类GAN 算法的脑部核磁共振图像增强技术研究
2021-11-28李梓鸥费树岷
李梓鸥,费树岷
(东南大学 自动化学院,江苏 南京 210096)
0 引言
传统的自动化技术逐渐被机器学习与深度学习等方法取代,智能检测方法在医学领域发挥着越来越重要的作用,在传统的医学影像技术中应用计算机图像处理技术具有重大的实际意义。计算机图像处理技术不仅能够有效提高医学影像的处理效率,还能够保证医学影像的清晰度与准确度,从而提高医学诊断准确度,最终大大提高了现代医疗水平[1]。
然而,在利用机器学习方法与深度学习方法对传统医学核磁共振图像(Magnetic Resonance Images,MRI)进行检测与分割时,由于采样难度大、成本高,病态样本数量的多样性稀缺以及病人的隐私问题而导致样本数量不足,样本质量不高严重限制了机器学习与深度学习方法应用[2-3]。因此,有效扩充数据集是支撑计算机辅助分析方法的重要基础。
传统的扩充方法是对图像的基本集合变换,如水平翻转、竖直翻转、随机旋转角度、随机水平平移、随机竖直平移、随机错切变换、随机放大、颜色变换、亮度变换、对比度变换等一系列图像处理方法[4]。单纯使用基本变换方法增加了样本数量,但这样指定特征的扩充方法是有限的,并且未从本质上改变图像,仅保留了处理前的特征与所有组合。除了对图像进行基本变换外,SMOTE 方法也是扩充数据集的一种直接方式。尽管SMOTE 方法可以扩展出与原数据集中元素不相似的图像,但在图像扩充问题质量上却很难通过视觉图灵测试。
近年来,随着深度学习的不断发展,通过深度神经网络模型生成的图像样本应用在不断增加[5-6]。2013 年,Die⁃derik 等[7]首次提出变分自动编码器VAE 模型,采用KL 距离作为理论损失函数,利用对下界逼近的方式训练模型。但是因为KL 散度在真实和生成分布间的不对称性,以及训练过程中是针对上界逼近,所以效果并不理想;2014 年,Ian 等[8]首次提出了生成对抗网络(Generating Adversarial Networks,GAN),利用一个判别器D 作为生成器G 的损失判别函数,隐式地表示生成器G 的损失函数。但是等价的詹森香农距离(Jensen Shannon Divergence,JSD)损失函数本质上并不是连续可导函数,所以仍存在不稳定的训练过程,即生成器G 的学习动力不足。GAN 模型广泛应用于医学图像合成,主要为医学图像的扩充;2017 年,Zhang 等[9]设计了SCGAN,利用两级的GAN 模型生成心脏MRI 的图像,并将该图像作为扩充数据集进行检测;2018 年,Plassard等[10]利用DCGAN 生成了T1 权重下的脑部MRI图像,并设计了去噪自动编码器对原图像去噪;Beers等[11]利用PGGAN对细胞瘤和视网膜图像进行合成。近年来,基于大规模计算框架的GAN 模型[12]与医学图像翻译(Translation)[13]逐渐成为热点。
