基于高阶累积特征的二阶调制识别模型
2022-01-22龚晓峰雒瑞森
张 秦,龚晓峰,雒瑞森,杜 淼
(四川大学电气学院,四川 成都 610065)
1 引言
自动调制识别在军事情报截获、电子侦察和无线电监控等领域有着广泛的应用。基于决策论方法理论成熟,但需要很多先验信息[1]。基于统计模式识别方法中基于高阶累积量(Higher Order Cumulant,HOC)方法的识别具有简单、有效和运算量小的特点,且高阶累积量能有效抑制零均值高斯白噪声(white Gaussian noise,WGN)对系统的影响。
1992年,Reichert J[2]首次使用高阶累积量特征参数与决策树阈值判决进行调制样式的识别。文献[3-6]采用从四阶到八阶不同类型的高阶累积量作为训练特征,并采用支持向量机等分类器分类,实现了多类调制信号的识别。文献[7]对高阶累积量组合的设计两个高阶特征参量,定义三个判决门限,实现了快速分类识别。近些年来,高阶累积量或其组合与深度学习算法结合识别成为一种新的趋势[8]。文献[9]把IQ数据与高阶累积量结合构造一种结构为3×128的特征样本,长短期记忆网络(Long Short-Term Memory,LSTM)作分类器实现调制样式的分类,在SNR=0dB时取得了80%左右的识别率。文献[10]提出一种基于高阶累积量和堆叠自编码器的三级调制识别算法,第一级与第三级为高阶累积量阈值判决,第二级为堆叠自编码器,在低信噪比下取得较好的识别效果。Zhao Z J等人[11]采用受限波尔兹曼机模型和高阶累积量特征参数,完成了多类别调制信号识别。A.Ali,F.Yangyu[12]首次提出了基于深度学习自编码器网络的非负性约束训练的方法。使用非负性约束来训练自动编码器以学习输入数据的稀疏的、基于部分的表示。文献[13]利用高阶累积量和反向传播神经网络实现了九类数字调制信号的识别。以上算法虽然取得了较好的识别效果,但在低信噪比环境下识别率不稳定,而且存在预处理工作复杂、网络参数较多、特征参数难以提取等问题。针对上述问题,本文提出一种结合稀疏自编码器与高阶累积特征阈值判决(High Order Cumulative Feature && Sparse Autoencoder,HOCF-SAE)的二阶调制识别模型。不同于端到端的自动调制识别算法,该方法提出了一种二级调制分类结构。对高阶累积量进行了多种组合方式,充分利用多个高阶累积量信息,针对MFSK和MQAM的类间特性构造了对应的高阶累计特征。仿真结果表明在低信噪比环境下,综合识别率较对比算法有所提高,且拥有较低的算法复杂度。
