基于深度置信网络的多变量时间序列分类方法
2022-01-22朱海浩祝永新
朱海浩,祝永新,汪 辉
(1.中国科学院上海高等研究院,上海 201210;2.中国科学院大学,北京 100049;3.上海科技大学信息科学与技术学院,上海 201210)
1 引言
多变量时间序列(Multivariate Time Series,MTS)指的是在同一时间内,多个变量有序地记录观测数据[1]。它是一种复杂的结构化对象,MTS通常由传感器获取,其多个变量之间存在相关性,具有高维性和可变性等特点[2]。在各个领域中,更是得到了广泛的应用,如语音识别、监控视频、气象信息的获取、医疗技术和金融技术等。对于多变量时间序列的分类,一直都是时间序列分析相关领域重点研究项目和热点问题之一。
文献[3]提出基于BP和朴素贝叶斯的时间序列分类模型,采用BP神经网络非线性映射能力,结合朴素贝叶斯分类器,标记数据分类能力,在朴素贝叶斯分类器中,设定BP神经网络作为输入特征,实现时间序列分类,该方法具有较高的分类准确度,但分类时间较长。文献[4]提出基于shapelet的时间序列分类方法,通过分析优化现有时间序列shapelet发现算法,将其划分为两类,分别为空间搜索发现shapelet和目标函数优化学习shapelet并进行应用,采用shapelet的一元时间序列和多元时间序列分类算法,实现时间序列分类,该方法的分类时间较短,但存在分类精度较低的问题。
针对上述问题,提出了基于深度置信网络的多变量时间序列分类方法。利用深度置信网络,基于受限玻尔兹曼机,提取特征信息,减少参数寻优空间范围,采用Isomap算法,附加约束构造半正定矩阵,实现降维处理,提高泛化能力,利用支持向量机实现对多变量时间序列的分类。提出方法具有较好的分类性能和泛化性能,能够有效降低分类时间。
2 深度置信网络构建
深度置信网络由一层BP(Back Propagation)神经网络和若干层受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)栈式叠加构成,在时间序列分类领域应用非常广泛。
2.1 深度置信网络结构
DBN的学习主要通过两个过程来实现:预训练和微调[5-6]。通过这两个过程的无监督学习和有监督学习后,可使模型达到理想的状态,并且在数据不足的情况下仍然可以表现出很好的效果。与此同时,这种训练方法可以在一定程度上减少参数寻优的空间范围,由此减少有监督的训练时间。DBN模型结构如图1所示。
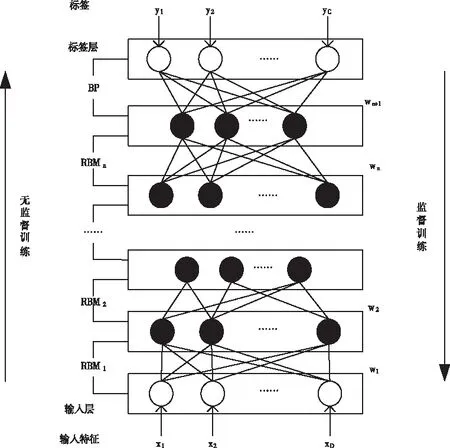
图1 DBN模型结构
2.2 受限玻尔兹曼机下特征信息提取
受限玻尔兹曼机主要由隐藏单元和可见单元两层神经网络构成,连接单元与单元之间的线段为权值[7],RBM模型结构如图2所示。

图2 RBM模型结构
从图2中可知,可见单元与可见变量v相互对应,隐藏单元与隐藏变量h相对应[8]。RBM是在能量函数的基础上延伸而来的。假设已知一组状态为(v,h),那么可见单元与隐藏单元之间的能量函数为

(1)
其中,θ=(w,a,b)表示模型参数,ae、ve分别表示第e个可见单元的偏置信息和状态信息;bq、hq分别表示第q个隐藏单元的偏置信息和状态信息;weq表示连接两个单元e、q之间的权值大小。在式(1)的基础上,计算(v,h)的状态概率如式(2)所示

(2)


(3)


