基于人血浆荧光光谱与CARS-PLS-LDA的结直肠癌早期检测
2022-01-09邱智军
陈 煜,邱智军,张 彬
(河南科技大学 食品与生物工程学院,河南 洛阳 471023)
结直肠癌是当今最常见的恶性肿瘤之一,其发病率和死亡率居高不下[1]。结肠癌早期可以没有任何症状,中晚期可表现为腹胀、消化不良,而后出现排便习惯改变,腹痛,黏液便或黏血便,这些症状易被忽视,产生漏诊,也是结直肠癌确诊时期较晚的主要原因之一。目前,肠镜检查是结直肠癌诊断的重要手段,但该方法依据病理学专家的视觉评估,较为主观[2]。而结直肠癌的早期快速准确检出对于结直肠癌患者有重要意义。光谱方法是常用的快速检测方法,其中荧光光谱已经用于癌症样本的识别。利用激光诱发的荧光检测组织内部分子的结构信息,可发现正常组织和结肠癌荧光强度的明显差异[3]。另外,乳腺癌患者血清样本的荧光光谱也被用来区分健康女性与乳腺癌患者[4]。稀释或未稀释的血清或血浆的自体荧光也可用于癌症检测[5-8]。Lawaetz 等[9]应用平行因子分析(PARAFAC)方法对人血浆荧光光谱进行分解,判断最佳组分,并利用PARAFAC 得分矩阵建立了偏最小二乘法判别分析(PLS-LDA)分类模型。结果显示癌症组和各对照组之间分类模型的敏感性、特异性和AUC(Area under curve,ROC 曲线下的面积)值均在0.75左右。随后Bro 等[10]采用同样的样品进一步分析,在荧光光谱检测的基础上,增加了核磁共振光谱、生物标记物检测,结合多种检测信号建立了PLS-LDA 分类模型,AUC值由0.75提升至0.89,同时也增加了较大的检测成本。对于癌症的分类模型,上述研究中模型的分类准确度尚不理想,需要设计开发更好的模型以满足实际诊断的需求。
基于上述研究的人血浆荧光光谱相关数据,本研究采用竞争性自适应加权算法(CARS)进行光谱变量筛选,应用PLS-LDA 建立结直肠癌症患者分类模型,并与全波长模型及上述两项研究[9-10]进行比较,评价其对癌症样本的识别能力;同时通过筛选到的关键变量推断具有鉴别能力的物质结构信息,为后续结直肠癌患者的快速、准确检出研究提供方法和数据参考。
1 实验部分
1.1 样品与光谱采集
