英语网络非正规语言表达的自动识别与术语库构建
2022-01-12夏榕璟张克亮
夏榕璟 张克亮






摘 要:网络非正规语言表达(Network Informal Language Expression, NILE)具有的创新性强、超常规化、表达方式口语化等特点,为许多自然语言处理任务带来了挑战。在使用网络语言进行交流的过程中,部分网络非正规语言表达逐渐标准化和规范化,形成网络非正规语言表达术语。通过对46万余条Twitter数据的收集、处理和分析,英语网络非正规语言表达可以在音、形、义层面划分为13类,并对其特征进行分析和总结。结合统计方法和规则方法的优点,设计了统计和规则融合的英语网络非正规语言表达自动识别方法。最终构建规模为7000余条的网络非正规语言表达术语库。
关键词: 网络非正规语言表达;自动识别;术语库
中图分类号:N04; H083 文献标识码:A DOI:10.12339/j.issn.1673-8578.2022.01.004
Automatic Recognition and Terminology Database Construction of English Network Informal Language Expressions//XIA Rongjing, ZHANG Keliang
Abstract: Network Informal Language Expression (NILE) has the characteristics of novelty, unconventionality and colloquialism,which poses a challenge to many natural language processing tasks. In the process of using online language for communication, some NILEs are gradually standardized and normalized, forming a crucial part of the NILE terminology. By collecting, processing and analyzing more than 460 000 tweets, we divide English NILEs into 13 categories from the perspectives of sound, form and sense, and further analyzed their characteristics. Taking the advantage of statistic-based approach and rule-based approach, we design an automatic English NILE recognition system based on the integration of statistical techniques and linguistic rules, and thereupon build a terminology database of 7000 NILE items.
