面向智能手机拍摄的变形文档图像校正*
2022-01-24冯百明
周 丽,冯百明,关 煜,方 格
(西北师范大学计算机科学与工程学院, 甘肃 兰州 730070 )
1 引言
在生活中,拍摄书籍或者资料时,由于书籍较厚和拍摄方式等原因,经常会发生图像中所拍页面出现透视、倾斜或弯曲变形等现象,这些现象对图像的后续应用,诸如图像识别、机器视觉等造成很大的影响。因此,需要对这些不利后续应用的变形进行校正,以便更好地使用文档图像。目前,对透视和倾斜变形图像的校正方法比较成熟,但对弯曲变形图像仍存在校正效果不理想的问题,本文主要研究弯曲变形图像的校正。
页面弯曲变形的校正技术主要有基于连通域的方法[1-6]、基于3D技术的校正方法[7 - 9]和基于模型的方法[10 - 12]。Gatos等人[1]提出了一种对于任意变形文档分割的校正方法。该方法首先通过提取单词的上基线和下基线[2],并用直线来拟合,然后找到最近邻单词之间的倾角关系,逐步将每个单词进行校正。Liu等人[3]介绍了一种基于字符迭代绑定和平行线法构造曲线的恢复方法,增加了很多限制规则,这无疑增加了算法的复杂度,而且对变形图像的校正效果不理想。Liu等人[4]同时又提出了一种基于文本边界线调整的复原方法,这种方法不依赖文本行,对文档图像的内容没有限制。国内研究人员常使用字符分割的方法[5,6],这种方法提取字符比较耗时。Ulges等人[7]利用3D信息将四边形映射到正确的尺寸和位置,但该方法需要提前知道页面布局情况且要求相机垂直于书脊。Zhang等人[8]利用SFS(Shape-From-Shading)技术来提取用于3D建模的信息,在文档图像的几何校正方面取得了不错的效果,其公式能够很容易进行修改,以适应不同的光照条件。Tang等人[9]应用可展平面锥面来建模图像文档变形,但局限于个别情况。Fu等人[10]提出使用模型转换的方法对变形图像进行校正,模型转换的方法可以用在不同的语言上,而且对复杂的文档图像也能进行校正,但校正速度较慢。Kim等人[11]在建立广义圆柱模型研究成果的基础上,提出了一种成本函数的校正方法。Kil等人[12]基于Kim等人的研究成果,将图像中的线段属性编入成本函数进行校正,当线段扭曲变形严重时,校正效果不理想。Meng等人[13]使用向量场来对单一变形页面进行三维建模,当变形类型多样时,效果较差。Li等人[14]提出基于块分割和卷积神经网络模型的校正方法,复杂度较小,但这种方法不能检测识别文档的边界,对文档图像的未裁剪部分不能校正,同时图像与合成的训练数据集相差太多的时候,校正精确率较低。
目前,基于模型的方法对页面弯曲变形的校正效果最为理想,但很多是只针对英文和纯文本图像的变形进行校正的,而且大多是以文本行和文本块为校正对象,存在校正的效果不理想和校正类型单一的问题。
针对上述问题,本文提出了一种基于文本域合并的文本行获取算法,并提出利用最小化重投影的方法进行参数模型的优化,从而实现校正。现有方法以文本行或者文本块作为校正对象,当文本行变形严重时,并不能完全提取变形信息,而以文本域作为处理对象,能够提取到局部的变形信息,再对其进行合并,使得变形文本行信息更加丰富,从而更有利于文档的校正。
最小化重投影方法与现有字符拉伸、文本行曲线拉伸以及成本函数优化方法相比,不仅考虑了投影矩阵的计算误差,还考虑了图像点的测量误差,所以有更高的精确率;此外,本文选择序到最小二乘规化SLSQP(Sequential Least SQuares Programming)算法,使得误差最小化,经过测试,此优化方法速度高于其他方法,因而最小化重投影方法更准确、更高效。
本文利用文本域合并提取的文本行信息建立扭曲页面的模型,在优化时对整个页面进行重新映射,因此对于带公式、插图的扭曲文档也能够校正。相比对插图部分进行线段约束的方法,本文方法不需要检测线段,而是利用建立好的模型直接优化和重投影,因而有着更高的效率。实验表明,本文方法提高了校正的精确率,并可以对带插图的变形文档图像进行较好的校正。