2 调制信号模型与高阶累积量
2.1 数字调制信号模型
高斯环境下接受到噪声影响的数字调制信号,可以表示如式(1)所示
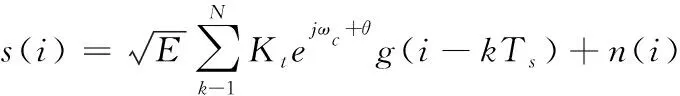
(1)
其中k=1,2,…,N,g(·)代表发送的是码元波形,理想情况下希望是矩形脉冲,而实际情况大多是使用升余弦等脉冲方式,Kt是平均功率归一化后的码元序列,且码元之间相互独立且概率相等的传输,N是观测数据的序列长度,E表示发送码元波形的能量,ωc为载波频率,θ为相位偏差,Ts是码元符号周期,n(i)则为零均值的加性复高斯白噪声序列。经过下变频,中频滤波,解调和码元同步[14]后可以表示为式(2)所示
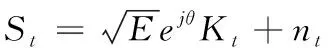
(2)
其中,t=1,2,…,N,而N为观测序列长度。
2.2 高阶累积量
对于零均值k阶实平稳随机过程{x(i)}的m阶累积量可定义如式(3)所示
cmx(τ1,τ2,…,τm-1)=cum(x(x),x(i+τ1),
…,x(i+τm-1))
(3)
对于零均值的平稳复随机过程{X(k)},其p阶混合矩阵可表示如式(4)所示
Mpq=E[X(k)p-qX*(k)q]
(4)
其中X*(k)表示函数X(k)的共轭,如果数字调制信号发送的是概率相等,均值为零的码元序列,且g(·)选用的是单位矩形脉冲形式。因此X(k)的二阶至八阶累积量计算公式如式(5)所示
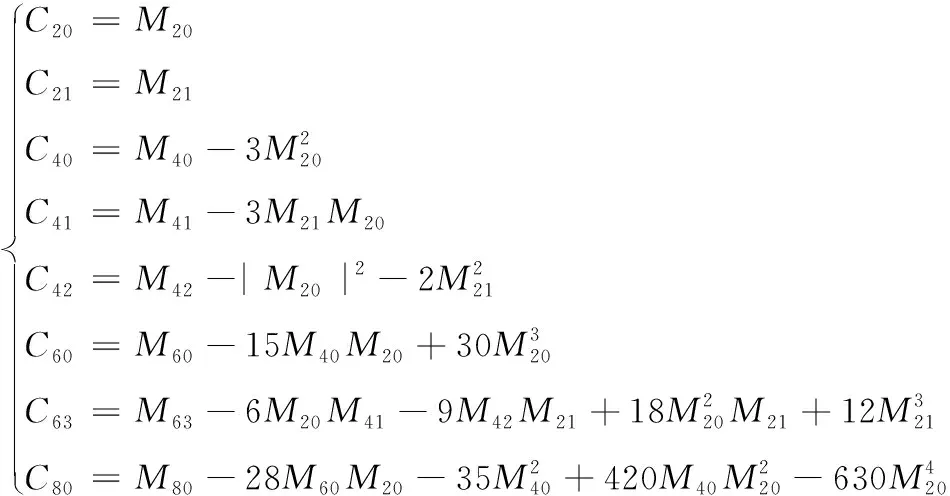
(5)
若X为零均值高斯噪声,其高于二阶累积量的值恒等于0,因而高阶累积量对高斯噪声有良好的抑制特性,引入高阶累积量作特征可以大幅降低高斯白噪声对调试识别系统识别效果的影响。设不同调制信号的能量为E,可以推导得本论文调制信号的累积量理论值如表1所示。
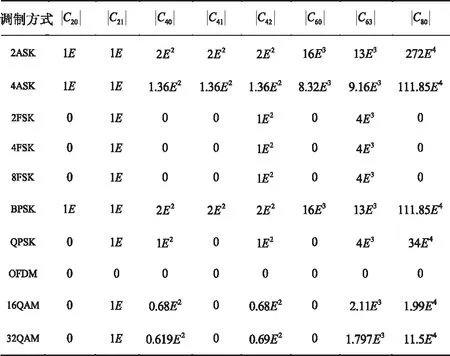
表1 各阶累积量理论值
由表1分析可得,不同调制信号计算的高阶累积量的理论值,具有明显的特征差异,可以利用高阶累计量以及构造的组合特征参数实现调制信号类别之间的分类。对于2ASK,4ASK,2PSK,4PSK和OFDM这几类信号,特征参数之间的差异性较好,但是对于MQAM和MFSK而言,16QAM与32QAM、2FSK,4FSK与8FSK的各高阶累积量理论值邻近,类间识别效果较差,可以进一步提取更加针对性的特征参数对进行分类识别。
3 调制识别算法
3.1 稀疏自编码器