Keywords: Network Informal Language Expression (NILE); automatic recognition; terminology database
引言
術语(terminology)指在特定领域用于表示概念的称谓的集合,是思想和认识交流的工具,具有单义性、纯概念性、理据性、简洁性、构词的能产性、稳定性与国际性[1]。每一个具体术语具有上述八种属性的部分或全部属性。
网络非正规语言表达(Network Informal Language Expression, NILE)指应用于网络中的特殊语言形式,可以体现为单词、词组、短语、句子等多种表现形式,但主要为单词和词组两种类型。部分网络非正规语言表达逐渐规范化和标准化,在网络交流中形成了固定用法,具有了术语的性质。因此,网络非正规语言表达是网络非正规语言表达术语的上位概念。网络非正规语言表达术语包括黑客语(leetspeak)、常用语缩写、具有特定用法和意义的符号等多种表达方式。
术语的自动识别和网络非正规语言表达术语库构建的根本目的在于能够使机器“读懂”网络非正规语言表达,服务于自然语言处理任务。例如机器翻译需要准确翻译网络非正规语言表达的含义;情感分析任务需要正确理解网络非正规语言表达的情感倾向。所以,网络非正规语言表达识别和术语库建设具有重要的理论意义和应用价值。
1 相关工作
目前,自动术语识别和抽取可以分为基于规则、基于统计和基于深度学习的方法。但是基于深度学习的方法需要更大规模的训练语料,跨领域能力弱[2],相较于基于统计的方法,其效果提升并不明显,所以统计方法在新词识别中仍有较大优势。
术语识别作为信息抽取中的一个重要任务,目前已有许多研究成果。Pantel和Lin[3]采用互信息来衡量术语的单元度。Chang等[4]利用熵来判别术语。Kamel[5]基于规则提出了一个本体信息抽取系统(OBIE),对Twitter数据中的本体(ontology)进行语义描述[6]。陈飞等[7]基于条件随机场将新词发现转换为序列标注问题,在开放领域识别新词边界。杜丽萍等[8]通过改进的互信息算法,与少量规则相结合,在大规模语料中自动识别网络新词。赵颂歌等[9]引入远程监督的方法解决缺乏大规模训练语料的问题,然后基于自注意力机制的Bi-LSTM模型对科技术语进行自动提取。
关于术语库的建设,早在20世纪80年代,联合国总部已经建立了名为UNTERM(The United Nations Terminology Database)的术语库[10]。刘宇红等[11]设计了“词频统计”“停用词列表”“运用互信息熵和词组教学值”“基于人工语义判断”四个步骤,以英语语言学为例,识别和归纳总结术语,并认为这种识别方法能够迁移到其他学科和领域。