2 校正弯曲变形的方法
本文提出一种新的变形文档图像校正方法。该方法首先利用文本域合并方法获取文本行,其次使用主成分分析PCA(Principal Component Analysis)方法进行关键点投影,利用三次多项式计算关键点和其投影点之间的偏移量,最后使用优化算法进行最小化重投影,使得图像得以校正。本文方法具有以下特点:无需切分字符和分析字符位置;利用文本域进行合并;使用最小化重投影方法。
2.1 投影原理
智能手机拍摄空间物体时,空间物体的位置与像平面某点的位置是相关的,位置的相互关系是由手机成像的几何模型决定的。三维空间到二维空间的变换是一个投影的过程。手机成像过程涉及4个坐标系(世界坐标系、相机坐标系、图像物理坐标系和图像像素坐标系)以及坐标系之间的转换。下面介绍坐标系之间的转换。
世界坐标系的坐标用(Xw,Yw,Zw)表示,相机坐标系的坐标用(Xc,Yc,Zc)表示,图像物理坐标系坐标用(x,y)表示,图像像素坐标系的坐标用(u,v)表示。如图1所示是图像物理坐标系和图像像素坐标系的关系,xy表示的是图像物理坐标系,uv表示的是图像像素坐标系。假设每一个像素在u轴和v轴上的物理尺寸为dx和dy。
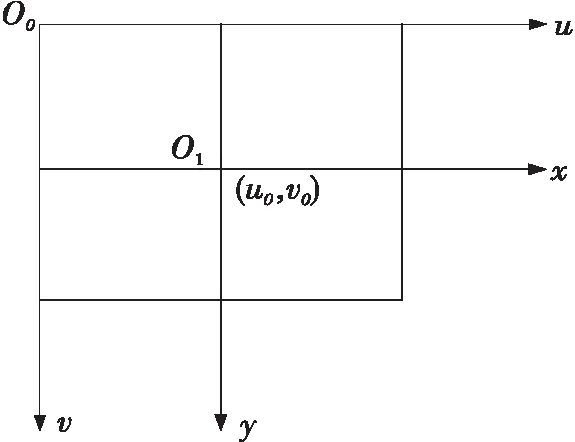
Figure 1 Relationship between the physical coordinate system of an image and its pixel coordinate system图1 图像物理坐标系和其像素坐标系之间的关系
图像物理坐标向图像像素坐标的转换过程如式(1)和式(2)所示,转换矩阵如式(3)所示:
u=x/dx+u0
(1)
v=y/dy+v0
(2)
(3)
世界坐标系转换到相机坐标系的过程如式(4)和式(5)所示,转换矩阵如式(6)所示:
x=f*Xc/Zc
(4)
y=f*Yc/Zc
(5)
(6)
其中f表示相机的焦距。
同时,相机坐标系和世界坐标系的转换如式(7)所示:
(7)
其中,R表示旋转矩阵,T表示平移矩阵。
世界坐标系和图像像素坐标系的转换过程如式(8)所示:
(8)
其中,M1表示内参矩阵,M2表示外参矩阵。这样三维空间物体的坐标就可以投影到二维空间中。
2.2 页面弯曲变形
为了更加方便和快速地处理图像,在进行图像处理前需要的图像进行一些规范化操作,也就是图像的预处理工作。传统的预处理方法是对多余部分进行裁剪。本文对只有页面弯曲变形的图像,直接选定感兴趣区域ROI(Region of Interest)进行校正。页面弯曲文档图像的类型主要有纯文本图、图文混合图、纯图像和表格等,本文主要处理的是纯文本图和图文混合图。图2和图3分别是图文混合和纯文本的变形文档图像。

Figure 2 A distorted document image mixed with text图2 图文混合的变形文档图像

Figure 3 A distorted document image of plain text图3 纯文本的变形文档图像
2.3 ROI区域大小的选定
从图2和图3可以看出,日常拍摄的图像很多时候存在多余的部分。以往文献会对多余部分进行裁剪,如文献[15],本文不再讨论如何裁剪,直接在选定的ROI上操作。对于分辨率超高的图像,使用像素区域关系进行重采样,以降低图像的分辨率,低于电脑分辨率的不做处理。在获取页面ROI大小时,事先根据输入的图像选定页面的4个页边距,根据页边距最后确定ROI大小,图4是页面边距设为30所得的ROI大小。如图5框选部分为图2的ROI大小。

Figure 4 Page ROI size图4 页面ROI大小

