Top-k近似否定约束的发现
2021-12-14谈子敬
冉 艾 谈子敬
(复旦大学计算机科学与技术学院 上海 200433)
0 引 言
互联网的广泛使用使得数据集的来源变得多样化。很多用户参与内容生成或提供的数据集允许在互联网上传播和同步修改。比如维基百科、百度百科中词条的解释是面向全网开放编辑的,即允许所有网民进行自定义的修改。在上述操作过程中,数据的真实性或者准确性无法得到有效的保证。学术数据库或者知识图谱之中也经常出现错误论文信息,比如信息缺失或论文重复记录。数据一致性成了数据质量的一个重要指标之一。发现数据里的约束,再使用数据约束去修复数据集已经成了数据处理的基本流程。
数据约束对后续的数据处理非常重要,目前已有大量数据约束方面的研究。常见的数据约束包含字段级约束和表级约束。其中,字段级约束指只对单个元组或者单个字段有约束,比如域约束、检查约束等;表级约束指定义在两个元组间的多个字段的约束,常见有函数依赖、条件函数依赖、次序依赖和差分依赖等。在现实中,字段级约束与表级约束可以同时存在于同一个数据中,且数据间的关系不仅仅有等于或者不等,还有着大于、小于的次序关系。否定约束[1]是一个表达能力极强的数据依赖的形式,它满足了以上的需求。常见的域约束、主键约束、函数依赖、条件函数依赖和次序依赖等都可以转为相应的否定约束形式。
在数据约束的相关工作中,数据约束的发现是一个基础的问题。因为原始数据上会有数据与现实不一致,近似约束的发现也变得尤为重要。文献[2-3]的实验结果表示,一个数据集上面发现的否定约束往往数目是数以千计的,近似否定约束的结果往往更多[4,9]。为了得到具有更高语义的Top-k的近似否定约束,选择评价否定约束剪枝指标变得非常必要。文献[3]提出了两个评价指标,但其得到的否定约束没有考虑到数据相关性,得到的结果有可能会将毫无关系的变量放进同一个否定约束中。本文引入了信息论中的互信息评估指标,并且借鉴了文献[5]中的无偏估计来评价两个变量间的相关性。将这样的相关性加入到近似否定约束发现的流程中,作为否定约束的一个评价指标之一,保证了得出的结果包含的变量具有较强的相关性。
本文的研究目标是在数据集上面发现Top-k的近似否定约束。在发现过程中加入信息论的指标来保证得到的否定约束中包含的属性具有较好的相关性。提出可以实现Top-k近似否定约束的算法,在数据集上比较算法的时间和否定约束结果集性质。
1 背景知识
1.1 否定约束
在给出否定约束的具体定义前,需要说明一些必要的记号。给定关系R及R上的实例I,记属性集合为attr(R)={A1,A2,…,Am}。其中Ai表示一个属性,其值域记为dom(Ai),i∈{1,2,…,m}。一个元组t代表关系数据实例I中的一行,记t.A表示该元组在属性A上的取值。
定义1否定约束是形式为否定多个谓词同时存在的实体约束语言。其表达式如下:
φ:∀tα,tβ∈R(p1∧p2∧…∧pk)
式中:p为一个谓词表达式,表示为v1θv2;tα和tβ为数据表中的元组;θ为符号运算符,θ∈{=,≠,≤,≥,<,>}。谓词表达式中的v1和v2指元组的值,即v1,v2∈T.A,T为tα或者tβ,A为任意属性。否定约束表示约束中的谓词不能同时为真,即不存在数据集中的元组或者元组对满足否定约束中的所有谓词。φ.pres表示φ中包含的谓词构成的集合。
例如,在表1中的税收缴费记录中,每一个记录为一个税收缴费,包含了元组编号(TID)及5个描述个人信息的属性,分别为姓名(Name)、所在州(ST)、邮编(ZIP)、工资(SAL)、税率(Rate)。

表1 税收缴费记录
可以验证以下的否定约束成立:
φ1:(tα.ZIP=tβ.ZIP∧tα.ST≠tβ.ST)
φ2:(tα.Name=tβ.Name)