选用因有结肠癌相关症状而接受大肠内窥镜检查的308 个患者[11-12]的血浆样品(柠檬酸钠抗凝血剂),设置1 个癌症病例组,3 个对照组:(1)内窥镜检查健康的受试者,(2)具有其他非恶性发现的受试者,(3)患有腺瘤的受试者。每一组(病例组或对照组)均由77个个体组成。
在磷酸盐缓冲液(PBS)(pH 7.4)中测量未稀释和稀释100倍的样品。样品激发波长:250~450 nm,增量:5 nm;发射波长:300~600 nm,增量:1 nm,积分时间为0.05 s。相对于健康人,癌症患者往往具有较高的血卟啉水平[6]。为验证癌症患者体内的卟啉[13]水平,对未稀释的样品进行荧光光谱测定,重点测量卟啉的荧光发射,样品激发波长:385~425 nm,增量:5 nm;发射波长:585~680 nm,增量:1 nm,积分时间为0.2 s。对于所有测量,激发和发射狭缝宽度设定为4 nm。除去部分测量明显错误和采样量不够的样品,共采集到3 种不同的荧光光谱数据集(EEM),分别是低波未稀释组、低波稀释组以及高波未稀释组。
1.2 CARS变量优选
CARS 方法是一种模仿达尔文进化理论“适者生存”原则的变量选择方法[14],通过自适应重加权采样(ARS)技术选择出PLS 模型中回归系数绝对值大的波长点,去除权重小的波长点,并利用交叉验证均方根误差(Root mean square error of cross validation,RMSECV)最低值选出最优变量子集,有效寻出最优变量组合。本研究采用CARS方法进行变量优选,设置最大因子数为10,采样次数为100,预处理方法为自标准化(Autoscaling),比较循环后100个变量子集的RMSECV,以其最小值对应的变量子集作为最优变量子集。
1.3 PLS-LDA模型的建立与评价
经CARS变量优选后,基于优选的波长变量,应用PLS-LDA进行交叉验证建立分类模型。以荧光光谱矩阵作为独立X变量,样本分类属性向量Y作为因变量,其中1表示属于该类的样本,-1表示不属于该类的样本。共建立7 组CARS-PLS-LDA 模型,包括结肠癌病例组与3 个对照组的合集(crcvsall)、结肠癌病例组与健康受试者组(crcvsno)、结肠癌病例组与非恶性发现的受试者组(crcvsonf)、结肠癌病例组与腺瘤受试者组(crcvsade)、健康受试者组与非恶性发现的受试者组(novsonf)、健康受试者组与腺瘤受试者组(novsade)、非恶性发现的受试者组与腺瘤受试者组(onfvsade)。