随着网络日益流行,学者对网络语言特征的研究也在不断深入。Zhang和Yao[12]认为网络非正规表达是一种文本噪声,并讨论了与英语关联的网络非正规语言表达的特点。景漾[13]借鉴传统的构词方法,认为英语中网络语言构词方法主要有缩略法、合成法、省略法。刘宇红[14]将语言学术语分为四类,其中“利用现有语言资源进行部分创新”“创造新的术语”和“非常规的术语创新”这三类可以在很大程度上覆盖网络非正规语言表达的形成原因。
在目前的研究基础上,本文拟通过社交媒体数据对英语网络非正规语言表达特征进行分类和分析,结合目前已有的术语识别方法研究英语NILE的识别方法,设计高效网络非正规语言表达识别系统,最后构建英语NILE术语库。
2 英语NILE特征分析
2.1 英语NILE的类型
不同于汉语网络语言中复杂的汉字、字母、数字、符号的混合使用,英语网络非正规表达仅有英语字母、数字、符号以及它们的组合。英语非正规表达可从音、形、义三个层面上进行细化分类,具体分类方法见表1。
表1中展示了按音、形、义划分的13类网络非正规语言表达。在“音”的层面上,英语NILE可分为借用英语字母、数字的英语发音、混合借用英语字母和数字的英语发音和借用英语的音表其他语言的义四小类。在“形”的层面上,英语NILE可分为借用字母的形、借用符号的形、借用数字的形、混合借用字母数字和符号的形、带有符号五小类。在“义”的层面上,英语NILE可分为词义缩略、借用其他语言的语义、旧词新义、旧词组合衍生出新义四小类。
2.2 英语NILE的特征
通過对英语NILE分类整理,可以总结得到NILE识别的两个重点——缩略词和新义词。英语NILE中的缩略词指英语词汇的缩略和混合字母、数字、符号缩略的词或词组,新义词指具有新义的英语单词或由单词组合衍生得到新义的词组。
(1)缩略词分析
缩略法(Abbreviation)是英语的主要构词方法之一,可以分为首字母拼音法(Acronym)、截成法(Clipping)和混成法(Blending)[15],具有非常浓烈的“非正式”特点,是英语NILE词汇的主要构词方法之一。
在13类英语NILE分类中,缩略词覆盖了借用字母的音、借用数字的英语发音、混合借用英语字母和数字的英语发音、带有符号、词义缩略五小类。由于缩略词特征鲜明,基于规则的方法能够有效识别英语NILE缩略词。
部分缩略词在网络文本中常见,已经形成了固定用法,人们一看到这种缩略方法,就会想到这个词,比如“LOL = laugh out loud”“BTW = by the way”。还有一类缩略词是基于话题标签的具有一定时效性的缩略词,例如“MAGA(make America great again)”“KAG(keep America great)”。这类缩略词因社会中某一事件而产生,在一段时间内高频出现,但是过后可能不再使用。同时,这类作为标签的缩略词也有演变为术语的潜力。所以,在构建英语NILE术语库时,应该考虑是否将这类词收录。
(2)新义词分析