(4)
给定一个训练样本集S=(v1,v2,…,vs),将其容量大小设置为s。计算RBM模型的对数似然函数L(θ),得到模型的参数θ,接下来进行拟合操作,将可见单元与隐藏单元的特征信息拟合在一起,则有

(5)
将RBM模型进行训练,对L(θ)与θ进行对比散度计算。以weq为例,如式(6)所示
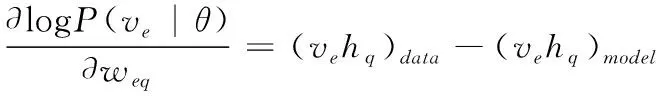
(6)
式中:(vehq)data表示数据分布期望值;(vehq)model为模型最初定义的期望值。具体的期望值,可根据吉布斯采样算法得到。从理论上说,吉布斯采样次数越多,得到的结果越精准,但是从实际应用中发现,只通过一次吉布斯采样就可得到理想效果[11]。因此,本文通过一次吉布斯采样结果作为RBM模型定义的期望值。那么,即可根据式(7)对权重参数weq进行更新计算
weq=ϑweq+η[(vehq)data-(vehq)model]
(7)
式中:ϑ表示动量;η表示学习率。
3 多变量时间序列降维处理
多变量时间序列属于高维数据,需要对多变量时间序列进行降维处理。采用Isomap算法,结合深度置信网络,通过优先特征提取操作,不但有效降低噪声,并且能够将高维数据特征精准映射到对应空间内,具有较好的泛化能力和鲁棒性。
3.1 降维计算


(8)

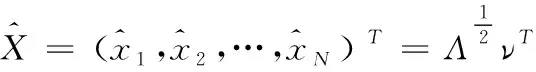
(9)
3.2 算法泛化特征分析
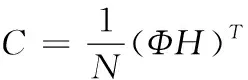
(10)


(11)
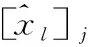
4 低维空间上多变量时间序列分类

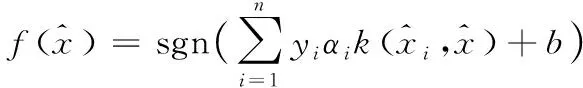
(12)
其中,αi为拉格朗日乘子,n(nN)为与αi对应且不等于零的训练样本数,b为阈值。αi可通过计算式(13)得到
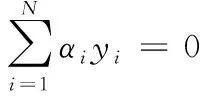
(13)
其中,γ(γ≻0)表示正则化参数,γ的值越大,对经验误差的惩罚也会相应增大。通过求解式(13),可得到αi的值,与αi对应且在αi≻0的情况下得到的训练样本被称为支持向量,数量为n个。b可通过式(14)计算得到

(14)
再通过高斯核函数计算,可得
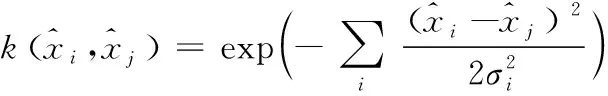
(15)
式中,σ表示核参数。通过上述步骤,在低维特征空间内,通过支持向量机中分线性分类函数,计算得到拉格朗日乘子,凭借正则化参数特性,通过高斯核函数,计算得到最优核函数,完成多变量时间序列分类。
5 仿真研究
为了验证基于深度置信网络的多变量时间序列分类方法的有效性,仿真在Windows7系统上完成,利用eviews5.0软件工具,采用MATLAB7.6搭建实验平台,并分别采用文献[3]方法、文献[4]方法与所提方法进行对比,验证所提方法的有效性。
5.1 实验数据
实验数据集选用三组分别为ASL(Australian Sign Language)、JV(Japanese Vowels)和Wafer。根据三组数据集的序列长度,将其分为两类:ASL和Wafer序列长度较长,可以表达出一个完整的MTS,而JV序列长度较短,可以准确表达出状态点的MTS。接下来具体介绍三组数据集分别为:
ASL数据集:通过多个传感器获取到澳大利亚本地手语者不同语意的序列集合,一种手语者所表达的一种语意用一个MTS表示,实验中选择了270个样本作为数据集。
JV数据集:通过采集9名志愿者产生的12个LPC(Linear Predictive Coding,线性预测编码)同态谱数据描述的日本元音发音,每次发音记为一个MTS。每名志愿者发音次数均不同,采集到640个实验样本。
Wafer数据集:由6个传感器在硅晶体生产过程中采集到的半导体微电子序列,每个硅晶体用一个MTS来表示,并将其分为normal和abnormal两类。实验中选取的样本总数为327个。设置的实验数据如表1所示。

