作战辅助系统中基于深度学习的投影图像颜色补偿方法
2022-01-10张凤张超杨华民王发斌
张凤,张超,杨华民,王发斌,2
(1.长春理工大学 计算机科学技术学院,吉林 长春 130022;2.吉林师范大学 计算机学院,吉林 四平 136000)
0 引言
随着计算机、人工智能和网络技术的发展,在作战过程中需要处理的数据种类和规模正以前所未有的速度增长。在作战辅助系统中应用投影系统可以实现庞大数据信息的高效可视化,有利于战场数据的实时分析和理解。传统的投影系统大多使用标准的白色投影幕。在野外作战指挥中如何快速搭建投影显示系统,有效消除带纹理物体表面对投影图像的干扰,同时减少环境因素及系统硬件对投影图像产生的影响是需要解决的关键问题。
文献[1]提出了一种不需要相机或投影仪的辐射计量预标定的方法。该方法由投影仪色域的稀疏采样和分散数据插值组成,实时生成从投影仪到摄像机颜色的逐一像素映射。但每一个投影仪的像素并不一定是跟每个相机像素一一对应,这样的简化会影响投影仪光学补偿的效果。文献[2]提出一种感知辐射补偿方法来抵消彩色投影表面对图像外观的影响。该方法基于人眼视觉系统的锚定特性,在保持图像色调和亮度的同时减少了色彩裁剪。该方法还考虑了颜色自适应对感知图像质量的影响,通过将图像像素点的颜色向投影表面的互补色方向适当移动,修正了非白色投影表面引起的颜色失真。但该方法只能补偿投影表面是单一颜色的干扰情况。还有一些传统的投影颜色补偿系统用相机捕捉一系列投影的采样图像,然后拟合一个复合辐射传输函数,消除纹理空间变化的表面反射率影响。这种方法在不同的投影表面上投影时都需要拍摄大量的图片,不能满足作战辅助系统中投影补偿的实时性要求。
近年来,深度学习广泛应用在医学图像[3-4]、遥感[5]、三维建模[6]、军事应用[7-9]等多个领域,为推动人工智能在多个行业的应用发挥了重要作用。深度学习的目的是通过组合低层特征形成更加抽象的表示能力强的特征,以发现数据中有用的宏观信息。温豪等[10]针对多通道三维测量技术,从采集图像的误差类型出发,将系统误差分为图像像素亮度与实际亮度之间的光强误差和图像像素空间分布的位置偏差,以此分别构建了光强误差关系和位置偏差关系并对检测系统进行定量测量。最后提出一种简单有效的系统误差补偿方法,同时补偿了串扰、色差、非线性和畸变等误差对测量结果的影响。在风格迁移中使用深度学习不仅能学习输入图像到输出图像的映射,而且学习一个损失函数来训练这种映射[11-12]。该方法在从标签映射合成照片、从边缘映射重构对象和给图像着色等任务中效果较好。文献[13]借鉴了风格迁移的网络结构,将投影补偿问题定义为端到端学习问题,提出一种隐式学习复杂补偿函数的卷积神经网络CompenNet.CompenNet由一个类Unet的主干网和一个自动编码器子网组成。模型中视觉细节和交互信息也沿着多级跳跃卷积层被带到更深的层。在深度学习中图片特征提取的准确度直接影响输出图片的效果,为提取更多有用特征,对CompenNet网络结构进行改进,并提出使用改进的结构相似性(SSIM)+SmoothL1损失函数,实现在色彩信息更加丰富的投影表面上进行投影的补偿方法。该方法对投影图像进行智能颜色补偿,可有效消除战场环境中投影表面固有的不规则纹理对投影图像引起的视觉偏差,最终摆脱投影设备对专业投影幕布的依赖,将任意自然平面环境作为“白色幕布”进行放映。该方法也可以推广到舞台表演中,使用投影营造震撼的舞台效果受到大众欢迎。本文研究也可改善投影系统的性能,为艺术创造者提供更大的自由创作空间,丰富人们的娱乐生活。
