测结果见表6,可以看出,122108工作面矿井水主要来源于直罗组水和延安组水,122109工作面矿井水主要来源于第四系水。
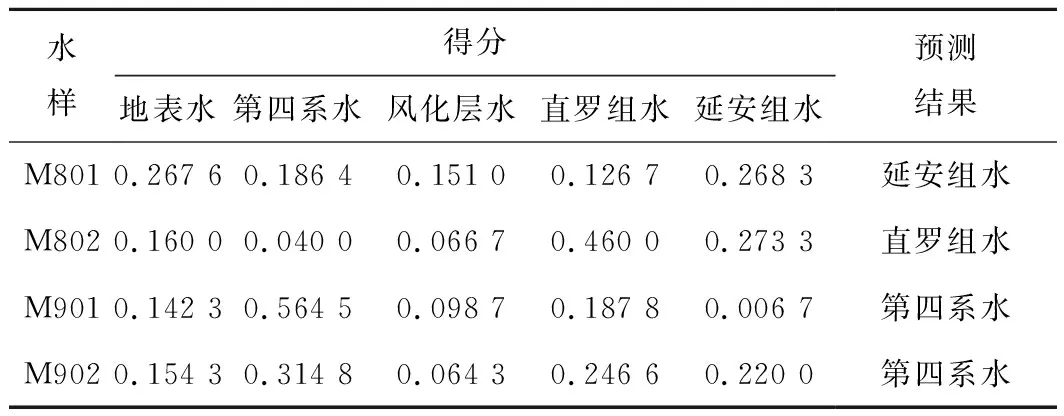
表6 RF预测结果Table 6 RF prediction results
4 剖面数值模拟
水文地球化学和机器学习的方法,分别对研究区涌(突)水水源进行判别,然而2种方法在122109工作面M901和M902水样的判别结果上出现了差异。下面将利用渗流场模型可视化示踪的方法,利用GMS软件建立研究区典型二维水文地质剖面渗流场数值模型,进一步对M901和M902的涌水来源及通道进行判别与可视化输出。
4.1 典型剖面选取
研究区分水岭西部潜水总体向西南方向径流,研究区红土层下部裂隙承压水径流方向基本顺岩层倾向由东向西南方向运移。另一方面,根据勘探钻孔揭露,研究区红土隔水层在西部存在薄弱区。典型剖面的选取主要目的是从地下水动力学方面分析122109工作面矿井水垂向来源于第四系地下水补给的可能性,并尝试给出补给路径,因此所选取的剖面应大致沿地下水径流西南走向,且穿过研究区西部红土薄弱区和122109工作面并靠近M901和M902取样点位置。为了尽可能满足研究目的,结合研究区钻孔的分布情况,选取SW-NE方向22.1°的剖面为研究剖面(图7)。
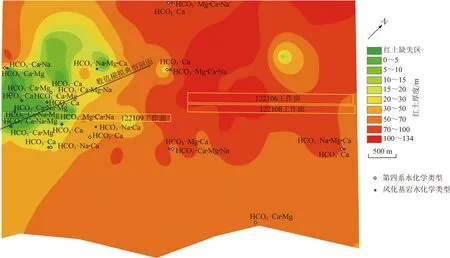
图7 第四系与风化基岩水水化学类型与红土厚度分布示意Fig. 7 Indications of hydrochemical types of Quaternary and weathered bedrock and thickness distribution of laterite
4.2 剖面地下水数值模型建立
由于本次剖面模拟的目的是分析矿井涌水来源和路径,不考虑地下水随时间改变而变化的情况,且所选剖面上含水层在水平上无明显分带,在垂向上不同深度的岩性有一定的分层性,因此将剖面结构概化为非均质各向异性稳定流地下水系统。垂向上概化为6层,即第四系含水层、保德组红土隔水层、风化基岩含水层、直罗组含水层、延安组第五段含水层和煤层。模型的上部边界,由于萨拉乌苏组含水层水量丰富且剖面附近长观孔监测数据显示水位半年波动仅为0.19 m,因此,将剖面上部边界视为定水头边界。模型的下部定义为隔水边界,东部和西部为控制整个剖面内地下水的流向,设置为定水头边界。由于稳定流中地下水水位不随时间发生变化,因此,初始水头对模型流场无影响,设置为与地表高程一致。模型水平长5.8 km,垂向上标高在948.66~1 288.32 m,因此,将模型Y轴(水平方向)剖分为583列,X轴(厚度)剖分为2列(11.23 m),Z轴(垂直方向)剖分为31层,共计36 146个活动单元格。通过反复调参,使剖面渗透系数符合附近历次抽水试验成果并与岩性变化规律相对应,且剖面流场形态与实际流场形态相一致,最终利用GMS软件运行后,得到煤层开采前等水位线分布如图8(a)所示。

图8 开采前后典型剖面水头分布情况Fig. 8 Water head distribution of typical section before and after mining
4.3 采动后涌水来源情况模拟
