面向主题的无监督文本摘要生成方法
2021-11-28蒋杰
蒋杰


摘要:随着人工智能的迅速发展,传统的文本摘要技术也从抽取式摘要向生成式摘要发展。当源文档中存在着多个主题的内容时,现有的大多数生成式文本摘要方法会尽全面地对多主题内容进行概括和总结,而对其中包含某个主题的内容可能无法进行细致描述。针对这一问题,本文提出了一个面向主题信息的无监督文本摘要生成方法。在给定目标主题信息的情况下,在解码器中利用注意力机制将目标主题信息与文本本身的主题信息进行信息融合,从而使得包含了目标主题的文本得到较大的注意力权重,以此生成与目标主题相关的文本摘要。在大规模英文文本数据集Yelp上的实验结果验证了所提方法的有效性和先进性。
关键词:自然语言处理;序列到序列模型;无监督学习;生成式摘要;主题信息;注意力机制
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2021)28-0127-04
开放科学(资源服务)标识码(OSID):
Topic-oriented Unsupervised Text Summarization Generation Method
JIANG Jie
(Guangdong University of Technology, Guangzhou 510006, China)
Abstract: With the rapid development of artificial intelligence, traditional text summarization techniques have also evolved from extractive summaries to generative summaries. When there are multiple topics in the source document, most of the existing generative text summaries will summarize and summarize the content of multiple topics in a comprehensive manner, and the content of a certain topic may not be able to be described in detail. In response to this problem, this paper proposes a topic-oriented unsupervised text summary generation method. Given the target topic information, in the decoder, the attention machanism is used to fuse the target topic information with the topic information of the text itself, so that the text which contains the target topic information gets a larger attention weight, so as to generate a text summary related to the target topic. The experimental results on the large-scale English text data set Yelp verify the effectiveness and advancement of the proposed method.
Key words: natural language processing( NLP );sequence-to-sequence( seq2seq ) model;unsupervised learning;abstractive summarization;topic information;attention mechanism
1 引言
隨着互联网产生的文本数据越来越多,文本信息过载问题日益严重,对各类文本进行一个“降 维”处理显得非常必要,文本摘要便是其中一个重要的手段。文本摘要技术是指通过各种技术,对文本或者是文本集合,抽取、总结或是精炼其中的要点信息,用以概括和展示原始文本(集合)的主要内容或者大意。
