基于改进概率霍夫变换的表格字符定位算法
2021-11-28陈其浩
张 倩,陈其浩,杨 硕
(山东科技大学测绘与空间信息学院,山东青岛 266590)
0 引言
纸质档案数字化对历史文档数据的保存和综合分析至关重要,表格字符定位技术是文档分析与字符识别领域的重要分支[1]。从表格框线中准确定位字符区域是字符分割的关键,故重点在于表格线的检测问题[2],因此高效准确地定位到表格信息至关重要。
早期的表格识别技术主要是基于启发式规则对表格进行识别,Chandran 等[3]根据水平或垂直方向的投影,提出以树的形式表示表格结构的表格提取系统,此方法能够快速完成对表格的识别,但不能生成表格的逻辑结构;Yildlz等[4]提出的Pdf2table 方法通过候选表格的绝对位置检测和合并文本段提取表格信息,但无法准确定位不规则表格;Koci 等[5]利用遗传算法将表格视为子图识别出来,基于启发式规则的表格识别方法设计较为复杂,准确度及适应性较差;Fan 等[6]利用表格模板进行识别的表格识别系统,将表格识别问题转为矩阵匹配问题,识别效率较高,但对表格模型的表达能力要求较高。针对识别算法,张艳等[7]用链码法对票据表格框线中的信息进行提取,但是该方法对于噪声较大的情况不具有鲁棒性;张国锋等[8]提出基于梯度霍夫变换的藏文手写采样表格检测,该方法由于表格线被多次检测,造成部分表格线重叠;张国福等[9]通过改进概率霍夫变换算法提取直线特征,从而实现对电梯门状态的实时监测,在时间和准确率上均有较大提升;邱东等[10]通过改进概率霍夫变换算法,添加约束条件加以改进,拟合出正确车道线,以实现对车道线的快速检测。
部分低质量文档图像中存在表格线变形、不清晰等情况,导致表格字符定位的鲁棒性较差[11]。针对表格字符定位技术中存在字符定位适应性较差、识别方法较复杂以及对表格字符信息的提取不完全等问题,本文结合霍夫变换算法提取直线的思想,提出一种基于改进概率霍夫变换的表格字符提取算法。该算法首先通过四邻域灰度差异阈值法对图像进行二值化处理,再对传统概率霍夫变换进行改进,实现表格线的精确检测,进而确定字符所在表格框的位置,最后基于投影法实现表格字符的精确定位。针对低质量表格数据图像,本文算法可实现表格内字符的精确定位。
1 图像预处理
低质量表格图像的分析与识别首先需要对图像进行预处理,二值化处理是图像预处理的关键技术,直接影响字符定位精度。目前,主要的二值化方法有全局阈值法和局部阈值法[12],基于全局固定阈值法的最大类间方差法(OTSU 算法)[13]可以快速有效地确定类间分割阈值,但对于目标灰度范围分布较大的图像,存在直线断裂现象,分割质量没有保障。基于局部阈值法的Sauvola 算法[14]可以进行局部阈值多目标分割,在图像光照不均匀的情况下,具有较好的分割效果,但存在运算速度慢、伪影现象,严重影响到字符的精确定位与分割。因此,本文针对低质量表格图像提出了一种四邻域灰度差异阈值法二值化算法。
图像进行去噪处理后,目标区域与背景区域灰度差异较大,因此本文提出一种基于直线灰度差异特征的二值化算法。该算法的主要思想是:根据图像的灰度差异,设置固定的阈值及窗口半径,对图像进行滑窗处理,选取四邻域方向半径为R 的像素点,将其灰度值与中心像素灰度值作差,并与阈值进行比较,以确定前景和背景。具体步骤如下:①取窗口中心像素的灰度值P;②对表格中的字符进行投影,根据每行白色像素的个数获取阈值,取阈值的平均值T;③根据阈值T,取中心像素四邻域方向上半径为R的像素灰度值P1、P2、P3、P4,本文R 取值为3;④计算4 个像素点与中心像素灰度值的差值di;⑤通过式(1)对整张表格图像进行逐像素处理,得到最终二值结果。
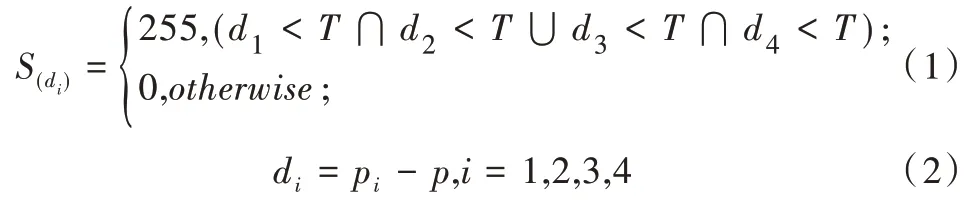
di的计算示意图如图1 所示。
本文将传统二值化算法与四邻域灰度差异阈值法进行实验对比。各类算法的二值化输出结果如图2 所示,其中图2(a)为低质量的表格图像,图2(b)、图2(c)分别为OT⁃SU 算法及Sauvola 算法得到的二值图像,在两种算法二值结果图中,直线断裂现象较为严重,存在字符不连续现象,图2(d)为本文四邻域灰度差异阈值法得到的二值图像。从直观视觉角度看,该算法对表格线的识别效果较好,基本保留了图像的表格线及字符信息,取得了较好的二值效果。