表1 实验数据
5.2 实验内容
为了对比分析三种方法对于不同数据集的分类处理能力,首先需要对数据集进行统计检验。本文使用Friedman检验验证作为显著性水平标准值,通过泛化误差来验证方法的分类性能。
Friedman检验可通过秩对若干个分布的总体是否存在显著差异进行非参数检测。在零假设的环境下,如果方法的泛化误差小于Friedman检验统计量,则方法之间不存在明显的差异性,均为等价关系,分类性能均为相同;如果方法的泛化误差大于Friedman检验统计量,就可以拒绝原假设,认为方法分类性能存在明显的差异性,并且泛化误差越小,表明方法的分类期望风险越小,同时分类集内个体的特征越明显,其分类值越靠近真实值,分类精度越高。
Friedman检验统计量CD计算公式如式(16)所示
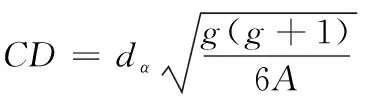
(16)
其中,g表示实验中算法的个数,A表示实验中数据集的个数,α表示算法的显著性水平,dα则表示临界差异。
显著性水平可体现多个分类器之间的性能差异,由于影响分类结果的因素有很多,显著性水平可在进行假设检验时,先确定好一个作为评判标准的小概率标准,通常为0.05,此时临界差异dα值如表2所示。

表2 显著性水平为0.05时dα的值
由表2可知,当显著性水平为0.05时,dα的5种分类器均值为2.3338,结合式(18)可得到标准Friedman检验统计量CD值为1.9051,其中g=3,A=3。泛化误差计算公式

(17)
根据泛化误差计算公式,得到不同方法的泛化误差对比结果如表3所示。

表3 不同方法的泛化误差对比结果
从表3中的数据可知,文献[3]方法、文献[4]方法和提出方法的泛化误差均值分别为1.9797、2.0293和1.9087,由此可知,三种方法的泛化误差均值均大于标准Friedman检验统计量,因此,三种方法的分类性能存在明显差异性。并且通过对比三种方法的泛化误差均值可以得出:2.0293文献[4]方法>1.9797(文献[3]方法)>1.9087(提出方法),提出方法的泛化误差较小,在保持分类集内个体特征显著性的基础上,具有较小的分类期望风险,能够有效提高分类精度,因为提出方法采用Isomap算法,在深度置信网络内进行优先特征提取操作,不但有效降低噪声,并且能够将高维数据特征精准映射到对应空间内,具有较好的泛化能力,从而提高了多变量时间序列分类精度。
在此基础上,进一步验证提出方法的分类时间,分别采用文献[3]方法、文献[4]方法与所提方法进行对比,得到不同方法的多变量时间序列分类时间对比结果如图3所示。

图3 不同方法的多变量时间序列分类时间对比结果
根据图3可知,随着数据集样本总数的增加,不同方法的多变量时间序列分类时间均随之增大。当JV数据集样本总数为640个时,文献[3]方法和文献[4]方法的多变量时间序列分类时间分别为20s和16s,而提出方法的多变量时间序列分类时间为11s。由此可知,提出方法的多变量时间序列分类时间较短,因为提出方法构建深度置信网络模型结构,在一定程度上减少参数寻优的空间范围,由此降低监督训练时间,从而缩短多变量时间序列分类时间。
6 结论
针对当前多变量时间序列分类问题,提出基于深度置信网络的多变量时间序列分类方法,在基于深度置信网络的基础上,对于高维数据,采用Isomap算法进行降维处理,通过支持向量机实现对多变量时间序列的分类。该方法在保持分类集内个体特征显著性的基础上,具有较小的泛化误差,能够有效提高分类精度,缩短多变量时间序列分类时间。