通过正向选择法,将矩阵X和矩阵Y分别进行主成分分解,得到X矩阵主成分(即影响分类的因素)的贡献率。按照影响分类结果的大小依次排序,得到对分类影响较大的荧光光谱的特征波段。在PLS-LDA 分析中,采用K 折交叉验证,通过将数据集分成K份,对每个模型,将除去第n(n属于[1,K])份的所有数据用于训练,得到训练集,然后将训练参数在第n份数据上进行测试,最后将得到的K个模型结果平均,本文设置K=10。所建的分类模型由错误率(Error rate)、敏感性(Sensitivity)、特异性(Specificity)以及AUC进行评价。其定义公式如(1)~(4)所示:
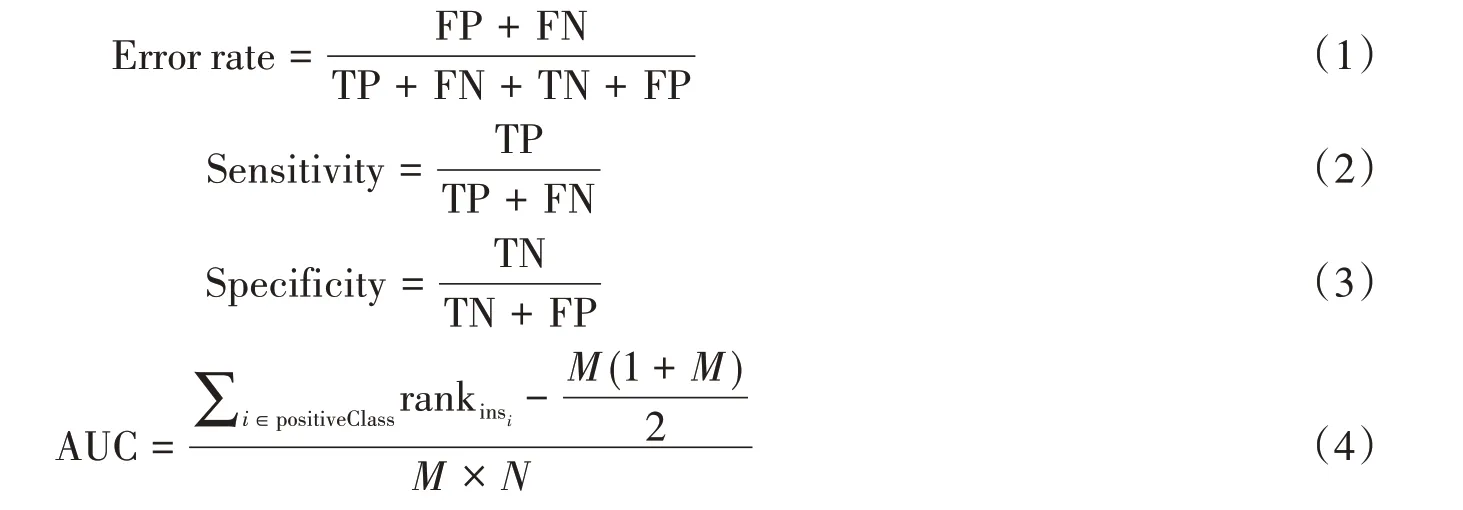
公式中,TP、TN、FP、FN分别表示真阳性、真阴性、假阳性、假阴性,M为阳性样本数,N为阴性样本数,i代表第i条样本序号。实验规定癌症患者代表阳性,对照组为阴性。在分类模型中,特异性和敏感性均为分类结果判断的重要标准。敏感性表示所有阳性样本被分对的概率,衡量了分类模型对阳性样本的识别能力;特异性则表示阴性样本被分对的概率,衡量了分类模型对阴性样本的识别能力。而AUC值则是分类模型的评价指标,AUC值越大,表示分类识别准确性越高。
2 结果与讨论
2.1 最优主成分数的确定
CARS 变量优选后,采用交叉验证进行建模,根据交叉验证错误率最小原则确定最优的建模主成分数。由图1 所示,对于高波未稀释组,各对照组模型的最优主成分不尽相同,但随着主成分数的增加,交叉验证错误率均逐渐降低。最终确定crcvsno组的最优主成分数为6,crcvsonf和onfvsade组的最优主成分数为7,crcvsade 组和novsonf 组的最优主成分数为8,novsade 的最优主成分数为3。而crcvsall的交叉验证错误率随着主成分数的增加保持不变,因此,确定最优建模主成分数为1。低波未稀释组与低波稀释组也采用同样的方法,过程结果不一一展示。
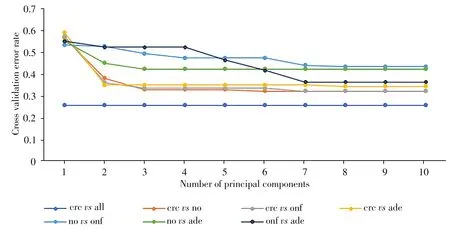
图1 高波未稀释组各对照组的PLS-LDA交叉验证结果Fig.1 PLS-LDA cross validation results of control groups in high wave undiluted group
