改进进化算法的贝叶斯网络结构学习及其应用
2022-01-13郭文强毛玲玲黄梓轩肖秦琨郭志高
郭文强,毛玲玲,黄梓轩,肖秦琨,郭志高
(1.陕西科技大学 电子信息与人工智能学院,陕西 西安 710021;2.西安工业大学 电子信息工程学院,陕西 西安 710021;3.伦敦玛丽女王大学 电子工程与计算机科学学院,伦敦 E1 4NS)
0 引言
贝叶斯网络(Bayesian network,BN)是概率图模型的重要研究方向,主要用于表征和解决不确定性问题[1],并在故障溯源、医疗诊断和金融学习等领域得到了广泛的应用[2]。BN研究主要由结构学习、参数学习和推理3部分组成[3],其中,结构学习是BN构建与应用的基础与核心[4]。文献[5]提出了最大最小爬山(max-min hill-climbing,MMHC)算法,通过条件独立性构建初始结构,并结合爬山法学习贝叶斯网络结构,但算法存在学习耗时过长,且容易陷入局部最优的问题。进化算法(evolutionary algorithms,EA)使用启发式搜索策略能够在一定程度上避免算法陷入局部最优,主要通过种群中个体的选择、重组和变异等基本操作实现优化问题的求解。文献[6]基于最大信息系数和微生物遗传算法提出了一种新的贝叶斯网络结构学习,但耗时长,初始种群数目等先验参数的确定缺乏客观依据,存在一定的进化搜索盲目性等问题。
为解决上述问题,本文基于最大支撑树(most weight supported tree,MWST)[7]和EA,提出了一种新的贝叶斯网络结构学习算法MWST-EA。该算法将结构学习转化为进化问题后,先建立最大支撑树来得到种群中节点的父节点数目上限,采用本文设计的种群数目计算函数可以计算出种群数目;同时,采用条件独立性测试获得初始结构来限制搜索空间。其次,采用设计的变异函数来控制基因突变,可以提高算法的局部搜索能力,防止陷入局部最优。最终,通过种群的迭代操作学习出BN结构。
糖尿病是一种不可治愈的慢性疾病,据国际糖尿病联盟统计,截至2020年,全球糖尿病患病率约为9.3%[8]。目前糖尿病的发病机制尚未完全明确,多数学者认为在糖尿病病程发展的过程中,有多种因素对其产生作用,具有极大的不确定性。仅仅依靠医生个人经验的诊断方式,容易出现病情诊断不及时的情况。将糖尿病与机器学习相结合来辅助医生诊断,将在很大程度上提高诊断的智能性和实时性。文献[9]运用正余弦优化算法和神经网络相结合,为糖尿病的自动化诊断提供了一种智能方法。文献[10]提出了一种遗传算法模型用于糖尿病风险预测,辅助医生进行早期干预。文献[11]使用朴素贝叶斯(naive Bayes,NB)和支持向量机(support vector machine, SVM)等分类技术对糖尿病进行了预测。
本文将MWST-EA应用于加利福尼亚大学欧文学院分校David Aha博士搭建的UCI数据库中的糖尿病数据集[12]上,建立贝叶斯网络结构分类模型,取得了较好的结果。
1 贝叶斯网络结构学习改进算法MWST-EA
在贝叶斯网络结构中,事件节点容易确定,但节点间的关系错综复杂难以确定,并且从数据中学习贝叶斯网络结构是一个难题。因此,本文提出了一种改进型进化算法MWST-EA,来确定贝叶斯网络节点和节点间的依赖关系。
