基于子空间K 均值聚类的概率配准算法
2021-11-28汪亚明韩永华
陈 璐,汪亚明,韩永华
(1.浙江理工大学 信息学院,浙江 杭州 310018;2.丽水学院,浙江 丽水 323020)
0 引言
点集配准问题是计算机视觉广泛研究的问题,开发准确的点集配准算法一直都是模式识别领域研究热点[1]。点集配准目标是寻找两组相关点集之间的对应关系,或恢复两组点集之间的转化关系,从而建立两个点集之间的一一映射。根据变换方式不同,可将配准问题分为刚性配准问题和非刚性配准问题两类。刚性配准的变换方式仅考虑平移、旋转和比例缩放。非刚性配准变换方式通常较复杂,难以建模,包含较多的变换参数。在现实世界中,很多问题会涉及到非刚性变换,即面临非刚性配准问题,非刚性配准因为变换模型的未知以及存在大量的变换参数而更具挑战性。
目前,刚性点集配准研究已取得一定成果,迭代最近点(Iterative Closest Point,ICP)算法及它的变体是使用最广泛的方法之一[2]。该算法迭代地建立最近邻点对之间的对应关系并最小化点对距离,但由于其假设目标点集和源点集之间的最近点对相互对应而存在局限性,而算法的收敛性和准确性很大程度上取决于给定点集的相似性,因此易陷入局部极小值;Gold 等[3]为防止陷入局部极小值,提出一种用于确定空间中两个点集的姿态和对应关系的鲁棒点匹配(Robust Point Matching,RPM)算法。该算法应用一种确定性退火方法来凸化它们的能量函数,但RPM 算法仅限于仿射和分段仿射映射;由Chui 等[4]开发的薄板样条鲁棒点匹配(Thin Plate Spline Robust Point Matching,TPS-RPM)算法试图解决RPM 和ICP 算法中固有的非刚性映射问题,提出一个通用框架来解决存在异常值和噪声的非刚性配准问题;之后,Myronenko 等[5]提出在刚性和非刚性转换下都能够配准点集的概率方法,称为一致性点漂移(Coher⁃ent Point Drift,CPD)算法。该算法通过估计概率密度函数优化对齐两个点集,通过最大化似然函数寻找最优变换参数,迭代地将源点集的质心与目标点集数据进行拟合[6]。同时,为了保持点集的全局拓扑结构,将中心点作为一个整体进行移动。