2.2 CARS变量优选
高波未稀释组结直肠癌患者与健康人分类的CARS 变量筛选过程如图2 所示。图2A 显示,随着蒙特卡洛(MC)采样次数的增加,所选变量的数量不断减少,且减少的速度由快变慢,体现了筛选的粗选和细选两个部分。图2B 为CARS 变量筛选过程交叉验证错误率的变化趋势,可以看出,交叉验证错误率曲线先下降,在MC 采样次数为33、36、39 时,错误率达到最小值,随后随着采样次数的增加,错误率逐渐上升至平稳状态。变量筛选过程的变量回归系数曲线图见图2C。“*”星形垂直线表示RMSECV最低,即采样数为39时达到最佳模型。最终,原有864个变量经CARS变量优选为84个。
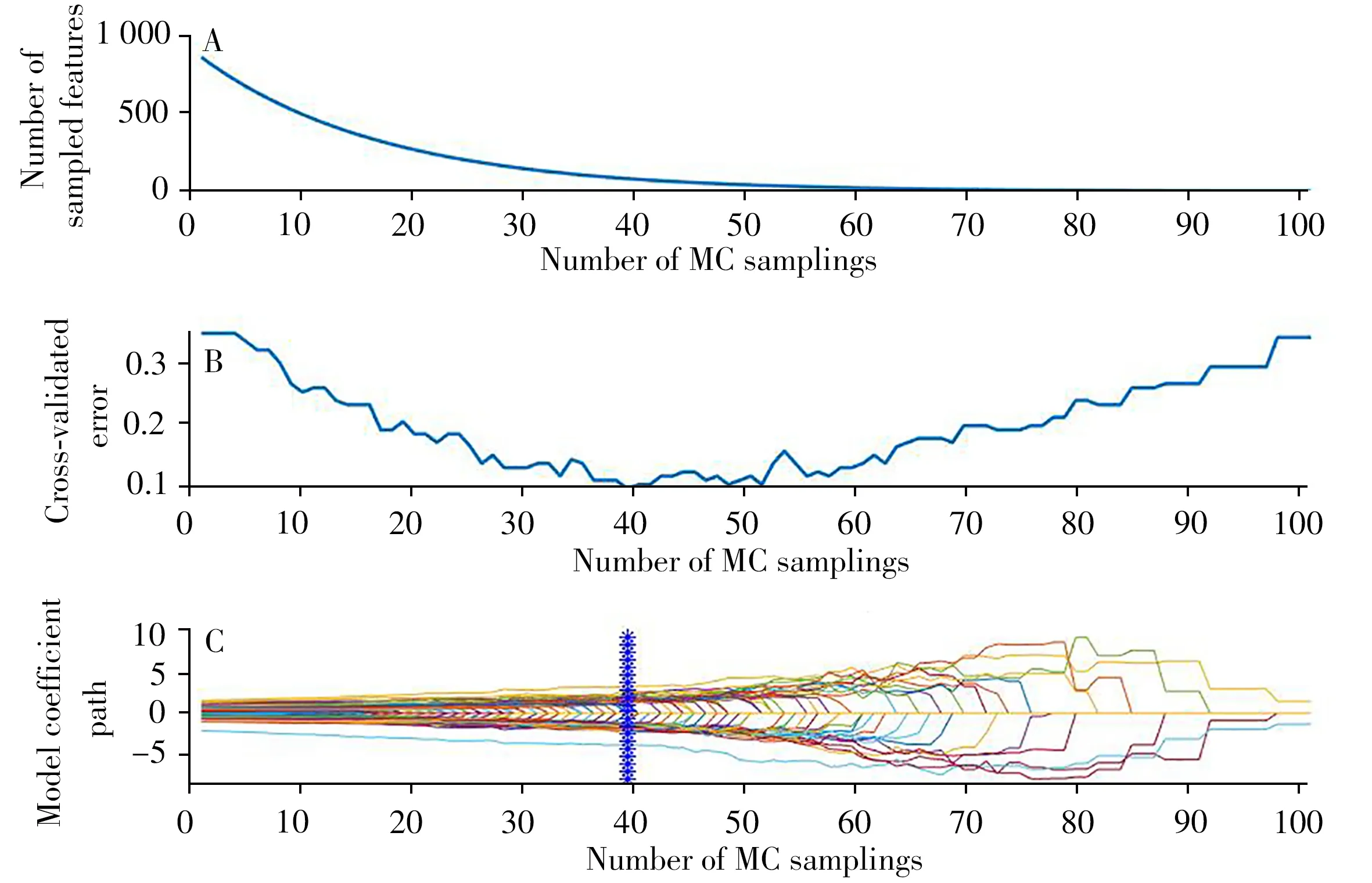
图2 癌症与健康人对照组模型的高波未稀释组CARS变量筛选过程Fig.2 The screening process of CARS variables in high wave undiluted group of cancer and healthy control group model
2.3 PLS-LDA模型的建立与比较
以Lawaetz 等[9]的研究为参照(所用数据和评价方法与本研究完全相同),Lawaetz 等利用3组荧光光谱数据分别拟合PARAFAC 模型,通过化学组分排序,共筛选出19 个变量的矩阵,并以此建立PLSLDA分类模型,通过模型的分类效果对主成分进行分析解释,反映与鉴别癌症与非癌症的相关变量。
利用CARS优选后的变量构建PLS-LDA分类模型,建立了癌症组与对照组以及不同对照组之间共7 种分类模型(与参照研究相一致),模型均进行十折交叉验证。结果发现,采用不同波段及对血浆样品100 倍稀释处理的方法,对癌症与非癌症的3 个对照组均有着较好的分类效果。通过图3 可以发现,高波未稀释组经CARS 变量优选后,其敏感性、特异性以及AUC 值均得到显著提升。其中高波未稀释组的癌症与腺瘤患者经过CARS 变量优选后建立的模型分类效果最佳,敏感性、特异性及AUC 值均达到1。
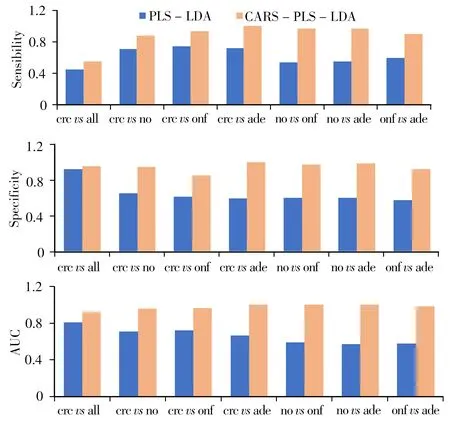