稀疏自编码器(Sparse Auto-Encoder,SAE)是一种尽可能复现输入信号的神经网络,其基本单元自编码器是对称无监督三层神经网络[15]。网络由编码层和解码层组成。本文采取稀疏自编码器(Sparse Auto-Encoder,SAE)提取信号特征,再级联Sotfmax分类器进行初分类,为一个分层结构,由输入层、输出层和多个隐层组成。编码过程将高维输入数据转换为低维特征空间,如式(6)所示
y=f(Wx+b)
(6)
解码过程从特征空间重构出输出数据,实质上是编码的逆过程,如式(7)所示
z=f(WTy+b′)
(7)
式中WT和b′分别代表隐藏层到重构层的权值矩阵和偏置矩阵。SAE的代价函数可表示如式(8-10)所示
Jcos t(Ψ,Z,x)=JMSE(Ψ,Z,x)+Jweight(Ψ)
(8)
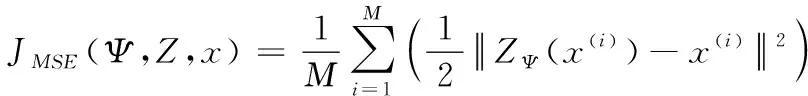
(9)
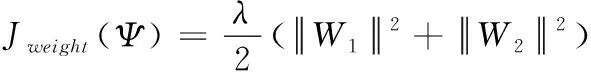
(10)
其中,Ψ={W,b},W表示自编码器权重矢量,b表示隐藏层偏置矢量,Μ是训练样本的数目,ZΨ(x(i))表示第i个样本的重构输出数据,x(i)表示第i个样本,λ是权重衰减参数,W1和W2分别表示输入层到隐藏层、隐藏层到输出层的权重矩阵。自编码器的重构误差较小的时候,原始输入数据的大部分信息将被保留,但这不足以让自编码器学习到所需要的特征,同时为了用尽可能少的节点来表示输入数据,通过对隐藏层节点加入稀疏约束构造稀疏自编码器[16]。SAE的整体损失函数表示如式(11)所示
Jcos t(Ψ,Z,x)=JMSE(Ψ,Z,x)+Jweight(Ψ)+Jsparse(δ)
(11)
编码和解码的非线性映射函数为sigmoid函数,结合稀疏自动编码器反向传播和梯度下降算法,更新参数结合Ψ,可得更新公式如式(12-13)所示
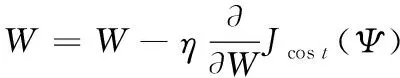
(12)
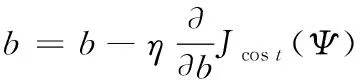
(13)
其中η为迭代步长系数,即学习率。假设输入数据为x(i),其对应标签为y(i)对c类nd个样本构成的回归模型训练集表示如式(14)所示
Θ:{(x(1),y(1)),(x(2),y(2)),…,(x(nd),y(nd))}
(14)
Softmax分类器与堆栈稀疏自编码器的组成是监督式学习算法,对于给定输入x,使用Softmax回归模型对其进行估计,测试目标x归为ω类的概率可表示为式(15)所示