但CPD 算法中有一个权值参数w 用来预测GMM(Gaussian Mixture Model,GMM)中的噪声水平和异常值数量,是在不明确的约束条件下人工选择的;为了解决这一问题,Wang 等[7]引入一种自动选择w 最优值的算法;另外,为了解决CPD 算法只考虑点集全局结构的局限性,Yang 等[8]提出全局和局部距离薄板样条(Global and local distance thin plate spline,GLMDTPS)非刚性点集配准算法。该算法基于全局和局部特征进行对应关系评估,全局和局部特征通过确定性退火技术融合为混合特征;在Ge 等[9]提出的全局—局部拓扑保持(Global-Local Topology Preserva⁃tion,GLTP)算法中,增加了一种局部描述符,称为局部线性嵌入(Local Linear Embedding,LLE),以保持两个点集之间的局部结构。在概率非刚性配准算法中,一个常见的问题是不准确的对应估计很容易导致优化过程陷入局部最优。
针对非刚性配准算法准确性较低问题,本文提出一种基于聚类的概率配准算法。该算法在基于GMM 的CPD 算法的配准框架下,在初始阶段对点集聚类,将聚类中心的对应关系投影到两个点集的对应关系,最后将配准框架结合局部拓扑保持得到最终配准结果。基于GMM 的点集配准算法目标是对齐两个高斯混合函数并优化它们之间的统计差异。当前先进的点集算法大多基于GMM[10-11],原因有3 个:①现实问题可以有效地建模为GMM;②GMM 更容易解释和表达;③低维点集存在闭式解,从而使算法的效率更高。另外,由于本文提出的算法通过聚类大量减少了初始配准点集数量,从而提高了配准速度,与此同时保持了局部拓扑结构,使配准具有收敛更快、精度更高等特点。
1 基于聚类的概率配准算法
基于聚类的概率配准算法研究关键是通过将聚类投影和局部拓扑保持融合到基于高斯混合模型的概率配准框架中,从而解决点集配准算法中准确性不足的问题。首先对两个给定点集分别进行聚类,对聚类中心进行配准,之后将聚类中心的对应关系投影到点集中,最后进行局部结构保持的配准。下面先介绍通用的基于高斯混合模型的点集配准框架,在此基础上给出聚类对应投影方法,最后介绍局部结构拓扑保持。
1.1 基于高斯混合模型的点集配准框架