Figure 5 ROI size of image in figure 3图5 图3中图像的ROI大小
2.4 检测文本域轮廓
校正中文变形文档时,已有方法通常采用分割字符的方法[5,15,16]。字符分割往往耗时长,而且不能有效分割不在一条水平线、弯曲严重的字符。有的方法直接通过检测文本行和文本块进行校正,这种方法速度较快,但准确率依旧不高。本文通过检测符号之间的文本域对文本进行划分,这里的符号包括正常的标点符号,还包括空格等符号。
在对文本进行检测前,需要进行灰度化、二值化、均值去噪以及形态学等预处理操作。本文使用OpenCV库的轮廓查找方法cv2.fingContours(),通过检测最外层轮廓的方式检测到每个文本域的轮廓,并通过图像矩找到文本域轮廓的近似中心点位置和文本域的方向角,从而确定文本域的中心线。如图6所示,是检测到的图3中文本域轮廓及其中心线。

Figure 6 Text field outline of image 3 and its center line图6 图3文本域轮廓及其中心线
2.5 获取行连通域及其关键点
文本行提取过程如下:前文获取的文本域信息被存进了列表info_list,设任意文本域区域i和j,要求i是j前面的一个文本域,i和j组成一对文本域,为每对文本域轮廓生成候选边,并对它们进行评分。
评分规则是:分数值由距离和角度变化的线性组合来决定,同时筛选掉那些重合、不在同一行的文本域,将重合、不在同一行的文本域候选边设为无穷大(INFINITY)。然后对分数score进行排序,分数越低生成候选边的可能性越大。遍历所有的候选边,对没有连接的候选边进行连接,直到连接到最后一个文本域。文本行提取算法如算法1所示,获取的文本行连通域如图7所示。
算法1变形文本行提取算法
输入:info_list。//文本域轮廓信息
输出:spans。//文本行轮廓信息
步骤1sorted(info_list);/*对文本域列表信息进行排序*/
步骤2can_edges=[ ];//候选边列表
步骤3spans=[];//初始化文本行轮廓列表
步骤4foreach contouri:
foreach other contourj:
score=get_edges_cost(i,j);
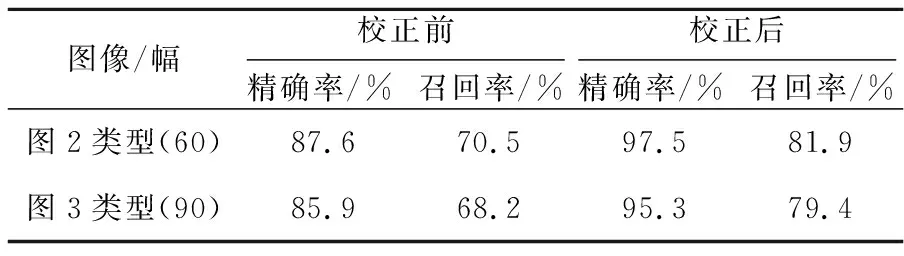
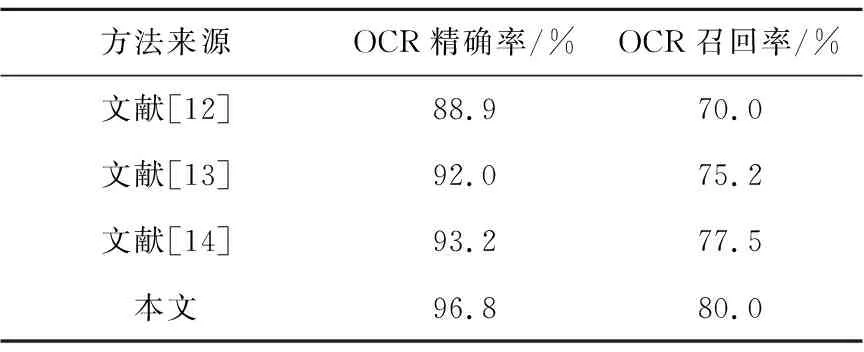
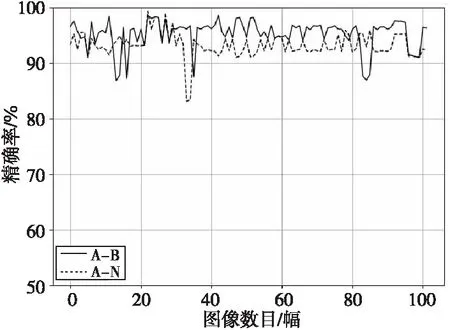
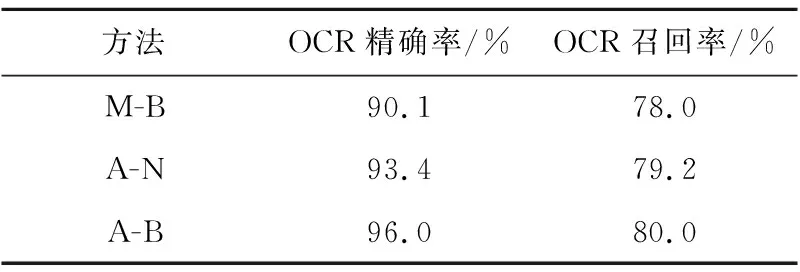
ifscore can_edges.append(i,j);/*为每个文本域生成候选边*/ 步骤5can_edges.sort();/*对候选边进行从低到高的排序*/ 步骤6 foreach edge (i,j) incan_edges: ifiandjunconnected: {span=connectiandjwithscore;/*根据候选边分值进行文本域连接*/ spans.append(span);} 步骤7 returnspnas. Figure 7 Text lines connect domains图7 文本行连通域 获取文本行连通域后,为了方便计算,需要在每个连通域上生成少量的代表性点,也就是关键点。本文在最初利用PCA方法估计文本行的均值和方向信息,设置在每20像素的位置上生成一个关键点,生成的连通域关键点如图8所示。 Figure 8 Key points in the connected domain图8 连通域关键点 使用三次多项式可以很好地拟合页面弯曲变形的形状,如式(9)所示。三维模型建好后,可以确定s和c之间的对应关系,其中,c表示投影点的坐标,s表示弯曲文档表面模型。 