当前,文本摘要按照输入类型可分为单文档摘要和多文档摘要。单文档摘要是指从给定的一个文档中生成摘要,多文档摘要则是从给定的一组文档中生成摘要。按照输出类型可分为抽取式摘要和生成式摘要。抽取式摘要是指从源文档中抽取关键句和关键词组成摘要,摘要全部来源于原文,如使用Lead技术[1]来产生摘要。而生成式摘要则是根据原文的内容,允许生成新的词语、短语来组成摘要。生成式文本摘要主要依靠深度神经网络结构实现,来自GoogleBrain团队就较早地提出的序列到序列[2](Sequence-to-Sequence,seq2eq)模型,开启了自然语言处理(Natural Language Processing,NLP)中端到端网络的火热研究。
近几年来,一些基于深度学习的主题文本生成方法也取得了一定的成果。Feng等人[3]通过给定主题词集合,利用长短期记忆(Long Short-Term Memory)[4]网络进行训练,从而产生一段包含这些主题词的文本,与常规的自然语言生成方法[5-6]相比,在主题相关性和主题完整性上得到了一定的提高。来自Adobe的Krishna等人[7]则是构造一个包含多个主题的文本数据集,针对同一文本,输入不同的主题信息,从而生成相应主题的文本摘要。也有学者通过对数据文本进行一些预处理,如使用TextRank技术[8],选出若干与当前文本相关的主题词,将主题词与文本作为输入,利用注意力机制将主题词与输入文本进行信息融合,从而产生一段与这些主题词内容相关的文本。
虽然以上这些模型的主题信息的表示形式各有不同,且主题信息的使用方法也有所差异,但主题信息使用的意义就是为了使模型能够生成与主题信息相关的文本摘要。鉴于此,本文提出一个面向主题的无监督文本摘要生成方法。先给定目标主题,然后在解码器中利用注意力机制将目标主题信息与文本主题信息进行融合,因此不同主题的文本得到不同的注意力权重,拥有目标主题的文本则得到较大的注意力权重,从而生成与目标主题相关的文本摘要。
2 面向主题的文本摘要生成模型
在自然语言处理中,大多数的生成式文本摘要模型都是基于seq2seq模型的,seq2seq本质上是一个编码器-解码器模型。在seq2seq模型中,普遍使用循环神经网络(RNN)[9]作为模型的编码器和解码器。编码器RNN通过将长度为m的序列x={x1 , x2 ,··· , xm}编码,得到中间序列H={h1 , h2 , ··· , hm},解码器RNN将中间序列h进行解码,得到生成结果y={y1 , y2 , ··· , yn}。
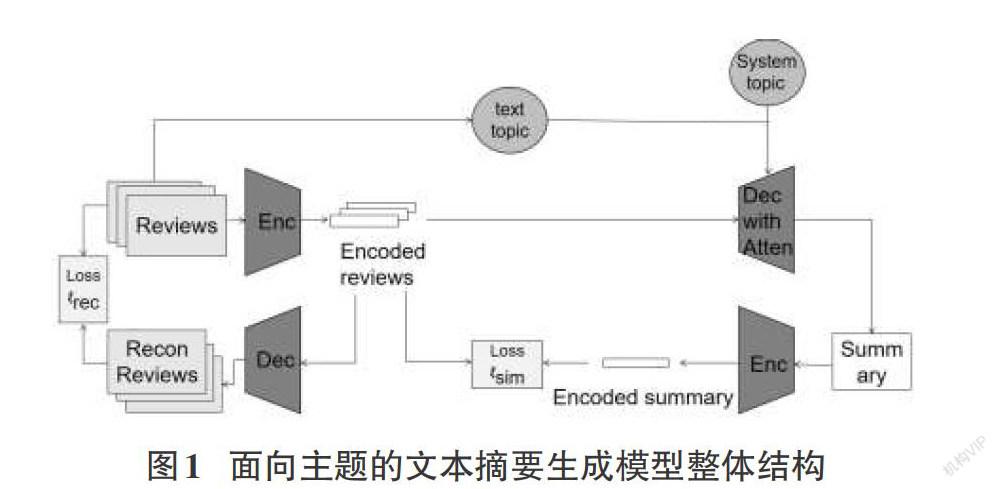
为了规避标准RNN无法长距离记忆的问题,一般会使用RNN的两种改进的网络结构,LSTM网络和GRU[10],本研究提出的模型在编码和解码的阶段都采用了LSTM网络。本研究提出的模型如图1所示,主要包含了两个部分,第一个部分是一个Auto Encoder[11]模块,Auto Encoder也叫做自编码器,Auto Encoder包含两个过程:encode和decode。给定k条评论文本作为输入x={x1 , x2 , ··· , xk},在编码过程中,通过编码器g将输入样本映射到特征空间z,z= g(x)。z=[h,c],h和c分别是编码器中的LSTM在对输入文本x中的每个token处理后输出的hidden state和cell state的最后一层。在解码过程中,通过解码器f将特征空间z映射回原始空间得到重构样本x'={x1', x2',··· , xk'},p(x'|z)= f(z)。优化目标则是通过最小化重构误差来同时优化encoder和decoder,从而学习得到针对文本输入x的抽象特征表示z。在本模型中,使用的是标准的交叉熵误差作为重构误差。
[?rec({x1,x2...,xk},g,f) =j=1k?cross_entropy(xj,f(g(xj)))] (1)
第二部分则是引入注意力机制的摘要模块。在摘要模块中,将特征空间z引入到注意力机制中,结合当前系统主题与源文档主题得到的主题相似度,得到最终注意力权重α。再将z与α结合,由此得到新的上下文信息C,最终将C输入到解码器f中,得到摘要y。将产生的摘要y输入到编码器g中,得到z',z'= g(y),z'=[h',c']。在本模块中,优化目标是最小化z和z'中h的误差,计算z和z'中h的误差则是使用余弦距离来进行计算。
[C=j=1khjαj] (2)
[y~fC] (3)
[?sim({x1,x2,…,xk},g,f)=j=1kαjdcos (hj,h')] (4)
本文模型的整体架构如图1所示。其中AutoEncoder模块和摘要模块中的编码器encoder是参数共享的,解码器decoder也是参数共享的。在本模型中,总的损失函数[?model =?rec+?sim]。
3 面向主题的文本摘要生成模型的构建
3.1 主題标记及向量表示