基于高斯混合模型的点集配准框架将两个点集的对齐问题视为概率密度估计问题,其中一个点集表示高斯混合模型的各个分模型,即高斯模型的均值,另一个点集表示为数据点,通过不断重置质心位置进行配准。
给定两个点集XN×D=(x1,…,xn,…,xN)T,YM×D=(y1,…,ym,…,yM)T,D是点集中点的维数,N是X点集的点个数,M是Y点集的点个数。点集Y中的点作为GMM 的均值,点集X中的点作为GMM 生成的数据点。每个GMM 分模型的概率密度为:
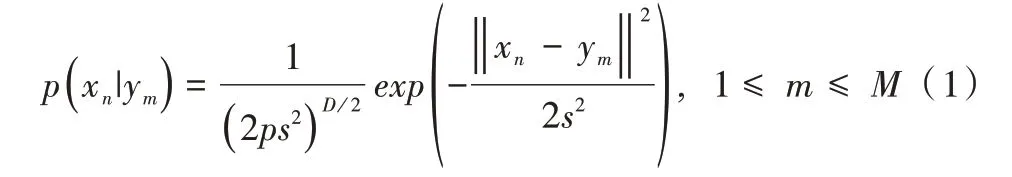
假设所有的高斯分量独立分布且具有相同的方差,并且对每个分量的概率相同。考虑到数据中存在噪声和异常值,在混合模型中引入一个额外的均匀分布p(x|M+1)=。此时,点xn的GMM 概率密度函数为:
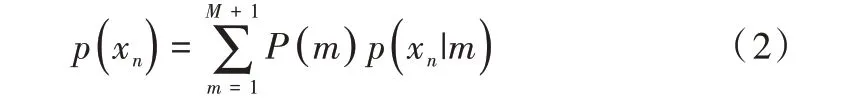
结合两种概率分布,使用参数ω(0 ≤ω≤1)对两种分布进行加权,则混合模型的概率密度函数为:
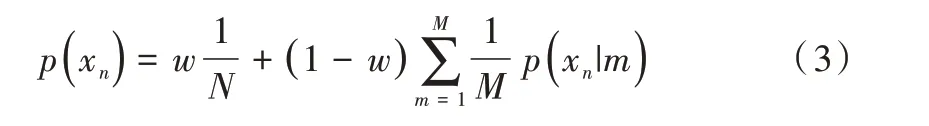
点集配准利用最小负对数似然函数方法不断重置GMM 的均值,此时方差也随着均值位置的改变而发生变化。设θ为GMM 均值改变的转换参数,则负对数似然函数可以写作:
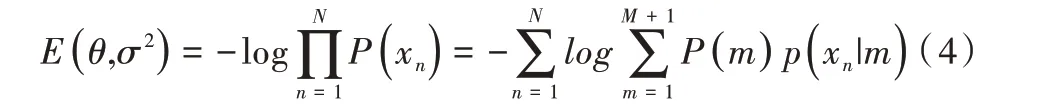
通过最大期望(EM)算法计算得到所需要的参数(θ,σ2),使负对数似然函数达到最小。
将ym和xn两点之间的关联系数定义后验概率:
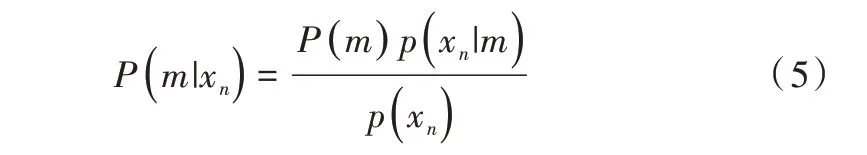
求解Pold(m|xn)就是EM 算法的E-step,M-step 利用求得的后验概率求解新的参数值使目标函数Q最小化[12],即:
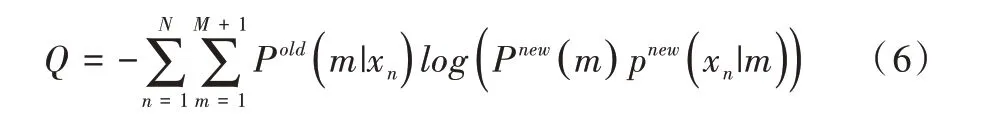
EM 算法在E-step 和M-step 之间交替进行,直到收敛。
根据概率密度函数,可以将目标函数改写为与参数相关的形式,即:
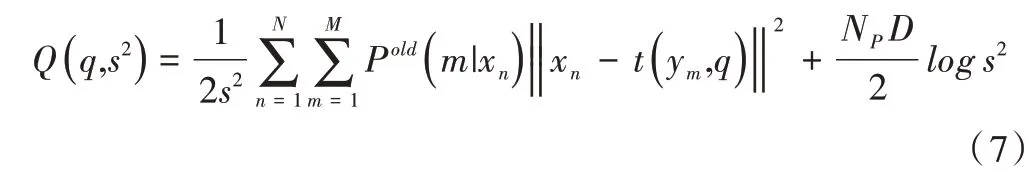
后验概率密度函数为:
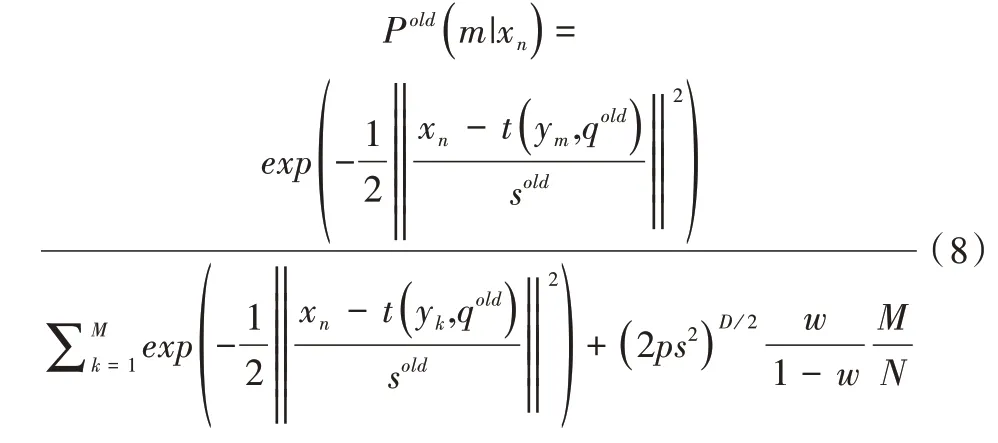
后 验概率矩阵PM×N正是对应关系矩阵,矩阵PM×N中每个元素代表ym和xn两点之间的关联系数。