以上方法都是对原始GAN 模型的改进,依然保留着原始GAN 中的缺陷问题,同时也缺少对GAN 缺陷的理论分析以及改进措施。本文使用K-Lipschitz 约束GAN 及其变体[14-16],并将其与图像处理中的深度卷积模型结合并加以改进,提出一种利用少量的脑部核磁共振图像(MRI)进行图像增强的方式,并从理论上分析了改进的稳定性数学原理及实际意义。同时,本文也分析了当前学术界较为流行的几种指标,指出了脑部MRI 的合成过程中常规指标IS 的不合理性,并采用FID[17]作为衡量生成数据的质量与多样性指标,对现有的FID 指标进行改进,以此替代一般的视觉图灵测试方法。实验结果表明,使用含有K-Lipschitz 条件约束的GAN 模型使判别器对输入的梯度数量级较为合理,稳定性明显强于使用JSD 作为损失函数的GAN 模型,同时在质量和生成多样性上也有显著提升。
1 脑部核磁共振图像数据集
1.1 脑部核磁共振图像成像原理
核磁共振图像是通过原子核在磁场内产生信号,并经过重构成像的一种医学影像技术。核磁共振技术在医学领域有着广阔的应用场景,可在不进行物理解剖的条件下无损地重构出身体器官的图像信息。核磁共振成像技术在病理分析、医学诊断等各个医学领域都有应用。
大脑是一个结构复杂且功能强大的器官,核磁共振图像因其在横截面成像方面性能优越,在脑部成像上应用最为广泛[18]。一般对大脑扫描成像的MRI 分为横断面、矢状面、冠状面,分别对应三维空间中的3 个截面。对于一个现实中的大脑样例,一次完整的核磁共振成像过程会在3 个截面上进行扫描,形成三组图像,每组图像包含了该截面与大脑相交的截面图像。同时,核磁共振的成像机器可以选择不同厚度和数量的切片,以满足不同应用场景需求。除此以外,在释放电磁波构建MRI 时,一般会采用加权的方式进行图像处理,通过此过程对大脑中不同的结构进行划分,这些加权方式包括T1、T2、Flair、DWI 等。
1.2 核磁共振图像预处理
本文主要使用两个数据集:①以自闭症内在大脑结构研究相关的ABIDE 数据集;②阿兹海默症(AD)与轻度认知障碍(MCI)内在大脑结构研究相关的ADNI 数据集。一张核磁共振图像一般由一个图像序列{ }x|i=1,…l组成,其中,参数l为切片层数,在预处理过程中,本文在ABIDE 数据集以及ADNI 数据集中选取横断面扫描的图像2D 切片作为生成对象,着重选择靠近丘脑与海马体的切片部分进行数据增强。最终,在ABIDE 数据集上选择106 个样本截取切片图像,并将图像重新映射至[-1,1]区间内。
值得注意的是,相比于学术界中较为流行的数据集,核磁共振图像数据集具有样本数量少、获得难度较大、样本之间大体特征相似但细节特征丰富而细微的特点。
2 数据增强算法模型
目前在医学领域最新且应用最广泛的数据增强方式是GAN 模型(包括深度卷积化的GAN 变体),然而传统的GAN 模型具有许多固有缺点:对抗方式训练过程具有不稳定性以及随着GAN 中判别器D 的收敛,生成器G 的学习动力不足等问题,这些问题都会影响传统GAN 生成样本的质量。本文使用Wasserstein GAN 及其改进的变体替代传统的GAN,对于训练的不稳定性以及学习动力不足有很大改善。
