基于LDA和卷积神经网络的半监督图像标注方法*
2022-01-24王保成刘利军黄青松
王保成,刘利军,黄青松,2
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500; 2.云南省计算机技术应用重点实验室,云南 昆明 650500)
1 引言
随着科技的快速发展,人们已经不再满足于文字形式的情感分享,更多地选择使用图像来表达自己的情感,这使得网络中图像的数量与日俱增,同时也出现了一个问题:虚拟现实中出现了大量缺少标签的数据,特别是大量的以图像形式存在的数据没有标签,使得这些图像不能被很好地使用。如何更好地利用这些无标签但含有大量信息的图像成为当今一个重要的问题,同时又因为我们身处于一个信息大爆炸的时代,所以每幅图像中都含有大量且丰富的信息。因此,每幅图像中往往需要标注多个标签,相对而言,虽然标注多个标签的方法更复杂,但图像中的信息能被更好地挖掘和使用。
目前生成模型、判别模型和最近邻居模型常被用来完成图像的多个标签的标注。生成模型通过同时学习图像和文本的分布来进行标注。其中,主题模型[1]经常被使用,例如,采用最大期望EM (Expectation Maximization)算法的概率潜在语义分析PLSA (Probabilisticlatent Semantic Analysis)模型[2]、使用贝叶斯框架的隐含狄利克雷分布LDA (Latent Dirichlet Allocation)模型[3]、融合PLSA和高斯混合模型GMM(Gaussian Mixture Model)的标注方法[4]和改进的融入类别信息的一致性LDA corr-LDA(correspondence LDA)方法[5]等。判别模型[6]首先为每个待标注标签单独训练一个分类器,再用其进行标注。最近邻居模型借助检索最近邻居的标签来标注图像,如根据特征计算距离的共同平等贡献JEC(Joint Equal Contribution)模型[7]和权重与邻居标签的存在状态有关的 标签传递TagProp (Tag Propagation)模型[8]。
因为深度网络的不断发展,学者们着手研究是否能把深度网络应用在图像上。例如,使用线性回归的卷积神经网络回归器CNN-R (CNN Regressor)模型[9]、对损失函数进行优化的均方误差卷积神经网络CNN-MSE(CNN Mean Square Error)模型[10]、利用网络中间层特征的标注方法[11]、引入关联规则的CNN-LDA模型[12]和引入邻域排序损失函数的LNR+2PKNN(List-wise Neural Ranking+Two Pass KNN)方法[13]。然而,这些方法仍然存在样本不足和标注词分布不均匀等问题。
因此,本文使用LDA来对文字数据降维,并且减少人工标注的成本,同时把注意力机制加入到卷积神经网络中,以更好地获得2种模态间的联系,并修改其损失函数解决标注词分布不均匀的问题,最后采用半监督学习的方法来处理样本可能不足的问题,从而得到了较好的结果。
2 相关介绍
2.1 主题模型
LDA模型生成主题和标注词的流程如图1所示。

Figure 1 LDA model图1 主题模型