1.2 聚类及聚类对应投影
当两个点集基数变大、点对应矩阵的维数变大时,点对应关系的求解效率就会变低。所以先通过聚类寻求问题的近似解。主要思想是将两个点集分别聚类,用两个点集的聚类中心之间的对应关系替代两个点集之间的对应关系,从而用聚类中心对应投影问题代替点对应投影问题[13],最后将聚类对应投影结果转换回点对应。
经实验,在各种聚类算法中,子空间K 均值聚类[14]配准精度更好,因此本文运用子空间K 均值聚类算法将X点集聚类成a个簇,表示为,将Y 点集聚类成b个簇,表示为。另外,用xk表示X点集中k簇的聚类中心,用yl表示Y点集中l簇的聚类中心。对两个点集进行聚类之后,对聚类中心进行配准,此时,概率密度函数为:
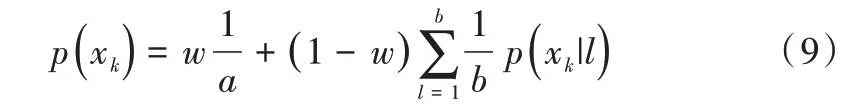
配准之后得到一个矩阵Qk×l,表示两个点集中聚类中心之间的对应关系。qk,l为矩阵Q中的元素,即表示X点集中与Y点集中的对应关系。
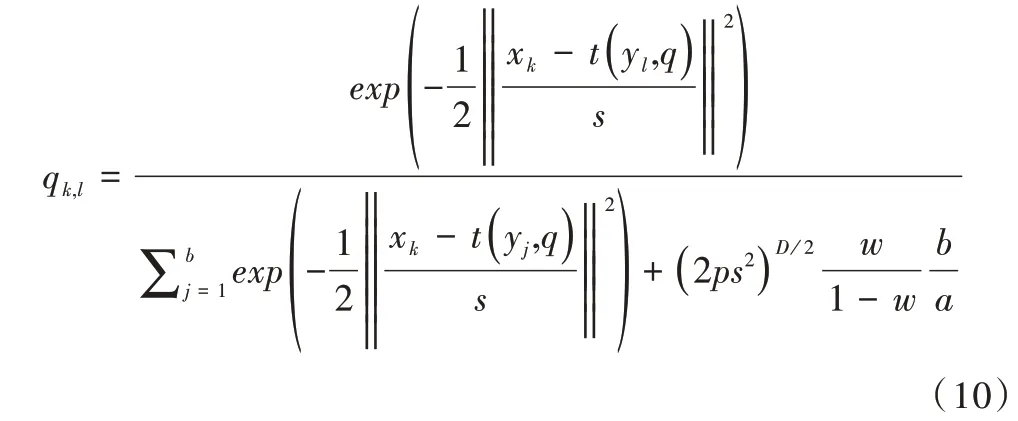
如果点对应P满足点对应矩阵P的约束CP,如,pij≤1,pij≥0,则对P的簇内元素求平均,形成聚类中心对应的Q满足聚类对应矩阵Q的约束CQ,如1 ≤k≤a,1 ≤l≤b;反之,如果聚类中心对应Q满足聚类对应矩阵Q的约束CQ,则Q的元素在相应簇中复制形成的点的对应P也满足点对应矩阵P的约束CP,所以在配准算法中可以通过复制聚类中心对应的中的元素来构造点对应P,即,达到聚类对应矩阵Q投影到点对应矩阵P的效果。
1.3 拓扑结构保持
由聚类对应投影得到点集之间的对应之后,在基于高斯混合模型的点集配准框架中加入局部结构拓扑保持对两个点集进行更精确的配准。
对于非刚性点集数据的配准问题,定义变换关系τ(Y,v)如下:
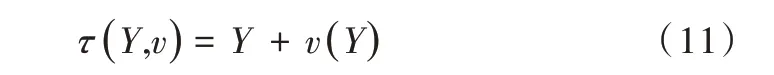
其中,Y表示Y点集的初始位置,v表示位移函数。在非刚性变换情况下,由于没有适当的正则化,配准通常面临不适应问题。运动相干理论(MCT)认为,相邻的点具有相干运动的倾向,因此点集之间的位移函数应该是平滑的。因此,在再生和希尔伯特空间(RKHS)[15]中建立位移函数v的模型,空间平滑正则化定义为v的傅里叶域范数,记为。
将定义的变换及正则化项加入到目标函数中,得到:
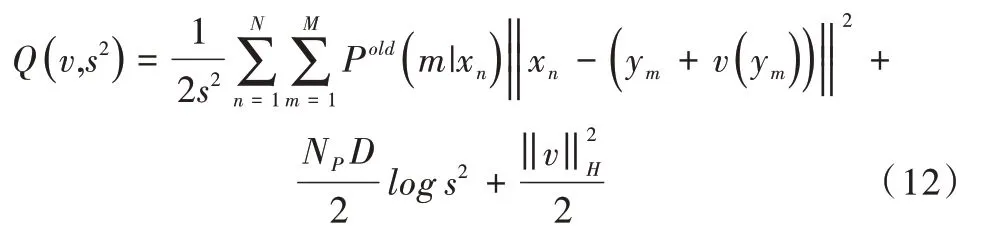
以点集Y为中心的特定核函数K的线性组合,给出使目标函数最小的最优函数v,即:
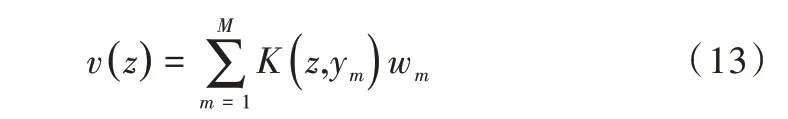
其中,z是点集Y中的一点,wm是待确定的系数向量。通过选择高斯核函数使正则化等价于运动相干理论(MCT),得到Y的变换位置为:

其中,GM×M为核矩阵,WM×D为核的权重矩阵。核矩阵中第i行,第j列的元素表示为,1 ≤i≤M,1 ≤j≤M,β控制局部平滑数量的高斯核大小。
然后对权值矩阵W 进行正则化,以增强运动一致性,并相应地保持全局拓扑:
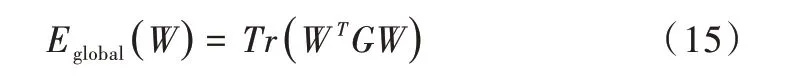
其中tr(·)表示矩阵的迹。保持全局拓扑使得所有的点作为一个整体一起运动。通过这种方式来保持点集的全局拓扑结构,可以保留不同部分的连通性和结合度。
全局拓扑有助于在配准期间保持点集的整体空间连接性,但可能不足以处理详细的局部变形。因此,在保持全局结构的同时还需要保持局部邻域结构并适应不同的局部变形,且能与基于高斯混合模型的概率配准框架相结合,起到互补作用。局部线性陷入(LLE)算法[16]作为一种非线性降维方法在低维潜在空间中保持局部邻域结构。局部结构表示为每个顶点与其预先选定的最近邻之间的空间关系。从高维到低维的映射中,通过共享同一组局部线性重建系数来保持局部结构。
配准时希望Y点集的局部结构经过非刚性变换后仍能保留,应用LLE 思想进行非刚性配准。首先,根据欧氏距离计算Y点集中每个点的K个最近邻;其次,将Y点集中的每个点用其相邻点的加权线性组合表示,通过使成本函数最小化得到权值,成本函数为:
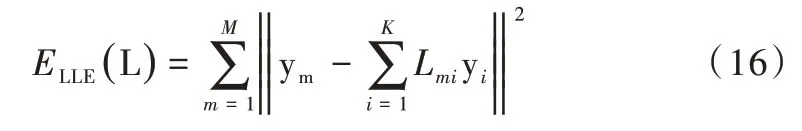
其中矩阵LM×K包含Y点集中每个点的领域信息。
最后由式(16)中定义的权重矩阵W控制非刚性变换后,计算具有相应权值的所有点的总重构误差。为得到最优的W应使代价函数最小:
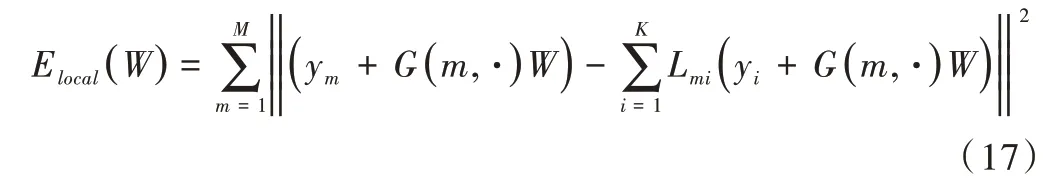
其中,G(m,⋅)表示G的第m行。
利用互补的全局和局部拓扑正则化项,在包含各种局部变形的复杂非刚体变换中保持局部结构和全局连通性。