对于新义词,英语单词或是构成新义词词组的单词在词典中能够查询得到,但是其在网络中表达的含义和词典中的意义并不相同,或者并不是词典中单词意义的简单堆叠。新义词主要覆盖了上述英语NILE的13类中的“借用其他语言语义”“旧词新义”和“旧词组合衍生出新义”三小类。
基于规则的方法难以识别新义词,然而这三小类NILE往往是机器翻译、情感分析等自然语言处理任务中需要重点解决的问题。
例如,对于“Miley’s new album slayed!”这一句子,常用机器翻译引擎将其翻译为“麦莉的新专辑被淘汰了!”这里“slayed”翻译是错误的。“slay”的原义为“kill in a violent way”,用于物品上被译作“淘汰”。但是作为网络非正规语言表达时,则是语气强烈的褒义词,表示“succeed in something amazing”。该例的意思实际上是“麦莉的新专辑棒极了!”。在中文的非正规表达中,“slay全场”里的“slay”一词也是取它的衍生义,表示“十分厉害而吸引全场”。如果是进行情感分析任务,“slay”的原义和衍生义则是完全不同的两种情感。对于这三小类NILE,本文拟采用统计的方法进行识别。
3 融合统计和规则的英语网络非正规语言表达识别
3.1 英语NILE识别方法
(1)基于统计的方法
英语网络非正规语言表达中,单词和词组为主要表现形式。识别单词类NILE,采用最简单的词频统计的方法;识别词组类NILE,则采用互信息和信息熵的方法。
词频(term frequency, TF)是发现新词或者新短语最直接简单的一种方法,其基本思想是:词语或短语出现的频率表现了单词的重要性;一个未收录的词或者搭配在某一领域文本中出现的频率越高,则是这个领域的新词的可能性越大。对于46万余条Twitter数据,没有必要对所有词都进行词频统计,可以基于WordNet词典过滤停用词和大部分正常使用的单词。此外,由于英语单词具有多种形态,所以词频统计时,需要进行词形还原和词干提取。
点互信息和信息熵常用于中文新词识别任务,可以在不切词的条件下预测文本中的新词。英语文本有空格作为天然的分割符,在分词任务上具有优势。点互信息和信息熵运用于汉语新词预测时,以字为切分单元。在英语文本中,既可以以字母为切分单位识别新单词,也可以以单词为切分单位识别新的单词搭配,即词组或短语。
点互信息(Pointwise Mutual Information)在NLP任务中,表示两个语言单元的相关性。其公式为:
PMIX,Y=log2P(X,Y)PXP(Y)
其中,P(X,Y)表示X和Y两个语言单元的共现概率。PX和P(Y)分别表示X和Y两个语言单元出现的概率。两个语言单元间的点互信息值越大,说明这两个语言单元越是经常一起出现,意味着两个单元的凝固程度就越大,形成一个网络非正规语言表达术语的可能性也就越大。因此,在进行NILE的识别时,可以将语言单元设定为词,识别得到表现为词组形式的“新表达”。也可以设定语言单元为字母,识别词典中未收录的、表现形式为词的“新表达”。
信息熵(Information Entropy)是一种表示信息量的指标,熵越高表示信息量越大,不确定性越高,越难以预测。对于一个随机变量X,其熵可以表示为:
HX=-∑x∈Xp(x)log2p(x)
在NILE识别任务中,p(x)表示一个语言单元出现的概率。左右熵指文本中语言单元的左边界的熵和右边界的熵。通过计算一个候选语言单元左边和右边的信息熵得到一个语言单元是否有丰富的左右搭配,达到一定阈值则可以认为两个语言单元组成一个新词。
在Twitter语料的处理中,点互信息可以识别出“新表达”,这些“新表达”包括“新搭配”的短语或者词。然后通过计算信息熵得到这些“新表达”的信息量,两者结合识别得到潜在的新的NILE。
通过统计的方法,可以初步得到英语NILE术语候选集。
(2)基于规则的方法
基于规则的方法是对统计方法筛选得到的语言单元,通过规则对候选NILE进行进一步识别和确认,得到NILE术语。
根据上述总结和分析得到的特征,设计以下三条规则。
第一,所有字母都为大写字母的语言单元。
对于网络文本,由于人名、地名、机构名常采用全大写的方法,所以在所有字母都为大写字母的语言单元中,命名实体(Named Entity)占很大比例,但是这类命名实体不属于英语NILE。在46万余条Twitter数据中,出现了如“TRUMP(特朗普)”“LOS ANGELES(洛杉矶)”“THE HOUSE(白宫)”等词。这类命名实体可以使用现有的封装好的自然语言处理工具进行识别,因此将这类词从NILE候选集中排除。
第二,带有“#”的语言单元。
在Twitter中,“#”有两种用法,一种是用于固定NILE术语中,如“#FF(等于‘#Follow Friday’,是Twitter中一种分享和推荐的方式,作为一个标签常添加于一条推荐性推文后)”,这种固定用法较少;另一种则表示一个创建或者设定一个话题标签,便于搜索关键词时对相关内容进行过滤。前者收录于NILE术语库中,后者则进一步判断是否具有成为NILE术语的潜力。
标签之间没有空格,这就会出现“#WorstPresidentEver”“#TrumpRallyNJ”等情况。这类标签经过切分后,能够调用常用机器翻译引擎正确翻译,不属于上述的NILE特征分类,所以可以将这类词从NILE候选集中排除。
但是也有可以从这些标签中提取出NILE表达的情况。例如“#GOPTraitors”中的“GOP”是“Grand Old Party”的缩写,在网络语言中用于代指“共和党”;“GetTheGat”拆分得到“get the gat”后,调用百度翻译API,翻译为“去拿服”,不具有可读性。这一标签翻译错误的原因是“gat”是“gun”的一个俚语,“gat”在网络中常代指“gun”。这种情况下,“GOP”和“gat”应该被收录进入NILE术语库中。
第三,混合数字、符号和字母的语言单元。
混合数字、符号和字母的语言单元涵盖了上述NILE分类中的六类。这类语言单元可以通过正则表达式匹配出。满足匹配条件且满足统计条件的语言单元,可以判定为NILE术语。
3.2英语NILE识别系统设计
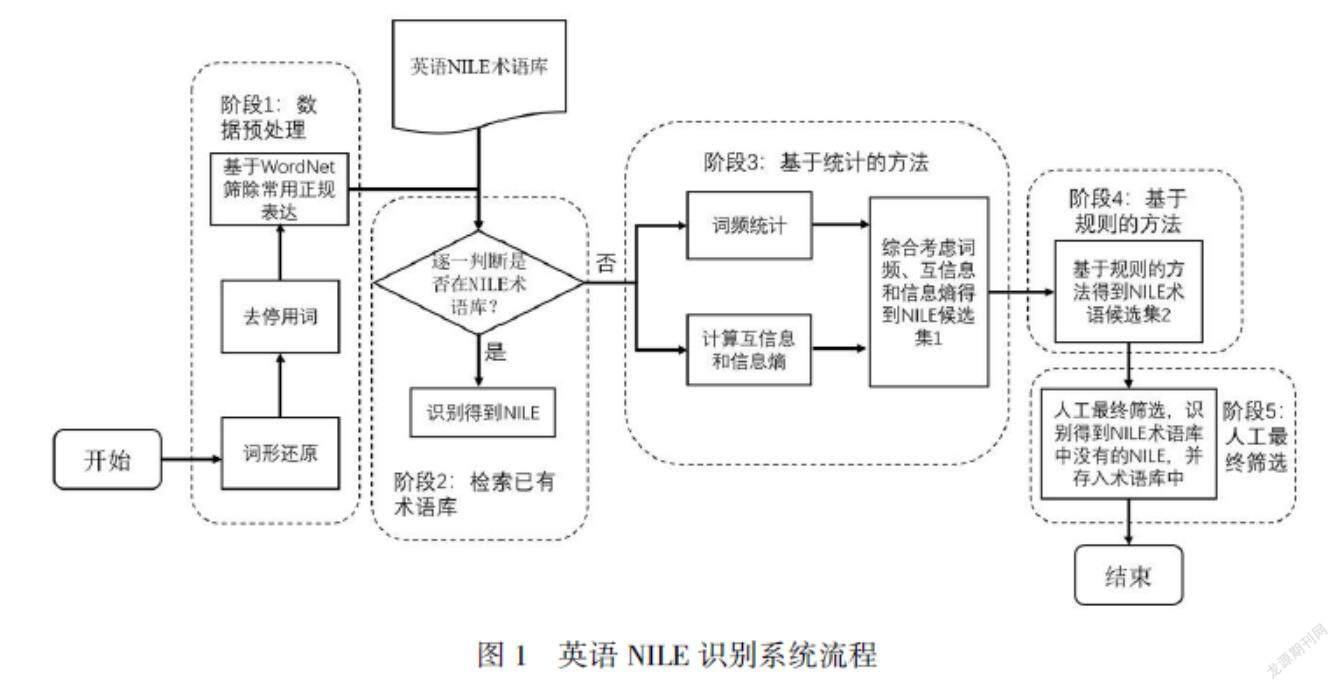