2.1 传统GAN 模型
2.1.1 深度卷积结构的GAN 模型
传统的GAN 模型采用两个子神经网络作为GAN 的基本结构,分别是生成器G 与判别器D。在常规模式下,生成器G 与判别器D 使用一般的前向神经网络进行建模。而本文对于生成器G 采用了深度解卷积层进行建模,对于判别器D 采用卷积层进行建模,以满足模型生成图像的要求。卷积与解卷积相比于一般全连接神经元建模方式有两个特点,分别是部分连接与参数共享。部分连接指前一层的卷积层只有一个相邻的子空间生成下一层的一个结点,参数共享指同一层产生不同位置的部分连接,享有共同的参数。部分连接所反映的思想是:对于一张图像,其中几个相邻的像素点组合成的一幅子图像就可以具有一定的特征属性,不必如全连接型的神经网络一样将所有结点都与下一层相连。而参数共享所反映的思想是:对于同一层次的多个部分连接都采用相同的参数进行特征提取,这意味着同一层次不同位置上的卷积层都可以利用相同的特征提取器进行特征提取。部分连接与参数共享的优势在于利用图像局部相关的特性大大减少了参数的数量及模型的空间复杂度,同时加快了模型的训练速度。GAN 网络框架结构如图1 所示,其中表示嵌入空间的随机变量,表示真实样本,表示生成样本,表示标签。

Fig.1 GAN network framework structure图1 GAN 网络框架结构
传统GAN 充分利用了对抗思想,引入二分类判别器D来判断生成器G 生成的样本与真实样本差别,其损失函数如下:

其中,生成器G 的输入为随机噪声信号,输出为与训练图像等尺寸的同类图像,而判别器D 则使用了一般的二分类网络,对真实图像和生成图像进行分类,使用神经网络进行判别。将式(1)优化到最优后即得到JSD。
整个优化过程属于min-max 优化,在不断优化生成器G 与判别器D 的过程中使G 与D 呈对抗态势。对于难以分开的复杂的两类样本,判别器D 的辨别能力在优化过程中不断加强,同时生成器G 生成样本的能力也越来越强,不断给生成器输送与正样本(即训练样本)形态类似的正样本,并且在生成器G 更新的过程中,其生成的样本越来越复杂且难以分开,这些与训练样本形态相似的样本被称为对抗样本,其优化公式如下:

2.1.2 GAN 模型训练过程
如图2 所示,GAN 的训练过程包含对生成器G 与判别器D 的异步更新,图2 简要说明了当下GAN 训练过程的基本框架,在不同K-Lipschitz 限制下,对于流程图的各个环节均有一些修改。

Fig.2 GAN-like network training process structure图2 类GAN 网络训练过程结构
其中,K 值表示每次更新生成器G 时判别器D 更新的次数。在训练过程中,首先采样随机噪声用于生成负样本,采样真实样本;之后对判别器D 训练K 次,将两类样本通过二分类器分割。在此过程中,分类器效果越好,生成器的学习动力越不足,后面将具体说明。在对判别器D 进行K 次更新后,再反向更新一次生成器G,反向更新在损失函数上表现为损失增大,即判别器D 不再能很好地区分生成样本与真实样本。当生成器G 收敛时,且判别器D 具有足够的复杂程度,则判别器D 的分类边界B在输入上所反映的流形就是真实样本在样本空间中反映出的流形。所以本质上说,优化过程是生成分布Pg跟随分类边界B不断逼近真实分布Pr的过程。