1 改进的CompenNet网络模型
1.1 CompenNet网络模型
CompenNet由一个类似Unet的骨干网络和一个自动编码器子网组成[13]。这种架构可以使相机捕获的投影表面图像和输入图像之间进行丰富的多层次交互,从而捕获投影表面的光度和环境信息。
CompenNet有两个输入图像分别对应相机捕获的未补偿图像和相机捕获的表面图像。两幅输入图像都被送入卷积层序列,进行下采样提取多层次的特征图。投影表面图像和输入图像各自特征图之间的多级交互感知,使模型学习全局光、投影仪特性、投影表面和投影图像间的复杂光谱作用。CompenNet通过跳跃卷积层将低级交互信息传递到高级特征图。中间块在保持特征图宽度和高度不变的情况下,通过增加特征通道提取丰富的特征,然后使用两个卷积层逐步向上采样特征映射到输出图像。
1.2 改进CompenNet架构


图1 改进后的D-CompenNet架构(省略激活函数)
在补偿模型中,两个分支不共享权值,因此分别用不同的颜色给出。投影表面图像特征提取分支输入为相机采集的投影表面背景纹理图像,这一分支提取投影背景纹理特征,每层提取的特征参数都传递给主干分支相应的卷积层。主干分支输入为相机采集的投影图像与投影表面的背景纹理重叠的图像,提取未补偿的投影图像特征。模型中上采样卷积层的输入除了前一卷积层的深层抽象特征外,还有与其对应的下采样层输出的浅层局部特征,将深层特征与浅层特征融合,从而恢复特征图细节并保证其相应的空间信息维度不变。最后输出为投影仪预投影的补偿后图像。表1所示为网络内部结构。
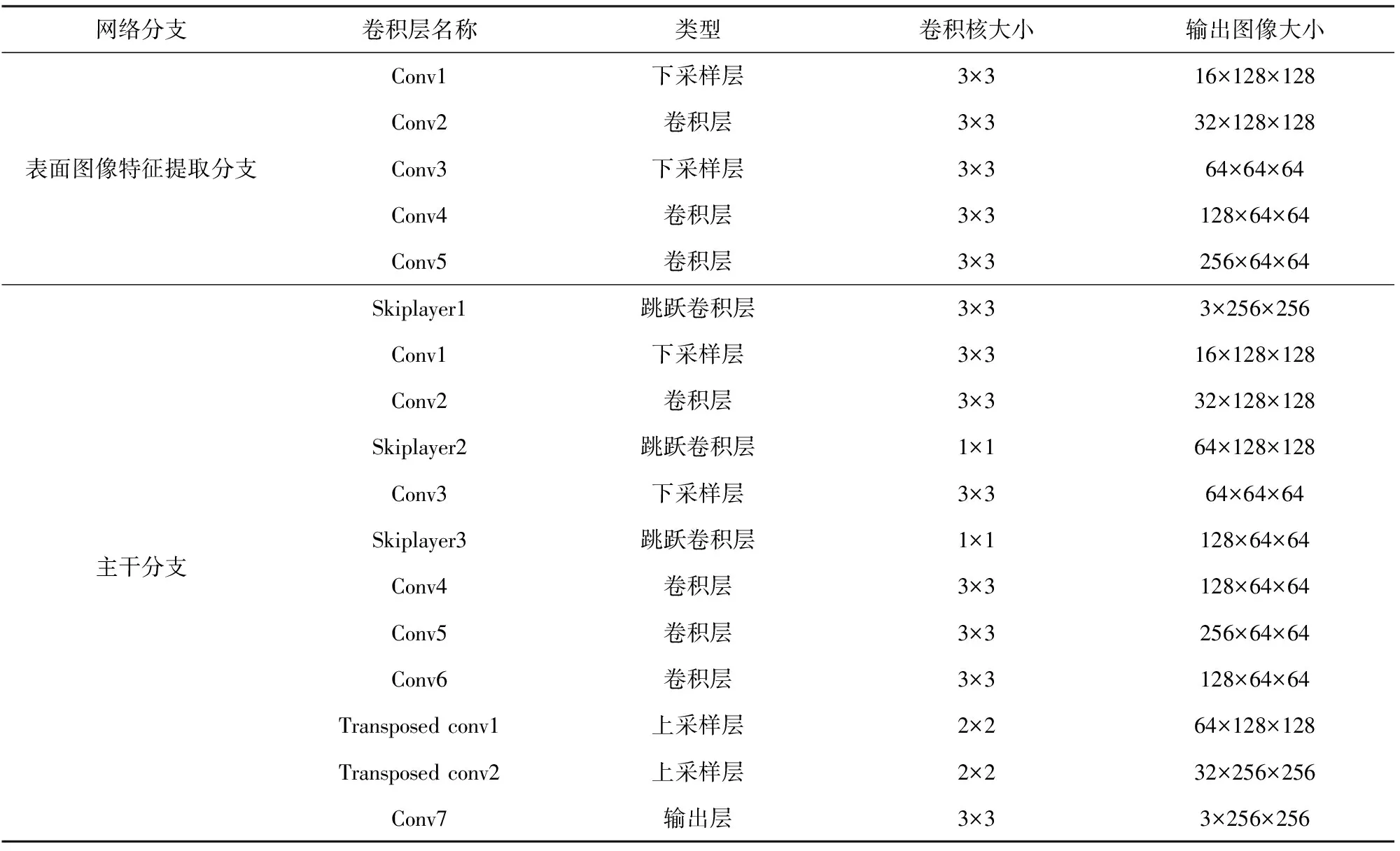
表1 D-CompenNet 内部结构
最后使用改进的SSIM+SmoothL1损失函数计算预测值与真实值之间的差值并不断修正,得到最优参数。
1.3 选取损失函数
损失函数是设计神经网络中很重要的一个关键因素,面对特定的问题,要设计不同的损失函数,损失函数是模型对数据拟合程度的反映,拟合得越差,损失函数的值就应该越大,同时还期望损失函数在比较大时它对应的梯度也要比较大,这样更新变量就可以更新得更快一点。投影仪呈现的图像内容是为了使观察者更好地理解图像的内容,同时观察者也是评价显示效果优劣的决策者,观察者依赖人眼视觉感知机理对获取到的信息进行分析和理解,最终得出相应的评价考核结果。而人眼视觉感知机理是一个复杂的视觉分析系统,需要采用一种符合人眼视觉感知系统特性的图像质量客观评价标准作为损失函数。基于此,本文对文献[13]选取的损失函数SSIM+L1提出改进方法。其中结构相似性度量SSIM是自上而下的一种图片对比方法,即人眼视觉系统非常适合从场景中提取结构信息,文中应用的L1范数损失函数是把目标值与估计值的绝对差值总和最小化。这一损失函数的缺点就是对于数据集的一个小的水平方向波动,回归线也可能存在跳跃很大的情况,在一些数据结构上该方法有许多连续解。基于以上问题,本文分析如下3种损失函数,L1损失函数如(1)式所示,L2损失函数如(2)式所示,SmoothL1损失函数如(3)式所示[14],其中y为预测值与真实值之间的差异。
