基于相对辨识度的信息系统属性约简算法研究
2021-12-07唐晓
唐 晓
(郑州工业应用技术学院 信息工程学院,河南 郑州 451100)
作为处理不精确、 不完备知识的数学工具,粗糙集[1]已经被成功应用于人工智能、 知识发现等领域,引起了越来越多学者的关注. 为此,许多学者先后从差别矩阵[2]、 相对分辨能力[3]、 知识划分相似性[4]等角度提出了相应的约简算法. 虽然这些算法能有效地实现属性约简,但某些启发式约简算法仍然存在重复计算的问题. 为了进一步提高约简效率,本文将从属性集的分辨能力出发,提出相对可辨识度,设计相应的改进算法,从候选属性集中删除不必要属性,减少不必要属性重要度的计算量,在一定程度上降低算法复杂度.
1 信息系统
为了便于理解基于相对辨识度的属性约简改进算法,下面先给出本文中涉及的若干信息系统中的定义和性质.
定义1[5]四元组S=(U,A,V,f)称为一个信息系统,其中U表示对象的非空有限集合,称为论域;A表示属性的非空有限集合;V=∪a∈AVa,Va表示属性a的值域;f表示U×A→V的一个信息函数,它为每个对象在每个属性上赋予一个信息值,即对于任意的a∈A,x∈U,有f(x,a)∈Va,通常
S=(U,A,V,f),也简记为S=(U,A).
定义2[5]设S=(U,A)为一个信息系统,P⊆A,若令
Ind(P)={
均有
f(x,a)=f(y,a)}
则称Ind(P)为P在U上的不可区分关系.
U/Ind(P)={[x]p|x∈U}表示属性集P在U上导出的划分,并简记为U/P. 其中[x]p={y∈U|
性质1[5]设S=(U,A)为一个信息系统. 若P⊆Q⊆A,则有U/Q⊆U/P,此时称Q在U上导出的划分比P更精细.
定义3[5]设S=(U,A)为一个信息系统,P⊆A,a∈P. 若U/P=U/(P-{a}),则称a在P中是不必要的; 否则称a在P中是必要的. 特别地,若每一个属性a在P中都是必要的,则称P为独立的; 否则称P为依赖的.
定义4[5]设S=(U,A)为一个信息系统,P⊆A. 若P是独立的,且U/P=U/A,则称P为A的一个约简.
定义5[5]设S=(U,A)为一个信息系统,P⊆A. 若P满足
(1)U/A=U/P,
(2) 对任意a∈P,U/A≠U/(P-{a}),
则称P是A的一个约简.
2 相对辨识度与属性约简
2.1 相对辨识度
定义6[3]设S=(U,A)为一个信息系统,P⊆A. 对任意属性a∈A,若令
DIS(P)={
f(x,a)≠f(y,a),x,y∈U}
则称DIS(P)为属性集P在U上的可辨识关系.DIS(P)是属性集P的所有可辨识对象对集合,体现的是属性集P关于论域U中对象的分辨能力. 对于任意的x,y∈U,若
性质2设S=(U,A)为一个信息系统,P⊆A. 对任意的x,y∈U,则
(1) 若[x]p∩[y]p=φ,则有
(2) 若[x]p=[y]p,则有
由性质2知,对于不同等价类中任意两个对象,DIS(P)是可以辨识的,而DIS(P)却无法辨识同一等价类中任意两个对象.
性质3设S=(U,A)为一个信息系统. 对于任意的P⊆A,则有
0≤|DIS(P)|≤|U|(|U|-1)
其中|U|为论域U的对象个数.
由定义6知,若U/P={{x1,x2,…,xn}},则|DIS(P)|min=0; 若U/P={{x1}, {x2},…,{xn}},|DIS(P)|max=(|U|-1)+(|U|-1)+…+(|U|-1)(|U|个|U|-1)= |U|(|U|-1).
定理1设S=(U,A)为一个信息系统,若P⊆Q⊆A,则DIS(P)DIS(Q).
证明对任意的Pi,PjU/P(i≠j),由于P⊆Q,由性质1知U/QU/P,故U/Q可看成将U/P的某个或多个等价类细分成多个等价类而成的新划分,假设Pi,Pj均裂变成两个Q等价类,即设
Pi=Qi1∪Qi2,Pj=Qj1∪Qj2(i1≠i2≠j1≠j2).