2.1.3 传统GAN 模型限制
传统GAN 在学术界存在两个最大问题是梯度弥散以及模式坍塌,这两个问题直接影响了传统GAN 在训练以及生成新样本时的质量与多样性。
梯度弥散问题主要指生成器G 在更新过程中,梯度计算必须经过判别器D 而导致的学习动力不足问题。传统GAN 的训练过程是先对判别器进行若干次优化,再对生成器G 进行优化。
定义1 定义紧致测度空间X及其上分布Pr与Pg,嵌入空间Z,二分类离散概率空间Y。映射Gθ:Z→X,映射Dw:X→Y。给定样本集Strain={(x(i),y(i))}i=1,2…m,其中x(i) ∈X,y(i) ∈Y。Dw在样本集Strain下的极 大似 然估计(MLE)为Dw_opt。
定理1 若Dw_opt对其输入可导,且supp(Pr)⋂supp(Pg)=∅,则∇loss(Dw_opt()) →0。其中supp(Pr)⋃supp(Pg),loss(⋅)为负对数极大似然函数。
推论 当Dw=Dw_opt时,Dw等价为JSD,定理1 说明JSD对Gθ输出的梯度为0,梯度信息基本不能传播到Gθ。
如定理1,传统GAN 将最优的判别器Dw_opt引入损失函数后,在更新生成器G 时梯度为0。所以针对传统GAN 的训练过程,每一步对判别器D 的更新都不能达到最优,否则会出现梯度为0 的情况,这是优化变得不稳定的根本原因。从JSD 的角度来看该问题,即JSD 的导数为0,不适合作为损失函数利用梯度进行启发式搜索优化。
模式坍塌问题主要是GAN 模型生成的样本不具有多样性。模式崩塌解决方法是采用改变训练批次的数量来权衡训练速度与样本多样性的平衡问题。此外,模式崩塌还与随机输入维数关系极大。
2.2 K-Lipschitz 条件下改进的GAN 模型
2.2.1 基于Wasserstein 距离的GAN 模型
Wasserstein GAN 使用Wasserstein 距离代替普通GAN中的JSD,Wasserstein 距离定义如下:
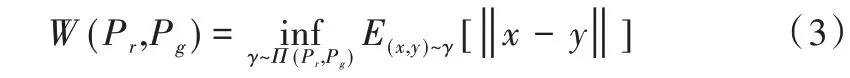
其中,Pr与Pg代表真实样本和生成样本的分布,Π(Pr,Pg)代表两个为边缘分布的所有联合分布组成的集合。
在两个分布Pr与Pg的联合分布中,选择一个特定的联合分布,在连续的样本空间中,这个联合分布可以表征出一种将Pr的概率函数变换成Pg的由微分过程和积分过程的可逆泛函映射,记作:F:Pr→Pg。对于离散的样本空间可以理解为将Pr(或Pg)中的概率值拆分并变换到Pg(或Pr)的过程。可证明每一个联合分布有且仅有一种分解Pg并将其组合为Pr的方式。