煤层开采影响下,顶板岩体中,上部岩体的移动变形小于下部岩体,因而采空区上方的岩层会自下而上发育导水裂隙带和弯曲下沉带。其中导水裂隙带自下而上可分为垮落带和断裂带。根据岩层的断裂、开裂及离层发育程度及导水能力,可以将断裂带区域自下而上进一步分为严重断裂区、一般开裂区和微小开裂区(表7),其中垮落带高度约为导水裂隙带高度的1/4,严重断裂区和一般开裂区高度约为导水裂隙带高度的1/2,微小开裂区高度约为导水裂隙带高度的1/4[22]。煤层上覆岩体的断裂变形也会造成其渗透率发生变化,随着与开采煤层垂直距离的增加,导水裂隙带的渗透系数增加幅度逐渐减小,变化幅度由上至下均为开采前的1~10倍[22-26]。

表7 断裂带分区情况[22]Table 7 Fractured zone division[22]
通过在122109工作面施工的“两带”钻孔的手段,以钻进过程中冲洗液漏失量、钻孔内水位变化、岩芯鉴定、钻孔电视等多种方法,综合确定122109工作面垮落带最大发育高度为53.99 m,波及到延安组含水层;断裂带最大发育高度为215.01 m,波及到风化基岩含水层。因此,结合导水裂隙带分区情况及导水裂隙带渗透系数变化情况,将模型对应导水裂隙带发育高度下部1/4位置、中部1/2位置和上部1/4位置渗透系数分别设置为原有10倍、5倍和2倍。此外,根据研究区附近已有红土层采动前后压水试验成果,虽然导水裂隙带未波及到红土层,但应力的改变也导致了其渗透系数变为开采前的10倍[27],将模型对应层位渗透系数也进行调整。而红土层上覆第四系松散沉积物主要成分为细沙和少量亚沙土、亚黏土,位于弯曲下沉带,研究区已有成果表明在采动影响下,其渗透性变异程度不大,模型中对应渗透系数不做调整[28-29]。将调整后的参数输入至模型中,使用GMS软件中的Drain模块模拟煤层开采后的情况,利用MODPATH模块的反向示踪功能对煤层开采后的涌水来源进行模拟,其中开采后水头分布情况如图8(b)所示,122109工作面矿井水来源路径情况如图9所示。
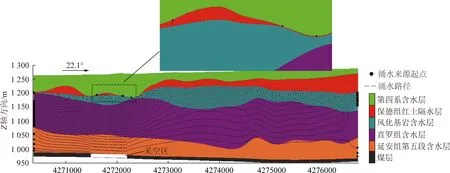
图9 开采后涌水来源判识示意Fig.9 Source identification diagram of water inflow after mining
从模型计算结果可以看出,开采后,典型剖面流场较开采前发生了明显变化,受煤层开采影响,采空区附近含水层水头明显降低。MODPATH模块反向示踪计算结果显示,在红土薄弱区存在第四系水越流并通过导水裂隙带补给矿井水的情况。
5 讨 论
根据水文地球化学特征相似性和随机森林方法的判识结果,122108工作面矿井水的主要来源为直罗组和延安组含水层地下水。此工作面北部紧邻的122106工作面“三带”发育规律研究项目,通过理论分析、现场实测、物理相似模拟及数值计算等方法,综合确定导水裂隙带最大发育高度为162.0 m,波及到直罗组地层,与水文地球化学和随机森林方法判识结果吻合。可以确定122108工作面矿井涌水的主要来源为直罗组和延安组含水层。
水文地球化学特征相似性判识122109工作面矿井水主要来源为深层直罗组或延安组含水层地下水,而随机森林方法判识结果显示其主要来源为第四系含水层地下水。通过引入典型剖面二维地下水数值模拟的方法,发现存在第四系含水层地下水通过红土薄弱区和缺失区及导水裂隙带涌入122109工作面的情况。研究区内保德组红土结构致密,半坚硬状,透水性差,分布连续,是较为稳定的隔水层。因此,当导水裂隙带发育至安定组风化基岩含水层时,红土层是否可以有效阻隔第四系水越流补给安定组风化基岩含水层,直接影响到122109工作面矿井水是否存在第四系含水层地下水作为来源。收集整理研究区范围内各类钻孔共129个,插值生成煤矿矿权范围内红土厚度分布图,并将收集整理的水化学数据中,存在坐标的14个第四系含水层取样点和14个风化基岩含水层取样点投射至红土厚度分布图,最终成图如图7所示。
