MFANet: 一种用于雾天图像语义分割的多任务融合注意力网络
2022-01-07任东东李金宝赵俊一
任东东 , 李金宝 , 赵俊一
(1.黑龙江大学 计算机科学技术学院, 哈尔滨 150080; 2.齐鲁工业大学(山东省科学院) 山东省人工智能研究院,济南 250014; 3.黑龙江大学 电子工程学院, 哈尔滨 150080)
0 引 言
图像语义分割是图像处理和计算机视觉领域一项重要且富有挑战性的任务,其目的是为输入图像预测一个密集的标签映射,从而为每个像素生成一个唯一的类别标签。近年来,基于卷积神经网络的方法在语义分割方面取得了显著成果[1-3],并在自动驾驶和视频监控等领域显示出巨大的应用潜力。 然而,这些应用系统在面临恶劣的天气环境时,由于采集到的图像质量较差,其分割准确率会受到较大影响[4]。
在各种恶劣的天气环境中,雾是一种较为常见的大气现象,它是由空气中的水汽凝结物、灰尘、烟雾等微小的悬浮颗粒产生的。由于光线在传播过程中与大量悬浮颗粒发生交互作用,光能被重新分布,使得雾天图像通常呈现模糊泛白、色彩饱和度下降、观测目标严重退化的现象,这将导致基于逐像素分类的语义分割任务性能急剧下降。因此,在雾天,尤其是大雾的天气条件下,如何准确、快速地分割图像对于室外应用系统来说十分关键[5-7]。
预处理法对有雾图像提前进行去雾处理,使图像恢复到无雾状态,不改变原始的语义分割模型。然而,这种方法主要存在以下两方面问题:(1) 通常是最小化有雾图像与无雾图像之间的均方误差,容易丢失高频的图像细节信息,在大雾情况下,该方法可能会对于一些纹理边界丰富的区域造成过渡平滑并产生伪影,严重影响边界处的语义分割精度; (2) 预处理方法需要对有雾图像进行端到端的目标映射,给语义分割任务增加了额外的成本和计算量,限制了在低功耗、高实时性系统上的部署和应用[8]。
特定训练法通过在大规模分割数据集上添加一定程度的噪声和合成雾来提高分割模型的鲁棒性。 然而,雾噪声会降低分割模型的特征提取能力,尤其在重雾情况下,图像整体泛白且边界模糊。这种方法不但限制了网络的特征提取能力,并且容易使分割模型在训练过程中发生梯度消散。
针对上述问题,本文提出了一种多任务融合注意力网络(MFANet: Multi-task fusion attention network)。如图1所示,MFANet将图像去雾与语义分割任务融合到一个网络框架中,提高了模型分割鲁棒性,避免了任务级联处理的复杂性,降低了模型的存储和计算成本。
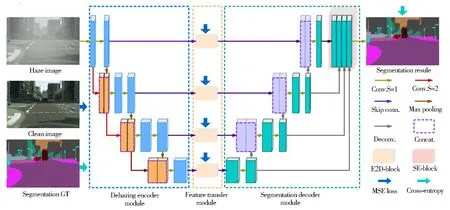
图1 MFANet整体框架结构Fig.1 Integral frame construction of MFANet
MFANet以编码解码器网络为基础,包含去雾编码模块,分割解码模块和特征转移模块三部分,具体贡献: 1) 为避免深层网络中高频细节信息的丢失,去雾编码模块采用跨尺度残差连接来增强特征信息的流动,并使用卷积下采样来弥补由于池化下采样造成的信息损失,使网络在有效去雾的同时避免了细节特征的丢失; 2) 分割解码模块通过连续上采样恢复图像的特征分辨率,通过多尺度特征融合增强不同分辨率的特征利用率,并使用注意力机制进一步突出目标特征,增强了分割结果的准确性; 3) 特征转移模块以跳跃连接的形式连接去雾编码模块和分割解码模块,既保证了两个不同任务模块间的特征过渡,又使去雾结果更加适用于图像语义分割。
1 相关工作
1.1 图像去雾