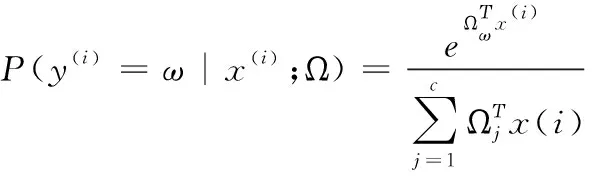
(15)
其中ω=1,2,…,c,在训练过程中,采用有监督训练算法训练,训练得到最优模型参数Ω,Softmax的最小化损失函数如式(16)所示

(16)
梯度下降方法是常用的参数优化方法,经常被用在神经网络中的参数更新过程中,梯度的含义是函数沿着某点处的方向导数可以以最快速度到达极大值,该方向导数定义为该函数的梯度,其基本原理是求导数时的链式法则。本文采用反向梯度下降算法进行有监督的整体优化,对于给定样本集Θ,可得整体代价函数为式(17)所示
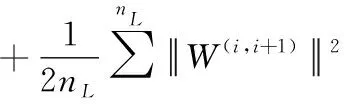
(17)
其中,h(x)为对应输入x的网络输出标签,nL是网络的层数W(i,i+1)表示第i层和第i+1层之间权值矩阵。通过梯度下降更新得到最优的W和b使得稀疏自编码隐层学到较好稀疏表达。
3.2 算法模型
3.2.1 算法思想
本算法的自动调制识别分两级实现,第一级的输入为高阶累积量、高阶累计特征和信号标签组成的高阶累积片段,用稀疏编码器级联Softmax作分类器,得到预分类结果。第二级的输入为上一级分类后的MFSK和MQAM信号数据,依据高阶累积特征作阈值判决,算法的整体流程图如图1所示。
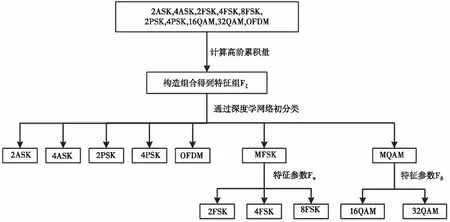
图1 整体算法流程图
算法的特征参数的选取与构造至关重要,不但要考虑相位抖动对高阶累积量的影响,还要考虑采集信号幅值对高阶累积量的影响。构造特征应取高阶累计量绝对值形式,同时通过比值来构造特征可以有效降低幅度对识别参数的干扰[17]。因而本文通过了多种方式对高阶累积量进行处理和组合,包括求绝对值、组合比值和计算高阶次方。
根据以上理论,构造出高阶特征参数片段T={T1,T2,T3,T4,T5,T6},其各参数具体计算公式如式(18)所示
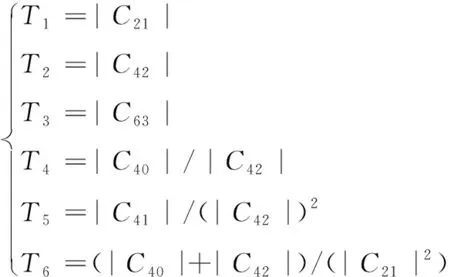
(18)
利用累积量的绝对值构造特征参数能减小相位抖动对特征参数的影响[18],征参数的影响利用高阶累积量C21、C63与C80构造得到特征参数Fβ,公式如式(19)所示
Fβ=(|C63|4+|C80|3)/(|C21|12)
(19)
对于MFSK信号,需要将其频率学习转化为含有幅度信息的信号,通过将MFSK信号求微分,再取高阶累计量,MFSK信号求微分后的高阶累积量|C∂21|、|C∂42|和|C∂63|理论值如表2所示。