将点集配准问题视为基于高斯混合模型的正则化密度估计问题。根据目标函数的一般式以及给出的两个保持全局局部拓扑的正则化项,目标函数可以改写成:
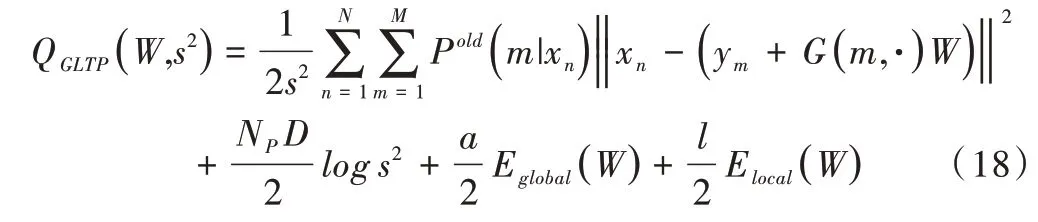
其中,α和λ是GMM 配准项和全局局部两个拓扑项的权衡参数。
1.4 算法
给定X点集和Y点集,对它们进行聚类。先对聚类中心进行配准,找到聚类中心的对应关系,并将对应关系复制到点集的对应关系中。在这一对应关系的基础上,更新Y点集的位置,使X点集和Y点集之间的初始状态更为接近;再结合局部拓扑保持进行配准。算法流程如图1 所示。
2 实验结果与分析
分别对Chui-Rangarajan 合成数据集、斯坦福合成数据集、可变形的三维对象数据集和三维景观人体数据集4 种数据进行以下实验:①三维动物点集[17];②三维头部点集[18];③三维人体点集[19]。然后,将实验结果与现有先进的非刚性配准算法GLTP 进行比较和分析。所有实验的软件环境为MATLAB R2016a,硬件环境为16GB 内存、AMD Ryzen 5 2600 六核处理器。
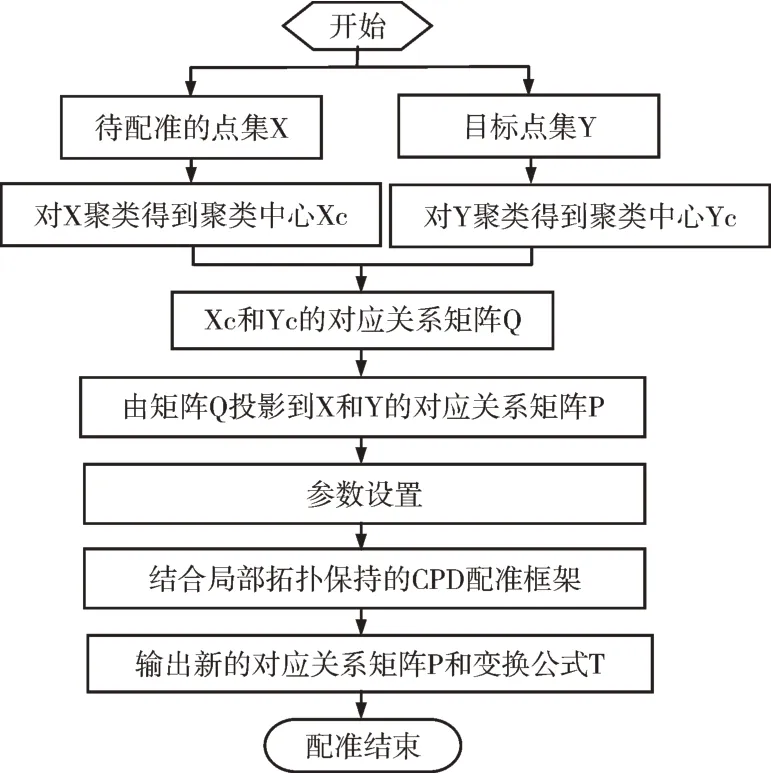
Fig.1 Algorithm flow图1 算法流程
为展示配准过程,首先对大多数点集配准算法都采用Chui-Rangarajan 合成数据中的鱼数据集进行实验。其中,该点集形状模型的模板点集和目标点集的点数相同。首先,分别对模板点集X 和目标点集Y 进行聚类,得到X 点集的簇a 和Y 点集的簇b,对每个簇的聚类中心进行配准。之后将聚类中心的对应关系复制到点集之间的对应关系,最后对点集的对应关系进一步配准并完成配准。配准过程如图2 所示(彩图扫OSID 码可见,下同)。
2.1 3D 动物点集
首先在3D 动物数据集上测试本文算法,该数据集中的点集提取自3D 网格模型。数据集中包含数个动物模型:狮子,包含5 000 个点;猫,包含7 207 个点;马,包含8 431 个点,等等,且每个形状模型的模板点集和目标点集的点数都相同。以猫模型和狮子模型为例对其进行实验。图3 和图4 显示两种模型在不同变形程度下本文算法的配准结果。对于两个不同形变的数据集,本文算法都提供了良好的配准结果,尤其是在高度可变性的四肢和尾巴部分。