图1中,θ表示主题参数,z表示主题,w表示标注词,α和β表示模型参数,M表示训练集大小,N表示输入词的数量。
模型生成主题和标注词的LDA步骤如下所示:
(1)先对文档切词;
(2)随机抽取主题;
(3)为所有在文档中的词选择任意主题;
(4)确定第i个文档的第j个词所属主题,重复操作(从所有词中最终筛选得到的词才称为标注词);
(5)得到文章-主题分布和标注词-主题分布。
从图1可知LDA的联合概率为:
P(θ,z,w|α,β)=P(θ|α)C
(1)
(2)
其中,zn为抽取的主题,wn为生成的标注词。
用LDA来标注图像时,首先计算得到属于测试集图像的所有主题分布,再根据该分布确定图像所属的主题,最后由选中的主题得到图像对应的标注词的概率。
2.2 卷积神经网络
卷积神经网络逐层获得图像的高级视觉特征[14],越接近网络的输出层,图像特征表示形式就越抽象,就越能获得更丰富的高级视觉特征,对图像的识别能力越强。
本文使用的是AlexNet网络,它有以下优点:
(1)激活函数是修正线性单元ReLU(Rectified Linear Unit),解决了在较深网络中Sigmoid可能会带来的问题,表明ReLU在较深网络中优于Sigmoid。
(2)在训练时用Dropout随机忽略一些神经元来解决过拟合问题,但是在预测时不使用Dropout。
(3)网络结构中的竞争机制使泛化能力得到了增强。
(4)借助GPU的计算能力加快了网络的训练。
2.3 注意力机制
目前该机制被广泛应用于文本生成[15]和图像分类[16,17]等之中。例如,由Huang等[18]搭建的选择性多模态长短期记忆网络,借助可以对图像的任意部分特别注意的功能,来调节标签与特征之间的对应关系。由Zhang等[19]搭建的对抗哈希网络,具有能捕获部分多个模态信息的功能,能提高对内容相似性的度量性能。因注意力机制能模拟人类的视觉进行物体选择,在输出某个实体时会关注图像的相应区域,本文同样把注意力机制引入网络中以获得2个模态间的联系。计算注意力的公式如下所示:
B=XW
(3)
(4)
E(Z)=aX
(5)

Figure 2 Modified convolutional neural network图2 改进后的卷积神经网络
其中,X=(x1,…,xn1)为n1维的输入特征向量,W由随机正态分布初始化得到且随着网络的训练而改变,a=(a1,…,an1),Z为输出。式(4)可以看成是对特征进行选择,ai为第i个特征在所有特征中的权重,表示该特征的重要程度;式(5)对特征进行加权以选择特征,调整注意力关注区域,因为该过程可导,即可训练W。B表示不同特征的得分,借助式(4)进行正则化后与输入结合,以得到每个特征的注意力大小。
2.4 标签相关性
标签往往不是单独出现的,而是存在着某种看不见的联系,如“房间”和“床”,分析并利用这种联系能更精确地进行标注。并且,借助标签相似性可以解决以往进行标签标注时出现的一个标签训练一个分类器,所有分类器无法相互配合,导致实验结果不是很理想的问题。
3 改进的卷积神经网络
3.1 使用注意力机制与迁移学习的卷积神经网络
