基于花粉算法的广域无线传感器网络最优数据聚合设计
2022-01-07兰婷婷秦丹阳孙冠宇
兰婷婷, 秦丹阳, 孙冠宇
(黑龙江大学 电子工程学院, 哈尔滨 150080)
0 引 言
无线传感器的广泛使用以及将其组织到网络中时会存在许多部署问题,能量的高效利用是最主要问题之一。因此,需要有效地使用传感器中有限的能量来维持网络性能,使服务质量(Qualit of seyrvice, QoS)不会受到影响[1]。为此,研究者开发了许多节能技术,如媒体接入控制(Media access control, MAC)协议、路由协议和数据聚合技术等,其中数据聚合是最常用的技术,能够有效降低网络能耗,减少网络拥塞[2]。除了提高系统效率之外,数据聚合还有助于培养可扩展的网络[3],能够轻松扩展到大型系统。
目前,无线传感器网络(Wireless sensor network,WSN)中的聚类协议已被广泛研究,典型的聚类协议LEACH是一种基于数据聚合的层次型路由协议,通过随机方式进行簇头(Cluster head, CH)的选择,来避免簇首能量消耗过度,同时将数据进行聚合处理能够有效地减少网络中的通信量[4],但是LEACH不能使用任何目标函数提供CH的最佳选择,且仅在小覆盖区域上进行有效工作,所以不能用于大规模的WSN中。HEED是一种分簇聚类协议[5],其分簇速度更快,能产生分布更加均匀的簇头、更合理的网络拓扑[6]。HEED算法中簇头会直接和基站进行通信,由于没有考虑它们之间的距离,会造成节点能量快速消耗[7]。在解决广域的无线传感器网络聚类问题时,采用扇形聚类协议(Fan-shaped clustering, FSC)进行簇头的选择既简单又很有效,有利于降低网络中通信成本,但是FSC算法在执行的时候不强调所需的QoS[8]。也可以在网络中使用其他聚类方法,包括K均值和模糊C均值[9],这两种方法都是采用随机选择k个中心点,剩余节点与最近的中心点分组,但是如果没有谨慎地选择起始点,则这两种聚类方法都可能产生较大的分歧或收敛到局部最优。文献[10]提出了一种适用于大规模传感器网络的聚类算法,该算法在实现过程中考虑了聚合网络规模,信息表达能力和能量消耗情况,能够提供更好的网络性能。在广域的无线传感器网络中研究聚类算法和路由协议时,由于接收器附近的节点经历更多的数据量,会出现能耗不平衡问题[11-12]。因此,文献[13]提出了一种基于能量感知的聚类路由协议,该协议能够对网络进行聚类并选择最优的簇头,并通过改进的布谷鸟搜索算法进行了优化。
本文基于WSN数据聚合技术,设计一种最优广域无线传感器网络数据聚合模型(Optimal data aggregation model, ODAM)。研究和分析了标准花粉算法的搜索性能,利用花粉算法在基站(Base station, BS)进行集中式聚类,通过目标函数能够获得性能最佳的聚合簇。利用相关数据进行仿真实验,验证算法的有效性及可行性。
1 模型的设计与描述
1.1 花粉算法
自然界中植物的授粉过程包括自花授粉和异花授粉两种方式,花粉算法是根据植物花朵授粉行为机理进行模拟而设计的一种新型启发式优化算法,算法的局部搜索和全局搜索过程分别模拟自花授粉和异花授粉行为[14]。将花粉算法建立以下规则:
规则 1:植物的异花授粉过程被模拟为全局搜索过程,其中花粉个体服从Levy飞行机制;
规则 2:植物的自花授粉被模拟为局部搜索过程;
规则 3:花的恒常性与授粉过程中两朵花的繁殖概率或相似度成比例。
规则 4:局部搜索和全局搜索由转换概率p∈[0,1]控制,当Rand>p时,进行全局搜索,反之进行局部搜索。
对于全局搜索过程,花粉粒子由昆虫和鸟类等传粉者携带,能够传播较远距离,因为昆虫,鸟类等生物媒介可以飞行或移动较长距离。将上述规则用数学表达式进行表示,规则(R1)和(R4)表示为:
(1)

(2)
而对于局部搜索,可以把上述规则(R2)和(R3)定义为:
(3)

1.2 最优数据聚合模型
假设给定的网络区域中存在N个节点或网络设备,将传感器网络区域划分为N个同心圆,也可以称为层,基站位于圆心处,如图1所示。在聚合网络中,簇节点间的通信开销比较大,会减少网络的生命周期。在最优数据聚合模型(ODAM)中,通过在基站中使用花粉算法可以对网络区域中每一层的节点进行聚类,能够使得节点和BS之间进行有效的通信。对于每一层中的聚合簇,簇节点将收集到的数据信息发送给簇头节点,簇头将对收到数据信息进行聚合,并且还可以作为中继节点将聚合后的数据包中继给下一层的簇头节点,最终会形成簇头覆盖的网络。