图3 高波未稀释组荧光光谱不同建模方法对各模型的分类结果Fig.3 Classification results of different modeling methods for high wave undiluted group fluorescence spectra crc,no,onf,ade,all were the same as those in Fig.1
其他组之间分类的AUC 也均高于0.9。其中,crcvsall模型的AUC值为0.917 2,特异性为0.955 2,敏感性为0.552 6。而未使用CARS 筛选的PLSLDA 模型的分类效果整体较差,其中癌症组与3 个对照组合集的AUC值和特异性最高,分别为0.806 3和0.916 9,敏感性只有0.447 4;癌症组与3 个对照组分类的AUC 值均处于0.7左右;对照组与对照组之间模型分类的敏感性、特异性以及AUC 值也较低(0.5~0.6)。
同样,经CARS 变量优选后,低波稀释组各对照组模型的分类效果均显著增强,AUC 值均在0.9以上,与高波未稀释组经CARS 变量优选后的分类效果相似。且crcvsall 模型在变量筛选前后有相似的高特异性和低敏感性,与高波未稀释组相同。
对于低波未稀释组,经CARS 变量筛选后,各模型的分类效果有所增强,其敏感性、特异性以及AUC 值均在0.7~0.8,但低于高波未稀释组与低波稀释组。其未经CARS 筛选的分类模型结果与低波稀释组相同,敏感性、特异性及AUC 均为0.5~0.6,模型分类效果相差不大,除crcvsall 外,其他组模型具有高特异性和低敏感性,与高波未稀释组、低波稀释组相似。
综上,未进行CARS 变量优选建立的PLS-LDA 的各种分类模型,其敏感性、特异性及AUC 值均在0.5~0.6,与Lawaetz 等应用PARAFAC 建立的分类模型结果水平相当;经CARS 变量筛选后,高波未稀释组和低波稀释组各模型的分类效果获得大幅提升,其敏感性、特异性和AUC值均达到0.9左右;基于低波未稀释组光谱数据的分类效果也有所提升,但提升幅度不明显。Lawaetz等的研究结果中,低波未稀释组的分类效果优于低波稀释组,并推测稀释会导致光谱产生蓝移,从而降低分类效果,这与本文的计算结果相反。