本文使用的AlexNet模型[20]的结构共 11 层,因为其层次较多,需要大量图像数据进行训练才能得到较好的模型,因此对ImageNet[21]的训练参数进行迁移学习[22]。首先把ImageNet中的全部图像进行训练后得到参数;然后训练训练集中的图像来改变模型最末层的参数,同时对损失函数和网络结构进行改进:把一个注意力层添加到该模型的最后的全连接层前,以标注多个标签和获得2个模态间的联系,以及对类似图像间的不同进行关注;最后使用改进的网络进行训练来对图像进行标注。该网络的初始化参数为:动量 0.5,衰减量 0.000 2,学习率0.001。改进的卷积神经网络的结构如图2所示。
3.2 损失函数的改进
研究人员通常把Softmax函数作为单标签的损失函数来完成单标签的标注,其定义如式(6)和式(7)所示:
(6)
(7)
为了计算样本的全部损失以标注多个标签,本文定义新的损失函数如式(8)所示:
(8)
其中,N1 表示图像文本标签的种类;ali表示图像训练样本x对应的高层特征向量第i维的特征值;pi代表卷积神经网络预测训练样本x属于第i类标签的概率;L表示交叉损失函数;yi表示训练样本x对应一个标签时的标签值(0或1);K表示训练样本x对应多个标签类时标签类个数;yji表示第i个训练样本对应多个标签类时第j个标签类的标签值。
由于训练集的标签分布不均匀会导致模型对高频标签类预测的准确率大大超过低频标签类的准确率,所以需要平滑处理[23]高频标签类,即在高频标签类中加入噪声,以提高低频标签类的预测准确率。先计算各个类的频率系数并添加到损失函数中,如式(9)所示:
(9)
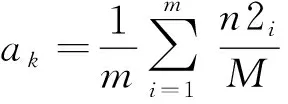
(10)
4 标签相关性方法
首先把所有的已知标签L1,L2,…,LD和所有训练图像M1,M2,…,MM组成一个矩阵K,Kij表示标签Li是否在图像Mj中出现,0和1分别表示未出现和出现的情况。K如表1所示,则2个标签Li和Lj的相关性计算方法为:cij=ri·rj,其中cij表示2个标签Li和Lj的相关性,ri和rj分别表示矩阵K的第i行和第j行,·表示向量点积。
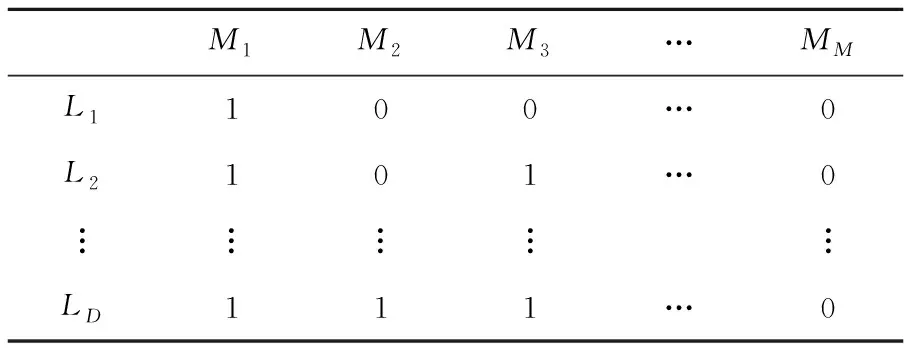
Table 1 Correlation matrix K
5 基于主题模型和半监督的图像标注方法
首先利用LDA主题模型对图像训练集的文本进行建模,生成图像训练集标注词分布,该过程充分利用主题模型的优势,在降低图像文本数据维度的同时避免了人工标注,不仅降低了图像标注的人工成本,也节省了时间。但是,LDA模型生成的标注词存在不够精确且数量较多的问题,本文使用标注词筛选和降维来解决这个问题。标注词筛选和降维步骤如下所示:
(1)筛选:通过限制主题中词的概率来进行标注词筛选,规定只有主题中词的概率大于某个阈值y时,该词才能作为标注词。
(2)降维:类似于特征降维,标注词降维主要是解决标签空间存在冗余信息的问题,即标注词之间普遍存在的相关性,本文即利用标注词的相关性进行降维,步骤如下所示:
①分别计算每2个标注词在同一幅图像中同时出现的次数,即可以得到相似性矩阵A。