由性质2(1)知,对任意的x,y∈U且x∈Pi,y∈Pj,则有
可得DIS(P)DIS(Q).
由定理1知,若P⊆Q⊆A,则DIS(P)DIS(Q),此时称属性集P比Q的分辨能力弱,特别地,若DIS(P)=DIS(Q),称属性集P和Q的分辨能力相同.
推论1设S=(U,A)为一个信息系统. 若P⊆Q⊆A,则DIS(P)=DIS(Q)的充要条件是
U/P=U/Q.
推论2设S=(U,A)为一个信息系统. 若P⊆A,Q⊆A,则DIS(P∪Q)=DIS(P)∪DIS(Q).
证明
(⟹)
对任意的
(1) 若a∈P,即∃a∈P,使得
f(x,a)≠f(y,a),由定义6知
(2) 若a∈Q,即∃a∈Q,使得
f(x,a)≠f(y,a),由定义6知
(3) 若a∈P∩Q,即∃a∈P∩Q,使得
f(x,a)≠f(y,a),由定义6知
综合(1)(2)(3)知,
DIS(P∪Q)⊆DIS(P)∪DIS(Q).
(⟸)
由于P,Q⊆P∪Q,故由定理1可得
DIS(P)⊆DIS(P∪Q)且DIS(Q)⊆DIS(P∪Q),即
DIS(P)∪DIS(Q)⊆DIS(P∪Q).
综上所述,可证得
DIS(P∪Q)=DIS(P)∪DIS(Q).
定义7设S=(U,A)为一个信息系统,DIS(P),DIS(Q)分别为U上的两个可辨识关系,若令
则称DIS(P,Q)为属性集P关于Q的相对辨识度.
由定义7知,DIS(P,Q)是利用可辨识关系对属性集P,Q对论域U分辨能力相似程度的度量,DIS(P,Q)值越大,说明属性集P对论域U的分辨能力越与属性集Q相近,显然,0≤DIS(P,Q)≤1,特别地当P=φ时,令DIS(P,Q)=DIS(φ,Q)=0.
定理2设S=(U,A)为一个信息系统,DIS(P),DIS(Q)分别为U上的两个可辨识关系,DIS(P,Q)为属性集P,Q的相对辨识度,
DIS(P,Q)=1的充要条件是DIS(P)=DIS(Q).
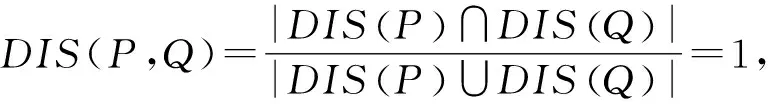
性质4设S=(U,A)为一个信息系统,则有DIS(A,A)=1.
定理3设S=(U,A)为一个信息系统. 若P⊆Q⊆A,则有DIS(P,A)≤DIS(Q,A).
证明由于P⊆Q⊆A,则
DIS(P)⊆DIS(Q) ⊆DIS(A),
即|DIS(P)|≤|DIS(Q)|≤|DIS(A)|.
又知

故有DIS(P,A)≤DIS(Q,A).
由定理3知,在信息系统中,对于P⊆A,若不断向属性集P中增加新的属性,P关于A的相对辨识度越接近于1,P的分辨能力越接近于A.
2.2 属性约简
定义8设S=(U,A)为一个信息系统,P⊆A. 对任意的属性a∈P,若令
SigP-{a}(a)=DIS(P,A)-DIS(P-{a},A)
则称SigP-{a}(a)为属性a在P中的重要度,其中DIS(P,A),DIS(P-{a},A)分别为属性集P,P-{a}关于A的相对辨识度.
由于P-{a}⊆P⊆A,有DIS(P-{a})⊆DIS(P)⊆DIS(A),由定义7知,SigP-{a}(a)=(|DIS(P)|- |DIS(P-{a})|)/|DIS(A)|,则知
0≤SigP-{a}(a)≤1.
SigP-{a}(a)度量的是从属性集P中删除属性a后引起关于A的相对辨识度的变化程度,SigP-{a}(a)越大,说明属性a对于P的重要性越大; 反之,属性a对于P的重要性越小. 特别地,当SigP-{a}(a)= 0时,知|DIS(P)|=|DIS(P-{a})|,即DIS(P)=DIS(P-{a}),由推论1知,U/P=U/(P-{a}),由定义3知属性a在P中是不必要的.