Fig.1 Calculation diagram of di图1 di计算示意图

Fig.2 Comparison of binary results图2 二值结果对比
2 基于改进概率霍夫变换的表格线检测
表格线的检测精度直接影响到后期字符定位结果[15]。由于概率霍夫变换算法中霍夫空间的投票方式会造成直线的错误检测,本文采用改进概率霍夫变换算法检测表格线,在直线融合及去除误提直线两个方面添加约束条件,以获得较准确的表格线。算法原理如图3 所示。
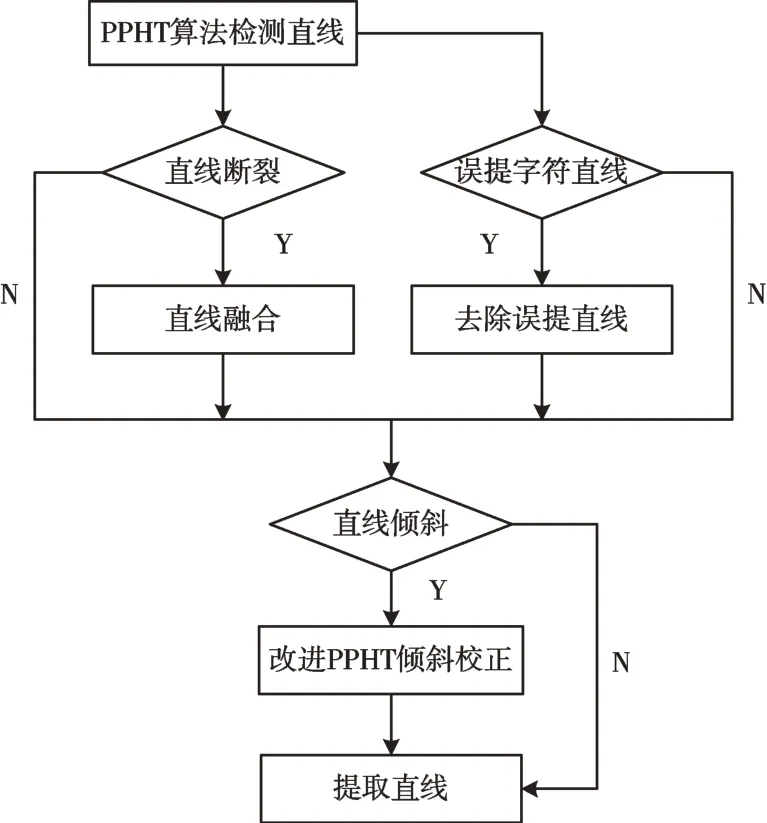
Fig.3 Algorithm flow图3 算法流程
2.1 霍夫变换检测直线原理
标准霍夫变换检测直线[16-17]的基本原理是:利用点和线在不同参数空间中的对偶性,将图像空间中的直线转换为参数空间中的点,进而对参数空间中的点进行投票,根据设定的阈值确定曲线,从而将检测任意形状的问题转化为统计峰值问题。
将笛卡尔坐标系下的直线映射到参数空间中,直线上所有的点在参数空间中都有一条直线与之对应。如图4(a)所示,笛卡尔坐标系下存在直线y=kx+b,直线上存在两点(x1,y1)(x2,y2),在参数坐标系中有两条直线与之对应,且两直线相交于一点(k0,b0);如图4(b)所示,将直线映射到极坐标系中,直线上的点在极坐标系中都有一条曲线与之对应,曲线相交于一点(ρ,θ)。通过统计参数空间中交点的个数确定直线位置,达到检测直线的目的。
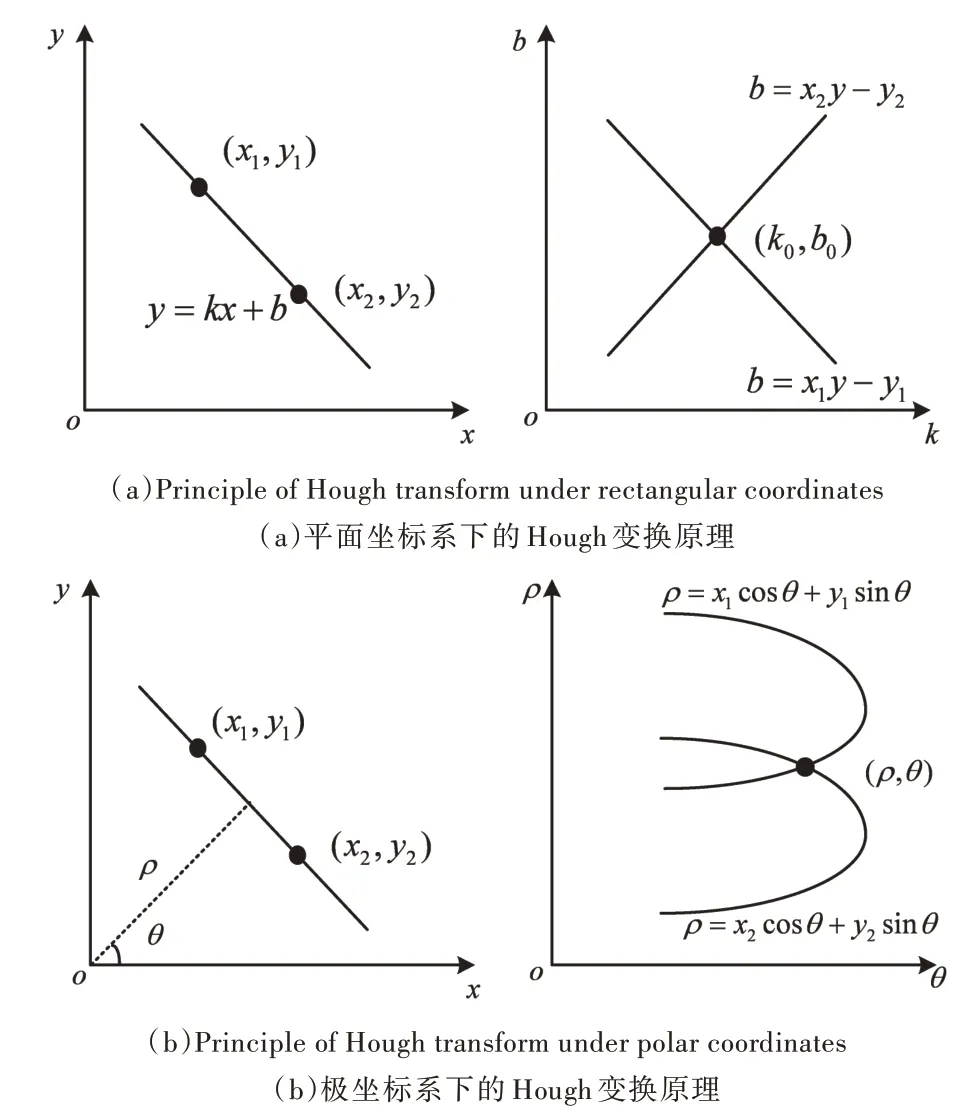
Fig.4 Principle of Hough transform图4 霍夫变换原理
2.2 概率霍夫变换直线检测
经典的霍夫变换算法检测直线时,时间和空间复杂度较高,在直线检测过程中只能确定直线方向,并且检测直线时进行了离散化处理,检测精度受参数离散间隔制约,严重影响到字符的精确定位。因此,本文采用概率霍夫变换算法(Progressive Probabilistic Hough Transform,PPHT)[18]提取表格线。