②构建无向图,每个节点对应一个标注词,2个节点之间连线的权重为节点对应的标注词在同一幅图像中同时出现的次数,即相似性,如果没有同时出现过,则无连线。
③从A中找到一个非零的最小值,同时在无向图中把这个值对应的2个标注词之间的连线断开并且把该值归零。
④从无向图中寻找极大连通子图,一个极大连通子图包含的标注词归为一类,如果极大连通子图的总数量少于需要的数量,重复③和④,直到极大连通子图的总数量大于或等于需要的数量,停止操作,完成降维。
考虑到深度学习在图像标注方面的优势,本文采用卷积神经网络提取图像的高层视觉特征,又因为深度卷积网络提取的有用特征易受背景等因素影响,而与无用特征混合在一起对图像识别造成干扰,并且为了解决图像间的微小差异会随着层数的加深渐渐消失的问题,本文在卷积神经网络的最后2个全连接层之间增加一个新的注意力层。同时改进损失函数,以完成多标签标注,最后利用半监督学习将网络的标注结果和标注词的相似性结合起来完成图像标注。本文的标注方法如图3所示。
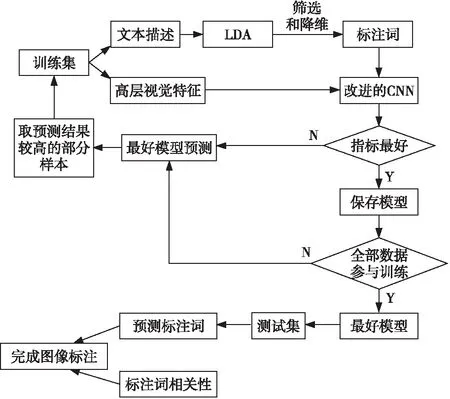
Figure 3 Semi supervised image annotation framework based on LDA and deep network图3 基于LDA和深度网络的半监督图像标注框架
由图3可知,本文的标注方法过程如下所示:
(1)借助LDA完成训练集的文本降维,降维后仍然会存在标注词精确性不高、数量较多问题,本文通过进一步筛选和降维来获得待标注的标注词。
(2)利用改进后的卷积神经网络提取图像的高层视觉特征,由于该卷积神经网络使用了迁移学习和注意力机制,提取到的高层视觉特征比传统手工特征更加全面,利用图像的高层语义特征及其对应的标注词来训练模型。
(3)把数据集分成训练集和测试集,考虑到样本可能不足的问题,使用半监督学习的方法首先对训练集的图像的高层视觉特征和对应的标注词进行训练,记录下模型的评价指标。然后利用该模型对测试集进行预测,选择准确率较高的一部分测试集样本放入训练集中再次进行训练,如果此次评价指标优于当前的最好指标,则保存该模型并且继续用该模型对测试集进行预测,选择准确率较高的一部分测试集样本放入训练集中再次进行训练;否则减少从测试集放入训练集的样本数量的同时用已保存的评价指标最好的模型开始重新训练,当训练集的大小等于数据集的大小时停止训练。
(4)计算所有图像标注词个数的平均值h,选择评价指标最大的模型为最终模型并对测试集进行预测,选择概率最大的前h个标注词构成预测的标签集合。
(5)把集合中的每个预测标签和其他标签的相关性与所有两两标签之间的相关性的平均值比较,当相关性大于平均值时把未预测的标签加入预测标签的集合中,当相关性小于平均值但标签存在于集合时,把对应标签去除。把预测结果与标注词的相关性结合后可以得到一个标签集合,该集合即为最终的标注结果。
6 实验与结果分析
6.1 实验设置

6.2 实验参数设置
首先对阈值y和标注词种类Q进行讨论。本文对Q以步长为10进行取值,对y以步长为0.01进行取值,同时以F1的值作为实验的对比指标。由图4可知,当Q为80时,F1值达到最大;由图5可知,当Q为80时,F1值达到最大。所以,本文将Q设为80,将y设为0.02。

