推荐系统中考虑流行程度差异的评分预测算法
2021-11-28何光波陈唯一何远济
王 宁,张 巍,苏 湛,何光波,陈唯一,何远济
(上海理工大学光电信息与计算机工程学院,上海 200093)
0 引言
互联网技术的不断进步为人类带来了极大便利,人们可以通过互联网随时随地获取各种信息,但海量的信息增加了人们获取信息的复杂性,预测用户个性化偏好并向用户推荐过滤之后的信息是解决这一问题的重要手段。推荐系统就是通过预测来过滤掉用户不感兴趣的低评价信息或商品,并向用户提供基于其偏好的个性化内容来解决这个问题。因此,相关研究在领域内广泛开展,并在相关服务中广泛应用,这种方法极大提高了用户的体验感[1-2]。
目前,推荐系统相关研究涉及电影推荐[3]、电子商务[4]、图书[5]、市场应用[6]、电视[7]、社交网络[8]、网络搜索[9]等领域。在推荐系统研究中,协同过滤算法(Collaborative Filtering,CF)是应用最广泛的一种方法。该方法基于用户对物品的历史评分来计算用户两两之间的相似性,并寻找与目标用户相似度高的邻居,基于邻居的评分来预测目标用户的可能评分[10],其理论依据是:如果两个用户对相同物品的历史评分相似,那么他们就拥有相似的“品味”或“偏好”,其中一个用户对某个物品的未来评分就可以通过另一个用户对该物品的历史评分预测出来。
协同过滤算法的基本方法是通过计算用户之间[11](基于用户)或者物品之间[12](基于物品)的相似性,基于用户对物品评分的预测结果进行推荐[13]。基于相似性的协同过滤算法包括3 个步骤:①基于各种相似性算法生成用户间相似度的相似矩阵;②选择与目标用户相似度最高的n个用户作为该用户的邻居集合;③向目标用户推荐预测评分高的物品。基于Pearson 相关系数的协同过滤算法和基于Cosine 相似性的协同过滤算法是常见的基于用户相似性的协同过滤算法。为了使评分预测更加精确,也可基于用户观点传播(User Opinion Spreading,UOS)等方法来计算用户间的相似性。
尽管计算相似性算法很多,但这些方法都没有充分考虑流行度对预测结果的影响。针对这一现状,本文针对以下两个问题对推荐算法进行研究。
(1)在用户间计算相似性时,两个用户评分过的物品是相似性计算的基础,在相似性计算中他们共同评过分的物品数量过多或者过少一般都不予考虑。在这种情况下,本文研究在相似性计算过程中引入一个基于用户间相同历史评分数量的置信系数来调整这些历史评分在相似性计算中所占的权重。
(2)不同用户或物品在推荐系统中的流行程度是不同的,如对于一个流行度高的物品会有大量用户评分,无论用户对其评分是高还是低,流行度高的物品比流行度低的物品在预测时更多地影响预测结果。因此,在预测用户对物品评分时引入物品流行程度系数,使预测评分更加接近于真实情况。本文主要研究置信系数和物品流行度的引入对预测准确度产生的影响。