这个差异产生的原因可以用方法的原理来解释,Lawaetz等利用得分矩阵建立分类模型,所筛选的变量并非是真正对癌症患者分类有较大影响的化合物信号,可能只是其本身自体荧光较高,故建立的分类模型的效果较弱;其次,在人血浆测量区域拟合得到的PARAFAC 模型的误差未能真正去除。这些都可能是造成模型分类效果较差的原因。另外,人血浆中含有丰富的化学物质,其真实发生的化学、物理变化无法确定,故推测血浆中可能含有某种物质,其浓度较高导致荧光猝灭;稀释后,该物质浓度降低,血浆中的自体荧光物质发射出较强的荧光信号[15],增强了分类所需的信息,从而有助于模型分类。
表1 给出了不同分类组的CARS 优化模型与基于PARAFAC 分数分类模型[9]的敏感性、特异性以及AUC值。PARAFAC 分数是从3组荧光光谱数据集分别提取特征变量后,建立的最优分类模型;本研究是分别将3组荧光光谱进行变量优选后建立分类模型。从表1可见,对于PARAFAC-PLS-LDA 模型,癌症组与各对照组的模型分类效果明显优于对照组之间的模型,而CARS-PLS-LDA 模型各对照组的分类效果相差不大,且AUC 值均达到0.9 以上。两种模型的相似之处在于,crcvsade 模型均为7 种分类模型中最优。由此可见癌症与腺瘤患者有着较为明显的区分,对后续病人肿瘤的区分有重要意义。Bro等[10]基于同性质样本的数据融合研究,对癌症与腺瘤患者的样品进一步分析,采用荧光光谱结合核磁共振、生物标志物等进行分析,得到AUC 值为0.890 0,相对于Lawaetz 等的研究结果有所提升,但仍低于本文的AUC 值(1.000 0)。对于crcvsall而言,PARAFAC-PLS-LDA 模型的敏感性和特异性均为0.700 0,本文CARS-PLS-LDA 模型的敏感性为0.552 6,特异性为0.955 2,具有低敏感性和高特异性的特点。而癌症组与各对照组分类模型的敏感性和特异性均在0.8 以上,对照组与对照组分类模型的特异性和敏感性同样在0.9以上。分析认为,造成crcvsall模型中出现高特异性和低敏感性结果的原因在于数据的非平衡性特点,即3 个对照组构成的合集是癌症组样品容量的3 倍,即样品中3/4 的人没有癌症,造成了样本的不平衡,从而导致模型结果的敏感性较低。Flamini等[16]的研究表明,大肠癌唯一可接受的血清标志物是癌胚抗原(CEA),其特异性为0.930 0,敏感性为0.340 0。而本文CARSPLS-LDA 的分类模型结果显示,低波未稀释组的特异性为0.937 8,敏感性为0.297 3;低波稀释组的特异性为0.967 9,敏感性为0.329 4,分类效果相当;但高波未稀释组的特异性为0.955 2,敏感性为0.552 6,明显优于上述各项参照研究的结果。