表2 MFSK信号微分后的高阶累计量
因此可由C∂21、C∂42和C∂63进行组合得到特征参数Fα,其计算公式如式(17)所示
Fα=|C∂42|/|C∂21|2+|C∂63|2/|C∂42|3
(20)
Fα和Fβ计算出的特征理论值如表3所示。依据理论值设置判决阈值关系,对于MFSK而言,当Fα大于8.95时,判决结果为2FSK,当Fα大于2.58且小于8.95时,判决结果为4FSK,当Fα小于2.58时,判决结果为8FSK。对于QAM而言,Fβ大于780时,判定结果为16QAM,Fβ小于780时,判定结果为32QAM。综上所述,通过特征阈值判决,可实现对MFSK信号和MQAM信号的类间识别。具体阈值判决如式(21)和式(22)所示
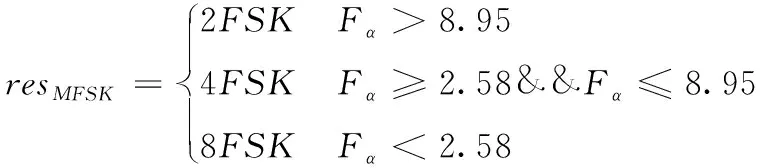
(21)
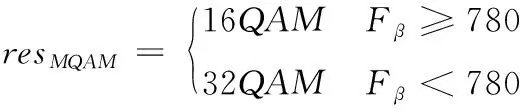
(22)

表3 特征参数Fα和Fβ的理论值
3.2.2 算法步骤流程图
本文算法可描述如下几个步骤:
1)仿真生成各个类别的数字调制信号。
2)将仿真得到的数字信号计算各阶高阶累计量,为避免随机干扰的影响,高阶累积量的计算方法为重复五十次计算做累加再求平均值,处理后得到T1、T2、T3,进而计算组合特征T4,T5和T6,综合得到高阶特征参数片段T。
3)预分类阶段:预分类流程图如图2所示,稀疏自编码器的输入特征为2)中提取的特征片段T,以及对应调制方式组成的数据标签,通过随机梯度下降法训练网络参数。测试集输入训练好的网络,从而达到出分类调制类型的目的。
4)在3)的基础上,分别计算用于识别MFSK信号和MQAM信号的特征参数Fα,Fβ,利用阈值判决,进一步辨识出不同的调制类型。
5)计算得到调制识别最终评价指标。
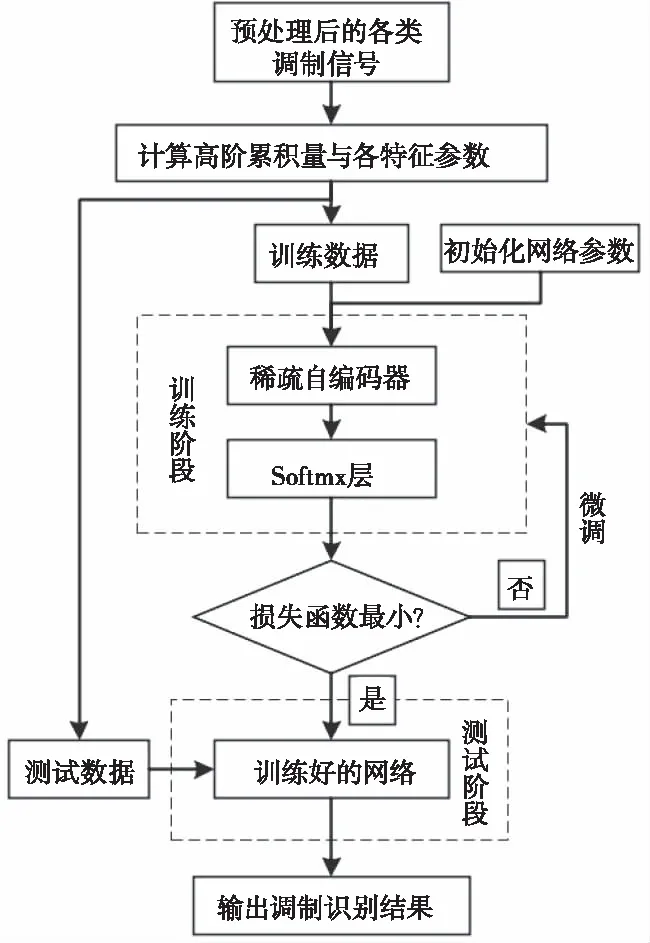
图2 稀疏自编码器预分类流程
4 仿真结果与分析
本文信号仿真和高阶累积量提取及计算由Matlab实现,稀疏自编码器网络采用python 3.7语言实现。仿真环境CPU为i5-8300H,显卡GTX 1050Ti。信号仿真参数为载波频率6kHz,采样频率15kHz,码元速率2000bit/s的二进制序列。信号类别有2ASK,4ASK,2FSK,4FSK,8FSK,2PSK,4PSK,16QAM,32QAM,OFDM十类数字调制。仿真信噪比从-5dB至20dB,步长为2dB的零均值高斯白噪声信道。训练集和测试集由仿真信号库随机抽样而得。识别率统计曲线为十次重复仿真求和求均值绘制而得,减小随机因素对实验的影响。