通过上述简单分析,可将Wasserstein 距离用以下方式解释:寻找一种泛函映射方式(一个Pr与Pg的联合分布),使得两个边缘分布Pr与Pg以最简单的形式相互转化。要尽量使得下确界达到,就要尽可能地使由X 与Y 中有相同取值的样本对应的概率密度进行直接转化。当两个分布相等时,其下确界取得的联合分布恰好在X 与Y 相同的位置其概率才不为0(其他位置概率为0),此时计算出的距离恰好为0,即最简转化形式。如果在最简形式的转化过程中,两个样本空间X 与Y 的非同值对应的概率密度发生转化,则被定义为Wasserstein 距离。
尽管式(3)具有很好的数学特性,但是在联合分布集{Fi} 中寻找出一个特定的联合分布在数值计算过程中仍有一定困难,根据文献[14]中的K-R 定理将式(3)等价为式(4):
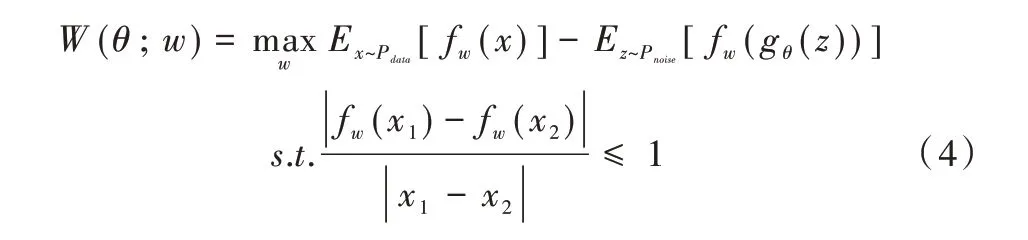
该式的约束条件即为1-Lipschitz 条件。将损失函数扩大K 倍后,可以将约束进一步改为满足K-Lipschitz 条件,即可使上式成立。值得一提的是,fw是Dw去除最后一层激活函数的非线性函数,当Dw=Dw_opt时,fw=fw_opt。由定理1及其推论可知,正是因为传统GAN 中最后一层激活函数是在分类器的背景下定义的,所以其梯度接近弥散的问题很难解决。如果隐层的激活函数也使用sigmoid 则弥散问题会严重一些,但隐层可以使用relu、elu 等抗弥散的激活函数代替,并且可以使用批归一化的方式对数据分布进行重新规划,而输出层则却不行,但使用Wasserstein 距离后就不存在隐层激活问题。
K-Lipschitz 条件沿用了部分导数定义,反映了一个函数在其定义域内的平均变化率。对整个判别器进行KLipschitz 约束后,相当于对判别器D 的复杂度进行了约束。在Wasserstein GAN 中采用权重限幅(weight clipping)的方式让判别器D 保持K-Lipschitz 条件,每次更新将权重限制在[-c,c]范围内,其中c 为限幅幅度,利用限幅来控制整个判别器的输出,限制其从输入到输出满足K-Lipschitz条件。
2.2.2 K-Lipschitz 条件下WGAN优势
传统GAN 最大的缺陷在于当真实样本和生成样本在样本空间中的支撑集没有交集,而且判别器D 达到最优分类界限时,生成器G 的学习动力不足,即:
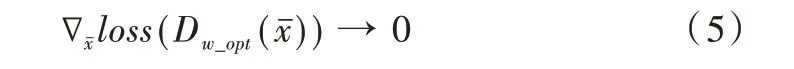
由文献[15]中的命题一可知,当1-Lipschitz 条件成立时可以得到以下结论:
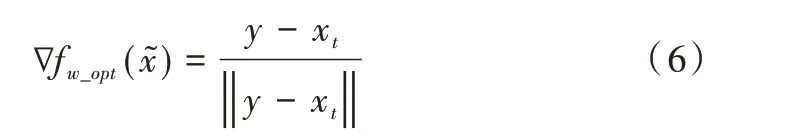
其中,来源于=εx+(1-ε)表示在真实样本x和生成样本连线区域。因为损失函数形式改为了Wasser⁃stein 距离形式,所以式(6)基本等于损失对输入的梯度,即与传统GAN 所得结果不同,满足K-Lipschitz 条件的WGAN其损失对输入的梯度向量等于单位向量。
3 判别指标