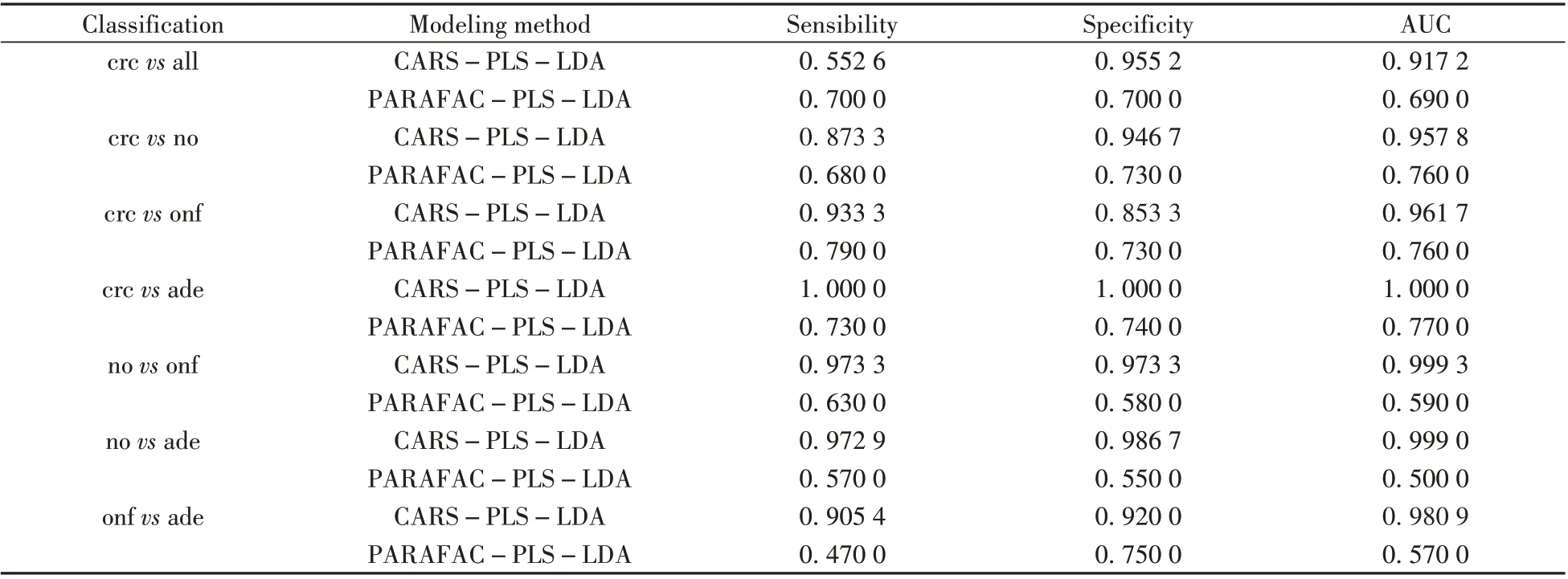
表1 CARS优选和PARAFAC分数的PLS-LDA分类模型比较Table 1 PLS-LDA classification model comparison between CARS optimization and PARAFAC score
综合来看,CARS-PLS-LDA 的分类效果整体优于全波长PLS-LDA 和PARAFAC-PLS-LDA。相较于全波长模型,CARS 波长变量筛选方法表现出的优势可以理解为:变量筛选过程去除了与模型指标关系不大的变量,有效保留了关系密切的变量,从而提高了模型性能。有研究针对相同的数据和评价指标,对同样作为变量筛选方法的CARS 法、移动窗口偏最小二乘法(Moving window partial least square,MWPLS)和蒙特卡洛无信息变量消除法(Monte Carlo variable elimination,MC-UVE)进行了比较。发现三者均能找到相同的谱带,但CARS 所选的波长变量最少,构建的模型性能也最好[14]。
PARAFAC 和CARS 均通过降维来优化模型,但其控制降维实施过程的参数指标却有着本质的不同,前者的控制指标是残差平方和,后者是模型性能指标,即预测误差。CARS 依据模型性能指标(预测误差)来挑选波长变量,这些筛选到的波长变量具有与模型性能更直接的关联。故CARS变量筛选方法比PARAFAC数据降维优化模型的分类效果好。
2.4 分类模型主要影响因子的确定
通过CARS 变量优选建立PLS-LDA 分类模型,对比3组数据的分类效果发现,高波未稀释组和低波稀释组各对照组的分类效果均较好,AUC 值达0.9 以上。将高波稀释组与低波未稀释组的癌症组与全体对照组模型的影响因子按得分进行排序,得到排名前5的变量,将这些变量回溯到原始荧光数据,确定其激发/发射波长信息。由于人血浆环境过于复杂,不同的pH 值、温度以及处理方法、稀释倍数均会对物质产生不同程度的影响,故仅能大致推测出主要影响变量的对应物质基础。