1 实验内容
1.1 置信系数对相似度计算的影响
现有研究表明,用于计算用户相似性的两用户间共同历史评分数目会对预测结果产生影响。为解决该问题,本文将置信系数引入相似性计算,以此改善评分数目对实验带来的影响。置信系数计算公式如下:
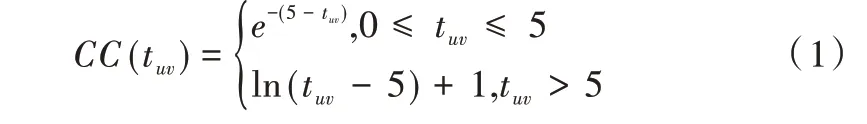
式中,CC(tuv)表示u用户与v用户之间的置信系数结果,tuv表示u用户与v用户同时评过分的物品数目。
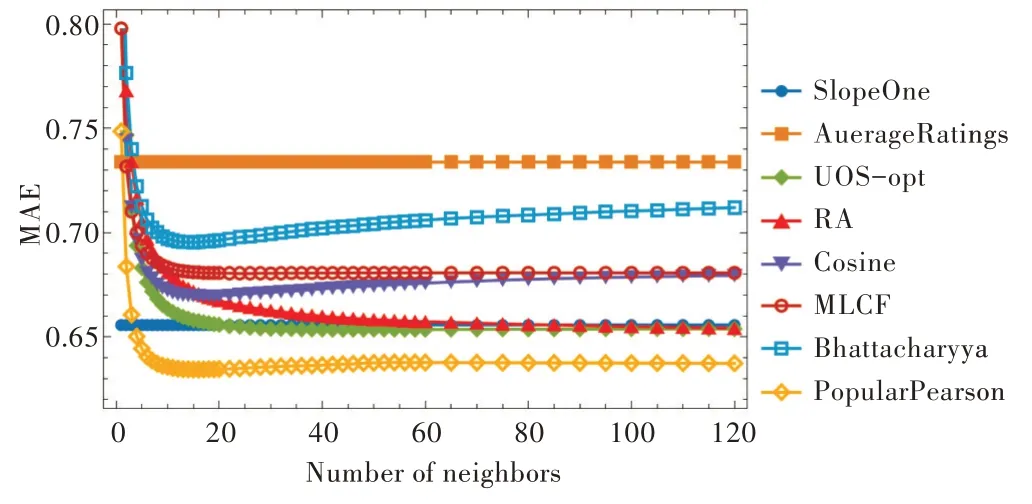
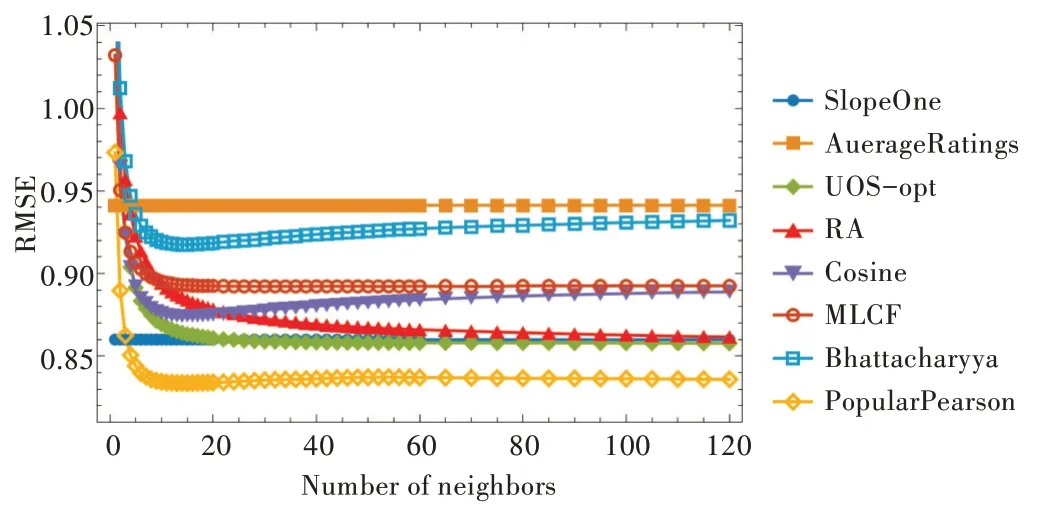
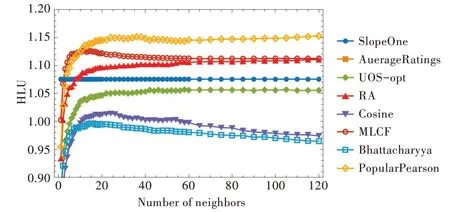
当两个用户之间的共同评分数目tuv>5 时,CC(tuv)的值会按照对数函数单调增大;而当0 本文基于文献[14]、[15]的研究结果来构建物品与物品间的复杂网络,并用度值表示用户的流行度,用此网络研究流行度对预测用户评分的影响。结果表明,流行度高的用户在预测评分过程中其作用被高估,这对预测评分的准确度带来很大影响。为解决这个问题,在评分预测公式计算中引入流行度数据以提高评分预测准确度。 本文采用置信系数来改进Pearson 算法进行相似度计算,以提高相似性计算的准确性。 本文进行相似度计算中考虑了评分数目对用户偏好的影响,公式如下: 其中是用户u对物品i的评分,是用户u的平均评分,CC(tuv)由公式(1)给出。 基于公式(2)给出的用户间相似性进行复杂网络建模,以用户为节点,以相似性为边,构建用户—用户复杂网络。在此网络中计算用户节点的度值中心性,并根据相似性结果选择一组合适的邻居,由邻居节点的度值权重、邻居的评分数据以及目标用户与邻居用户的相似性关系对目标用户的评分进行预测。基于流行程度差异的推荐系统评分预测算法简记为PopularPearson 算法,算法步骤如下:①用置信系数对皮尔逊相似性计算公式进行改进,提高用户间的相似性准确度;②按照得到的用户间相似性与用户节点构建用户—用户复杂网络模型;③根据此模型进行用户节点的中心性计算;④每个预测目标用户选择一组合适的邻居;⑤依据选择的邻居集、邻居的评分、改进后得到的相似性和度值中心性对目标用户进行预测评分。 图1 是PopularPearson 得到的相似性复杂网络模型(彩图扫OSID 码可见,下同)。相似性网络中的节点代表用户,节点大小表示用户度值的大小,节点与节点之间的链接为用户间的相似性,链接的长度表示用户间相似度的大小,不同颜色标记了用户所属的不同社团。 