目前在学术界中,常用的判别指标包括了Inception 得分(Inception Score,IS)以及Frechet Inception 距离(Frechet Inception Distance,FID)等[19],其中IS 与FID 两个判别方式是使用最广的判别指标。本文将先分析这两个指标在ABIDE 数据集与ADNI 数据集上的合理性,给出舍弃IS 的原因,最终选择FID 作为衡量指标。
3.1 IS 简介及其在MRI 数据集上的不合理性说明
Inception 得分是一种衡量图像质量与多样性的一种方式,文献[15]对于生成器生成图像的质量和多样性可以直接使用规模庞大的判别网络进行判断,所以IS 是一种网络的判断方法。将ILSVRC 竞赛中的Inception-V3 模型作为判别基准[20],其公式如下:
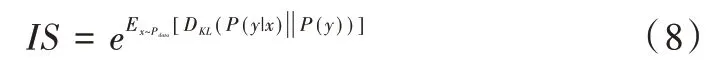
式(8)中最关键的两个部分就是KL 距离,以及对先验概率P(y)与经过判别器D 后得到的后验概率P(y|x)之间的关系。从本质上说,IS 是最大化两个熵值的差:

其中,H(y|x)表示在输入图像下其类别的熵值,是对后验概率P(y|x)的混乱程度的一种描述。当判别器D 能确定某张图像x(i)属于哪一类时,H(y|x)的值会较低,也即图像x(i)在该类上的质量较好。同理,H(y)表示在所有的生成图像中标签的混乱程度。混乱程度越大,生成图像的多样性越好。当先验概率P(y)呈平均分布时其熵值达到最大,所以最终将两个熵相减并反推以上证明,就得到Inception 的分值。值得一提的是,KL 距离在信息学上可以衡量两个随机分布的差异性(或者称为距离),但因其不对称性[10]以及当后一个概率的支撑集和整个概率空间的差集测度不为0时,在KL 距离无穷大的情况下,KL 距离会被其他距离所替代。
从上面的分析可以看出,若GAN 需要生成的样本都是属于Inception-V3 类别的样本,那么当上式给入样本集时,Inception-V3 能正确地给出统计概率(y|x)并判断图像样本的类别。在对类别进行统计时也能正确地给出每一类样本被生成的统计概率(y),这样最终得到的IS 指标还是比较有效的。然而,脑部核磁共振的切片图像属于单一有标签类别,并且不属于Inception-V3 中分类的任何一类,所以使用常规的IS 是没有内在意义的。我们更应该注重的是对于具有不同细节的同一个有标签类别的指标建模,以及图像中的某个局部图像是否为有标签类别的特征。
3.2 FID 简介
除了上述IS 劣势外,其未与图像空间的概率分布产生关联,仅仅与分类空间产生关系,但FID 则很好地解决了这个问题。
FID 定义如下:
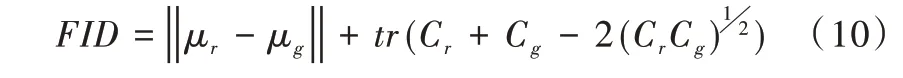
其中,μr与μg为真实特征和生成特征的均值,Cr与Cg则是真实特征和生成特征的协方差矩阵。