图4 为高波未稀释组和低波稀释组分类模型在荧光光谱中的定位情况。可以发现高波未稀释组(图4A)的癌症组与各对照组的影响变量主要集中在激发波长400~420 nm,发射波长610~625 nm,符合卟啉荧光的波长范围,与王金杰等[17]的研究结果相符,即癌症患者血液中的原卟啉含量高于正常人。而Lawaetz 等的研究结果却显示卟啉与癌症无关。图4B 结果显示,低波稀释组的癌症组与各对照组的影响变量主要集中在激发波长250~260 nm,发射波长310~360 nm,其所对应的是血液中的游离色氨酸、结合色氨酸以及酪氨酸[18]。同时还有激发波长260~272 nm,发射波长450~500 nm,符合还原型烟酰胺腺嘌呤二核苷酸(Nicotinamide adenine dinucleotide,NADH)的荧光特征[19]。由此可见,癌症样本在卟啉、色氨酸、酪氨酸以及NADH 等物质维度上可与其他对照样本有效区分,为后续癌症临床诊断研究提供了物质基础信息参考。
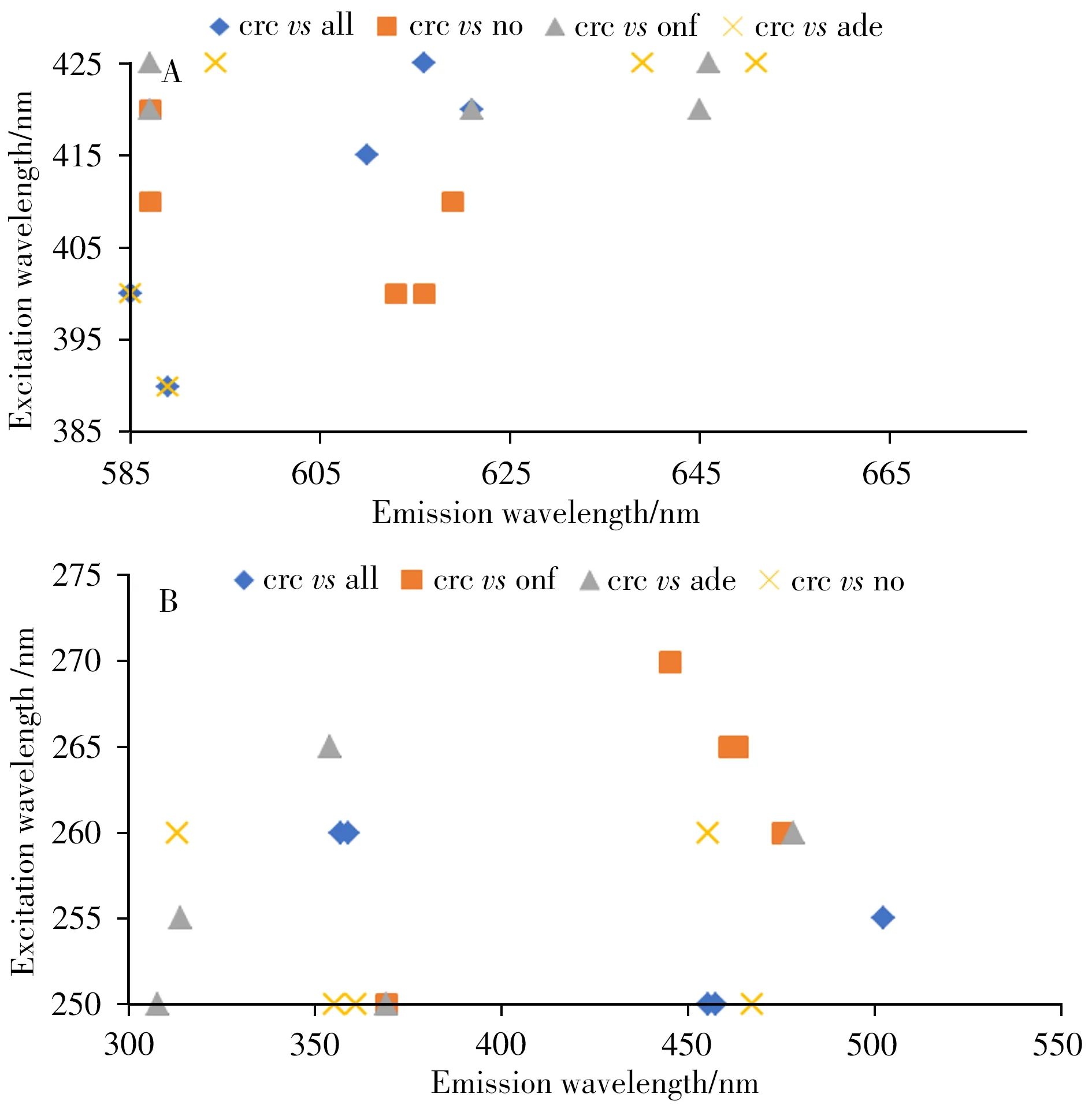
图4 高波未稀释组(A)和低波稀释组(B)分类模型的主要影响因子在荧光光谱的定位Fig.4 The location of the main influence factors of each classification model in the high wave undiluted group(A)and the low wave diluted group(B)in the fluorescence spectrum
3 结 论
荧光光谱结合CARS-PLS-LDA 的分类模型中,高波未稀释组和低波稀释组的分类效果较好。其中最优模型为高波未稀释组癌症组与腺瘤患者对照组,其敏感性、特异性及AUC 值均为1.000 0。与Lawaetz 等的研究比较,本研究除了在人血浆中发现相同的物质(色氨酸、酪氨酸和NADH)外,还发现一种重要的物质—卟啉,其在癌症样本与其他对照样本的区分中有显著作用,且与已有实验研究结论一致。相对于参照研究的PARAFACPLS-LDA 分类模型,CARS-PLS-LDA 大大提高了模型的分类效果,有望为癌症诊断模型提供一种新的方法。