Figure 4 F1 values corresponding to different topic numbers图4 不同主题数对应的F1值

Figure 5 F1 values corresponding to different thresholds y图5 不同阈值y对应的F1值
6.3 实验结果
首先将本文方法的模型与采用较传统方法的JEC模型[7]相比较;然后与TagProp-ML[24]和2PKNN模型[25]相比较;同时与ANNOR-G(Automatic image aNNOtation Retriever-Global features)模型[26]、特征融合与语义相似度FFSS (Feature Fusion and Semantic Similarity)模型[27]比较;最后与使用了深度卷积神经网络的CNN-R模型[9]和CNN-MSE[10]模型、CNN-LDA[12]模型、CNN-MLSU(CNN using Multi-Label Smoothing Unit)模型[28]和LNR+2PKNN[13]模型进行实验对比。实验结果如表2所示。
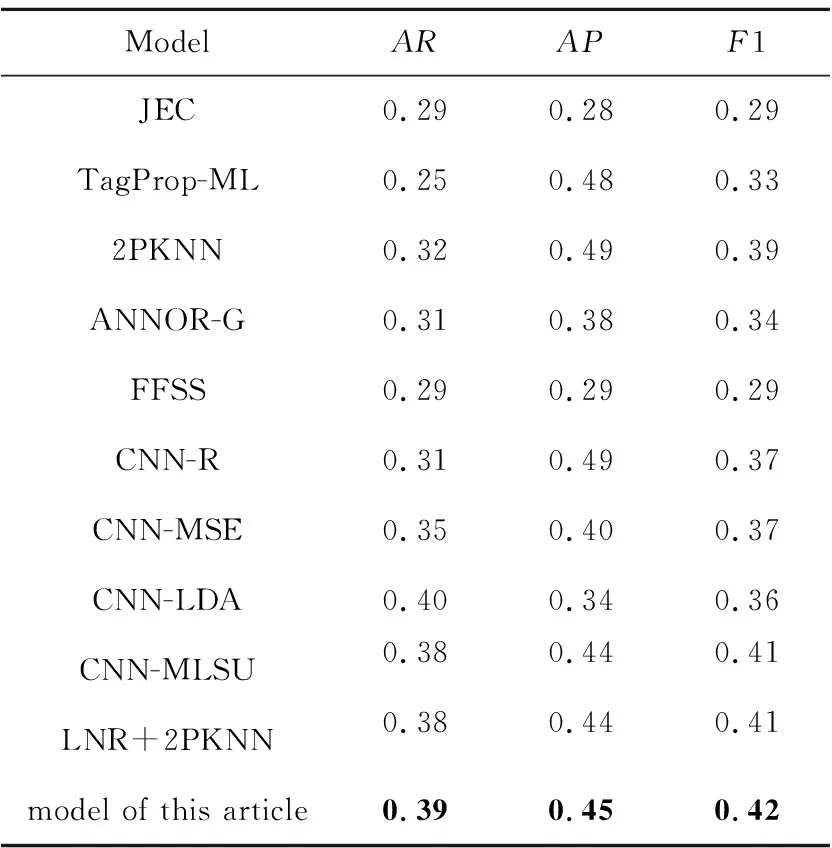
Table 2 Comparison between our models and other annotation models
通过表2可以看出,在同一图像集上,本文模型的结果相对于传统的标注模型有较大提高。在同一图像数据集上,平均召回率相对于JEC 提高了10%,相对于 TagPro-ML 提高了14%,相对于2PKNN 提高了7%。平均准确率相对于JEC的提高了17%,但低于TagProp-ML 和2PKNN 的。对比较为先进的ANNOR-G 模型和 FFSS 模型,本文模型的各项指标都有提高。
通过与使用了卷积神经网络的模型进行比较,可知本文模型的平均召回率只低于最高的CNN-LDA模型1%,但其平均准确率远高出它。平均准确率小于CNN-R的,但其F1高出5%。本文模型的F1不低于所比较的任何模型,通过本文模型和其他模型在同一数据集上的比较结果可知,本文模型在平均召回率上表现良好,但在平均准确率上不是很好,总的来看本文模型相对于大部分模型都有所提高。提高的原因有以下几点:首先,因注意力机制对特征进行选择,使网络其模拟视觉且不再只关注全局,更易获得2种模态间的联系;其次,利用改进的损失函数能够提高低频词的准确率;最后,使用半监督方法进行训练能够充分利用样本。
此外,为检验加入噪声对低频标签类的标注影响,把加入噪声前后低频标签类的平均准确率AP、平均召回率AR进行对比,该数据集有55个低频标签类,实验结果如表3所示。
由表3可知,加入噪声能防止模型过拟合,在几乎不影响高频标签类的标注下,极大提高了低频标签类的标注准确率。
7 结束语
本文利用主题模型在文本处理方面的优点来完成对文字数据的降维,同时更改AlexNet模型的网络结构和损失函数来更好地进行多个标签的训练和预测,并把模型的预测和标签间的相似性进行结合来提高准确率。由对比实验可知,本文方法的标注更精确。