PPHT 算法是在标准霍夫变换的基础上加以改进的直线提取算法,此算法无需对边缘像素点逐一进行检测,而是随机选取少量边缘点转换到参数空间下进行小范围的投票,从而提高运算效率。PPHT 算法检测直线的具体步骤如下:①将直线检测获取的边缘图像的前景点放入待选边缘点集P;②将参数空间分为n 个小区间,对应n个二维累加器acc(ρ,θ),其中ρ 为直线到原点的距离,θ 为直线的角度,ρ 和θ 的初值均为0;③随机从待处理边缘点集P中选取某一像素点,将此点投射在霍夫空间中,计算该像素点在霍夫空间中各θ 值下对应的ρ 值,并将对应的累加器acc(ρ,θ)投票数加1;④从点集中删除已处理过的点并更新累加器;⑤更新后累加器的值与阈值比较,若大于阈值,则完成一次直线拟合,删除直线上所有的点,若不满足返回步骤③;⑥根据线段的长度及方向的线段排序,得到表格线位置信息。
2.3 概率霍夫变换改进
针对表格图像,概率霍夫变换算法能确定直线的方向信息,且能够检测出图像中直线的两个端点,精确定位图像中的直线[19]。但由于概率霍夫变换算法投票机制的局限性以及噪声干扰,检测出的直线会出现断裂现象,且检测直线时对与直线共存的非直线结构不敏感,会造成字符上直线特征误检。为获得较准确的表格线,本文进行以下改进:
(1)直线融合。概率霍夫变换算法通过检测直线确定直线方向,却丢失了线段的长度信息,本文根据PPHT 算法检测出来的直线,筛选出线段的两个端点,以直线长度和相邻直线间的距离为约束条件,在一定的范围内进行直线融合,恢复表格直线的长度信息,修补缺失的表格线。如图5 所示,其中图5(a)为PPHT 算法检测出来的表格线,图5(b)为直线融合后的表格线。
Fig.5 Straight line fusion图5 直线融合
(2)误提字符干扰线去除。由于PPHT 算法提取直线是根据直线特征而进行,部分表格图像中字符之间间隔较小,具有直线特征的字符会连接在一起,粘连字符易被识别成直线,造成直线误提现象。字符上误检的直线,竖直方向上存在一定宽度的字符,因此根据直线周围像素特征去除误提直线。如图6 所示,其中图6(a)为PPHT 算法误提字符直线图,具有直线特征的字符被识别成直线,图6(b)为误提直线去除后的结果图,可有效去除误提字符干扰线。