针对英语网络非正规语言表达的特征,设计基于统计和规则融合的英语网络非正规语言表达识别系统,系统结构如图1所示。
总结来说,英语非正规语言表达识别经过数据预处理、判断是否已经在术语库中、基于统计的方法、基于规则的方法、人工最终筛选五个阶段。
在第三阶段基于统计的方法中,词频统计以词为统计单位,点互信息和信息熵兼顾词和短语的统计。词频统计需要基于WordNet过滤停用词和大部分正常使用的单词,得到候选集a。在点互信息和信息熵的计算时,首先计算点互信息,得到一个候选集b,然后计算候选集b中元素的信息熵,最终得到候选集c。候选集a与候选集c取并集得到NILE候选集1。
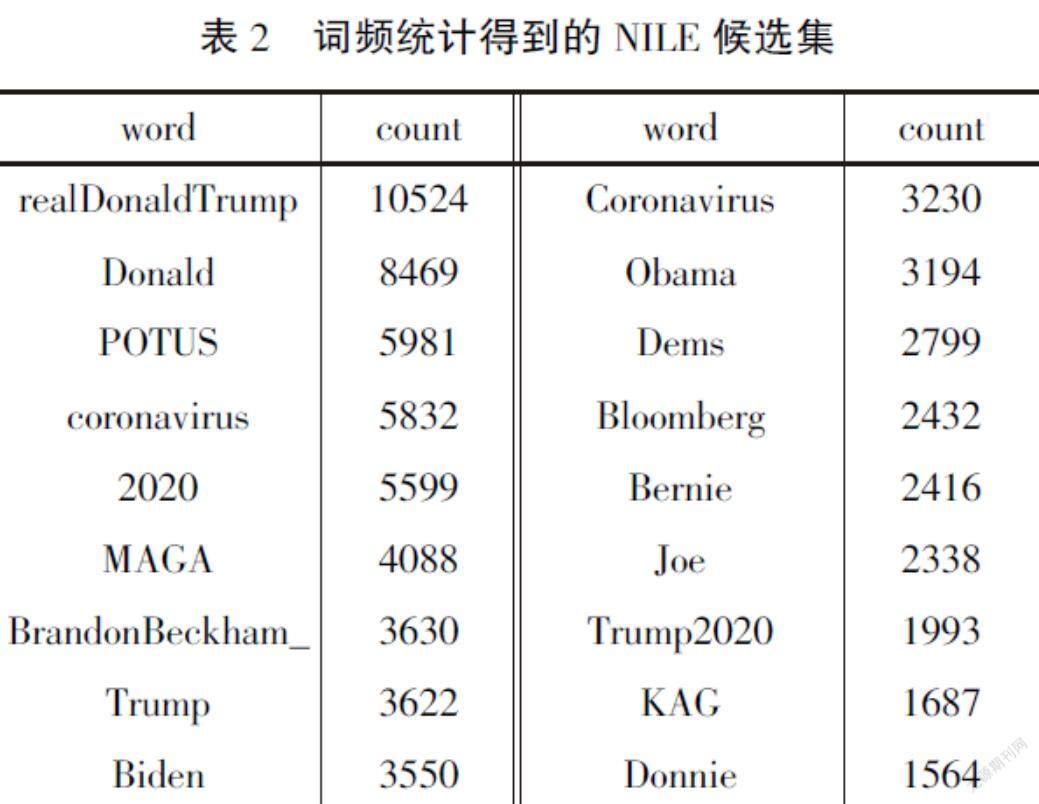
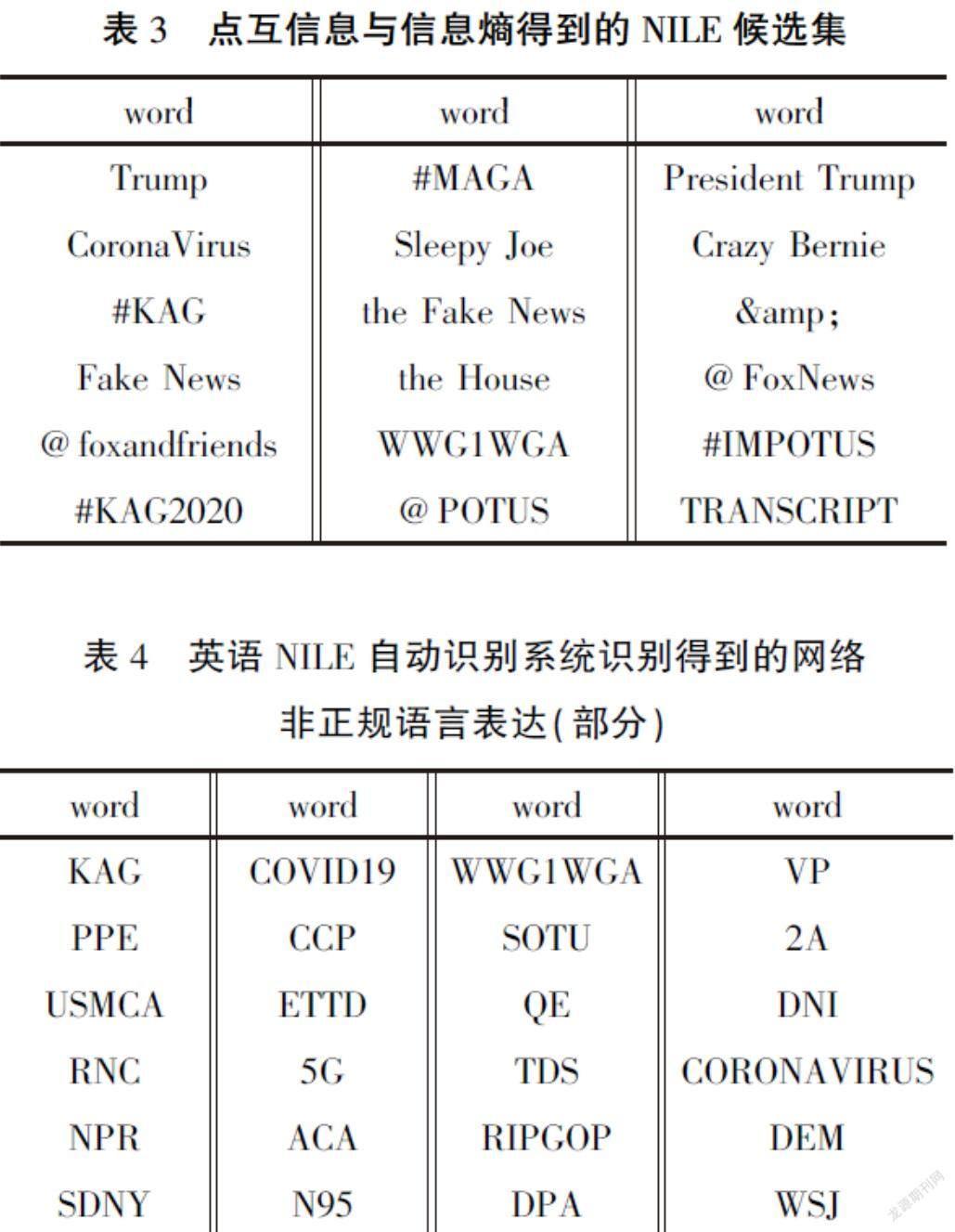
词频统计和点互信息与信息熵计算后,数据放置于.csv文件中,部分数据如表2、表3所示。
可以看出,经过数据预处理、已有术语判断和统计的数据中,很大一部分是命名实体,所以,在基于规则判定之前,需要筛选出命名实体。
阶段4中使用了3.1中的三条规则,在NILE候选集1上进行了进一步的筛选,得到候选集2。最终经过人工一一校验,得到以下NILE术语库中未收录的英语网络非正规语言表达,存储在.csv文件中(如表3所示),共170个未收录的NILE术语。
46万余条Twitter语料,使用AntConc进行统计,语料容量为6 763 672个词,包括不重复的单词93 439个。经过前三个阶段,即统计方法过后,候選集1中共有5828个表达。经过阶段4,即规则的方法的筛选过后,得到272个表达。最终人工筛选后,得到170个术语库中未收录的NILE,且这些表达具有可以演变为NILE术语的潜力,能够收录于NILE术语库中。所以,截止到阶段5,即人工筛选前,NILE术语的自动识别的准确率为62.5%。在46万余条语料中,识别得到的新的NILE术语,约占不重复单词总量的0.182%。
NILE自动识别的准确率并不是很高,NILE术语识别错误的类型和错误原因可以从以下几个方面进行分析:(1)部分识别错误的NILE是非正规表达术语库中的NILE术语的衍生,这类衍生不考虑为NILE术语。例如,“KAG”(Keep America Great)和“POTUS”(President of the United States)是NILE术语,但是“KAG2020”“POTUS45”这类由NILE术语衍生出来的表达不具备术语的八种属性中的任何一种属性。(2)仍然存在部分命名实体的衍生被错误识别为NILE术语。例如,“TRUMP2020”“Sleep Joe”这些表达可以看作命名实体的衍生,但本质上仍然是命名实体,而不是NILE术语。然而,也不是所有带命名实体的表达都不是NILE术语,比如“Uncle Sam”就是美国的绰号,在网络中常被使用。(3)语料本身主题的问题,使得一些短语的点互信息和信息熵很高。例如“Fake News”(假新闻)和“FOLLOW ME”。“Follow”本身是一个NILE术语,作为NILE的含义是“关注”。但是由于语料主题(美国大选)的限制,结合不同的语境,“FOLLOW ME”可以解释为 “跟随我”“支持我”或“关注我”。这是导致NILE术语识别错误的三种主要原因。人能够相对容易地识别出这些错误,但是机器通过统计和规则的方法可能难以判别。
