一种结合Focal Loss 的不平衡数据集提升树分类算法
2021-11-28朱翌民郭茹燕巨家骥
朱翌民,郭茹燕,巨家骥,张 帅,张 维
(上海工程技术大学电子电气工程学院,上海 201620)
0 引言
近年来,不平衡数据集学习成为机器学习领域的研究热点,其是指一个数据集中某类样本数量远小于其他类样本数量,通常将样本数量较多的类别称为多数类(负类),较少的称为少数类(正类)。由于不平衡数据集中样本类别分布的不平衡性,使用传统算法进行分类操作极易导致少数类样本被多数类样本“淹没”,从而使少数类样本被划分为多数类。在大数据时代背景下,不平衡数据分类问题在现实中普遍存在,如网络入侵[1]、电子邮件分类[2]、故障检测[3]、质量检测[4]等。针对银行信用卡系统中存在的欺诈问题[5],文献[6]认为这只是众多交易行为中的冰山一角,正常交易与欺诈交易的数据不平衡问题使得欺诈交易很难被检测出来,但银行需要对欺诈事件作出及时响应,以减少财产损失。在医疗诊断领域,先进的仪器和数据采集技术可产生大量医疗数据,但每种疾病在人群中的发生率差异很大,使得数据集极度不平衡,不平衡数据集的处理对于准确诊断病症十分重要[7-8]。
1 相关工作
针对不平衡数据集分类问题,研究人员提出多种解决方法,主要分为数据重采样、模型改进与算法适应3 种。数据重采样即按照某种特定规则滤除数据集中的多数类样本,或添加少数类样本,从而使原始数据集达到均衡状态。最基本的重采样方法包括随机欠采样(RUS)和随机过采样(ROS)两种,但具有遗漏数据集特征和过于强调同一数据的缺点,可能影响分类器性能。为此,很多研究者提出新的重采样方法,如人工合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE),其通过对少数类进行分析,选取每个少数类样本点,在其他少数类中搜索k 个最近邻样本,并以0~1 之间的采样倍率进行线性插值,从而产生新的合成数据。改进形式的SMOTE 使用每个少数类的欧氏距离调整类别分布,从而在其余少数类样本附近合成新的少数类样本[9]。例如,文献[10]中的Broder⁃line-SMOTE 算法采用最近邻原则将少数类分为safe、dan⁃ger、noise 3 种类型,仅在danger 类型的少数类样本中合成新的少数类样本;文献[11]中的A-SMOTE 算法根据与原始少数类样本的距离调整新引入的少数类样本,向少数类中引入新样本,并消除比少数类更接近多数类的示例;文献[12]利用不平衡三角形合成数据(Imbalanced Triangle Synthetic Data Method,ITSD)弥补SMOTE 线性插值的不足,在数据集特征空间的分类超平面两端取3 个数据点构成不平衡三角形,最大限度地利用了少数类和多数类数据。
