基于TensorFlow的深度神经网络优化方法研究
2021-12-08王保敏阮进军
王保敏,王 睿,阮进军,慈 尚
(安徽商贸职业技术学院 信息与人工智能学院,安徽 芜湖 241002)
深度神经网络可以视为添加了若干个隐藏层的神经网络,它是感知机的拓展.感知机的基本结构包括输入层和输出层,输入层用于接收来自外界的信号,其模型如图1所示.
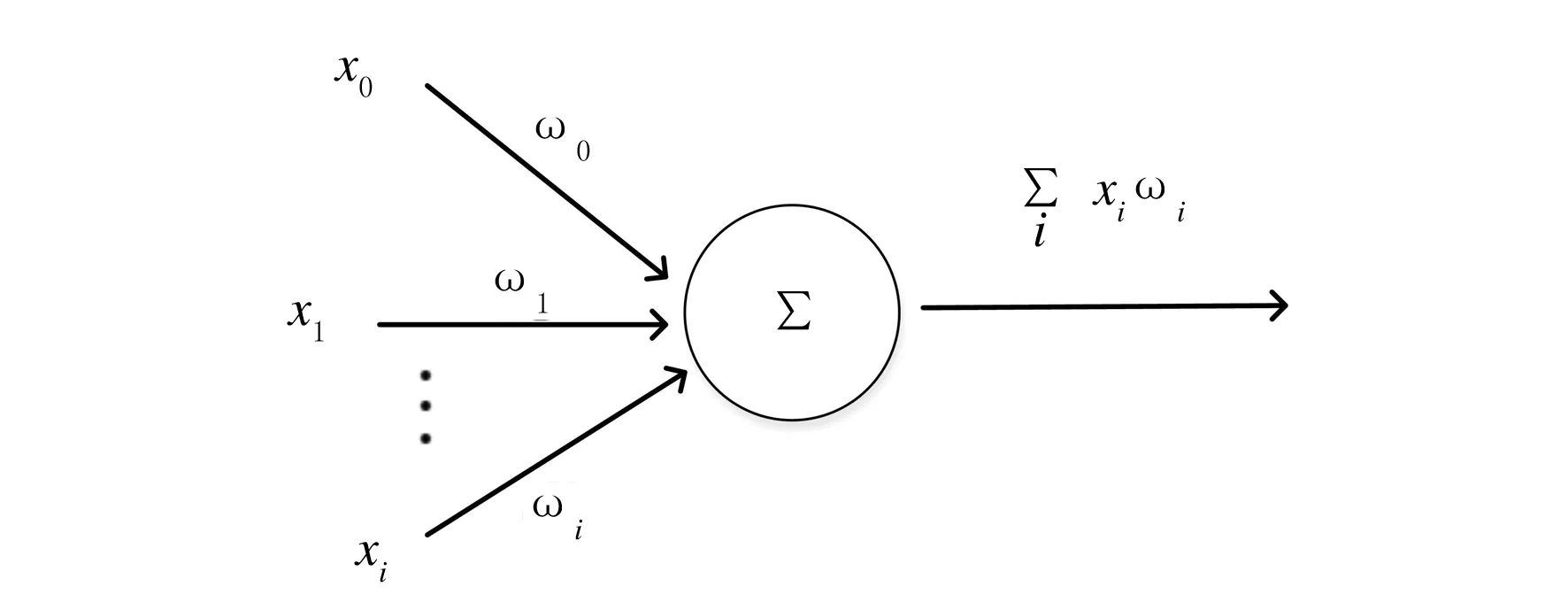
图1 感知机模型结构
感知机输出和输入之间的关系是线性的,经过学习可得到的输出结果为
(1)
经过神经元激活函数,可以得到最终的输出结果为1或者-1[1]:
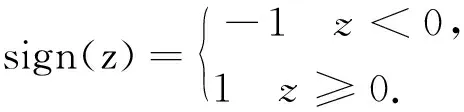
(2)
可以看出,一个简单的感知机模型能够解决的仅仅是二分类问题.对于复杂的非线性模型,感知机模型无法通过学习得到理想的结果.随着机器学习技术的发展,神经网络逐步替代了感知机,其对感知机模型做了3个方面的拓展:首先,在输入和输出之间增加了隐藏层,可以根据需要设计成多层结构,从而增强了模型的表达能力;其次,输出层的神经元不再局限于两个结果,而是可以为多个结果输出,这样模型可以灵活应用于分类回归以及其他机器学习领域的降维和聚类等问题;最后,神经网络对感知机的激活函数做了扩展,可以是tanx、Softmax或者ReLU等,比如在Logistic回归里面通常采用的是Sigmoid函数,即:f(x)=1/(1-e-x).不同的激活函数,在不同程度上都增强了神经网络的表达能力.