性质5设S=(U,A)为一个信息系统,对任意的属性a∈P,属性a在P中是必要的,当且仅当SigP-{a}(a)>0.
证明
(⟹)
由于P-{a}⊆P,由定理1知DIS(P-{a}) ⊆DIS(P),即|DIS(P-{a})|≤|DIS(P)|,假设属性a在P中是必要的,则由定义3知U/P≠U/(P-{a}),由推论1知DIS(P-{a})≠DIS(P),可得|DIS(P-{a})|< |DIS(P)|,SigP-{a}(a)=DIS(P,A)-DIS(P-{a},A)= (|DIS(P)|-|DIS(P-{a})|)/|DIS(A)|>0.
(⟸)
假设SigP-{a}(a)>0,即SigP-{a}(a)=(|DIS(P)|-|DIS(P-{a})|)/|DIS(A)|>0,则|DIS(P-{a})|< |DIS(P)|,由推论1知U/P≠U/(P-{a}),由定义3知属性a在P中是必要的.
综上所述,知属性a在P中是必要的,当且仅当SigP-{a}(a)>0.
性质6设S=(U,A)为一个信息系统,对任意的属性a∈A,核集Core(A)={a|SigA-{a}(a)>0}.
定义9设S=(U,A)为一个信息系统,P⊆A,对任意的a∈P均为P的必要属性,即SigP-{a}(a)>0,则称P为独立的,否则称P为依赖的.
定理4设S=(U,A)为一个信息系统,P⊆A,若DIS(P,A)=1且P是独立的,则称P为A的一个约简.
证明若DIS(P,A)=1,由定理2知DIS(P)=DIS(A),再由推论1知U/P=U/A.
因为P是独立的,则对任意的a∈P,都有SigP-{a}(a)=DIS(P,A)-DIS(P-{a},A)>0.
(1)
由于P-{a}⊆P⊆A,
则DIS(P-{a})⊆DIS(P)⊆DIS(A),
即|DIS(P-{a})|≤|DIS(P)|≤|DIS(A)|.
又由定义7知

DIS(P-{a},A)
(2)
由式(1)(2)知,|DIS(P)|>|DIS(P-{a})|,即DIS(P-{a})⊂DIS(P),故U/(P-{a})≠U/P,又U/P=U/A,所以U/(P-{a})≠U/A,由定义5知P是A的一个约简.
3 基于相对辨识度的属性约简算法
3.1 改进思想
定义8给出了从属性集中删除某个属性后的属性重要度度量方法,为了算法需要,下面给出另一种在属性集中添加某个属性后的属性重要度形式化定义.
定义10设S=(U,A)为一个信息系统,P⊆A. 对任意的属性a∈A-P,若令
SigP∪{a}(a)=DIS(P∪{a},A)-DIS(P,A),
则称SigP∪{a}(a)为属性a∈A-P相对于P的重要度,其中DIS(P∪{a},A),DIS(P,A)分别为属性集P∪{a},P关于A的相对辨识度.
显然,0≤SigP∪{a}(a)≤1.SigP∪{a}(a)度量的是在属性集P中添加属性a后引起关于A的相对辨识度的变化程度,SigP∪{a}(a)越大,说明属性a相对于P的重要性越大; 反之,属性a相对于P的重要性越小.
为了研究方便,结合性质5和定义10,下面重新给出不必要属性的等价定义.
定义11设S=(U,A,V,f)为一个信息系统,P⊂A. 对任意的属性a∈A-P,若SigP∪{a}(a)=0,则称属性a相对于P来说是不必要属性.
在以往启发式属性约简算法中,判断一个属性能否加入当前约简集Red时,出现重复计算不必要属性(a∈A-Red)重要度问题. 但是,若计算完所有属性重要度后,将那些不重要属性直接从候选属性集中删除并不影响约简结果,在一定程度上可降低算法复杂度.
为了验证上述说法的正确性,下面给出定理5予以解释.
定理5设S=(U,A)为一个信息系统,P⊆Q⊆A,a∈A-P. 若SigP∪{a}(a)=0,则SigQ∪{a}(a)=0.
证明
假设
SigP∪{a}(a)=DIS(P∪{a},A)-DIS(P,A)=0,
则DIS(P∪{a},A)=DIS(P,A).
(1)
由于P⊆P∪{a}⊆A,
则DIS(P)⊆DIS(P∪{a})⊆DIS(A),
即|DIS(P)|≤|DIS(P∪{a})|≤|DIS(A)|.