4.1 预分类算法仿真
为验证本文算法中预分类的识别效果开展了预分类算法仿真,训练集和测试集分别为3600和600个高阶累积特征片段,稀疏自编码器作分类器。SNR=0dB时,预分类的识别结果绘制混淆矩阵绘制如图3所示。
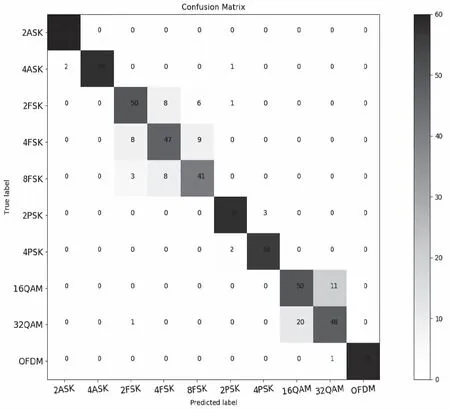
图3 SNR=0dB时 预分类输出混淆矩阵
由图3中可见知,预分类后2ASK,4ASK,2PSK,4PSK,OFDM这五类信号的单类识别率较高,MFSK和MQAM信号的单类识别率较低。MFSK信号的综合识别率为0.7,MQAM信号的综合识别率为0.81,低于其它五类调制类型的识别率。构思将MFSK和MQAM信号作为独立标签,通过预分类和其它类型初步分离,再进一步提取更针对MFSK和MQAM的高阶累积特征,高阶特征阈值判决进一步分类,提高整体识别率。不同信噪比下开展了预分类算法与HOCF-SAE算法实验,训练集和测试集分别为6000和2000个高阶累积特征片段。两者综合识别率进行对比,实验结果如图4所示。
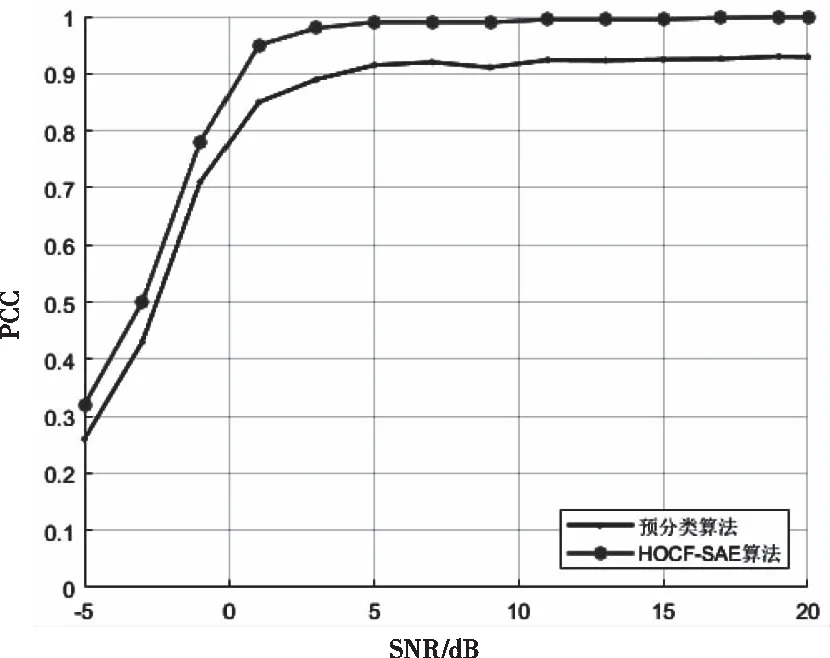
图4 初分类算法与HOCF-SAE算法的PCC对比图
由图4可知,在预分类的基础上,利用高阶累积特征独立对MFSK和MQAM信号进行分类,HOCF-SAE算法的整体识别效果较预分类有所提高。开展了HOCF-SAE算法中稀疏自编码器替换其它机器学习分类器的对比实验,对比组机器学习分类器为XGBoost、SVM、DecisionTree和KNN。训练集和测试集分别均为4000和2000个高阶累积特征片段。不同信噪比下的五种算法的综合识别率曲线绘制如图5所示。

图5 不同分类器的PCC与SNR之间的曲线关系图
由图5分析可知,HOCF-SEA算法略高于HOCF-XGBoost算法的识别效果。较HOCF-SVM算法、HOCF-Dicision Tree算法和HOCF-KNN算法的识别效果更好。深度学习分类器对调制信号的微弱特征有着更强的表征能力,因此稀疏自编码器级联Softmax作分类器较对比组的机器学习分类器在本算法结构下取得更好的效果。
4.2 算法识别仿真
为验证本算法的整体识别效果,开展了所提HOCF-SEA算法与其它自动调制识别算法的对比实验,对比算法包括是文献[10]所提算法1:基于高阶累积量和堆叠自动编码器算法,简称HOC-StackEA算法;文献[19]所提算法2:基于高阶累积量和小波变换的算法,简称HOC-WT算法。文献[20]所提算法3:利用稀疏自编码器的算法,简称Sparse-EA算法。训练集和测试集分别为12000和4000个特征参数片段。不同信噪比下,识别率曲线绘制如图6所示。