1.1 初始种群建立及个体父节点上限确定
进化算法的种群难以确定,且会影响算法的执行效率和稳定性。本文结合BN结构特点设计了一种确定进化算法种群数目下限的函数,如式(1)所示:
(1)
其中:A为所需的种群数量;λ为变量概率分布的偏度,本文取1;d为BN模型中节点最大父节点个数;ζ为节点的最大状态数;σ为BN模型的Kullback-Leibler(KL)距离,常取0.1;ζ为置信度,常取0.05。
设计的MWST-EA算法从完全无向图开始,为缩小BN结构的搜索空间,将条件独立性测试应用于所有的节点之间。当两个节点之间相互独立,移除节点之间的边,并据此得到初始结构BN0。采用式(1)中的A作为初始种群大小。然后,对初始结构中边连接的两个节点,随机选择边状态,以生成初始种群,并采用GR算法[13]对初始种群个体中产生的环即非法结构进行修正,从而得到结构BN1。
个体在交叉、变异的过程中,一个节点可能会存在多个父节点,显然,初始父节点的个数影响着算法的收敛速度。本文利用互信息构建MWST确定可能的个体父节点上限(individual parent node upper limit, IPI)数目,实现对种群中节点的父节点数量的限制,从而提高学习算法的效率。互信息[14]表示两个变量间的相互依赖关系,以任意两个变量X、Y为例,互信息I(X,Y)为:
(2)
其中:p(X,Y)为变量X和Y的联合概率;p(X)为变量X的概率;p(Y)为变量Y的概率。
MWST算法首先根据节点数据计算所有节点之间的互信息,通过把所有节点间的互信息从大到小进行排列,不断选取互信息最大的边加入最大生成树,并且遍历所有的节点,来完成MWST的建立。本文依据MWST中最大节点度,选择具有最大节点度的节点作为算法中的个体父节点上限数目。图1为个体父节点上限确定。以图1a所示的经典贝叶斯网络中的ASIA网络模型为例,根据MWST算法得出最大支撑树(见图1b),可看出节点6具有最大节点度(见图1c),因此该网络的IPI由节点6决定,其值为3。

(a) ASIA网络模型 (b) 图1a的MWST (c) 最大节点度图1 个体父节点上限确定
1.2 MWST-EA新个体的产生及种群更新
1.2.1 评分函数及个体的选择、交叉
本文采用BDeu评分函数对个体评分,以评分最高的个体作为精英个体x*。设X={X1,X2,…,Xn}是一组变量集合,D={D1,D2,…,Dn}是关于变量的样本集合,G是关于变量集的BN结构。假设数据集满足独立同分布条件假设,则BDeu评分如式(3)所示[15]:
(3)

为提高种群的局部寻优能力,挑选评分高的一半个体进行交叉操作。均匀交叉算子的性能较为优越[16],利用均匀交叉算子组合生成新的个体,在搜索空间进行有效搜索,同时降低对种群有效模式的破坏概率。
1.2.2 精英集构建及候选父节点数目限制
建立精英集e,以精英集中的每个个体作为种群的领导者,可以保证算法的寻优能力。
(4)
其中:精英资格阈值β∈[0.5,1];f(xk)为每个个体的评分;fbest为精英个体的评分。为了保持精英集的多样性,以增加进化算法的搜索能力,β在每次种群更新时的变化依据DiG-SiRG算法[17]。