又由定义7知
DIS(P∪{a},A)=
(2)
由式(1)(2)可得|DIS(P∪{a})|=|DIS(P)|,即DIS(P∪{a})=DIS(P)
(3)
又知DIS(Q∪{a})=DIS(P∪(Q-P)∪{a})=DIS(P∪{a}∪(Q-P))=DIS(P∪{a})∪DIS(Q-P) =DIS(P)∪DIS(Q-P)=DIS(P∪(Q-P))=DIS(Q).
(4)
结合式(4),由定义7知
DIS(Q∪{a},A)=DIS(Q,A),
则由定义10知
SigQ∪{a}(a)=DIS(Q∪{a},A)-DIS(Q,A)=0.
由定理5知,在进行启发式属性约简时,若存在属性a∈A-P使得SigP∪{a}(a)=0,则知在接下来的约简过程中,属性a对于其他属性集的属性重要度均为0,因此在下一步约简前,可将其从候选属性集中删除,不再参与下一轮约简判断过程.
在基于相对辨识度的启发式属性约简中,由于可能需要多次计算DIS(P∪{a},A),为了降低算法复杂度,本文利用文献[3]中基数排序的思想计算辨识度DIS(P),其时间复杂度为O(|P||U|). 结合改进思想,下面给出基于相对辨识度的属性约简算法.
3.2 基于相对辨识度的属性约简算法
输入:一个信息系统S=(U,A).
输出:S的一个属性约简Red(A).
Step1:计算DIS(A),令Core(A)=φ,
Red(A)=φ;
Step2:对任意属性a∈A,按定义8逐一计算其属性重要度SigA-{a}(a),若SigA-{a}(a)>0,令Core(A)=Core(A)∪{a};
Step3:令Red(A)=Core(A);
Step4:若DIS(Red(A),A)=1,转Step6,否则转Step5;
Step5:对任意属性a∈A-Red(A),按定义10逐一计算其属性重要度SigRed(A)∪{a}(a),若
SigRed(A)∪{a}(a)=0,令A=A-{a}; 否则,选取属性a使其满足
SigRed(A)∪{a}(a)=max{SigRed(A)∪{a}(a),a∈A-Red(A)}(若满足该条件的属性不止一个,任选一个属性加入约简集),令
Red(A)=Red(A)∪{a},转Step4;
Step6:算法结束,输出Red(A).
3.3 算法复杂度分析
(1) 对于Step1,计算DIS(A)的时间复杂度为O(|A||U|).
(2) 对于Step2,计算SigA-{a}(a)的时间复杂度为|A|×O((|A|-1)|U|).
(3) 对于Step3~4,由于Red(A)=Core(A),计算DIS(Red(A),A)=1的时间复杂度为
O(Core(A)|U|).
(4) 对于Step5,最坏情况下每个属性都是A的必要属性,在此情况下,对任意属性a∈A-Red(A)计算其属性重要度SigRed(A)∪{a}(a)的时间复杂度为O((|A-Red(A)|+(|A-Red(A)|-1)+…+1)|U|)=O(|A|2|U|),最优情况下仅需计算一轮属性重要度,得到一个属性重要度大于0的属性,其余属性重要度均为0,在此情况下,时间复杂度为O(|U|).
综合(1)~(4)所述,该算法的时间复杂度为
O(|A||U|)+|A|·O((|A|-1)|U|)+
O(Core(A)|U|)+O(|A|2|U|)=O(|A|2|U|).
与文献[6]算法时间复杂度O(|U||A|2|A|log|U|)相比,本文提出的算法最坏情况下是O(|A|2|U|),因此本文算法要优于文献[6]中的算法,并且本文所提算法能利用从候选属性集中不断删除不必要属性来解决不必要属性属的性重要度重复计算的问题,从而提高了属性约简的效率.
4 实例分析
为了验证3.2节所提算法的有效性与可行性,下面对表1中的信息系统S进行分析,其中U={x1,x2,x3,x4,x5,x6,x7,x8,x9},属性集A={a1,a2,a3,a4,a5,a6}.