φ3:(tα.ST=tβ.ST∧tα.SAL>tβ.SAL∧tα.Rate 其中的否定约束φ1为函数依赖ZIP→ST表明两个元组在邮政编码上相等时,元组所在的州名需要相等。φ2为主键约束,即两个元组的姓名不能相等。φ3表示在同一个州中,收入越高则税收率越高。 定义2给定一个实例I0和否定约束φ,如果约束φ成立,称φ为有效的否定约束。如果在任意的实例I中,均有φ成立,那么称φ为平凡的否定约束。在实例I0中,如果不存在有效否定约束φ1满足φ1.pres⊂φ.pres,则称φ为最小的否定约束。 一个m维的数据集,可以得到不同的元组和属性组合会有2m×(2m-1)种。因为谓词可以有6个不同的符号,所以谓词空间大小为P=6×2m×(2m-1),所以否定约束的整体搜索空间为2P。 衡量两个变量间的相关性有很多种方法,比如数据的相关性系数、协方差矩阵。在信息论中,使用两个变量间的互信息来评估两个变量间包含的信息多少。如果变量间的互信息量高,说明变量间的相关性是非常强的。 定义3将互信息量归一化为互信息分数: 目前已有的相关研究主要如下。(1) 文献[1]提出了否定约束的概念,文献[2]描述了否定约束的发现算法,文献[3,9]分别提出了否定约束的发现算法改进以及近似否定约束的发现。(2) 近似数据约束发现:文献[4-5,8-9]分别提供了函数依赖、差分依赖及否定约束的近似发现算法。(3) 属性间相关性计算:文献[5-7]给出了不同情境下使用互信息计算方式。(4) 约束的修复使用:文献[10]利用已有的约束进行修复数据。 在以往发现否定约束的文献中,在数据集上面发现的非平凡的最小否定约束结果一般都是非常大的,一般都是成千上万个。即使限定了不能进行跨列的属性比较,得到的否定约束结果也会是数以千计。这么大的约束结果对后续数据约束的修复或者数据处理是非常不便的。所以在数据集上面查找Top-k的否定约束对后续的数据处理是有必要的。本文在文献[2,5]的基础上提出了在数据集上查找Top-k的近似否定约束的算法。因为数据集上两个不同属性进行比较是没有太大实际意义的,所以本文主要考虑不跨列的谓词组成的否定约束。包含跨列谓词组成的Top-k否定约束发现只需要在数据集转换流程做相应的修改即可。 首先利用数据转换方法得到数据集I0,然后在数据集I0上计算相应的否定约束。因为互信息量计算需要给定变量Y,所以算法假设选定了兴趣属性Y。如果没有指定属性,则简单地将所有属性轮流做兴趣属性即可得到全局上的Top-k结果。算法流程如算法1所示。 算法1否定约束发现算法Find_Bst 输入:转换后的数据表I0,兴趣属性Y,阈值α。 输出:包含特定属性Y的Top-k否定约束。 1. 初始化属性集Q,DSCk。 3. 扩展分数最高的属性集top(Q): Rs=extend(top(Q)),Q=Q op(Q) 4. 更新当前的Top-k集合: DCSk=Top-k(DCSk∪Rs) 5. 更新目前的属性集: 6. 重复步骤2-步骤5 7. 根据转换后的数据表I0返回DSCk中属性集生成的否定约束。 否定约束是在数据元组对的约束,函数依赖也是元组对上的数据约束。所以希望建立函数依赖和否定约束间的联系使得将函数依赖上的算法能够转换到否定约束算法中。通过数据转换可以将原始数据集上的否定约束转换为新数据集上的依赖关系。 对于表1中的数据,由于姓名(Name)、所在州(ST)为字符串形式,即互相比较大小是没有意义的。包含这些属性的谓词符号为相等或者不相等。邮编(ZIP)、工资(SAL)及税率(Rate)是可以进行大小比较的,所以在这些属性上面需要考虑6个不同符号。但在一个特定的元组对中,属性的值只包含大于、等于、小于三种不同的情况。这样就可以通过将元组对改为只含-1、0、1三个数字的元组,-1表示小于或者字符型属性上的不等,0表示相等,1表示大于。 