Fig.1 An example of complex network modeling based on weighted similarity of confidence coefficients图1 基于置信系数加权相似性的复杂网络建模实例 度值对于评分的预测有一定影响,如对于某个目标用户u,通过相似性计算得到不同的邻居v1,v2,v3,如果Suv1=Suv2=Suv3,即用户u与3 个邻居用户的相似度一致时,可以根据文献[16]的研究结果对邻居赋予不同权重。对目标评分进行预测公式如下: 式(3)中,表示对于目标用户u的预测评分;表示用户v的平均评分;rvi表示用户v对i的评分;n表示选取的预测用户总数;Degree∗(v)表示用户v归一化之后的度值。 为验证本文算法的预测效果,选用了MovieLens 作为测试数据集。MovieLens 数据集中含有671 位用户关于9 125 部电影的10 万条评分数据。 本文选择折十验证方法进行测试。将MovieLens 数据集随机分为10 份,每份数据量差不多。首先选择其中一组为测试集进行验证,其余9 组均为训练集,然后依次完成10次实验,每次选择不同的一组为测试集,另9 组为训练集,这样使每组数据都能被预测。对10 次测试结果取平均值检查算法的准确度。 采取多种算法分别进行实验测试的方式比较其预测效果。选择进行比较的算法有资源分配RA 算法、SlopeOne算法、用户观点传播UOS-opt 算法、Cosine 协同过滤算法、多级协同过滤MLCF 算法等。 在衡量预测结果好坏问题上选择平均绝对误差(MAE)、均方根误差(RMSE)与排序性能指标半衰期(HLU)3 个度量标准。通过实验将获得的预测评分数据与测试集中用户的实际评分进行比较,计算出对应的MAE、RMSE 以及HLU 值,其中MAE、RMSE 的值越小,实验预测评分准确度越高;(HLU)值越大,推荐列表中物品的排序越准确。 MAE、RMSE、HLU 的计算公式如下: 其中,n表示测试集中的用户数;rui表示用户u对i的实际评分值表示实验中预测的用户u对i的评分值;d表示用户的平均评分;N表示物品数;h在本文实验中设置为2。 采用MAE、RMSE、HLU 三组参数比较各种算法的预测效果,由MAE、RMSE、HLU 的值得出各种算法在预测评分中的误差程度与排序准确性,以探究本文基于物品流行程度改进的预测算法有效性。 对MovieLens 数据集采用折十验证方法对算法进行实验测试,实验结果证明本文设计的基于流行程度差异的推荐系统评分预测算法在测试集中表现出很好的预测准确度,在评分准确度上比其它7 种算法提高很多,而且在达到最佳准确度时所需的邻居更少。 从图2 可以很清楚地看到不同算法在不同邻居数时平均绝对误差(MAE)的变化情况。其中,PopularPearson 算法下的MAE 值最小,为0.636 9,第二名UOS-opt 算法为0.653 4,PopularPearson 算法比UOS-opt 算法在性能上提高了2.5%,平均提高了3.48%。 