Fig.6 Removing interference line图6 去除误提直线
3 表格校正
对表格图像进行光学扫描时,由于硬件设备人为摆放等原因,表格会存在一定程度上的倾斜,造成图像像素点的定位偏差[20],从而严重影响后续的表格字符分割。表格图像中表格均由水平方向和竖直方向的线段构成,表格线与表格图像具有大致相同的倾角,根据表格线的倾角即可得到表格的倾角。为降低倾斜图像在字符识别过程中产生的影响,本文通过改进的概率霍夫变换算法对图像进行倾斜校正[21]。
表格校正算法的主要思想是通过改进的概率霍夫变换算法检测出的直线倾角确定图像的倾角。在笛卡尔坐标系中,过(x1,y1)(x2,y2)的直线y=kx+b在参数空间中所对应的坐标系可以表示为ρ=xcosθ+ysinθ。利用式(3)可得到直线的倾斜角度。
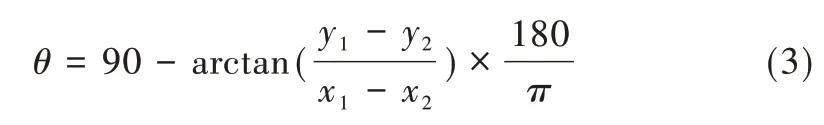
通过改进的概率霍夫变换算法获取表格线信息,分别得到横线和竖线的倾斜角度。
(1)以横线为例,通过改进的概率霍夫变换算法得到横线的倾斜角度θ1、θ2、θ3…θn,利用式(4)对所有横线的倾斜角度取平均值θ。
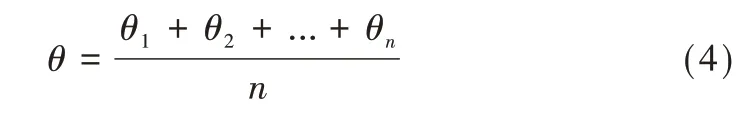
(2)对图像旋转θ 度,得到校正后的图像。
如图7 所示,其中图7(a)为原始图像,图7(b)为改进的概率霍夫变换算法校正后的图像。实验结果表明,该方法能从复杂图像中实现表格线倾斜校正。
4 字符定位
通过前期对表格图像的预处理、对表格线的提取以及对表格图像的倾斜校正,可精确定位表格线。为了有效地提取表格字符,还需要对表格字符进行粗定位和精确定位。
4.1 粗定位
根据表格的横线与竖线的交点位置信息确定字符所在矩形框的4 个交点坐标,即可粗略定位到表格字符的位置,如图8 所示。
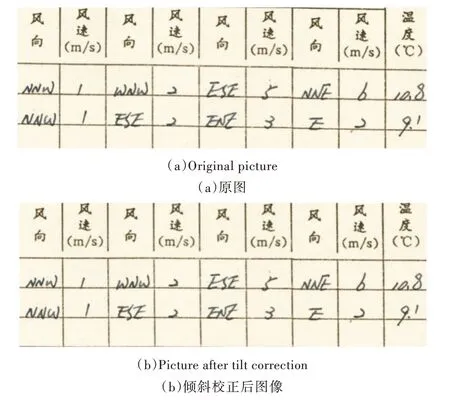
Fig.7 Table line tilt correction图7 表格线倾斜校正