考虑元组对 表2 转换后新数据 由表2可以看出,在属性Name上面,所有的元组属性均为-1,这表明在原始数据集表1中,所有的元组对的Name属性不相等,即否定约束φ2成立。 现实数据集往往包含百万以上的元组,直接在所有数据上计算变量间的相关性或者信息量会非常繁琐,所以常常使用随机抽样的方法来评估互信息分数。目前有非常多的方法在抽样数据上估计信息量。但是这些方法并不是无偏的估计,且误差与变量值域大小密切相关。例如以表2中的数据进行估计,会产生非常大的误差。本文采用文献[5,7]提出的无偏估计。这样的无偏估计误差与抽取的变量包含的不同可能取值无关。这个性质在本文算法中是非常必要的,因为本文转换后的数据每一个属性至多只有3个不同的取值。 对于变量X、Y,假设在数据中抽取出n个元组。在这n个元组上,X的不同取值有D种,Y的不同取值有C种。记X的值域为dom(X)={x1,x2,…,xD},Y的值域为dom(Y)={y1,y2,…,yC},使用ai表示在抽样数据n个元组中X的值为xi的元组数目,对应的bj表示在抽样数据中Y的值为yj的元组数目。 定义3中的互信息分数估计计算公式为: (1) (2) p(k)为一个超几何分布的概率,计算公式为: (3) 为了简化计算过程,可使用递推公式计算: (4) 错误率ER用来评判近似约束的好坏,即在数据集中有多少比例的元组对不满足约束,计算式如下: (5) 错误率越低说明近似约束越能描述出数据集的性质,约束的适用性也越高。 对于否定约束,文献[1,3]还提出了两个评价指标,分别为覆盖率与简洁性。因为简洁性可以直接用于属性集合中,本文打分函数中只采用了简洁性。后续的实验表明,即使算法中没有考虑覆盖率,得到的结果覆盖率并不会比对比算法低太多。如果一个否定约束的包含的谓词数目越多,则表明简洁性越低。其计算公式为: (6) 式中:L为一个给定常数;φ.pres为否定约束中包含的谓词集合;|φ.pres|为否定约束中谓词个数。 为了使得否定约束具有更好的简洁性,本文在定义3基础上使用如下的打分函数: (7) 式中:F(X;Y)为定义3中的评价分数;X为否定约束φ中除了Y以外的属性组成的集合;φ.pres为否定约束包含的谓词集合;λ为参数。一个否定约束集合打分定义为集合中包含的否定约束的最小打分,即f(DSCk)=min(f(dc)),dc∈DSCk。 (8) 前文的打分函数都是基于谓词个数和包含的属性,并没有确定否定约束中各谓词的符号。本文依据在转换数据集中出现次数(如表2中的count属性)的元组作符号选择。这样的选择可以使得在抽样数据中的错误率最小,保证约束的性质。 对属性集合X及Y,首先按照X和Y出现在数据集I0的所有取值在count属性上的值进行由小到大进行排序。以count属性上最小的取值作为基准符号,再逐个属性考虑能否将符号进行扩展。比如属性Y在最小的取值为-1或1时,考虑X上取值相同的时候,Y为0的count是否满足可以进行符号扩展的条件。 以表2数据为例,考虑X={SAL},Y={Rate}。因为SAL和Rate均为数值型变量,那么在I0中的出现次数由小到大分别为:1次<1,-1>、<-1,1>、<-1,0>、<0,1>及4次<-1,-1>、<1,1>。选取<1,-1>为基准。假设选择扩展的标准为满足的count之和小于总元组对数的10%。此时的count为1是小于12×10%的。保持其他属性取值不变,考虑能否将SAL的符号扩展为≥,即<0,-1>是否可以包含。因为I0中不包含<0,-1>,因此可以将SAL的符号扩展为≥。再考虑将Rate的符号扩展为≤是否可行。同样因为<0,0>以及<1,0>不在I0中,所以可以扩展。