采用欧式距离作为配准误差[20]来评价配准算法性能。表1 显示图3 中猫模型在3 种不同形变下GLTP 和本文算法的配准误差对比,表2 显示图4 中猫模型在3 种不同形变下GLTP 和本文算法的配准误差对比,结果表明本文算法更具优势。

Fig.2 Diagram of registration process图2 配准过程

Fig.3 Registration results of different deformable data sets of cat model图3 猫模型不同形变数据集配准结果

Fig.4 Registration results of different deformable data sets of lion model图4 狮子模型不同形变数据集配准结果
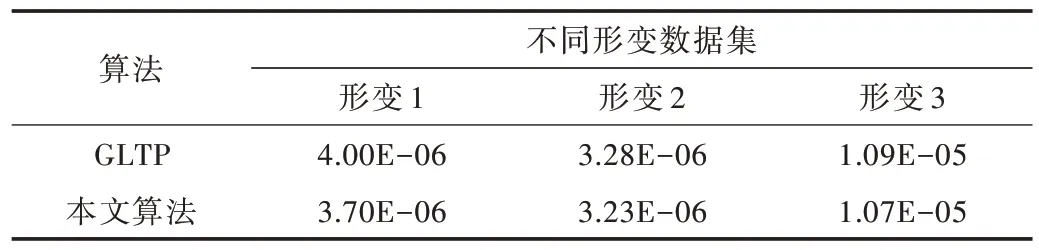
Table 1 Comparison of registration errors of cat model with different deformations at 7 207 points表1 7 207 个点的猫模型不同形变数据集配准误差对比
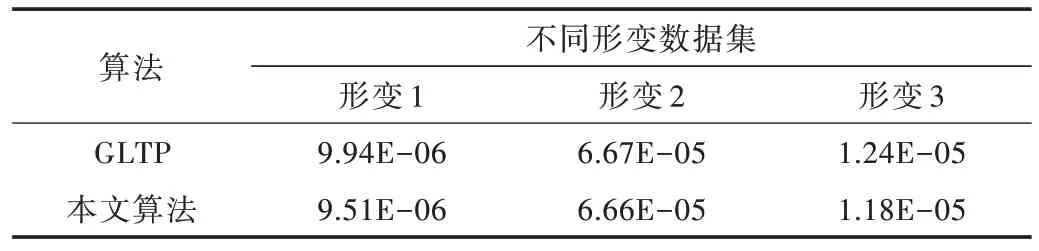
Table 2 Comparison of registration errors of different deformable datasets of lion model with 5 000 points表2 5 000 个点的狮子模型不同形变数据集配准误差对比
除此之外,对本文算法在匹配不完整形状(丢失部分数据)和具有离群值的情况下进行性能评估。图5 为删除了猫模型中尾巴上的部分点,以及在数据集中随机添加一些异常值的配准结果,显示在具有异常值的情况下本文算法仍具有较好的配准结果。
2.2 3D 头部点集
分别在动物头部数据集和人体头部数据集上进行实验。数据集来自斯坦福合成数据集,其中猴子头部数据集的目标点集和模板点集数相同,均为7 958 个点。图6 显示3D 猴子头部数据集在本文算法中的配准结果。
图6 中猴子头部模型展示了良好的配准结果,其中在GLTP 算法中的配准误差是5.55E-05,本文算法中的配准误差是5.51E-05,结果表明本文算法更具优势。