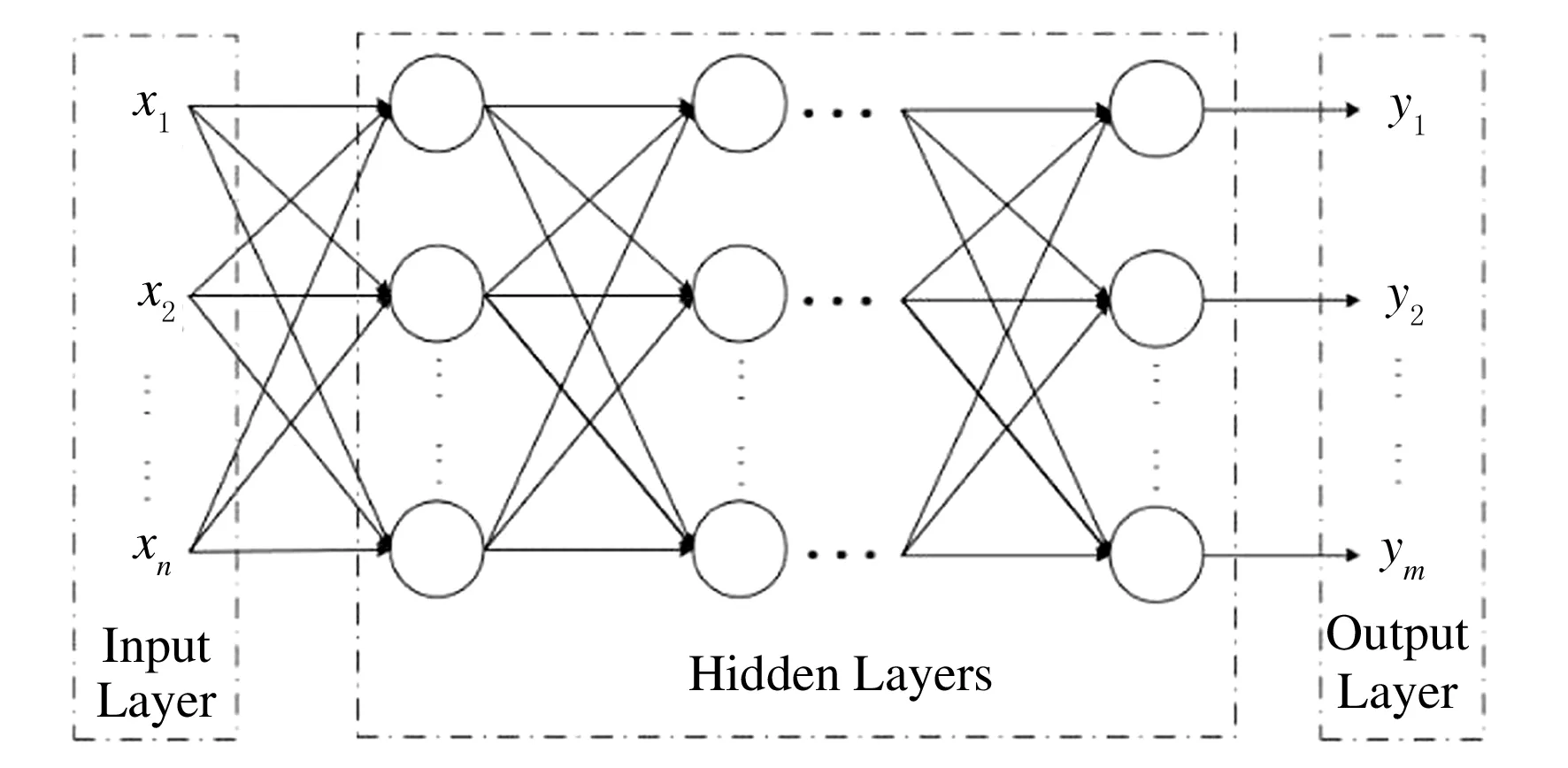
图2 深度神经网络结构
从结构上看,深度神经网络(Deep Neural Networks,DNN)是一个包含了多个隐藏层的网络,由输入层、隐藏层和输出层组成,层与层之间是全连接关系.虽然DNN内部组成部分关联性较大,但是从微观范围来看,基本与感知机类似,局部输入和输出之间是线性关系.从总体上看,DNN本质上是一个非线性非凸函数[2],其基本结构如图2所示.