最后得到的近似否定约束为: (tα.SAL≥tβ.SAL∧tα.Rate≤tβ.Rate) 在这一过程中,count之和即为2.4节中定义的ER。文献[7]提出的ER近似评估方法指出抽样数据中可以有效估计原始数据集的错误率,且这个抽样数据集是与原始数据集大小无关的。所以使用这样的符号选择方式也可以减少产生的近似否定约束在原始数据集上的错误率。 实验使用的环境为Intel(R) Core(TM) i7-7700-3.60 GHz的CPU,8 GB内存,64位操作系统的计算机。使用的实验数据是人工的税务数据集Tax,以及描述字母的特征真实数据集LETTER,其中:Tax拥有7个字符型属性,8个数字型属性;LETTER包含1个字符型,11个数字型属性。本文使用的默认数据集大小为50 KB,阈值α为0.4,K为10。 文献[3]提出利用覆盖率及简洁性打分函数进行剪枝,可以很好地得到分数高的Top-k否定约束。本文在其基础上做些许改动后,使得其可以发现近似否定约束,作为对比算法Fast_Rank。因为覆盖率的计算是一个复杂度为O(n2)的计算,导致计算时间非常长。在两个数据集上,在不同的K取值时均可以观察到对比时间明显慢于本文算法Fast_Bst。下面给出了具体算法运行时间,图1(a)为Tax数据结果,图1(b)为LETTER数据结果。 图1 Fast_Rank和Find_Bst的时间结果 本文的算法是基于抽样数据的结果,即算法的运行时间取决于抽样元组对数目r。故相较于Fast_Rank需要在全部数据上进行运算,本文算法Fast_Bst大幅度减少了运行时间。 图2展示了算法时间与抽样元组对数目r(K)及剪枝分数的阈值α的关系。 图2 不同r和α取值的Find_Bst时间结果 可以看出运行时间与抽样的元组对数目r成正比。当剪枝分数的阈值α越高时,满足步骤2的剪枝越多,运行时间越短。 使用的评测指标有错误率(ER)、简洁性(Succ)和覆盖率(coverage)。为了将错误率及简洁性结果归一化,图3展示的结果是错误率(简洁性)与结果中最高错误率(简洁性)的比值ER′(Succ′)。比值越低说明错误率越低,简洁性越差。 图3 不同α取值和K的性能分析 图3(a)为在数据集LETTER上面改变阈值α的三个评分指标的变化。可以观察到当阈值变大时,覆盖率没有发生大的变化,但是错误率明显提升,包含的谓词数目因为扩展的概率变小,所以简洁性变好。图3(b)为Find_Bst算法和Fast_Rank算法在不同K上的运行结果的评价分数的比值。可以观察到在K比较小的时候(K=5),本文算法与Find_Bst算法结果有些许差距,当K变大时,差距趋向于减少。总体上本文的结果与对比算法的结果在评价指标上面非常接近。 否定约束用于描述属性间的关系,相比其他的约束而言,具有更好的表达能力和更多能够包含的符号。但是表达能力强导致了在数据集上会成立非常多的否 定约束。因为数据集有时候会出现误读误写以及用户希望找寻与兴趣属性相关的否定约束时,只需要发现评分较高的Top-k近似否定约束即可。本文针对这个问题提出了利用属性间的相关性以及否定约束的简洁性分数做分支定界的剪枝函数。通过实验,算法的时间优势非常明显,得到的K个近似否定约束在评价指标上与对比算法基本一致。 未来工作还需要考虑跨列的否定约束的Top-k发现算法。针对包含跨列的否定约束,可以在数据转换中进行相应的修改,也可以在属性集合与约束转换中进行扩展。1.2 变量间相关性

1.3 相关工作
2 算 法
2.1 算法流程
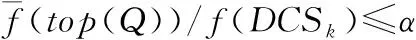

2.2 数据转换

2.3 相关性计算
2.4 评价函数
2.5 属性集合与约束转换
3 实 验
3.1 时间分析


3.2 性能分析

4 结 语