L1(y)=|y|,
(1)
L2(y)=y2,
(2)

(3)
根据(1)式可知:使用SSIM+L1损失函数在训练后期,当预测值与真实值差异很小时,L1损失函数对预测值的导数绝对值仍然为1;而学习率不变,损失函数将在稳定值附近波动,难以继续收敛以达到更高精度。
根据(2)式可知,当y增大时L2损失函数对y的导数也增大。这就导致训练初期,当预测值与真实值差异过于大时,SSIM+L2损失函数对预测值的梯度十分大,训练不稳定。
根据(3)式可知,SmoothL1结合了L1损失函数和L2损失函数的优点:当y较小时,对y的梯度也会变小;而在y很大时,对y的梯度绝对值达到上限1,也不会太大,以至于破坏网络参数。使用SSIM+SmoothL1损失函数完美地避开了SSIM+L1损失函数和SSIM+L2损失函数的缺陷。因此本文使用了SSIM+SmoothL1作为损失函数计算预测值与真实值之间的差值并不断修正,得到最优参数。实验结果证明了该方法的有效性。
2 实验结果与分析
实验使用开源的机器学习库PyTorch实现D-CompenNet,训练用Adam[15]优化器,设置指数衰减率β=0.9,初始学习率为10-3,800次迭代后将其衰减5倍;初始化模型权重使用Kaiming[16]方法;计算机配置包括两个Nvidia GeForce 1080显卡,22G显存。
本文所提基于D-CompentNet模型的投影图像颜色补偿算法在网络训练过程中选用公开的24个不同环境设置的评估基准数据集,每个数据集500张训练图片、200张测试图片。
同一数据集中对文献[13]方法和本文改进的方法进行定量比较结果如图2所示,从中可以看出在其中一个数据集上进行测试,D-CompentNet模型并使用SSIM+SmoothL1损失函数比CompentNet中使用SSIM+L1损失函数的验证SSIM提高了11.49%、验证均方根误差RMSE仅提高了0.51%,而训练损失降低了10.96%,显示出了改进的明显优势。

图2 同一个数据集中文献[13]方法和本文改进方法的定量比较
实验在不同纹理投影表面背景下进行投影,本文方法与文献[13]方法对比结果如表2所示。从表2中可见,使用本文改进方法进行补偿后,投影显示效果实现了与人眼主观感知更好的一致性。

表2 本文方法与文献[13]方法结果对比
3 结论
本文研究了作战辅助系统中基于深度学习的投影图像颜色补偿方法,提出了CompenNet网络结构改进方法,该方法可以对有色投影背景进行智能投影校正,提高作战辅助系统中投影显示设备的搭建速度和显示效果。所得主要结论如下:
1)D-CompenNet网络模型增加了网络深度,使生成图片能够保留较多的图像细节,提高了图像生成质量。
2)引入新的损失函数项后,使网络训练较快收敛的同时保证了训练结果的稳定性。
3)使用本文改进方法实现了投影图像与原图像更好的客观一致性,同时人眼主观感知效果也有所提高。
参考文献(References)
[1] GRUNDHÖFER A.Practical non-linear photometric projector compensation[C]∥Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops.Portland,OR,US:IEEE,2013:924-929.