近年来,端到端CNNs被设计成直接从输入雾图像中学习干净图像以进行去雾。 Li等将VGG特征和L1正则化梯度引入条件生成对抗网络(cGAN)进行无雾图像重建[9]。Ren等设计了一个编码-解码器网络(GFN),从三个由不同物理模型生成的雾图像中学习置信度图,并将它们融合到最终的去雾结果中[10]。Liu等将语义分割任务中的GridNet网络引入到图像去雾任务上,提出了一个GridDehazeNet用于端到端图像去雾[11]。Qu等提出了一个增强型Pix2Pix去雾网络,通过分阶段的去雾模块来增强去雾效果[12]。Deng等提出了一种深度多模型融合网络,将多个物理模型得到的结果融合到不同的层中,大幅提高了图像去雾的性能[13]。上述方法在图像去雾任务上效果显著,然而,在去雾过程中,图像的高级语义信息并未得到充分考虑,去雾结果也不能完全适用于图像语义分割。为了克服这一缺点,本研究将图像去雾与语义分割算法融合到统一的网络框架中,通过图像重建损失、分割交叉熵损失共同优化去雾模块。在图像语义信息的约束下,去雾网络产生了更加突出的语义特征,进一步提高了分割的精确度和鲁棒性。
1.2 语义分割
传统的语义分割方法通过使用支持向量机(Support vector machines, SVM)等手工先验分类器实现逐像素分割。 Brian等使用超像素作为类分割和像素定位方法的基本单元,根据每个超像素中找到的局部特征直方图构造分类器,并通过在每个超像素的邻域内聚合直方图来规范分类器,然后使用条件随机场进一步细化分割结果[14]。Gabriel和Florent提出了一种简单的语义分割方法,通过强制执行局部一致性来指导图像低层次分割,并使用全局图像分类器增强图像级别的一致性[15]。Shotton等通过对图像纹理、布局和上下文信息的联合建模来实现多类对象的识别和分割[16]。
随着深度学习技术的进步和大规模数据集的开发,语义分割任务得到了突飞猛进的发展。Vijay等提出了一个新颖的深度分割网络模型,简称SegNet[1]。该网络由一个编码器网络、一个相应的解码器网络和一个像素级的分类层组成,具有高效的存储内存和计算时间。Long等通过融合深层和浅层的特征信息[17],将分类网络(AlexNet[18]、VGG[19]和GoogLeNet[20]) 改造为完全卷积网络,并微调最终的表示形式,实现分割任务的要求。Chen等通过使用扩张卷积来获取上下文信息,并提出了一种基于空间特征金字塔的上下文信息聚合语义分割网络[21]。Zhao等提出了一种图像级联网络(ICNet),通过处理多分辨率的图像,减少像素级标签预测产生的高计算量,通过级联特征融合实现高质量的语义分割结果[3]。Jiao等提出了一种专门用于语义分割的知识蒸馏方法,提高了整体跨距大的紧凑FCNs的性能[22]。此外,为了解决学生网络和教师网络之间特征不一致的问题,通过利用预先训练好的自动编码器转移潜在域的特征相似度,通过计算整个图像的非局部相互作用来获取特征间长期依赖关系。然而,上述语义分割算法使用的数据集大都是在亮度适当、轮廓清晰和色彩均衡条件下收集的,当在雾天环境,特别是大雾环境下测试时,其准确率会大幅降低。因此,本文使用有雾情况下的图像数据集,通过去雾编码模块和特征转移模块,实现有雾特征到无雾特征的转移,增强了算法对有雾天气的适应性和鲁棒性。
1.3 多任务学习
多任务学习被广泛应用于计算机视觉问题中。Teichman等提出了一种使用统一架构进行联合分类、检测和分割的方法,其中编码器在三种任务中共享[23]。Kokkinos提出了一个UberNet网络,该网络通过联合处理进行边缘检测、角点估计、显著性估计、语义分割、人体部分分割、语义边界检测和目标检测等低、中、高级的任务[24]。Eigen等使用多尺度CNN来处理深度预测、表面法线估计和语义标记三种不同的计算机视觉任务[25]。Xu等提出了一种多任务引导的预测蒸馏网PAD-net,从低级特征到高级特征的转换,将转换特征作为最终任务的多模态输入[26]。目前,多任务学习都是提取联合特征,然后进行任务分类,最后实现多任务的目标,属于并行处理机制。本文以语义分割作为唯一的任务目标,通过去雾和分割两项任务顺序处理,实现任务间的影响和相互促进。