图3 表示不同算法在不同邻居数量时对应的均方根误差(RMSE)变化趋势,从图中可以看出,基于PopularPearson算法的RMSE 值最小,约为0.837 5,UOS-opt 算法的RMSE值约为0.857 7,PopularPearson 算法比第二名在性能上提高了约2.4%,平均提高3.38%。 图4 为在选择不同邻居数时不同算法的排序性能指标(HLU)变化情况,可以清楚看到,PopularPearson 算法下的HLU 值最大,达到1.161 9,而第二名MLCF 算法下的HLU值只有1.126 6,最优预测下PopularPearson 算法比MLCF 算法在排序准确性上提高了3.13%,平均提高了1.78%。 Fig.2 Comparison of MAE results of various algorithms with different numbers of neighbors图2 各种算法在不同邻居数量下MAE 结果对比 Fig.3 Comparison of RMSE results of various algorithms with different neighbor numbers图3 各种算法在不同邻居数量下RMSE 结果对比 Fig.4 Comparison of HLU results of various algorithms with different numbers of neighbors图4 在不同邻居数目下各种算法的HLU 结果对比 综合3 个图中的实验结果数据可知,本文设计的Popu⁃larPearson 算法在预测准确度上高于其它几种算法。 本文研究了推荐系统相似性网络模型中流行程度差异对预测准确性和推荐列表排序效果的影响,设计了一种新的推荐系统评分预测算法,利用用户相似性网络模型中不同用户度值大小来表示其流行性差异,并基于流行性差异设计了预测方法。融合用户流行度差异和用户评分偏好特征对未知评分进行预测。 在MoiveLens 数据集中的折十验证实验表明,本文方法的预测结果准确度比其它传统算法相比有明显改善,以MAE 和RMSE 指标度量,比算法UOS 的预测准确度提高了3%以上。 研究结果表明,本文设计的算法在预测评分时性能优越,并揭示了推荐系统中流行程度差异对评分预测结果有较大影响,合理利用这一信息可以有效提高推荐算法性能。1.2 物品流行度对相似性网络的影响
2 基于流行程度差异的推荐系统评分预测算法
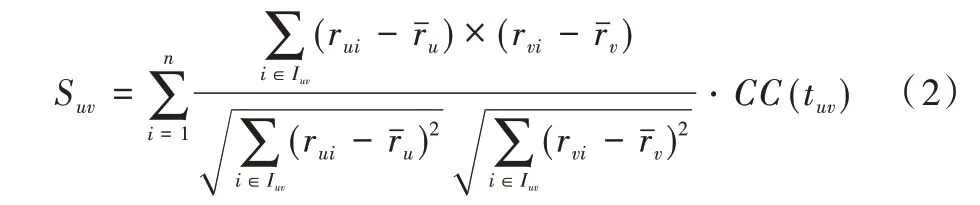

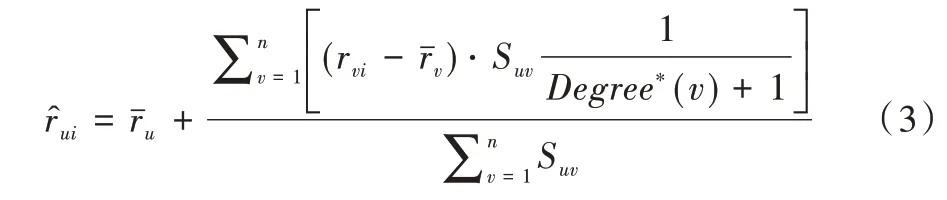
3 实验设置
3.1 数据集与参数
3.2 算法比较
3.3 评估标准
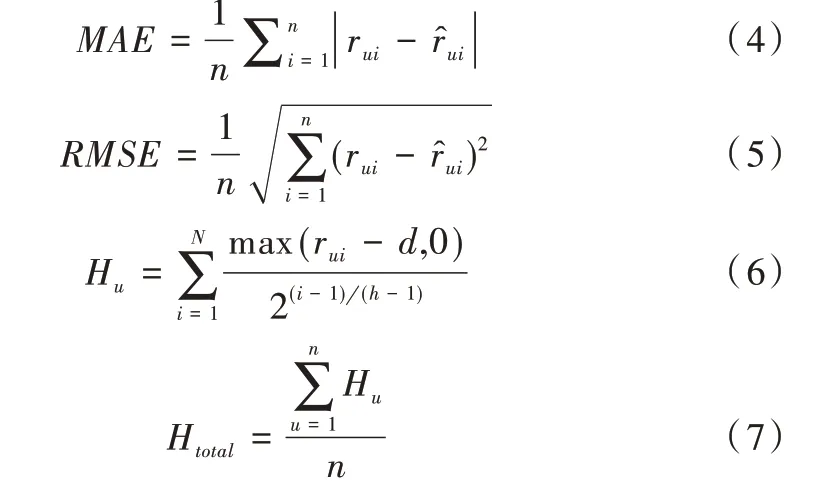
4 实验结果与分析
4.1 比较参数
4.2 实验过程
5 结语