[2] HUANG T H,WANG T C,CHEN H H.Radiometric compensation of images projected on non-white surfaces by exploiting chromatic adaptation and perceptual anchoring[J].IEEE Transactions on Image Processing,2016,26(1):147-159.
[3] COSTA P,GALDRAN A,MEYER M I,et al.End-to-end adversarial retinal image synthesis[J].IEEE Transactions on Medical Imaging,2018,37(3):781-791.
[4] TAN J X,GAO Y F,LIANG Z R,et al.3D-GLCM CNN:A 3-dimensional gray-level co-occurrence matrix-based CNN model for polyp classification via CT colonography[J].IEEE Transactions on Medical Imaging,2020,39(6):2013-2024.
[5] LI Y S,ZHANG Y J,HUANG X,et al.Learning source-invariant deep hashing convolutional neural networks for cross-source remote sensing image retrieval[J].IEEE Transactions on Geoscience and Remote Sensing,2018,56(11):6521-6536.
[6] EL MALLAHI M,ZOUHRI A,QJIDAA H.Radial meixner moment invariants for 2D and 3D image recognition[J].Pattern Recognition and Image Analysis,2018,28(2):207-216.
[7] 李响,苏娟,杨龙.基于改进YOLOv3的合成孔径雷达图像中建筑物检测算法[J].兵工学报,2020,41(7):1347-1359.
LI X,SU J,YANG L.A SAR building detection algorithm based on improved YOLOv3[J].Acta Armamentarii,2020,41(7):1347-1359.(in Chinese)
[8] 梁杰,李磊,任君,等.基于深度学习的红外图像遮挡干扰检测方法[J].兵工学报,2019,40(7):1401-1410.
LIANG J,LI L,REN J,et al.Infrared image occlusion interference detection method based on deep learning[J].Acta Armamentarii,2019,40(7):1401-1410.(in Chinese)
[9] 余跃,王宏伦.基于深度学习的高超声速飞行器再入预测校正容错制导[J].兵工学报,2020,41(4):656-669.
YU Y,WANG H L.Deep learning-based reentry predictor-corrector fault-tolerant guidance for hypersonic vehicles[J].Acta Armamentarii,2020,41(4):656-669.(in Chinese)
[10] 温豪,孟召宗,高楠,等.多光通道条纹投影系统误差测量与补偿[J].光子学报,2020,49(7):712004.
WEN H,MENG Z Z,GAO N,et al.Error measurement and compensation of multi-light channel stripe projection system[J].Acta Photonica Sinica,2020,49(7):712004.(in Chinese)
[11] ISOLA P,ZHU J Y,ZHOU T H,et al.Image-to-image translation with conditional adversarial networks[C]∥Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops.Honolulu, HI,US:IEEE Computer Society Press,2017.
[12] 杜振龙,沈海洋,宋国美,等.基于改进CycleGAN的图像风格迁移[J].光学精密工程,2019,27(8):1836-1844.
DU Z L,SHEN H Y,SONG G M,et al.Image style transfer based on improved CycleGAN[J].Optical Precision Engineering,2019,27(8):1836-1844.(in Chinese)
[13] HUANG B Y,LING H B.End-to-end projector photometric compensation[C]∥Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach,CA,US:IEEE,2019.
[14] GIRSHICK R.Fast R-CNN[C]∥Proceedings of 2015 IEEE International Conferenceon Computer Vision.Santiago,Chile:IEEE,2015.
[15] KINGMA D P,BA J L.Adam: amethod for stochastic optimization[C]∥Proceedings of the 3rd International Conference on Learning Representations.San Diego,CA,US:the Computational and Biological Learning Society,2015.
[16] HE K M,ZHANG X Y,REN S Q,et al.Delving deep into rectifiers: surpassing human-level performance on ImageNet classification[C]∥Proceedings of 2015 IEEE International Conference on Computer Vision.Santiago,Chile:IEEE,2015.