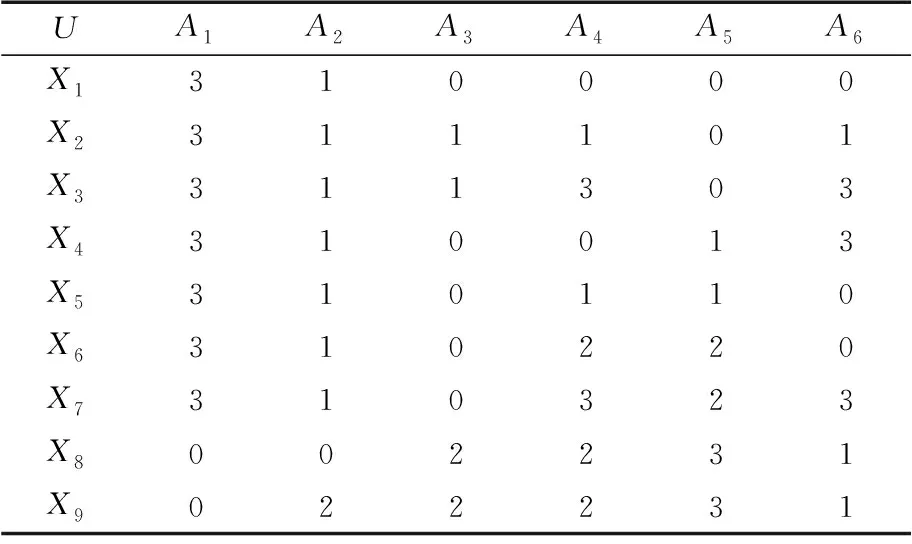
表1 信息系统S
(1) 令Core(A)=φ,Red(A)=φ,计算DIS(A),得|DIS(A)|=72.
(2) 对任意属性a∈A,按定义8逐一计算其属性重要度SigA-{a}(a),可得SigA-{a1}(a1)=SigA-{a3}(a3)=SigA-{a4}(a4)=SigA-{a5}(a5)=SigA-{a6}(a6)=0,SigA-{a2}(a2)=1-70/72=2/72>0,令Core(A)=φ∪{a2}={a2}.
(3) 令Red(A)=Core(A)={a2},
DIS(Red(A),A)=DIS({a2},A)=30/72≠1.
(4) 对任意属性a∈A-Red(A),按定义10逐一计算其属性重要度SigRed(A)∪{a}(a).
Sig{a2}∪{a1}(a1)= 0,Sig{a2}∪{a3}(a3)=20/72,
Sig{a2}∪{a4}(a4)=66/72-30/72=36/72,
Sig{a2}∪{a5}(a5)=62/72-30/72=32/72,
Sig{a2}∪{a6}(a6)=60/72-30/72=30/72.
由于Sig{a2}∪{a1}(a1)=0,令
A=A-{a1}={a2,a3,a4,a5,a6},又知Sig{a2}∪{a4}(a4)=max{Sig{a2}∪{a}(a),a∈A-{a2}},故令Red(A)=Red(A)∪{a4}={a2}∪{a4}={a2,a4}.
(5)DIS(Red(A),A)=DIS({a2,a4},A)=66/72≠1,对任意属性a∈A-Red(A),重新计算SigRed(A)∪{a}(a).
Sig{a2, a4}∪{a3}(a3)=70/72-66/72=4/72,Sig{a2, a4}∪{a5}(a5)=Sig{a2, a4}∪{a6}(a1)=72/72-66/72=6/72.
由于Sig{a2, a4}∪{a5}(a5)=Sig{a2, a4}∪{a6}(a6)>Sig{a2, a4}∪{a3}(a3),故任选属性a5加入Red(A)中,即Red(A)=Red(A)∪{a5}={a2,a4}∪{a5}={a2,a4,a5}.
(6)DIS(Red(A),A)=DIS({a2,a4,a5},A)=72/72= 1,算法结束,输出信息系统S的一个相对约简{a2,a4,a5}. 同理,可得{a2,a4,a6}也为该信息系统S的一个相对约简.
利用本文算法与利用文献[4]中算法计算得到的约简是一致的,说明该算法是可行的. 另外,由于该算法在执行时在不断地删除属性重要度为0的属性,避免了不重要属性的重复计算,降低了算法复杂度,说明该算法是高效的.
5 结语
以可辨识关系为出发点,本文定义了相对辨识度,把它用于刻画不同属性集之间分类能力的相似程度,据此提出了改进的信息系统属性约简算法. 为了进一步提高约简效率,在进行启发式约简时,该算法通过不断从候选属性集中删除不必要属性,有效地解决了不必要属性的属性重要度重复计算的问题.