s=a3c3+a2c2+a1c+a0 (9) 由于相机坐标系和图像坐标系存在偏差,需要将上一步获取的关键点坐标信息代入式(9),建立二维平面坐标点到三维曲面坐标点之间的映射关系,实现三维坐标到二维平面的投影。结合已获取的坐标信息,本文通过solvePnP方法求得旋转参数矩阵R和平移参数矩阵T, 最初假设曲面的曲率为0,通过初始参数可以确定式(9)的系数。将式(10)作为目标函数,图2中关键点和投影点之间的初始化误差为0.045 7,通过序列最小二乘规划优化算法(SLSQP)优化后,图2中关键点和投影点之间的误差为0.000 65。 (10) 其中,m表示关键点的数目,dsti表示第i个关键点,ptsi表示第i个投影点。 根据获取的优化参数对页面大小进行最小化重投影,得到投影后页面的坐标,最后再通过三次样条插值法实现对文本行之外像素的填充,从而实现变形图像的校正。优化前的关键点及其投影点如图9所示,优化后的关键点及其投影点如图10所示。 Figure 9 Key points and their projection points图9 关键点及其投影点 Figure 10 Optimized key points and projection points图10 优化后的关键点及其投影点 本文在PyCharm2018环境下采用Python语言+OpenCV进行实验,实验环境为: AMD A8-6410 APU with AMD Radeon R5 Graphics 2.0 GH z;内存8 GB;操作系统Windows 10。实验采集设备为智能手机,图像版面主要为文本和图文混合页面。采集的图像为手机正常拍摄的自然变形书页。采集的图像大小为800*600~3120*4160,数量为150幅。图2类型的测试图像60幅,取自CBDAR2007数据集[17],该数据集包含102幅扭曲变形的图像,以及通过平板扫描仪获得的变形图像所对应的真实图像。图3类型的测试图像90幅。图11为采用本文方法对图2的校正结果,图12为采用本文方法对图3的校正结果。图13为文献[11]方法对图2的校正结果。 Figure 11 Image correction result of figure 2图11 图2的校正结果 Figure 12 Image correction result of figure 3图12 图3的校正结果 从图11和图12中可以看到,带插图和纯文本的图像都得到了很好的校正。用光学字符识别OCR(Optical Character Recognition)软件ABBYY FineReader 14识别校正前后的图像。OCR精确率(Precision)的定义如式(11)所示,OCR召回率(Recall)的定义如式(12)所示: (11) (12) 其中,Nc是OCR识别到的文档图像的正确字符数目,No是识别到的文档图像字符总数目,N是文档图像字符总数目。 图2类型和图3类型的图像校正前后的平均字符精确率和平均字符召回率,如表1 所示。 Table 1 Comparison of OCR average Precisionand Recall before and after correction 从表1可以看出,图2类型图像校正后平均识别字符的精确率和召回率分别为97.5%和81.9%,比没校正前提高了9.9%和11.4%;图3类型图像校正后平均识别字符的精确率和召回率分别为95.3%和79.4%,比没校正之前提高了9.4%和11.2%。 图13展示了本文方法与其他文献中方法的校正结果的比较,图13a是公共数据集CBDAR2007中的示例图像,图13b是文献[12]方法的校正结果,图13c是文献[13]方法的校正结果,图13d是文献[14]方法的校正结果,图13e是本文方法校正结果。 