4 英语网络非正规语言表达术语库构建
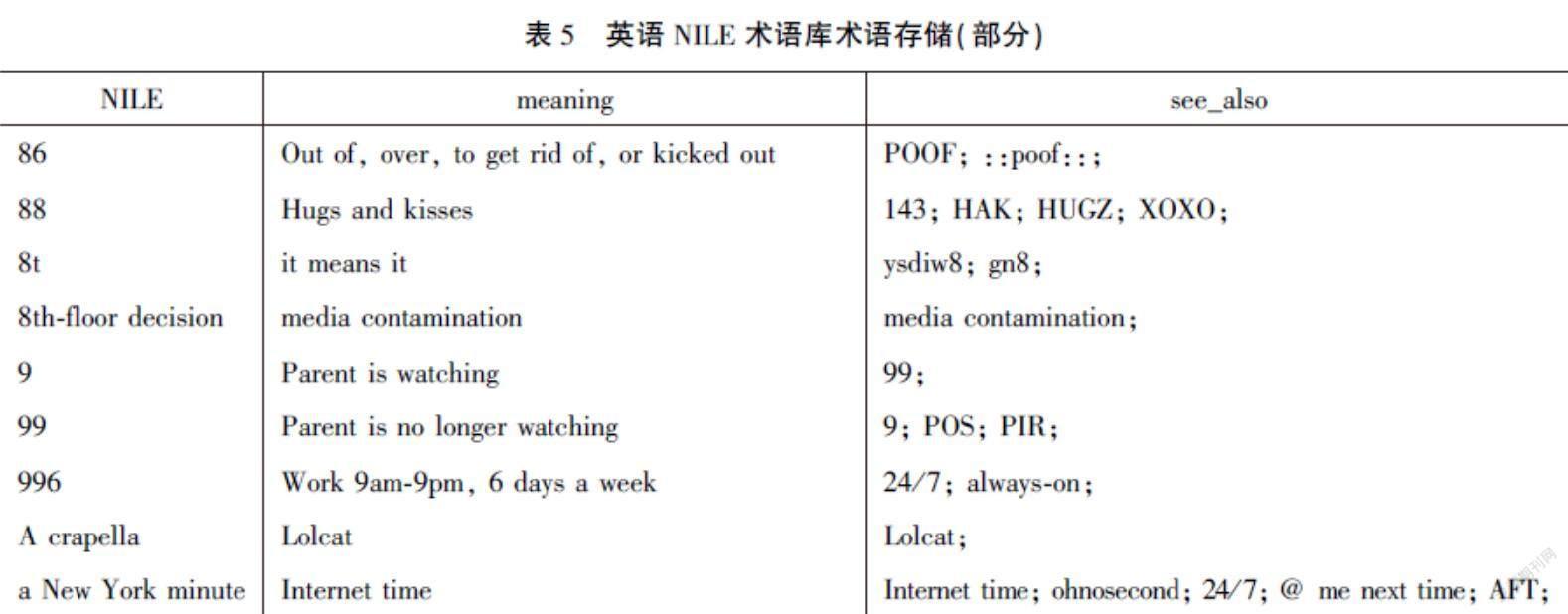
在构建英语网络非正规语言表达术语库时,需要用标准化的、可读的表达解释术语库中的每一个术语。例如,“142n8ly”被解释为“Unfortunately”,“troo”被解释为“true”。所以,术语库中存储的NILE术语需要具有解释性。
通过对数据的分析,能够发现相同的含义有多种表达方式,也就是存在“一义多词”(即同义,synonymy)的现象,例如“LOL (= Laughing Out Loud)”“LOOL(= Laughing Outrageously Out Loud)”“LOOMM(= Laughing Out Of My Mind)”是三个不同NILE表达的缩写,但是都表示“very happy”这一含义,所以可以通过这一含义在这三个不同的表达中构建联系,这种关联可以看作为一种“同义联系”。
如果两个或多个表达之间在含义上相近或者相关,这两个或多个表达之间也应该构建一种联系。例如“luv(= love)”“I <3 U(= I love you)”和“ILI(= I Love It)”虽然表述不同,含义也不尽相同,但都和“love”这一概念有所关联,这种关联关系可以看作一种“相关联系”。
因此,在构建英语NILE术语库时,术语库应该存储某一术语的准确解释上述两种关联。由此设计一个三元组用于存储每一术语。三元组结构如下所示。
<W,E,R>
该三元组中,W表示一个NILE术语,E表示W的解释,R表示关联术语,关联术语间用“;”进行分隔。
术语库的来源主要有两方面。一部分来源于相关网站的数据爬取,得到部分NILE术语信息;另一部分来源于基于上述统计和规则融合的NILE自动识别方法得到的170个未收录的NILE,共得到7000余个NILE术语及相关信息,即7000余个NILE术语三元组。将得到的NILE术语库按符号和字母索引存储于.csv文件中,如表5所示。该.csv文件可以用于进一步构建MongoDB数据库或Neo4j数据库,以提高存储能力和检索效率。
5 结语
对于英语网络非正规语言表达的研究,首先阐述了术语识别方法、术语库建设和网络非正规特征表达的研究现状,总结了英语网络非正规语言表达的特征并对特征进行了分析。针对总结得到的特征,制定三条规则,并且结合统计的方法,设计了基于统计和规则融合的英语网络非正规语言表达识别系统。最后基于两种来源构建了英语网络非正规语言表达术语库。英语网络非正规语言表达识别与NILE术语库构建对于语言学研究和自然语言处理都具有重要意义。
参考文献
[1] 朱伟华.谈谈术语的特性[J].外语教学与研究,1987(2):47-49.