图1 最优广域传感器网络数据聚合模型Fig.1 Aggregation model of optimal wide-area sensor network data
与其他类似网络不同的是,ODAM将聚类、簇头选择、簇头重选、信令以及重新聚类[15-16]等过程限制在基站中进行,目的是为了减少节点间的计算开销,有助于延长传感器节点的寿命。具体实现过程如下:
Step 1 簇的形成BS根据收到的节点位置和节点剩余能量等信息,执行聚类过程并把给定簇中的簇头ID发送给节点,节点在此基础上形成簇。节点和BS之间的所有通信都通过簇头进行,由于每个节点的ID、位置信息和剩余能量都会保存在BS中,因此可以根据节点的状态进行实时的更新,如图2所示。当现有簇中没有节点能满足设定的阈值时,则触发重新聚类,在此期间,新的阈值会重新被设定。在BS中进行簇节点间距离和能量的计算,能够降低节点间的能量消耗。
Step 2 数据聚合在成簇阶段完成后,第N层的节点将数据发送给簇头,簇头将收集到的数据进行聚合并将聚合后的数据发送给邻近的簇头,作为来自第(N-1)个环的中继节点,直到数据被中继到BS为止。数据聚合的模型如图3所示。

图3 数据聚合Fig.3 Data aggregation
Step 3 簇头重选随着节点工作时间的增加,节点自身的能量不断减少,当CH的能量逐渐接近所设定阈值时,将通过广播的方式来提示所有节点启动簇头重选过程。此时节点将自身剩余能量的信息发送给CH,CH将其和这一轮的相关数据一起中继到BS。当基站接收到数据后,则更新传感器节点的相关信息,并利用FPA对簇头进行重选。簇头重选如图4所示。
Step 4 逐层重新聚类在传感器网络中,如果给定簇中没有节点具有足够的能量来充当簇头,则节点与网络中的其他簇进行重新分组。当网络中每一层的聚合簇接近饱和时,BS通过设置簇头满足的阈值,对整个层执行重新聚类。
1.3 最优聚合目标函数
假设在不影响数据包传输的情况下,成员节点可以直接向簇头传递数据。在广域的无线传感器网络中,为了形成具有高能效的簇,把在单位时间内消耗单位能量所传输的总比特数,即效率E设定为ODAM模型所需的目标函数为:
(4)
式中:P为网络中消耗的总功率;DR1和DR2分别代表簇头和节点的数据传输速率。
式(4)中的簇头和簇节点的数据传输速率满足:
(5)
(6)
式中:N和Nc分别为传感器节点和聚合簇的数量;Ze和Za分别代表簇头和节点上的阴影;β1为簇头发送包的数量;PTx为簇头的传输功率;D1和D2分别为节点与基站和簇头之间的距离;w1为簇头的带宽;w2为簇中每个节点的带宽;Pla为簇头经历的路径损耗,Ple为节点经历的路径损耗,如式(7)和式(8)所示。
Ple=128.1+37.6·log2(D1/1 000)
(7)
Pla=38.5+20·log2D2
(8)
簇通过最小化节点、簇头和基站之间的阴影效应被更换,因此,形成的簇具有较高的能效,且在不影响QoS的情况下有助于延长网络生命周期。立足于所构建的ODAM模型,结合花粉算法设计的最优聚合算法,如算法1所示。

算法1 最优聚合算法Algorithm 1 Optimal aggregation algorithm
2 仿真结果与性能分析
在仿真实验中,无线传感器节点被均匀地分布在100 m×100 m的区域上,其中BS位于网络区域中心,仿真参数如表1所示。本文在评估ODAM性能时考虑了以下指标:
(1) 数据包收集率: 在基站处每轮传输后所收集的数据包数量与所传输总的数据包数量的比值,在无线传感器网络中常采用轮数表示网络工作时长;
(2) 网络节点平均剩余能量: 每轮传输结束后网络中所有节点的剩余能量与节点数量的比值;
(3) 生存节点数量: 在每轮传输后网络中运行的节点总数。
2.1 数据包收集率
数据包收集率与轮数之间的关系如图5所示。可以看出,ODAM在接收器处可以提供更稳定且连续的数据包收集率。当数据包收集率降至0.9时,HEED和FSC分别出现在网络生命周期的35%和75%左右,而在网络生命周期的86%之后,ODAM中数据包收集率才降至0.9,可以看出ODAM的网络寿命明显优于HEED和FSC。虽然曲线适用于较短的网络工作时间,但在数据包收集率方面可以看出所提出的ODAM模型要比其他两种算法更加稳定。
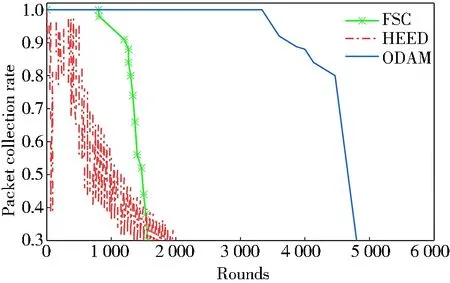
图5 数据包收集率的比较
2.2 网络节点平均剩余能量
节点平均剩余能量(Residual energy of nodes, REN)随着轮数的变化情况如图6所示。对比三条曲线,在节点经历3 000轮左右传输时,HEED和FSC的节点的平均剩余能量值均降为0,网络开始失效,而ODAM系统中的平均剩余能量还有900 mJ左右,因此,网络工作时间要比其他两种聚合算法更长。在初始阶段,FSC中节点的平均剩余能量下降的较为缓慢,但在1 400轮后开始迅速下降,而ODAM中节点的能量减少速度要相比于HEED和FSC要更加地稳定。在ODAM模型中,网络区域采用分层结构的设计,使得簇头传输数据时所跨越的距离进一步减少,节省了传感器节点的能量。