1 问题分析
深度学习是一种基于特征的学习方法,而特征是通过学习过程从数据中提取出来的[3],一般可以通过两个步骤实现对神经网络的优化.首先是通过前向传播算法得到模型的输出值(预测值),同时计算输出预测值和真实值的差值;其次利用BP(Back Propagation)算法求得损失函数对模型中每个参数的偏导数(梯度),最终通过偏导数和学习率(learning rate)使用梯度下降算法迭代计算出各个参数的取值.
1.1 过拟合问题
在实际应用场景中,并非仅仅是使用深度神经网络去模拟训练数据,而是通过训练,使得模型更加贴合实际从而最大程度地判断未知数据.判断模型在未知数据中的性能,并不能完全根据其在训练数据上的表现结果,原因在于存在着过拟合问题.所谓过拟合,指的是当模型复杂程度变高之后,虽然能够较好地刻画出训练数据中的随机噪音,但是在挖掘和提炼训练数据中的通用规则或者特征等方面表现出了局限性.过拟合由于过度关注了训练数据中的噪音而忽视了问题的整体规律.
1.2 参数值突变问题
权重weight和偏差bias在神经网络模型训练过程中可能出现更新幅度过大或者过小,从而表现出参数值在迭代过程中出现“突变”现象,导致训练过程中遇到异常波动状况,降低了模型在未知数据上的健壮性.为便于说明这一问题,假设某个参数x在训练过程中得到了原始10个数值,用集合表示,记为x={-10,2,5,6,1,8,3,5,6,3,-1},显然可以看出这10个值存在较大的波动性,尤其是-10作为参数将会是一个“噪音”,代入模型后,会对训练结果产生较大的干扰,不利于模型的训练效率和结果求解.
2 计算方法优化
针对上述问题,本文分别引入了正则化思想解决过拟合问题,采用滑动平均模型解决参数值突变问题,提高模型的训练效果.
2.1 正则化处理
为了优化模型参数,避免过拟合问题,一个常用的方法是对模型进行正则化(regularization)处理[4].正则化通过约束参数的范数来降低模型的复杂度,其基本方法是在损失函数中增加能够表现模型复杂程度的附加项[5].假设模型中的损失函数为P(θ),描述模型复杂程度的函数是Q(ω),那么正则化处理的方式是:在优化P(θ)的同时,优化Q(ω),即综合优化P(θ)+λQ(ω),其中λ为模型复杂损失在总损失中的比重,θ代表神经网络模型中的所有参数,包括权值ω和偏移值b.通常模型复杂程度是由权重ω所决定.常用的描述模型复杂度的函数Q(ω)有两种,一种是L1正则化,对ω取模后求和,计算公式为:
(3)
另一种是L2正则化,对ω平方取模后求和,计算公式为:
(4)
公式(3)和(4)中ωi表示模型中第i个权重参数.上述两种正则化方法的思想都是试图通过限制模型中权值的大小来减少拟合训练数据过程中出现的随机噪音,但L1正则化和L2正则化是存在很大差异的.L1正则化可以让参数在训练过程中变为0,显示出更稀疏的性质,从而有利于模型类似特征的选取.L2正则化避免了这种情况的出现,因为当参数取值很小时,其平方更小以至于可以忽略,且L2正则化公式是可导的,在优化时会令求损失函数的偏导变得更加简洁.在实际应用中,可以同时使用L1正则化和L2正则化:
(5)
其中:α为L1正则化项所占系数.
2.2 指数移动平均模型
在神经网络的训练过程中,为了使模型结果不发生突变,参数更新幅度不能过大或者过小,且更新后的参数值与之前的参数值需要有关联,要尽量避免异常的参数值,即使遇到一些突变的数值,也需要对其进行抑制,从而保障模型的鲁棒性.为解决参数值突变问题,在模型中采用了指数移动平均算法(Exponential Moving Average, EMA),对不同阶段的权重进行平滑处理,以此来预测未知事物趋势[7],从而在一定程度上提高模型在测试数据集上的表现.
滑动平均模型的基本思想是对每个变量αt维护一个影子变量vt,vt与αt的初始值相同,在每次更新变量αt时,影子变量vt的值也做相应调整,被设置为:
vt=vt-1·β+αt·(1-β),
(6)
其中:β为衰减率,决定模型参数的更新速度.从滑动平均模型与深度学习的关系来看,使用滑动平均模型可令整体参数数据更加平滑,屏蔽了数据噪音,杜绝了异常值的出现.