[2] 張雪, 孙宏宇, 辛东兴,等.自动术语抽取研究综述[J].软件学报,2020,31(7):2062-2094.
[3] PANTEL P,LIN D. A Statistical Corpus-Based Term Extractor[M] / / STUMPTNER M,CORBETTD,BROOKS M. Advances in Artificial Intelligence. Berlin Heidelberg: Springer-Verlag, 2001: 36-46.
[4] HANG J S. Domain specific word extraction from hierarchical web documents: a first step toward building lexicon trees from web corpora[C] / / Proceedings of the 4th SIGHAN Workshop on Chinese Language Learning: 64-71.
[5] KAMEL N. Ontology-Based Information Extraction from Twitter[J]. Proceedings of the Workshop on Information Extraction and Entity Analytics on Social Media Data, 2012, 12: 17-22.
[6] 张艳,宗成庆,徐波.汉语术语定义的结构分析和提取[J].中文信息学报,2003(6):9-16.
[7] 陈飞,刘奕群,魏超,等.基于条件随机场方法的开放领域新词发现[J].软件学报,2013,24(5):1051-1060.
[8] 杜丽萍,李晓戈,于根,等.基于互信息改进算法的新词发现对中文分词系统改进[J].北京大学学报(自然科学版),2016,52(1):35-40.
[9] 赵颂歌,张浩,常宝宝.基于自注意力机制的科技术语自动提取技术研究[J].中国科技术语,2021,23(2):20-26.
[10] 顾春辉,温昌斌.联合国术语库建设及其对中国术语库建设的启示[J].中国科技术语,2017,19(3):5-9,34.
[11] 刘宇红, 殷铭.术语表研制的四个步骤:以英语语言学为例[J].中国科技术语,2021,23(2):11-19.
[12] ZHANG X, YAO T. A Study of Network Informal Language Using Minimal Supervision Approach[J]. Autonomous Systems:Self-Organization, Management, and Control, 2008: 978-1-4020-8888-9.
[13] 景漾. 英漢网络词语构词浅析[J].校园英语,2016(2):205.
[14] 刘宇红. 语言学术语的理据类型研究[J]. 中国科技术语,2021,23(1):17-22.
[15] 张怀建, 黎进安, 刘丽燕,等. 新世纪大学英语语法 (下册)[M]. 广州:华南理工大学出版社, 2003:25.
作者简介:夏榕璟(1998—),女,信息工程大学洛阳校区研究生。主要研究方向:自然语言处理、机器翻译、知识图谱等。通信方式:cczxxrj@163.com。
张克亮(1964—),男,博士,信息工程大学洛阳校区教授、博士生导师,主要研究领域为计算语言学、机器翻译、知识工程等。先后兼任中国人工智能学会理事及自然语言理解专委会委员,中国中文信息处理学会机器翻译专委会委员,国家自然科学基金、国家社会科学基金、教育部学位中心学位论文评审专家。长期从事计算语言学和语言信息处理教学科研工作,主持或参与完成国家科技支撑计划、国家自然科学基金、国家社会科学基金、装备科研等10余项课题的研究工作,其中包括主持国家自然科学基金重大项目课题1项,出版专著、编著、词典、教材4部(套),发表中英文论文80余篇。通信方式:kliang99@sina.com。