在数据预处理过程中,人工对实验数据集中的文本信息进行主题标记,按照服务、环境、价格三个主题给文本进行标记,并以一个三维向量进行表示v={v1,v2,v3},若文本中包含了某个主题,则对应位置的值为1,否则为0。此外模型会随机生成目标主题V={V1,V2,V3},以一个one-hot[12]形式表示,分别对应服务、环境、价格这三个主题,其中的有效位代表模型需要生成与有效位所对应的主题相关的摘要。
3.2 编码器
编码器encoder采用的是单层单向的LSTM网络来对输入文本进行编码,从而将输入文本映射到特征空间。LSTM的定义如下:
[it=σ(Wi[ht-1,xt])] (5)
[ut=σ(Wu[ht-1,xt])] (6)
[c~t=tanh(Wc[ht-1,xt])] (7)
[ot=σ(Wo[ht-1,xt])] (8)
其中Wi、Wu、Wc、Wo是權重矩阵。
[ct=ut*ct-1+it*c~t] (9)
[ht=ot*tanh(ct)] (10)
其中h为短记忆,c为长记忆。
在编码器中,LSTM网络首先将初始状态h0,c0设置为零向量。然后将输入文本的词嵌入向量从左至右的读入,最终得到一个特征向量z,z=[h,c]。
3.3 解码器
本文使用由注意力机制所计算出的注意力并结合LSTM网络共同解码并生成摘要。解码过程可分为两个部分,第一个部分是利用注意力机制对z中的h进行注意力观察,并结合模型主题与输入文本之间的主题相似度,从而有针对性地生成一组对应的注意力权重α,将生成的注意力权重α与h结合,从而产生一个新的上下文信息C。第二个部分则是在每个解码时间步t时刻,LSTM网络结合前一个词向量wt-1、上一个时间步的解码状态[hdt-1]以及[cdt-1]计算新的解码状态hd t和cd t,并产生yt。具体实现过程如下:
[βi=1,Vi?vi-1, Vi?vi] (11)
其中V为系统随机产生的one-hot向量,为目标主题。v = {v1,v2,...,vk},为输入文本所体现的主题向量。β = {β1,β1,...,βk}为模型主题与输入文本之间的主题相似度。
构成上下文信息C的注意力权重α的计算结果如下:
[αi=exp(η(hi,wd)βi)i=1kexp(η(hi,wd)βi)] (12)
[C=i=1kαihi] (13)
[hdt=C (t=0)] (14)
[cdt=i=1kαici (t=0)] (15)
得到新的上下文信息Ct后,结合前一个词yt-1,以及上一个时间步的解码状态hd t-1以及cd t-1,从而获得当前输出状态st,以及当前解码状态hd t和cd t。
[odt,hdt,cdt=LSTM(yt-1,hdt-1,cdt-1)] (16)
[st=maxot,jj=1,2,...,T] (17)
[p(yty1,y2,...,yt-1)=softmax(Wsst)] (18)
4 实验结果与分析
4.1 实验数据集
本文实验所使用的数据集为YELP数据集[13],该数据集包含两个部分。
1) 第一个部分是Businesses。它包含了YELP数据集中的商户信息。
2) 第二个部分是Reviews。它包含了YELP数据集中顾客对Businesses中商户的评论信息,主要包含了文本评论和情感打分(1~5分)。
3) 本文实验先对Businesses中商户类型进行了筛选,要求商户类别中必须包含Restaurants标签,再对通过筛选后的商户所对应的Reviews中的评论信息进行筛选,首先将评论信息中商户出现频次超过90%的商户排除在外,这样做的目的是为了避免数据集中出现某个商户的评论信息过多,从而导致数据不均衡。并要求每个商户所对应的评论信息的条数大于等于50条,且每条评论信息中的文本评论长度小于等于150个单词。
最终训练集、验证集、测试集分别对应有27560、3327、3321条文本评论信息,其中与“服务”主题有关的文本评论有15002条,与“环境”主题有关的文本评论有9234条,与“价格”主题有关的文本评论有7785条。
4.2 评价标准
由于本文实验所使用的数据集为YELP数据集,且该数据集无Ground truth,所以采用以下三个指标作为评价标准。
1) Word Overlap Score
在文本摘要领域中,对于摘要常用的评价工具为ROUGE[13],其通过计算标准摘要和实验结果所生成的摘要计算重叠的词汇来衡量摘要生成的质量。由于本数据集无标准摘要,所以使用输入文本x中每条文本与摘要计算一次ROUGE score,并将ROUGE score加權求和来表示摘要与输入文本的词重叠比例。在本实验中,计算ROUGE score使用ROUGE-1。
[WO=1Ni=1N[j=1kα(i)jROUGE(y(i),x(i)j)]] (19)
其中N为一次训练中的数据块的个数,x(i)j为第i个数据块中第j条输入文本,y(i)为第i个数据块所生成的文本摘要,α(i)j为解码器在第i个数据块中注意力机制所计算出的第j个注意力权重。