2 方 法
为提高雾天语义分割的准确率和鲁棒性,降低语义分割模型的存储和计算成本,设计了一种图像去雾和语义分割任务融合的深度学习模型,如图1所示。MFANet以编码解码器网络为基础,将编码模块和解码模块分别应用于图像去雾和语义分割,通过特征转移模块连接编码和解码器。
2.1 去雾编码模块
Dehazing encoder module为去雾编码模块如图1 所示,由一个4层的空间金字塔构成,通过对输入图像进行连续的卷积和下采样生成不同分辨率的特征图。为降低参数和计算复杂度,前三层采用两次卷积操作,最后一层采用一次卷积操作,每一个卷积操作后都伴有一个Relu激活层,卷积核大小为3×3,步长为1,通道数量分别为32、64、128和256。每层的下采样方式为最大池化,训练阶段输入图像的尺寸为256×256,各层的特征分辨率分别为256×256、128×128、64×64和32×32。随着网络深度的增加和池化下采样次数的增多,网络的高频特征容易丢失。因此,去雾编码模块采用跨尺度残差连接来恢复丢失的细节信息,跨越的尺度层采用卷积核大小为3×3、步长为2的卷积操作对齐不同分辨率的特征图,并以通道叠加的方式进行特征融合。跨尺度残差连接可以表示为:
xl+1=p(xl)+f(xl)
(1)
式中:l表示不同分辨率的特征层;p(·)为卷积核大小为3×3、步长为2的卷积下采样;f(·)由两个步长为1的卷积和一个最大池化构成。
2.2 分割解码模块
分割解码模块与去雾模块相对应,分割解码模块通过连续的卷积和反卷积逐步上采样特征图,每一个尺度的特征均是由上一尺度的反卷积和对应的编码器转移特征层融合组成,并通过卷积和反卷积操作传输到更高分辨率层。 在分割解码器模块中,最低层采用一次卷积操作,后三层采用两次卷积操作,每一个卷积操作后都伴有一次Relu激活层,卷积核大小为3×3,步长为1,通道数量分别为256、128、64和32。每层的上采样方式为反卷积,训练阶段输出图像的尺寸为256×256,各层的特征分辨率分别为32×32、64×64、128×128和256×256。在解码器模块中,低分辨率的特征图具有更大的感受视野和全局信息,高分辨率的特征图具有更多的细节信息和局部特征。为了使分割算法适应不同分辨率图像,并提高不同尺度目标分割的精度,在输出层采用多尺度融合方法进行特征汇集,具体过程如下:
S=cat(L1,L2,L3,L4)
(2)
式中:S为融合后特征图;cat(·)为特征图级联叠加;Li为不同层的输出特征图。为对齐低分辨率特征到输出分辨率,采用反卷积方式进行上采样。
为重点关注有利于分割的特征信息,弱化噪声等无关信息,各尺度特征融合后采用注意力机制进行非线性的特征通道筛选。注意力模块以SE-block[27]为基础,主要分为通道压缩和特征激励两个阶段。利用特征图的通道间关系来产生通道注意力图,通道注意力主要关注各通道全局的突出特征。首先,为了有效汇集空间信息,计算各通道的非线性关系,压缩了输入要素图的空间维度,对每个通道实施全局平均池化操作,具体计算公式为:
(3)
式中:Cr表示第r个通道;XCr(i,j)代表第r通道的第i行第j列元素。
激励阶段是由2个全连接层(FC)和一个Relu激活函数组成,然后再由门控函数Sigmoid控制输出,两次全连接采用中间层8倍降维,即FC(480,60)-FC(60,992)。激励过程可表示为:
MC(F)=σ(W1δ(W2ZCr))
(4)
式中:δ(·)表示Relu激活函数;σ(·)表示Sigmoid函数。
2.3 特征转移模块