MWST-EA将个体具有可变状态的边定义为位点,位点中每组有值的组成部分被定义为等位基因。构建边频次权重EFW=(wi,j),wi,j对应于等位基因i∈{b,←,→},即“无边”、“反向边”、“正向边”出现的概率,j∈{1,2,…,L}(L为个体长度)。wi,j是精英集合中位置j处等位基因i出现的概率。
其中:当个体xk在位点j的等位基因等于i时,δ函数δ(xk,j=1)等于1。
有效地限制候选父节点数目,能加快BN结构寻优速度。采用父节点重复权重来选择要删除的边以限制父节点数量。父节点重复权重是为每个节点定义的键值向量,其中键值由其父集中节点的索引给出,代表整个精英集中边(父节点→节点)出现的概率,由个体的评分决定。为每个节点Xt填充与边相关的概率(父(Xt)→Xt),通过随机排序为每个节点Xt构建父节点重复权重,删除出现概率最小的边。ASIA网络父节点限制如图2所示。

图2 ASIA网络父节点限制
以图1a的ASIA网络模型为例,个体父节点上限设置为3,精英集由图2中的3个精英集个体组成,对其他非精英个体的6节点进行父节点数目限制。要删除的边是在精英集中频率出现最低的边。个体1要删除节点2至节点6的有向边;个体2要删除节点1至节点6的有向边和节点5到节点6的有向边;个体3满足父节点数量为3的要求,所以不需要删除节点。通过上述操作来保证每个个体中节点6参与进化、寻优的父节点初始数目不超过3。
1.2.3 个体变异率函数
为避免算法陷入局部最优,本文提出了一种新的变异函数来更新种群。通过上述EFW和精英集为种群中的每个个体xk的每个点j∈{1,2,…,L}计算个体变异率υi,j,如式(6)所示:
(6)
其中:wi,j为EFW的第(i,j)个元素;f(xk)为当前个体的评分;fbest为精英个体的评分;ε为一个极小正数,避免零概率。每个突变率都是基于边在精英群体中的分布以及个体的评分函数来衡量的。
1.3 MWST-EA结构学习算法步骤
本文提出的MWST-EA结构学习算法步骤如下:
步骤1 设置算法最大迭代次数Iter,利用互信息建立最大支撑树MWST,由最大节点度得到个体父节点上限数目IPI;采用式(1)计算种群数目。
步骤2 采用条件独立性测试获得初始结构,生成初始种群P0,利用GR算法[13]修正种群中个体产生的非法结构。
步骤3 依据式(3)对每个个体进行评分,挑选评分高的一半个体作为新种群P1进行均匀交叉操作,得到种群P2。
步骤4 对种群P2评分得到精英个体,将个体评分与P2代入式(4)构建精英集e。
步骤5 依据个体评分函数和将精英集e代入式(5)构建边频次权重。
步骤6 构建父节点重复权重对种群P2中个体的父节点个数进行限制,得到种群P3。
步骤7 利用式(6)计算个体的突变率,对种群P3进行变异操作增加种群的多样性,得到新种群P。
步骤8 若当本次迭代达到迭代次数Iter, 则输出精英个体对应的BN结构模型;否则转至步骤3, 进行迭代计算。
2 MWST-EA结构学习算法仿真实验