模型改进策略则尽可能地保留原始数据的分布特征与数据集的内在结构,通过调整传统分类算法或优化现有分类思想,使其适应不平衡数据集的内在特征,从而提高对少数类样本的识别能力。例如,文献[13]通过聚类算法对数据集进行均衡处理,然后采用AdaBoost 算法进行迭代获得最终分类器;文献[14]通过改进的贝叶斯分类模型将贝叶斯思想引入不平衡分类任务,用类别的间隔似然函数代替后验分布中样本的概率似然函数,优化了分类判别依据,提高了不平衡数据的分类精度。在深度学习领域也有模型改进策略的提出,如Lee 等[15]提出利用经验模态分解能谱数据,然后通过GAN 生成新样本,得到了比传统过采样技术更好的分类效果;魏正韬[16]提出对采样结果增加约束条件,削弱采样对类别不平衡的影响,在保证算法随机性的同时利用生成的不平衡系数对每个决策树进行加权处理;刘耀杰等[17]在构造随机森林算法过程中对处于劣势地位的少数类赋予较高的投票权重,从而提高了少数类样本的识别率。
算法适用则是融合多种方法优点,使其训练出的分类器具有更好的多元性和鲁棒性,代表性算法包括SMOTEBoost[18]、XgBoost[19]、AdaBoost[20]等。
上述文献主要研究了样本数量不平衡的问题,对难易样本的不平衡问题没有进行深入讨论。在模型训练中,如果一个样本可以很容易地被正确分类,这个样本对于模型来说即为易分样本,但模型很难从易分样本中得到更多信息。而被分错的样本对于模型而言为难分样本,其产生的梯度信息更加丰富,更能指导模型的优化方向。在实际训练过程中,虽然单个易分样本损失函数很小,单个难分样本损失函数较大,但由于易分样本占整个数据集的比重极高,易分样本累积起来的损失函数仍会主导损失函数,导致模型训练效率非常低,甚至会出现模型退化问题。因此,本文针对难易样本不平衡问题,提出在提升树模型的基础上结合Focal Loss 损失函数的分类算法,通过Focal Loss 损失函数调整易分样本和难分样本在损失函数中的权重,使模型训练更关注于难分样本。在UCI 和KEEL 数据库中对建立的新算法与Borderline-SMOTE 结合梯度提升树的算法进行了比较,发现新算法虽然对分类精度的提升效果有限,但收敛速度明显提升。
2 算法介绍
2.1 Focal Loss
在目标检测问题中,每张图片可能产生上万个目标候选区,但通常只有少数候选区中含有需要识别的对象,其余部分均为图片背景内容,这便导致了类别不平衡问题。此外,负样本大多是容易分类的,会使模型优化方向背道而驰[21]。使用Focal Loss 损失函数,通过减少易分类样本的权重,使模型在训练时更专注于难分类样本,以达到更高的分类准确率。
对于一般的二分类问题,单样本(x,y)的交叉熵损失函数为:
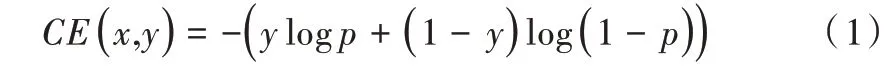
式中,y∈{ 0,1} 为类别标签,p∈[ 0,1 ]为预测样本属于类别1 的概率。
对于不平衡数据集的分类问题,可采用调整多数类和少数类样本权重的方式提高模型对少数类样本的分类效果,表达为:
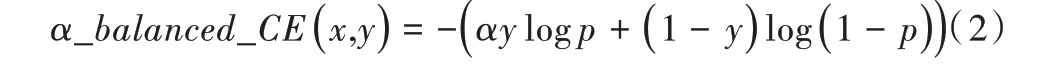