2) Sentiment accuracy
一条有用的摘要不仅要在内容上体现主题相关性,还要在情感上保持着一致性。由于一条评论信息中可能包含多个主题,所以当出现多主题这种情况时,可以认为评论信息的评分是顾客折中后给出的评分,即可以使用该评分来代表评论信息中关于某个主题的情感分数。
[1N[i=1N(CLF(y(i))=round(j=1kα(i)jr(x(i)j)))]] (20)
其中CLF为评分器,[r(x(i)j)]为第i个数据块中第j条输入文本的评分。
3) Negative Log-Likelihood(NLL)
为了评价实验所生成的文本摘要是否流畅通顺,所以根据本实验模型预训练了一个语言模型,由训练好的语言模型来计算文本摘要的负对数似然的值来对文本进行评判。
4.3 实验设置
在本实验的数据预处理过程中,使用了一个开源的单词分词器[14]对文本进行分词,再使用subword[15]模型,最终生成一个包含了32000个单词的词典。在实验中使用subword模型不仅可以减小词表的大小,而且还可以解决seq2seq模型中经常出现的稀有词问题(UNK问题)。
本实验使用的语言是Pytorch,在本实验中语言模型,编码器,解码器均使用了512维的LSTM,256维度的词向量。本实验采用了Adam[16]模型优化器,β1=0.9,β2=0.99。对于语言模型,学习率设定为0.001,对于面向主题的文本摘要生成模型,学习率设定为0.0005,对于评分器,学习率设定为0.0001。在对语言模型和面向主题的文本摘要生成模型的训练中,拟定每次输入模型的文本数k=30,在对评分器的训练中,拟定每次输入模型的文本数为1。
语言模型的创建是为了评判摘要是否流畅通顺,其本质是一个LSTM网络。拟定模型的输入项为30条文本评论以及它们的结束定界符的组合,初始状态h0和c0都为零向量。评分器是类似于RUSH[17]等人提到的多通道文本卷积神经网络,它具有3、4、5三个不同宽度的过滤器,每个过滤器具有128个特征图以及0.5的淘汰率。
4.4 对比方法
本文选取了三个基准模型和本文提出的模型进行比较。
Opinosis[18]是一个基于图结构的摘要算法,旨在利用高度冗余的文本信息生成简短的文本摘要,虽然该算法是生成式摘要算法,但是它只能通过从输入文本中选取单词,从而组成摘要。
VAE[19]是一个变分自编码器,通过平均从输入文本采样到的隐变量Z,从而生成一条文本摘要。
MeanSum[20]是一个基于序列到序列的无监督的文本摘要模型。该模型通过将特征向量z平均后送入到解码器中,从而产生一条文本摘要。
4.5 实验结果分析
由表1结果可见:
1)Opinosis在词重叠和情感准确度这两方面较其他三个方法还是略有不足,说明在生成式文本摘要这一任务中,采用深度学习的方法更加有效。
2)本文方法相较MeanSum而言,不仅引入了主题向量表示的概念及使用,而且还在解码端使用了注意力机制,不仅弥补了MeanSum在多文档摘要生成任务中的情感准确度较低的问题,而且在内容上,也更能体现主题相关性。
3)本文方法及其对照方法实际生成的文本摘要实例如表2所示。Opinosis通过抽取文本中的单词来生成文本摘要,VAE则更偏向于利用文本中大量的冗余信息来生成文本摘要,MeanSum通过平均输入文本信息生成文本摘要,但以上三种方法都不能合理利用文本信息中的主题信息,本文方法通过注意力機制使得拥有目标主题的文本拥有更大的注意力权重,以此引导解码器生成与目标主题内容相关的文本摘要。
5 结论
本文提出了一个面向主题的文本摘要生成算法,该算法不仅引入了主题信息的向量表示及其应用,还将对输出向量的注意力与主题向量进行了信息融合。在YELP数据集上实验所得到的实验结果证实表明,该算法生成的文本摘要在内容上可以更好地体现主题,且更能准确地反映输入文本中关于主题的情感。而且在未来还有很多等待发掘的工作,例如将本算法应用在中文的文本摘要生成上,或者是尝试挖掘更深层次的主题信息的运用方法。
参考文献:
[1] Rossiello G,Basile P,Semeraro G.Centroid-based text summarization through compositionality of word embeddings[C]//Proceedings of the MultiLing 2017 Workshop on Summarization and Summary Evaluation Across Source Types and Genres.Valencia,Spain.Stroudsburg,PA,USA:Association for Computational Linguistics,2017:12-21.