IS 未将原数据集引入计算,为解决该问题提出了FID,其原理是将实际图像和生成图像利用Inception 特征提取器进行特征提取,之后将提取后的特征看作特征空间的高斯分布,通过考量两个高斯分布均值和协方差矩阵的差值范数,从而得出两个图像空间之间的距离。距离越近,两个分布越相似,生成的质量也就越高,但同时多样性也随之变差;距离越远,生成的质量则越低。对于脑部MR图像这类特征细小的样本,以高斯分布对其进行建模的方式十分适用于该问题,将IS 对通过神经网络所得的类别分布直接改为原始图像在像素空间中的分布,很大程度上提高了FID 在该问题上的可解释性与合理性。
3.3 基于FID 的新型指标计算方式
本文将经过Inception 特征提取器的FID 绝对值作为衡量指标改为基于样本集的相对指标,相对指标综合考量了生成图像的质量与图像多样性要求。之前的研究普遍认为FID 值越小越好,然而在实践中如果对数据集的图像进行简单的图像变换(例如翻转、平移、错切等)后,计算其与原集合的FID 值会产生一个十分小的值。此时,尽管整个数据集与原图有差异,但是其FID 值依旧很低,在细节模式上变化很小,但新样本是与数据集相似的冗余样本,而非具有多样性的样本。
针对以上问题,本文提出类间FID 与类内FID 概念,并说明其原理。
FIDinter成为类间是指训练集与生成图像集之间的FID值,也就是常用的FID 方式。FIDintra也称为类内FID,指某类集合中样本间固有的FID 值,反映了一类样本集中固有的多样性。根据两种集合,还可以把类内FID 分为样本集类内与生成集类内,样本集类内又被称为FIDanchor。FIDinter的计算方式与传统FID使用方式一致,而FIDintra则是将某类集合随机分为两半,将这两半集合作为不同分布进行统计。将新的FID 指标定义为:
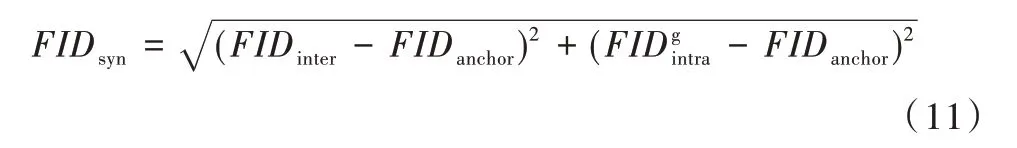
其中,式(11)的优势在于FID 值不是越小越好(将生成集作为训练集时,FID 为0,但图像冗余度过高,样本多样性不够好),而是越接近FIDanchor越好(因为类别具有层级性,某一大类中样本依旧有小类,即某些细节特征的变化是多样性的根本,保证类内的多样性即保证FID 值不应太小)。式(11)的第一项反映了整体生成集的质量和多样性是否与训练集一致,第二项则反映了生成集内部有无模式坍塌现象。
4 实验结果与分析
基于ABIDE 脑部核磁共振数据集中的数据,本文使用训练过程更为稳定的Wasserstein GAN 代替了传统的GAN,同时利用传统的图像增强方式对原数据集进行扩充,在传统指标FIDinter与本文提出的FIDsyn指标上进行对比分析,实验环境为Python+Tensorflow 框架。
实验流程如下:首先,从ABIDE 数据集中逐一选择出清晰而合适的横断面扫描图像的三维采样数据集。通过观察与对比,将接近丘脑部分的截面图像提取出并进行归一化处理,在图像尺寸方面,将其统一成128*128 大小的灰度图像;在图像像素强度方面,将其统一在[-1,1]区间内;之后,将图像通过图2 的流程进行训练,采样得到新生成的核磁共振图像。与此同时,利用挖除、添加噪声、对比度变化等方式,对数据集进行传统的数据增强;最后,计算FIDinter与FIDsyn指标,值得一提的是,FIDinter指标需要对一个样本进行不同方式的分割,计算其均值减少偶然误差。图3 给出了两组图像的对比。