Fig.8 Rough positioning of characters图8 字符粗定位
4.2 投影法精确定位
为了提高字符识别精度,在粗定位的基础上进行精确定位,本文通过投影法对字符进行定位,以获得字符的精确位置。
首先,对图像从左到右及从上到下进行遍历,若满足式(5),即得到字符的左边界及上边界。其中Cn为第n行白色像素个数,Cn+1 为第n+1 行的白色像素个数。

其次,对图像从右到左及从下到上进行遍历,若满足式(6),即得到字符的右边界及下边界。其中Cn为第n行白色像素个数,Cn-1 为第n-1 行的白色像素个数。

如图9 所示,其中图9(a)为原图,图9(b)、图9(e)分别为水平及竖直方向上白色像素的一维投影图,图9(c)、(f)为二值图像上定位到字符的左右及上下边界,图9(c)为字符定位结果。


Fig.9 Precise positioning of characters图9 字符精确定位
5 实验结果分析
为充分验证基于改进概率霍夫变换的字符定位算法的可行性和有效性,实验设计使用PaddleOCR 深度学习字符定位方法以及传统的霍夫变换算法与本文算法进行比较,实验对20 张低质量表格图像中2 460 个字符进行字符定位,针对两种算法的提取结果在字符定位精度和算法准确率两个方面进行分析。
如图10 所示,图10(a)为原图,图10(b)为概率霍夫变换算法结合投影定位效果,部分表格框内字符无法定位到,图10(c)为PaddleOCR 文本检测算法定位到的字符结果。由图可知,当表格框内存在不清晰的字符或表格框内字符之间间隔较大时,无法准确获得字符位置,图10(d)为本文算法定位到的字符结果,基本可以精确定位到全部字符。实验结果表明,本文算法对字符在低质量表格图像上的定位效果优于PaddleOCR 文本识别算法。


Fig.10 Character positioning results图10 字符定位结果
如表1 所示,概率霍夫变换算法定位到正确字符2 252个,错误字符108 个,准确率为91.5%;PaddleOCR 文本字符定位算法共检测到正确字符2 398 个,错误字符62 个,准确率为97.4%;本文算法能定位到正确字符2 443 个,错误字符17 个,准确率达99.3%。实验结果证明,本文算法可以有效定位到表格字符,实现表格字符的精确提取。

Table 1 Comparison of accuracy of different algorithms in different images表1 不同算法在不同图像上的准确率比较
6 结语
本文针对低质量的表格文档图像字符提取问题,设计了一种基于改进概率霍夫变换算法的字符定位算法。本文提出的四邻域灰度差异阈值法,相比于其他算法,能够达到较好的二值效果。本文的字符提取算法在倾斜的图像上校正效果较好。并且,该算法可以精确地定位到字符的位置,相比于PaddleOCR 检测算法,字符提取准确率达99.3%,且本文算法无需大量数据集训练模型,减少了算法的复杂度,提高了字符提取效率。由于本文算法是基于直线定位表格字符,针对直线定位效果不好的图像,字符定位容易出现错误,有待进一步研究。
