基于机器学习的数据库系统自动调参研究
2021-11-28陈镭
陈 镭
(1.南京审计大学 信息工程学院,江苏 南京 211815;2.南京大学计算机软件新技术国家重点实验室,江苏南京 210023)
0 引言
数据库管理系统(Database Management System,DBMS)在管理大量数据和处理复杂工作的同时,自身也有成百上千个参数(Mysql 有几百个,Oracle 则有上千个)需要配置,如缓存大小和读写磁盘频率等。DBMS 的性能很大程度上依赖于这些参数的合理设置,但应用程序不能简单地复用先前配置,最佳配置往往取决于其工作负载和底层硬件。配置参数大多不是独立的,其间存在复杂的隐式关系,更改一个参数可能会影响另一个参数的最佳设置,如何找到最优参数配置是一个非确定性多项式(NP-hard)问题。因此,数据库管理人员往往需要花费大量时间根据自身经验调优数据库参数。随着数据库规模与复杂性的不断增长,以及工作负载的频繁变化,数据库管理人员的优化工作量已经超出其承受能力。
为解决上述问题,利用机器学习技术改进数据库系统性能成为工业界和学术界的研究热点。在工业界,Oracle公司于2017 年发布了无人驾驶数据库,可以根据负载自动调优并合理分配资源;阿里云于2018 年启动数据库智能参数优化的探索[1],目前已经在阿里集团10 000 个实例上实现了规模化落地,累计节省12%的内存资源;华为于2019年发布了首款人工智能原生(AI-Native)数据库,首次将深度学习融入分布式数据库的全生命周期。在学术界,卡耐基梅隆大学数据库研究组开发的OtterTune 系统[2]维护了一个调优历史数据库,可利用这些数据构建监督和无监督的机器学习模型组合,进而使用这些模型映射工作负载、推荐最优参数等,使DBMS 调优过程完全自动化;Zhang等[3]利用基于策略的深度强化学习方法提出一种端到端的云数据库调参系统CDBTune,首先从用户处采集工作负载,然后内置模型,根据当前工作负载状态推荐参数,并在线下数据库中执行负载,记录当前状态和性能用于训练离线模型,同时对在线模型进行相应调整。此外,还有大量基于机器学习的数据库系统综述研究[4-9]。基于此,本文首先详细介绍数据库自动调参系统的结构和工作原理,然后对机器学习模型的应用场景进行分析,最后基于Otter⁃Tune 系统设计实验,对PostgreSQL 关系数据库进行自动化参数调优实验。
1 数据库自动调参系统介绍
数据库自动调参系统通常包含客户端和服务端两个部分。客户端安装在DBMS 所在机器上,负责收集DBMS的统计信息,并上传至服务端。服务端一般配置在云服务器上,负责训练机器学习模型并推荐参数文件,客户端接收到推荐的参数文件后将其配置到目标DBMS 上,评测其性能,直到用户对推荐的参数满意为止。
1.1 客户端
客户端通常由控制程序和驱动程序组成。控制程序通过访问目标数据库收集DBMS 的各种配置参数和度量(吞吐率、响应时间等)数据;驱动程序则负责实现客户端的所有控制流,主要与服务端进行交互。
客户端组件工作流程如图1 所示,具体为:
(1)驱动程序首先清除缓存并重启DBMS,检查磁盘使用量是否过多,确保控制程序可以收集数据。
(2)工作负载生成,驱动程序启动工作负载,并作为后台作业运行。当准备开始测量时,驱动程序向控制程序发送一个信号,并等待基准完成。
(3)在测量前,控制程序首先收集旋钮和度量数据。
(4)完成工作负载测量后,驱动程序向控制程序发送终止信号,控制程序再次收集数据。控制程序将所有收集到的数据以及元数据摘要(数据库名称和版本、观察长度、开始/结束时间、工作负载名称)发送回驱动程序。
(5)驱动程序将控制程序收集到的所有DBMS 数据上载至服务器,并定期检查服务器是否已完成推荐的新配置。
(6)如果服务端已成功生成下一个配置,驱动程序将从服务端查询新配置并将其安装至目标DBMS。
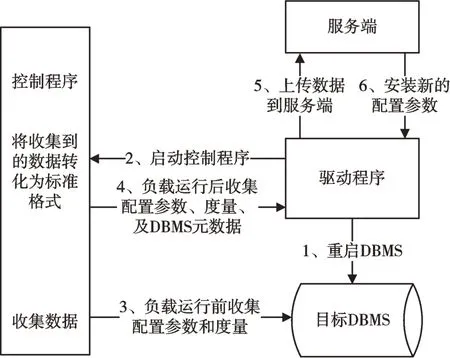
Fig.1 Client side workflow图1 客户端工作流程
1.2 服务端
服务端通常由调优管理和作业调度两部分组成。调优管理负责处理和存储调优数据,并可视化每个调优会话的结果;作业调度负责计算机器学习模型并提出配置建议。