图3 中左侧为经过预处理后的ABIDE图像数据,右侧则是经过WGAN 模型生成的脑部核磁共振图像数据。通过视觉图灵测试(Visual Turing Test,VTT),可以观测出,尽管有细微的差异,但生成图像在质量上基本与训练集差别不大。同时,生成图像的多样性也较好,生成与数据集重复与冗余的图像较少。这两点充分证明了WGAN 在逼近某个分布时,相较于传统方式具有更好的生成能力。
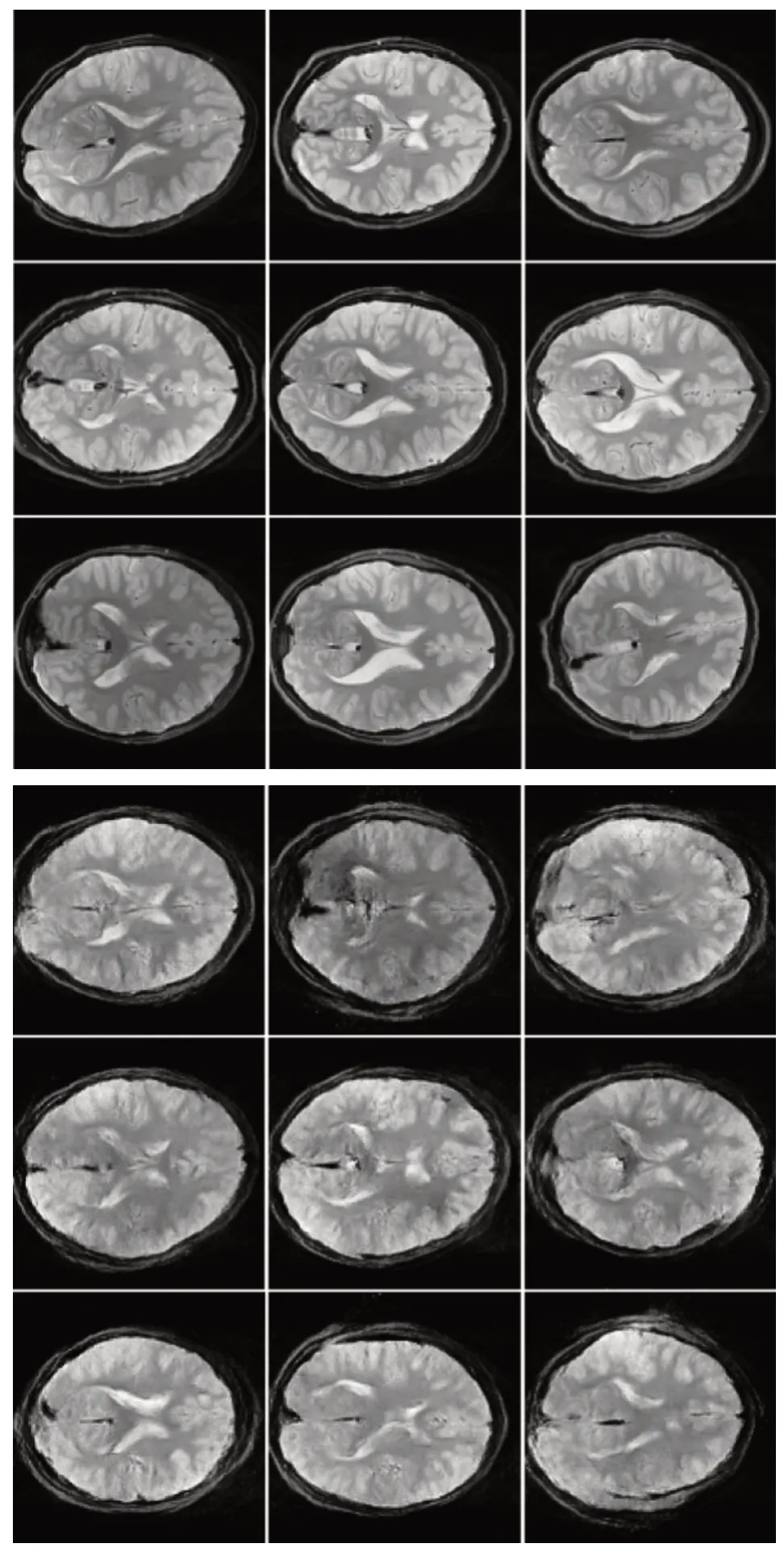
Fig.3 Partial MRI real images(left)vs.generated images(right)图3 部分核磁共振数据集图像(左)与生成图像(右)
表1 反映了在不同图像集下其与ABIDE 数据集的FID指标关系,可以看到质量低的数据集(如随机噪声)的FIDinter值(传统FID)很高,质量高的数据集(如原数据集(整))的值接近0,但后者忽略了生成新样本的多样性问题。FIDsyn则很好地反映出了质量与多样性之间的关系。在SMOTE 算法上实验得到的图像经过VTT 的效果很好,但是FIDinter的指标很大,这是由于其超越了数据集进行了扩充。由表1 可知,WGAN 方法生成的样本相比传统方法更好,在传统FIDinter指标上达到了1.29,在FIDsyn指标上则达到了0.07,相较于传统的增强方法有明显提高。

Table 1 Comparison of FID metrics for ABIDE dataset generation results表1 ABIDE 数据集生成结果FID 指标比较
5 结语
改进的GAN 模型及其变体中,使用Wasserstein-1 距离代替了JSD 作为生成网络G 的损失函数,同时将Wasser⁃stein-1 距离表达成可以优化的函数式,增加了K-Lipschitz条件对GAN 的限制,使得GAN 训练过程中,在反向传播后,对于判别器D 的支撑集(WGAN-GP)以及支撑集以外的区域(SNGAN)有着优良的梯度特性,从而很好地避免了因为网络层数过深以及不合适的非线性激活函数所导致的学习动力不足之类的训练稳定性问题。后续工作应该着重于对Lipschitz 条件深入理论分析与实际改进。
模式坍塌是GAN 最常见的问题之一,在本文之外对类GAN 网络产生模式坍塌的原因做了一些简单实验,经过VTT 发现,生成器G 的随机噪声输入维数越小,生成器生成的模式相似图像就越多。深入探究类GAN 网络模式坍塌的具体原因也是未来的工作之一。
同时,对于新的FID 指标,还需要在更多的数据集以及更大规模的真实样本集上实验,并对比更多数据扩充方法(尤其是SMOTE 算法)验证其优缺点,从理论上说明不同的数据集上FIDsyn的第一项与第二项收敛的依据。如何提高整个指标的敏感度也是进一步改进FID 指标重要的研究方向。