3 基于TensorFlow的优化方法实现
3.1 正则化处理方法实现
TensorFlow是由Google开发的一种开源框架,借助其强大的深度学习功能,能够高效进行高性能数值计算[8].在TensorFlow中,损失函数可以加入正则化的部分,代码如下:
loss=tf.reduce_mean(tf.square(y_-y))
tf.contrib.layers.l2_regularizer(lambda)(w)
以上代码中,loss为损失函数,它包含两个部分,分别是用于衡量模型在训练数据集上表现效果的均方误差损失函数,以及抑制随机噪音出现的正则化项.TensorFlow提供tf.contrib.layers.l1_regularizer()函数计算L1的值,tf.contrib.layers.l2_regularizer()计算L2正则化项的值.在简单的神经网络中,这样可以很好地计算包含正则化项的损失函数.
3.2 指数移动平均模型实现
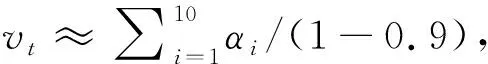
定义变量v1,其类型为tf.float32,初始值是0,用以计算指数移动平均值:
v1=tf.Variable(0,dtype=tf.float32)
定义变量step,表示神经网络中选代的轮数,其作用是用以动态控制衰减率:
step=tf.Variable(0,trainable=False)
定义类(class)来计算指数移动平均值,其中0.98为初始化时的衰减因子:
ema = tf.train.ExponentialMovingAverage(0.98, step)
定义一个操作用来更新变量的滑动平均值,需要传入的参数是一个变量列表,每执行一次操作列表中的变量将同时更新一次:
maintain_average_op=ema.apply([v1])
4 实验与结果分析
为验证正则化处理和采用滑动平均模型的效果,本文在MNIST数据集上实现了神经网络优化算法,识别数据集上的手写数字[9].
对MNIST数据集中的每张图片,像素矩阵大小为28*28,在TensorFlow中为方便输入,将其处理为一个长度等于784的一维数组,即输入层的节点数为784,输出层的节点数为10(代表0到9).此外模型的基本参数设定如下:隐藏层节点数为500,基础学习率为0.5,学习率的衰减率为0.99,正则化项在损失函数中的比重为0.001,训练轮数为50 000,滑动平均衰减率为0.98.有关正则化损失函数和指数学习率设置的说明和代码如下.
创建正则化函数regularizer:
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
定义需要正则化处理的项regularization(其中weights1为从输入层到隐藏层的权重参数,weights2为从隐藏层到输出层的权重参数):
regularization = regularizer(weights1) + regularizer(weights2)
定义损失函数loss(由交叉熵cross_entropy_mean和正则化损失regularization两部分组成):
loss=cross_entropy_mean + regularization
设置指数衰减型学习率learning_rate(其中基础学习率LEARNING_RATE_BASE为常量0.5,global_step为训练轮数,每次训练使用的样本数BATCH_SIZE为常量100,滑动平均衰减率LEARNING_RATE_DECAY为常量0.98):
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,mnist.train.num_examples/BATCH_SIZE,LEARNING_RATE_DECAY)
定义训练步骤train_step(采用梯度下降优化器GradientDescentOptimizer实现损失函数loss最小化):
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
优化前后,训练轮数与正确率之间的关系曲线如图3所示.
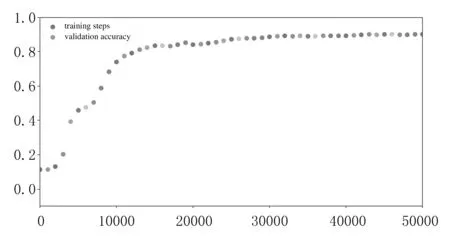
(a)优化前

(b)优化后 图3 训练轮数与识别正确率关系曲线
由图3可以看出,相比优化前,优化后的训练模型曲线更加平滑,这一趋势在训练轮数为10 000至20 000区间内表现尤为明显,显示出较高的性能.其次,从正确率上看,经过50 000轮训练,说明优化效果更好.
5 结论
随着计算机硬件性能和计算能力的提升,深度神经网络被广泛应用于语音识别和图形图像识别,其识别准确率和速率大大超过了人类.本文使用正则化和指数滑动平均算法能够优化模型的训练参数[10],能够有效避免过拟合问题,降低数据“噪音”对模型训练的影响.