如图2 所示,当调优管理从控制器接收到目标DBMS的数据后,首先将这些信息存储在数据存储库中,然后在前端可视化结果。作业调度负责调度任务,以便在机器学习管道中重新计算模型,将新的数据合并到机器学习模型中,计算DBMS 要尝试的下一个配置。任务完成后,调优管理将任务状态返回给客户端,客户端根据链接下载下一个推荐配置。

Fig.2 Server side workflow图2 服务端工作流程
2 自动调优方法框架
从调优会话中收集到的数据需要使用机器学习模型进行处理,如图2 中的作业调度模块所示,数据应用场景为工作负载特征化、特征选择与自动调优算法。
2.1 工作负载特征化
通常使用DBMS 内部运行时的度量数据描述工作负载行为,因为它们捕获了数据库运行时方方面面的信息,能够提供工作负载的准确表示。然而,不同DBMS 提供的度量具有不同的名称和粒度,有些度量是重复的,有些度量高度相关。修剪冗余度量能够减少机器学习算法的搜索空间,降低机器学习模型的复杂性,加速整个调优过程。因此,有必要使用因子分析方法将高维度量指标转换为低维数据,然后通过聚类算法从每个集群中选择一个具有代表性的度量,即最靠近集群中心的度量,组成机器学习模型训练需要的特征向量。
2.2 特征选择
DBMS 有数百个配置参数,需要找到最能影响其性能的配置参数。使用特征选择技术(例如lasso)对配置参数的重要性进行排序,可确定哪些配置参数对系统整体性能的影响最大。在提出配置建议时,还需决定使用多少个配置参数。使用过多参数会显著增加优化时间,过少则会妨碍找到最佳配置。为自动完成该流程,推荐使用递增的方法,即逐渐增加调优会话中配置参数的数量。
2.3 自动调优算法
自动调优算法需要识别先前调优会话中与当前工作最为相似的负载。首先确保所有度量标准具有相同的数量级,然后计算当前工作负载与存储库中历史工作负载的差异(如欧式距离),差异值越小表示越相似。
典型的自动调优方法包括:①OtterTune 系统采用高斯过程回归(Gaussian Process Regression,GPR)为工作负载推荐合适的参数,该模型可以预测DBMS 在每种配置参数下的性能,在推荐过程中,需要平衡探索(获得新知识)和利用(根据现有知识进行决策),否则可能会陷入局部最优而无法达到全局最优;②CDBTune 系统使用深度强化学习算法将数据库的调参过程刻画成强化学习问题,状态即参数文件,动作即调整某个参数的值,而反馈则是当前参数下数据库的性能。其利用深度确定性策略梯度(Deep Deter⁃ministic Policy Gradient,DDPG)算法,最终达到了与Otter⁃Tune 系统近似的调优效果。
3 数据库自动调优实验
采用卡耐基梅隆大学数据库研究组开发的OtterTune系统对PostgreSQL 关系数据库进行自动化参数调优实验。
3.1 实验环境
主机硬件配置:Intel(R)Core(TM)i5-8500U CPU@3.00GHz 处理器,16GB DDR4 内存,240GB SSD 硬盘。Otter⁃Tune 分为服务端和客户端两部分:服务端包含Mysql 数据库(用于存储所有网站数据、调优数据,供机器学习模型使用),Django(前端网站);客户端包含目标DBMS(存储用户的业务数据,支持多种DBMS),Controller(用于控制目标DBMS),Driver(用于调用Controller,入口文件为fabfile.py)。
软件环境搭建步骤为[10-13]:
(1)准备两台Ubuntu18.04 的虚拟机,配置均为4 核心CPU,4GB 内存,40G 硬盘。一台用作服务端,另一台用作客户端。
(2)配置好网络连接。
(3)服务端、客户端分别下载最新版OtterTune,按照官方配置安装好必要的软件包。
(4)OtterTune 需要Python3.6 版本以上配置,而Ubun⁃tu18.04 系统安装的是Python2.7 和Python3.6,默认使用Py⁃thon2.7,因此需要通过ln-s 软连接命令,修改系统默认使用Python3.6。
3.2 服务端配置
S1:安装Mysql,新建名为ottertune 的数据库。