图6 节点平均剩余能量的比较Fig.6 Comparison of average REN
2.3 网络生存节点数量
三种算法随着轮数的增加,网络中运行节点数量的比较图如7所示。可以看出,相比于HEED和FSC来说,ODAM在初始阶段节点数量的减少更为缓慢。由于ODAM试图将聚合簇中大多数计算限制在基站中进行,因此,可以减少节点间因计算产生的能量消耗,有助于增加节点的寿命。图中当FSC和HEED进行4 000轮时,几乎已无节点存活,此时,ODAM依然有将近2 000个节点存活,说明ODAM的网络生命周期要远优于HEED和FSC。
3 花粉算法的特征分析
为了验证采用花粉算法是否为聚类网络中节点的最佳选择,本节将通过研究不同簇数的能效和节点数量的关系来证明FPA的选择。其中聚合簇Cluster的簇数n分别取值2、4和6,如图8所示。可以看出,聚合簇Cluster中节点数较少时,n=4时具有能效最高,如当聚合簇Cluster中有20个节点时,三种簇数(n=6、4、2)的能效分别近似为12.5、13.5和12.2Mbits·J-1。但是随着聚合簇Cluster中的节点数量不断增加,这种变化趋势将发生改变。比如当节点增加到200个时,三种簇数(n=6、4、2)的能效分别近似1.55、1.5和1.45Mbits·J-1。三种簇数的能效值随着节点的增加会大大收敛,在聚类网络中,应用FPA算法能够获得更高的能效,而且不受聚合簇数量的影响。因此,网络可以根据其他特征需求选择簇的数量,同时不会影响聚类网络中的能效。

图8 花粉算法的特征分析Fig.8 Characteristic analysis of flower pollination algorithm
4 聚合簇数量的分析
在ODAM中,聚合簇的数量对无线传感器网络的性能也产生一定的影响。为了获得最佳数量的聚合簇,通过对不同数量的簇在平均数传输速率和计算时间上进行比较能够有效地进行聚合簇的选择。
三种不同簇数的平均数据传输速率的比较如图9所示,可以看出,三种簇数的平均数据传输速率随着节点数量的增加均呈逐渐递减的趋势,而且簇数越大,平均数据传输速率越大,即6个簇中的的平均数据传输速率最高,当聚合簇中有50个节点时,三种簇数(n=6、4、2)的平均数据传输速率分别为125、75和25 kbps。虽然这种趋势随着节点数量的增加而继续保持着,但是速率值变化的差异却减小了。
三种簇数随着节点数量的增加,形成聚合簇所需计算时间的比较情况如图10所示。三种簇数的计算时间均随着节点数量的增加而增加,同时,聚合簇的簇数越大所需的计算时间也越多,即聚合簇数量为6时,发现所计算时间最多。当聚合簇中有200个节点时,三种簇数(n=6、4、2)所需的计算时间分别为0.9、0.75和0.6 s。

图10 计算时间的比较Fig.10 Comparison of computational time
为了达到这个平衡的要求,需要去平衡网络支持的平均数据传输速率与其运行过程中所涉及的计算时间,在分析聚合模型时选择簇数为4的聚合簇。所提出的ODAM模型使用有效的FPA算法进行聚类,使得单位能耗下能够获得最大的数据速率,实现在不影响QoS的情况下获得较高的能效。
5 结 论
设计了一种最优广域无线传感器网络数据聚合模型,该模型通过采用FPA算法与目标函数结合进行簇头的最佳选择,从而获得最优的簇集合,并能够在簇间和簇内的通信成本上取得平衡。进一步将聚类和簇头重选等类似活动限制在BS,使得节点不受开销的影响,同时,将数据进行分层传输,有助于提高数据传输的准确性和节省网络中的能量。在考虑节点的传输功率和带宽的情况下,实验结果表明,ODAM较其他聚类算法能够有效地延长网络寿命,由于使用了优化功能,在接收端能够接收到连续的数据包,在不影响QoS的情况下,使得传感器网络中能量能够被高效地利用。但是由于对花粉算法的提出时间较短,花粉算法的理论还需进一步的完善,在后续的研究中,可以考虑借鉴智能优化算法的改进来提高花粉算法的性能。