实验采用的编程环境为Windows10系统,处理器为Intel 酷睿i7 4712MQ(2.3 GHz),8 G内存,开发语言为MATLAB R2016b。为验证MWST-EA的BN结构学习性能,基于经典BN模型-Alarm网[2]进行仿真实验,Alarm网包含37个节点和46条边。为体现本文算法的优越性,在相同实验条件下,与MMHC算法、传统EA进行实验对比及结果分析。
实验中以Alarm网络作为基础,随机生成数据容量分别为500、1 000、3 000和5 000的训练数据样本集,利用MWST-EA进行10次仿真实验,结果取平均值以减少随机性影响。实验中设置种群迭代次数Iter为100,模型置信度ζ取0.05,精英资格阈值α为0.9。由式(1)计算得到种群数目为101。
表1为不同数据量下各算法学习Alarm网的BDeu平均评分对比,表2不同数量下为各算法学习Alarm网的平均运行时间。
由表1可知:MWST-EA在不同数据量的情况下,得到的BDeu评分优于MMHC和传统EA等算法。
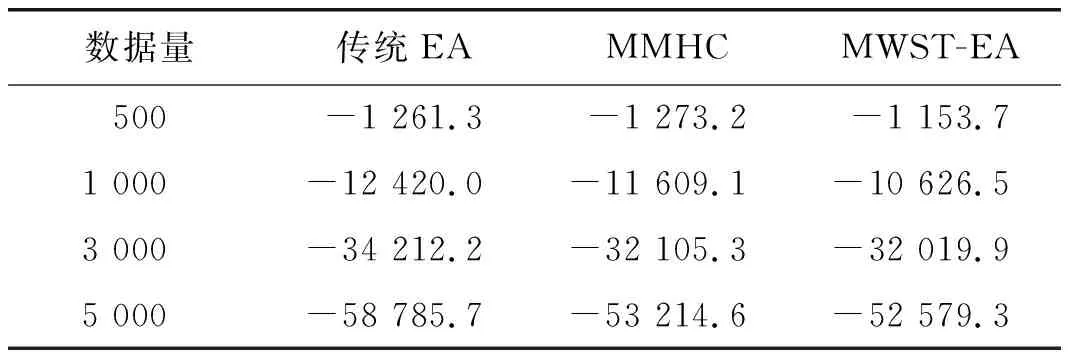
表1 不同数据量下各算法学习Alarm网的BDeu平均评分
原因是MMHC算法搜索能力有限,而传统EA启发函数容易陷入局部最优。本文提出了改进的变异函数来更新种群,可以有效防止进化过程陷入局部最优,从而学出更好的BN模型。
由表2可知:MWST-EA运行时间明显小于MMHC算法耗时,同时也优于传统EA。原因是MWST-EA采用了有效的种群数目和节点的个体父节点数目限定策略,缩小了算法的搜索空间,因此算法的执行效率较高。

表2 不同数据量下各算法学习Alarm网的平均运行时间 s
将本文算法学习得到的网络结构与Alarm网原模型进行对比,计算得到网络与标准网中相同边的数量(samesides,SS)、增加边的数量(added sides,AS)和丢失边的数量(missing sides,MS)。Alarm学习得到的相同边、增加边和丢失边数量统计如图3所示。
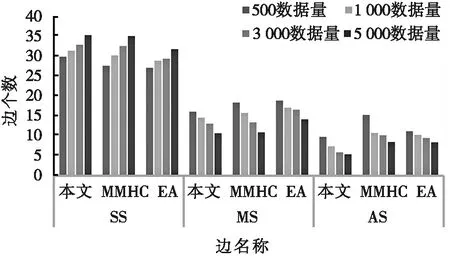
图3 Alarm网络仿真对比
通过图3对比可知:在Alarm网络中,MWST-EA的相同边个数,在不同数据量下,均大于MMHC算法和传统EA;MWST-EA的丢失边、增加边个数也小于其他算法。这是由于算法生成了较好的初始种群,用改进的变异函数来更新种群,提高了算法寻优的能力。
综上所述,MWST-EA结构学习算法速度快于MMHC算法和传统EA,且结构寻优能力更强。
3 MWST-EA在糖尿病诊断中的应用
3.1 实验设置
本节实验条件与上节实验的设置相同,所采用的UCI数据库中糖尿病数据集[12]包含520个实例信息,每个实例中包含17条属性,对数据库中的属性做属性标签,其中,节点1设置年龄段19~35岁为状态1,36~59岁为状态2,60岁及以上为状态3;节点2设置性别Male为状态1,Female为状态2;节点3~16中,Yes为状态1,No为状态2;节点17设置Positive为状态1,Negetive为状态2。数据集描述如表3所示。
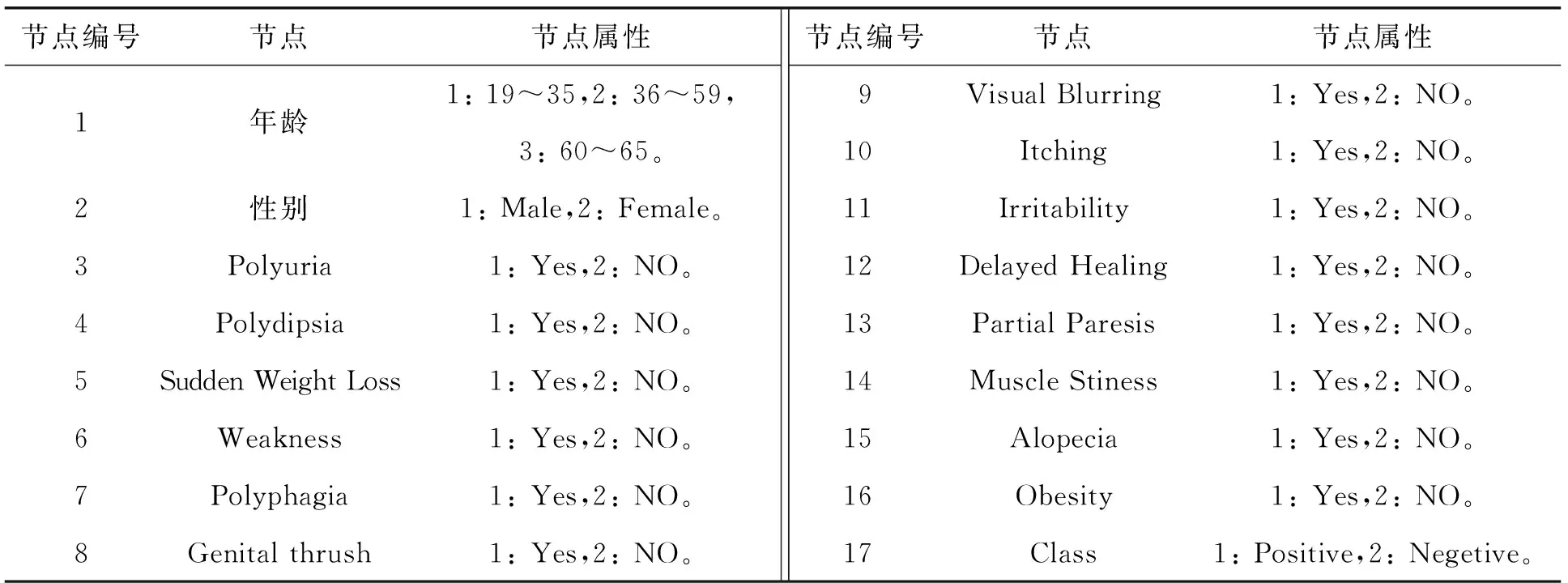
表3 数据集描述