S2:编辑配置文件,修改credentials.py 文件,并更新数据库名称、用户名和密码等信息,设置DEBUG=True。
S3:配置Django 网站后端,将需要的表放进MySQL 的ottertune 数据库内。创建Django 网站的超级用户,在MySQL 的ottertune 数据库中建立数据表。值得注意的是,website_knobcatalog 和website_metriccatalog 两个表中存储了待观测的信息。
S4:启动Celery(用于调度机器学习任务)和Django Server,完成后通过浏览器打开http://127.0.0.1:8000,在其中建立一个tuning session,并记下upload_code,使用celery beat 启动周期任务。
3.3 客户端配置
C1:安装PostgreSQL9.6(作为目标DBMS),安装成功后会自动添加一个名为postgres 的系统用户,密码随机,然后在postgres 用户中新建名为tpcc 的数据库,供oltpbench 用。
C2:下载最新版OltpBench Repo(数据库测试框架),同样存储在用户根目录下。编辑tpcc_config_postgres.xml,配置oltpbench(用于周期性地在目标DBMS 上运行bench⁃mark)。
C3:配置Controller、Driver,编辑sample_postgres_config.json,driver_config.py,填入目标DBMS 类型、用户名、密码、oltpbench 路径、配置文件等信息。对于save_path 这一项,要事先建立好对应的文件夹;对于upload_code 这一项,要与S4 中分配的upload_code 一致。
C4:加载初始化oltpbench 数据到目标DBMS(Post⁃greSQL)中。
C5:编译Controller,执行gradle build。
C6:在完成上述步骤后,开始运行循环程序。在每个循环中收集目标DBMS 信息,上传至服务端,获取新的推荐配置,安装配置并重启DBMS,直到用户对推荐的配置满意为止。在驱动程序文件otertune/client/driver/fabfile.py 中定义loop 函数,fab loop:i=1 表示运行一个单循环,fab run_loops:max_iter=10 表示运行10 次循环,可通过修改命令中的数字更改迭代次数。
3.4 实验效果
实验环境配置完成后,通过浏览器打开网站主页,使用S3 步骤设置的超级用户账户进行登录。登录成功后首先需要创建一个新的project,然后在项目中创建session。
实验过程按照“3.2”和“3.3”小节中S1、S2、C1、C2、C3、C4、C5、S3、S4、C6 的顺序执行即可。实验结果如图3 所示,可以看出session 的参数以及工作负载情况。在刚开始运行时,数据比较少,机器学习模型缺乏足够的训练数据,Ot⁃terTune 倾向于探索而非利用,生成的配置参数可能是随机的,因此系统的吞吐率较低,为个位数。但当服务端配置到云上,有多个客户端访问时,OtterTune 会将所有用户尝试的参数文件和对应的性能数据存储起来进行利用。这意味着用户越多,使用的时间越长,收集的训练数据越多,推荐效果就会越好。从图3 中可以看出,经过10 轮周期的调整,OtterTune 生成的最佳配置使得系统的吞吐率显著提高,达到了百位数级别,几乎与数据库管理人员的经验配置一样好。
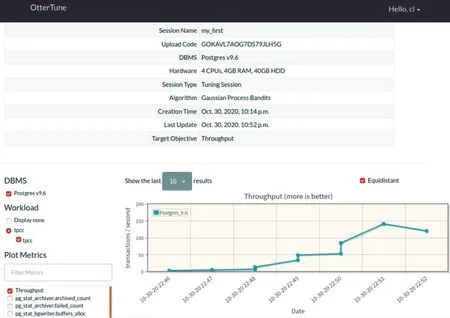
Fig.3 Operation effect of parameter adjustment experiment图3 调参实验运行效果
4 结语
本文详细介绍并采用实验验证了基于机器学习的数据库自动调参系统的原理与运行机制,取得了较佳的配置效果。对于数据库领域来说,很多配置工作可尝试与机器学习结合,参数文件调优只是其中一小部分,还可以发展到更核心的部分,如学习型数据库索引[14]、优化器查询优化[15]等,可以作为今后的研究方向。此外,由于自动调参系统与数据库交互的只是一个参数文件,理论上也可以用于其他系统的调参,例如调优操作系统的内核参数,亦可取得不错效果。