从图7可以看出,研究区红土分布情况为中部及东部较厚,厚度可达50~134 m;而研究区西部红土较薄,厚度普遍在50 m以下,且存在红土缺失区,经计算,缺失区面积为1.13 km2。由前文分析可知,研究区第四系地下水中阳离子为Ca2+,而风化层水无主导离子。结合图水化学类型分布情况来看,在中部和东部红土较厚区,风化层水中Ca2+质量浓度不大,其与临近的第四系水水化学类型存在明显差异,而在红土薄弱区,特别是在红土缺失区,风化层水中Ca2+质量浓度显著增加。经进一步计算发现,研究区第四系水中Ca2+毫克当量百分比平均为61.60%,红土厚度15~134 m处Ca2+毫克当量百分比平均为31.77%,而红土厚度0~15 m处Ca2+毫克当量百分比平均为40.82%。对比分析判断,在西部红土缺失区和薄弱区,第四系含水层与风化层水之间存在水力联系。考虑到红土缺失区域与122109工作面存在重叠,重叠面积为0.17 km2,因此,在红土缺失区域内,存在第四系含水层地下水通过导水裂隙带涌入122109工作面的情况,这与随机森林判识和典型剖面二维数值模拟判识结果相吻合。水文地球化学特征相似性判识122109工作面涌水来源为直罗组或延安组含水层地下水,可能是因为判识过程仅参照了K+,Na+,Ca2+,Mg2+等常规离子质量浓度,忽略了pH、TDS、总硬度和总碱度等理化指标,导致判识结果出现误差。此外,在实际生产过程中,122108工作面平均涌水量约为341.21 m3/h,而122109工作面平均涌水量约为758.33 m3/h,达到122108工作面涌水量的2.22倍,结合122109工作面上部存在0.17 km2红土缺失区,且第四系萨拉乌苏组含水层水量大的特点,综合判断122109工作面涌水主要来源于第四系含水层地下水。
6 结 论
(2)通过十折交叉验证方法,得出RF方法正确率为98.00%,优于GA-SVM的90.17%。此外,SVM需要额外利用GA算法等方法对参数c和g进行优选,增加了模型的复杂度,而RF无需复杂的参数设置和优化便能得到较为满意的性能。因此,利用RF得出122108工作面涌水来源于直罗组和延安组含水层地下水,而122109工作面涌水来源于第四系含水层地下水。
(3)选取122109工作面取样点附近典型剖面,利用反向示踪原理,结合曹家滩矿水文地质条件、工程地质条件和抽水试验渗透系数等信息,建立MODPATH矿井涌(突)水渗流场可视化模型,实现涌水路径的可视化输出,并对RF判识结果进行验证。结果显示,122109工作面在红土薄弱区和缺失区位置,存在第四系含水层地下水通过导水裂隙带涌入工作面的情况。
(4)基于水化学场机器学习分析与水动力场反向示踪模拟耦合的矿井涌(突)水水源综合判识结果,结合工程实例进行讨论验证分析,发现判识结果与工程实际情况相吻合,证明该方法具有较高的准确性和可信程度。最终判断122108工作面涌水来源于直罗组和延安组含水层地下水,122109工作面涌水来源于第四系含水层地下水。判识结果可为曹家滩煤矿以后防治水工作的开展提供参考依据。