Figure 13 The results of this method are compared with those of other literature methods图13 本文方法与其他文献方法的结果示例比较 从图13可以看出,本文方法相对其他文献方法更好,在文本行提取时,使用文本域合并的方法能获得更加细节的信息。在建模时使用三次多项式模型,同时使用最小化投影方法进行模型优化,与弯曲变形页面的吻合度较高,从而得到了比较理想的结果。 本文方法和其他文献方法的对比采用了CBDAR2007中的102幅扭曲变形图像,文献[12]方法和文献[14]方法均在本机实现,文献[13]方法由于其实验环境与本文一致,故直接引用了其论文里发表的结果。使用软件ABBYY FineReader 14识别每种方法校正后的102幅图像并计算各自的OCR平均字符精确率和召回率,结果如表2所示。 从表2可以看出,本文方法的平均识别字符精确率要高于其他方法的;文献[12]方法受线段变形严重的影响导致效果较差;文献[13]方法采用单幅图像进行文档变形页面的建模,在多样化数据集上效果不理想;文献[14]方法使用的合成数据集包含多种变形类型,它对裁剪好的和纯文本的图像校正效果最好,但对包含图像和未裁剪的图像效果较差,导致其识别平均字符精确率和召回率下降。 Table 2 Correction results comparison with other literature methods 为了验证文本域合并模块和最小化重投影模块分别对识别性能的影响,本文分别对2个模块进行了对比实验。为了表述方便,将文本域合并简称为A模块,最小化重投影简称为B模块,本文方法就是A-B方法。将文本行提取方法作为文本域合并的对比方法,称作M模块;将文本行基线拉直法作为最小化重投影的对比方法,称作N模块。第1组测试是A-B方法和A-N方法的性能对比,第2组测试是A-B方法和M-B方法的性能对比。测试的OCR平均识别字符精确率如图14和图15所示。 Figure 14 Performance comparison of A-B and A-N methods in this paper图14 本文A-B方法和A-N方法的性能对比 Figure 15 Performance comparison of A-B and M-Bmethods in this paper图15 本文A-B方法和M-B方法的性能对比 OCR平均识别字符精确率和平均字符召回率如表3所示。 Table 3 Performance comparison between different methods 从图14 和图15可以看出,A-B方法的精确率整体上要高于A-N和M-B方法的,且M-B方法的精确率波动幅度较大,A-B和A-N方法性能相对比较稳定。 从表3可以看出,A-B方法的平均识别字符精确率和平均字符召回率要高于A-N和M-B方法的,同时A-N方法的高于M-B方法的,这说明在识别性能上文本域合并模块的贡献大于最小化重投影模块,当2个模块结合时,性能最好。 本文利用文本域合并方法获取行连通域,之后使用基于三次多项式的关键点重投影和页面优化方法实现文本校正。文本域合并方法能够对中英文变形文档的文本行信息进行更准确的提取。最小化重投影方法不仅考虑了投影矩阵的计算误差,还考虑了图像点的测量误差,所以有更高的精确率。三次多项式和最小化重投影方法相结合可以对变形文档图像进行校正。校正后的图像可以很好地用于识别和后期处理。相比其他方法,本文方法的识别性能好,且能够对带插图、公式的变形文档图像进行很好的校正。消融实验显示文本域模块对识别性能的贡献大于最小化重投影模块。未来将主要从纯图像和表格的变形文档页面校正以及人工数据集校正等方面进行研究。

2.6 最小化重投影校正


3 实验结果和分析




4 结束语