[2] 冯读娟,杨璐,严建峰.基于双编码器结构的文本自动摘要研究[J].计算机工程,2020,46(6):60-64.
[3] Feng X, Liu M, Liu J, et al. Topic-to-Essay Generation with Neural Networks[C]//IJCAI. 2018: 4078-4084.
[4] Hochreiter S,Schmidhuber J.Long short-term memory[J].Neural Computation,1997,9(8):1735-1780.
[5] Guu K,Hashimoto T B,Oren Y,et al.Generating sentences by editing prototypes[J].Transactions of the Association for Computational Linguistics,2018,6:437-450.
[6] Liu L Q,Lu Y,Yang M,et al.Generative adversarial network for abstractive text summarization[EB/OL].2017
[7] Krishna K,Srinivasan B V.Generating topic-oriented summaries using neural attention[C]//Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,Volume 1 (Long Papers).New Orleans,Louisiana.Stroudsburg,PA,USA:Association for Computational Linguistics,2018:1697-1705.
[8] Mihalcea R , Tarau P . TextRank: Bringing Order into Texts[C]//Proc Conference on Empirical Methods in Natural Language Processing,2004.
[9] Graves A.Generating sequences with recurrent neural networks[EB/OL].2013
[10] Fu R,Zhang Z,Li L.Using LSTM and GRU neural network methods for traffic flow prediction[C]//2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC).November 11-13,2016,Wuhan,China.IEEE,2016:324-328.
[11] Hinton G E,Krizhevsky A,Wang S D.Transforming auto-encoders[M]//Lecture Notes in Computer Science.Berlin,Heidelberg:Springer Berlin Heidelberg,2011:44-51.
(下转第148页)
(上接第130页)
[12] Lin C Y,Hovy E.Automatic evaluation of summaries using N-gram co-occurrence statistics[C]//Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology - NAACL '03.May 27-June 1,2003.Edmonton,Canada.Morristown,NJ,USA:Association for Computational Linguistics,2003:150-157.
[13] Asghar N. Yelp dataset challenge: Review rating prediction[J]. arXiv preprint arXiv:1605.05362, 2016.
[14] Wu Y H,Schuster M,Chen Z F.et al.Google's neural machine translation system:bridging the gap between human and machine translation[EB/OL].2016
[15] Radev D R,Jing H Y,Sty? M,et al.Centroid-based summarization of multiple documents[J].Information Processing & Management,2004,40(6):919-938.
[16] Han Z D.Dyna:a method of momentum for stochastic optimization[EB/OL].2018:arXiv:1805.04933[cs.LG].https://arxiv.org/abs/1805.04933.
[17] Rush A M,Chopra S,Weston J.A neural attention model for abstractive sentence summarization[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing.Lisbon,Portugal.Stroudsburg,PA,USA:Association for Computational Linguistics,2015.
[18] Ganesan K, Zhai C X, Han J. Opinosis: A graph based approach to abstractive summarization of highly redundant opinions[J]. 2010.
[19] Bowman S R,Vilnis L,Vinyals O,et al.Generating sentences from a continuous space[C]//Proceedings of The 20th SIGNLL Conference on Computational Natural Language Learning.Berlin,Germany.Stroudsburg,PA,USA:Association for Computational Linguistics,2016.
[20] Chu E,Liu P J.MeanSum:a neural model for unsupervised multi-document abstractive summarization[EB/OL].2018:arXiv:1810.05739[cs.CL].https://arxiv.org/abs/1810.05739.
【通聯编辑:唐一东】