为了验证本文提出的基于MWST-EA结构学习算法的糖尿病诊断方法的有效性,采用十折交叉验证法,将糖尿病数据库中的468组数据用来训练,52组数据用来测试。对10次实验结果取平均值进行性能评价。
3.2 基于MWST-EA的糖尿病分类模型
采用MWST-EA,首先依据样本中各节点的数据来计算互信息。图4为糖尿病数据模型构建。将互信息从大到小排序,遍历所有的节点来确定糖尿病数据构成的最大支撑树模型,以此确定种群中每个个体的各节点的父节点数量上限数目,如图4a所示;接下来,对所有节点之间进行独立性测试,据此得到初始结构用来构建种群,其初始结构如图4b所示;依据3.1节参数设置,由式(1)计算得到种群数量为108,初始化种群之后,采用MWST-EA对种群进行多次迭代得到最优的贝叶斯网络结构图,如图4c所示。
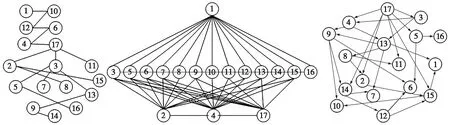
(a) 最大支撑树模型 (b) 初始结构 (c) 糖尿病分类模型的BN结构
由文献[12,18]可知,糖尿病与性别、多尿、多饮、体质量突然减轻、烦躁、肌肉僵硬、脱发等有关。由图4可直观地看到:糖尿病与节点2、3、4、5、11、14、15有直接依赖关系。由此可见,MWST-EA学到的模型与专家经验相吻合,具有较强可解释性。
3.3 实验分析
贝叶斯网络结构学习完成后,用最大期望(expectation maximization,EM)算法[19]对糖尿病分类模型进行参数学习。设置EM算法实验迭代次数为5 000次,以得到BN模型的参数。在BN结构和参数确定之后,利用BN对是否有糖尿病进行诊断。本文采用联合树精确推理算法[20]来进行BN推理。将推理结果与MMHC、传统EA、NB[11]和SVM[11]等算法进行对比,实验结果如表4所示。
由表4可以看出:SVM算法是目前4种算法中识别率最高的,但MWST-EA与SVM算法相比平均识别率提升了1.54%;与MMHC算法相比,MWST-EA性能提升了11.15%。本文的MWST-EA算法构建出的BN模型结构进行糖尿病诊断识别率有明显提高。
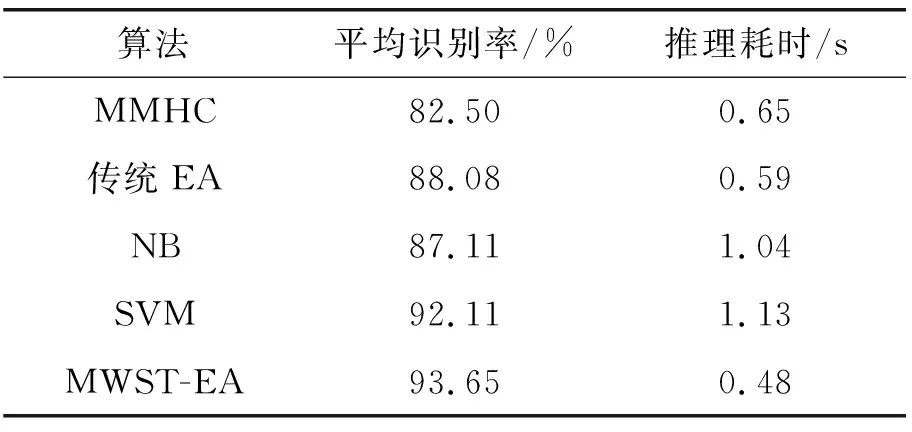
表4 不同建模方法的实验结果对比
为进一步验证本文算法的性能,实验对不同方法在十折交叉验证情况下的时间进行对比,结果如图5所示。从图5中可以看出:本文算法的推理耗时与传统EA和MMHC算法基本相同,相比NB算法和SVM算法的耗时则明显降低。这表明MWST-EA算法构建出的BN模型在推理速度方面性能优良。

图5 不同建模算法推理耗时对比
4 结束语
针对传统进化算法学习贝叶斯网络结构存在收敛速度慢、局部搜索能力差以及种群数目确定缺乏依据的问题,本文提出了一种改进进化算法的BN结构学习算法MWST-EA。该算法利用条件独立性构建初始结构和设计的个体父节点上限数目函数共同作用,减少了搜索的盲目性,缩减了BN结构的搜索空间,提升了算法的寻优效率和收敛速度。采用改进的变异函数可避免算法陷入局部最优。对比实验结果表明了本文算法在BN结构学习性能的优越性,为智能系统的建模提供了一条新途径。未来工作将考虑把进化算法与其他算法相结合,学习得到更优的贝叶斯网络结构。