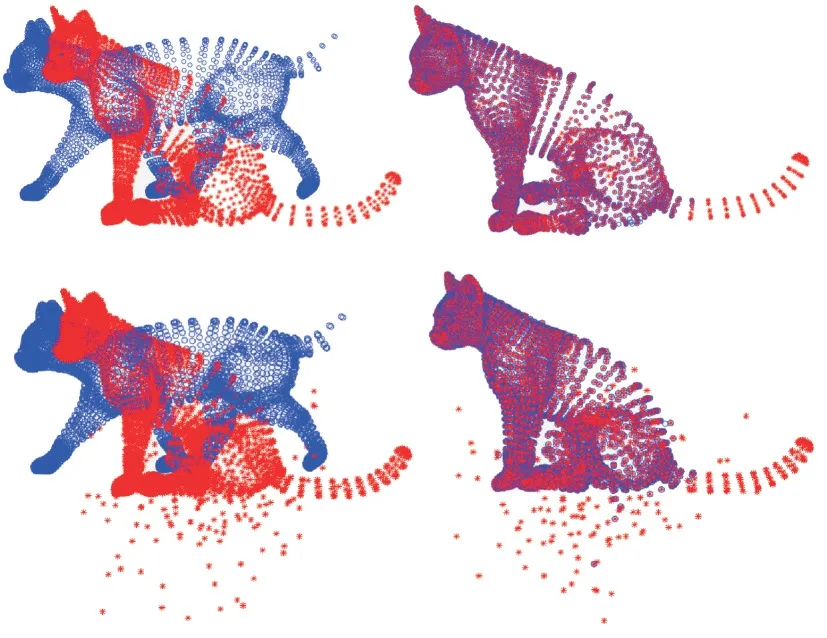
Fig.5 Registration results of point set of cat model with outliers图5 具有异常值的猫模型点集配准结果

Fig.6 Registration results of 3D monkey head dataset图6 3D 猴子头部数据集配准结果
人体头部数据集的目标点集和模板点集数相同,均为15 941 个点,配准结果如图7 所示,头部数据集包含细微的脸部表情,对配准算法有更高要求,结果表明对于头部以及脸部的点集本文算法也有较好的配准结果。
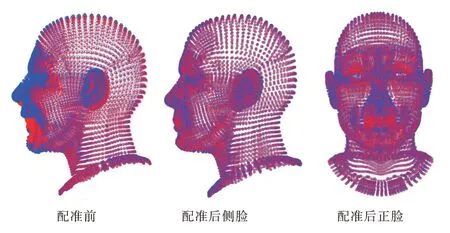
Fig.7 Registration results of 3D head model图7 3D 头部模型配准结果
2.3 3D 人体点集
最后在更具有挑战性的3D 人体数据集上进行实验,其中目标点集数为12 500,模板点集数为2 150,模板点集由人工标记,与目标点集相比具有显著的形状和位姿差异。图8 显示了3D 人体数据集在不同变形程度下本文算法的配准结果。如图8 所示,对于两个不同形变的人体数据集,本文算法都提供了良好的配准结果。
表3 显示了图8 中人体模型在不同形变下GLTP 和本文算法的配准误差对比结果,结果表明本文算法更具优势。

Fig.8 Human body data set registration results图8 人体数据集配准结果

Table 3 Comparison of registration errors of different deformation data sets of human model表3 人体模型不同形变数据集配准误差对比
3 结语
在一致性点漂移(CPD)算法作为配准框架基础上,本文提出了一种新的基于聚类的概率配准算法。该算法能够处理各种二维、三维数据集配准问题。将聚类作为配准的初始化,将投影思想结合到CPD 中,同时引用全局局部拓扑,从而提高了配准算法的配准精度。在不同的二维和三维公共数据集上的非刚性点集配准实验表明,该算法都具有较好的配准结果,优于现有先进算法。后续将在人体姿态估计、三维运动估计等领域应用此算法。