MFANet(Feature transfer moduleke)共包含4个特征转移模块,每一个特征转移模块都连接一对相应的去雾编码层和分割解码层,输入特征层为去雾编码层,输出层传输到分割解码层。特征转移模块的详细结构如图2所示,分别由卷积、Relu激活、卷积、Sigmoid、逐像素相乘和逐像素相加组成,其中2个卷积层的卷积核大小为3×3,步长为1。
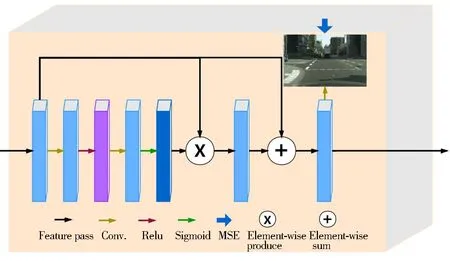
图2 特征转移模块框架结构Fig.2 Architecture of feature transfer module
2.4 损失函数
语义分割的目标函数是分割损失,并不能对输入的雾图像进行明确的雾噪声去除建模。并且随着网络的加深,图像的高频纹理特征易出现丢失,不利于精确分割其边缘细节。 因此,在每个特征转移模块,加入了一个重建损失来强制约束去雾编码阶段的特征结果更接近无雾图。使用均方误差MSE作为重建损失,可以表示为:
Lmse=‖XT-Xgt‖2
(5)
式中:XT表示去雾后图像;Xgt表示清晰的目标图像。
对于最终的分割输出,使用预测的伪像素标签和标注标签之间的交叉熵作为分割损失。分割损失可以表示为:
(6)
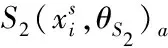
3 实验数据
使用Cityscapes数据集[28]作为原始图像数据。Cityscapes是一个由车载相机采集的真实城市道路图像数据集,拍摄范围覆盖了德国及其附近国家的50个城市。该数据集共包含5 000张分割标注好的图像样本,其中训练集2 975张,验证集500张,测试集1 525张。所有训练、验证和测试图像的每个像素都进行了精准的类别标注,数据集中共有34个不同的分类。此数据是在晴朗的天气情况下采集的,图像质量较高,而本文主要解决雾天的图像语义分割问题,因此,在Cityscapes数据集上合成雾噪声。在高质量图像上添加模拟雾,通常是将雾建模为一个函数,该函数与场景深度密切相关,并由场景到摄像机的距离参数化。因此,无雾图像和其深度图构成了雾天图像合成的基础。
在以往的去雾研究中,使用了各种光学模型来模拟雾对可视化场景的影响。因为有雾和无雾情况下形成图像的物理过程本质上是相似的,所以在无雾图像合成过程中使用了标准的光学模型,表示为:
I(x)=R(x)t(x)+L(1-t(x))
(7)
式中:I(x)为有雾图像的像素;R(x)为无雾图像的像素;L为全局大气光程;t(x)为传输量,决定了到达相机的场景亮度。在均匀介质的情况下,传输量取决于场景到相机的距离l(x),可以表示为:
t(x)=exp(-βl(x))
(8)
式中:β表示衰减系数,能有效地控制雾的厚度,值越大则产生的雾越重。
气象光学距离(Meteorological optical range,MOR),又称为能见度,是描述雾严重程度的常用指标,通常相机到场景的距离要大于0.05 m,由式(8)可知,此时的能见度为MOR=2.996/β。根据气象标准,雾天的能见度要低于1公里,因此,衰减系数的取值范围确定为:
β> 2.996 × 10-3m-1
(9)
根据式(9),原始图像可被合成为轻雾、中雾和重雾三种类型,对应的衰减系数分别为0.005、0.015和0.030,可视化结果如图3所示,合成雾后的数据集由原来的5 000张图像扩充到15 000张。

(a) Clean image
4 实验数据
4.1 实验设置
实现细节:MFANet采用ADAM优化方法,参数Beta1和Beta2分别设置为0.9和0.999,学习率为5×10-5,权重衰减为2×10-4,Batch size为16。实验环境为基于Ubuntu 16.04操作系统的PyTorch深度学习框架,使用GPU进行训练,配置NVIDIA CUDA 10.1+cuDNNv 7.6.1深度学习库加速GPU运算,用于训练和测试的软件为Python 3.5,训练阶段共使用了3块NVIDIA Tesla V100 32GB GPU。