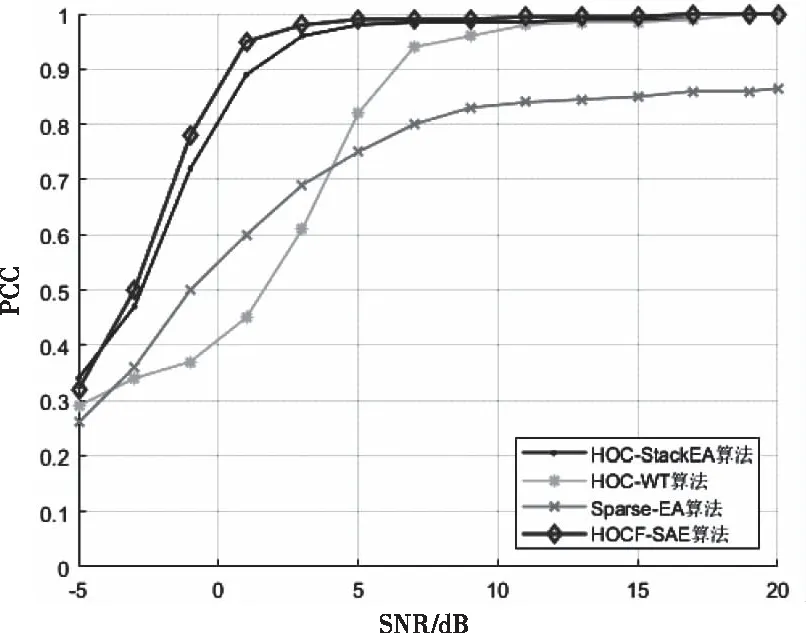
图6 不同算法的PCC与SNR之间的曲线关系图
从图6可看出在SNR小于5dB时,本文所提算法与算法1的识别效果几乎持平,相算法2和算法3有整体的提高,在SNR>10dB时所提算法、算法1和算法2综合识别率均取得1.0。由于高阶累积量和高阶累积特征的应用,极大程度上减轻了WGN对系统的干扰,因而本算法在低信噪比环境下仍然具有良好的识别效果,在SNR=0dB时,综合识别率达到0.87,在SNR=5dB时,综合识别率趋于1.0,较算法1和算法2表现更好。
4.3 算法复杂度分析
本文对所提算法、算法1和算法2的复杂度进行了对比分析,其空间复杂度如表4所示。
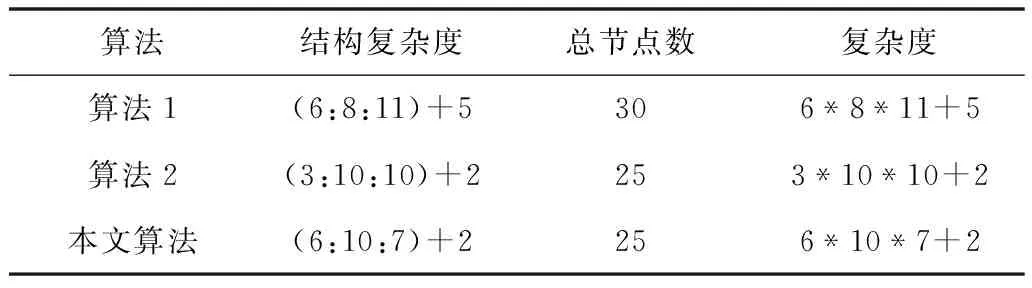
表4 不同算法的空间复杂度对比
本文算法的结构复杂度可用(6:10:7)+2表示,其中(6:10:7)代表稀疏自编码机的网络结构,6表示输入层节点个数,10表示输出层节点数,7表示输出层的节点数。2表示阈值特征Fα和Fβ提取的节点数。算法1的网络结构为(6:8:11)+5,6表示堆叠自编码机输入层节点个数,8表示隐藏层单元数,11表示softmax层节点数,5为特征参数进行判决的节点数。算法2的网络结构为(3:10:10)+2,3表示神经网络输入节点数,隐含层和输出层节点数均为10,2表示特征参数提取过程的节点数。由复杂度对比可知,所提算法的复杂度相对算法2持平,较算法1更低,是由于隐含层的节点数较算法1少。
5 结论
本文提出一种基于高阶累积特征,结合稀疏自编码器与特征阈值判决的两阶调制识别模型。首先计算各阶高阶累积量,并采取多种构造方法,组合构造若干高阶特征参数,与信号标签组合成高阶累积片段,作为预分类阶段的输入数据;然后经由稀疏自编码器级联Softmax分类器进行预分类;最后根据MFSK和MQAM的特性构造了对应的高阶特征参数,设置阈值参数,运用判决算法完成二阶分类,最终实现了十类数字调制方式的自动识别。仿真验证,相比于对照组调制识别算法,在低信噪比环境中,综合识别率有所提高。并且随着信噪比的提高,综合识别率更快的趋于1.0,且算法整体复杂度较低。本文算法依赖较为较大量的样本数据和复杂的高阶组合特征,下一步可针对更小的样本或更新的高阶特征组合方式展开研究。