评价指标:IOU (Intersection over unions)是语义分割任务中常用的评价标准,它量化了预测掩模与标签掩模之间的重叠度。具体来说,对于每个类,IOU为预测区域与目标区域的交集与并集之比。表示为:
(10)
式中:I(X)表示交集集合;U(X)表示并集集合,可近似如下:
(11)
当存在多个类时,则计算所有类的平均IOU(mIOU)。
4.2 实验设置
不同方法在Cityscapes有雾图像上的定性分割结果如图4所示,所有实验图像均为真实车载相机拍摄,前三行为重度雾,后三行为轻度雾。比较了目前在mIOU和FLOPs上表现最好的两种方法,其他方法由于页面限制不再展示,定量结果如表1中所示。如图4所示,每一类物体场景均由一种颜色标签标示,由于雾对图像色彩、纹理等的影响,ESPNetv2和ERFNet的分割结果比较差,无法准确判断类别,并且边界分割不清晰。而本文提出的MFANet则有效克服了雾给分割任务带来的影响,其结果在场景分类和边界分割上更加准确。

(a) Haze image
不同方法在Cityscapes雾图像测试集上的定量恢复结果如表1所示,分别对比了平均IOU (mIOU)和浮点运算数 (FLOPs)两个指标,最好的结果字体加粗显示,次好的下划线显示。可以看出,在雾图像上已有方法的mIOU均比较低, 最好的ERFNet只有55.9,而本文方法的mIOU为66.8, 要明显高于其他方法。在FLOPs指标上,尽管本方法包含了去雾模块和分割模块,但由于对这两个任务模块融合处理,所以MFANet的FLOPs仅有3.3 B,要远低于其它方法。虽然比方法ESPNetv2略高,但mIOU却比其高出12.5,具有更高的综合性能。

表1 不同方法在Cityscapes雾图像测试集上的mIOU和FLOPsTable 1 mIOU and FLOPs on the Cityscapes haze image testset by different methods
为了进一步证明本文方法的鲁棒性和对环境的适应性,Cityscapes图像测试集无雾情况下的测试结果如表2所示。在无雾情况下,本方法依然取得最好的定量分割结果,在mIOU上比次好的ERFNet高出 6.1。

表2 不同方法在Cityscapes测试集(无雾)上的mIOU和FLOPsTable 2 mIOU and FLOPs on the Cityscapes testset (without haze) by different methods
为验证各关键技术对网络性能的影响,通过消融实验进一步证明了各个模块的有效性。如表3所示,在Cityscapes有雾测试集上,通过分别对跨尺度残差连接、多尺度特征融合和注意力模块进行了消融实验,结果表明各模块对分割的性能都有一定程度的提升,证明了其有效性。

表3 不同技术模块在Cityscapes有雾测试集上的mIOUTable 3 mIOU on the Cityscapes haze image testset by different technology modules
5 结 论
设计了一种新颖高效的多任务融合注意力网络,有效地解决了雾环境下的图像语义分割问题。通过对网络的结构优化,既减少了存储和计算成本,又有效克服了雾噪声对分割任务的影响。实验结果表明,本方法分割的雾图像,可以生成更准确、更精细的结果,具有更高的mIOU。所提出的方法可推广到不同类型的低质量图像语义分割任务,如模糊图像语义分割和暗图像语义分割等。