Focal Loss 损失函数调整了易分样本在损失函数中的权重,表达为:
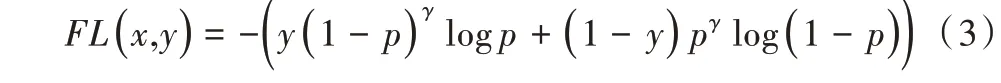
式中,γ为调节系数。对比交叉熵损失函数可以看到,Focal Loss 可在训练过程中动态调整易分样本与难分样本在损失函数中的权重。
2.2 提升树
提升树是一种Boosting 算法,采用的基函数为决策树的加法模型,通过前向分布算法获得新的弱学习器,将每一步的回归树组合起来,即可得到满足需求的强学习器[22]。

当损失函数取平方差损失和指数损失时,每一步迭代的优化都相对简单。但对于一般损失函数而言,每一步的优化通常较难计算。针对该问题,Freidman[23]提出梯度提升算法,通过损失函数的负梯度在上一步迭代得到的学习器下的值拟合回归树。
3 结合Focal Loss 的不平衡数据集提升树分类算法原理与步骤
一般情况下,在分类模型任务中,模型性能的优劣与数据集中各类别样本的分布特性有很大关系。在不平衡数据集中,可以根据正负、难易两种标准将样本分为4 种类型,分别为易分正样本、难分正样本、易分负样本、难分负样本。采用梯度方法训练模型时,虽然每个易分样本产生的梯度均较小,但由于数量较多,最终还是会主导梯度更新方向。在提升树中引入Focal Loss 损失函数,降低易分样本在训练中的权重,使其更关注能有效指导模型优化方向的难分样本,从而提高算法的收敛速度。此外,由于难分负样本占所有负样本的比例较小,可降低样本的不平衡程度,一定程度上提高不平衡数据集的分类准确率。
为得到提升树中叶子结点每次迭代更新的权值,假设输入为x,二分类问题的标签为y∈{ 0,1},提升树分类模型为,第m 轮迭代时学习到的提升树基函数为,则学习 到的提升树为:
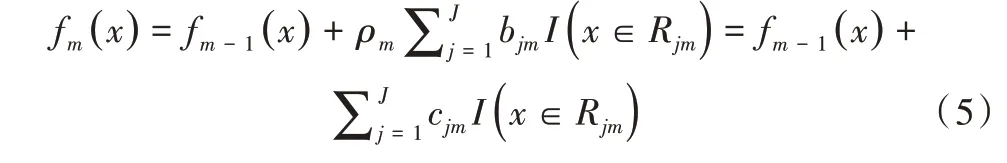
通过牛顿法可得到式(5)的近似解,即叶结点的权值为:
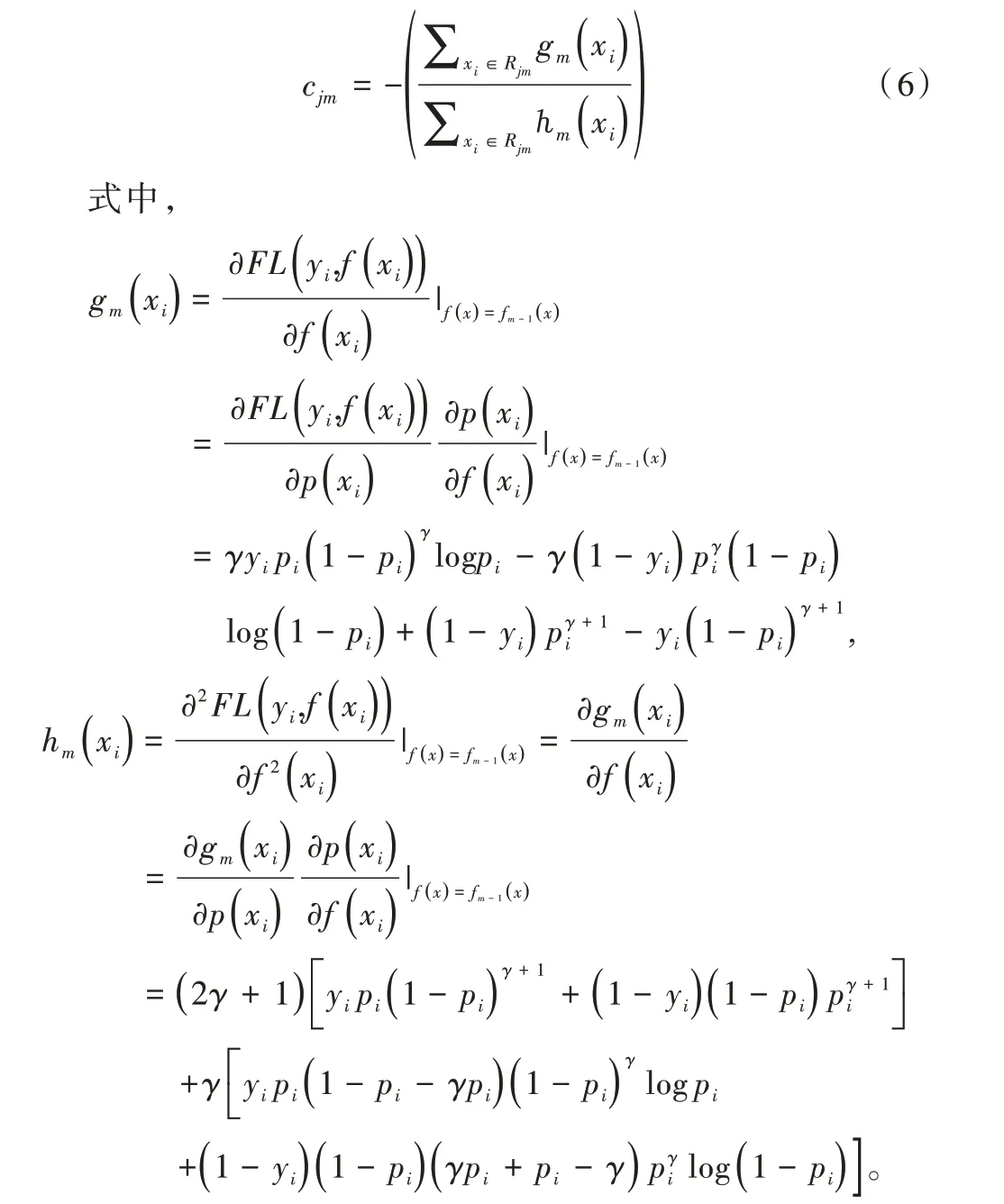
根据上述计算,得到本文算法的具体步骤如下:

b)更新每个叶结点的输出值cjm;
(3)最终的提升树为fM(x)。
4 实验结果与分析
为验证该模型的有效性,选择来自不同领域的3 组数据集,与Borderline-SMOTE 以及随机森林算法进行比较。实验硬件环境:Win10 系统、16GB 内存以及Core i5 处理器;软件环境:Python3.7。
4.1 数据集
使用来自UCI 与KEEL 数据库的3 组数据,数据集具体信息如表1 所示。其中Number 表示数据集的样本总数,At⁃tributes 表示样本特征数量,Minor/Major 表示正类/负类,IR表示数据集的不平衡度。
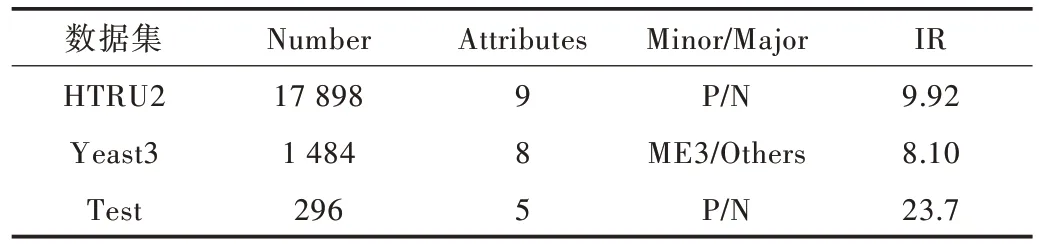
Table 1 Dataset information表1 数据集信息
4.2 评价指标
在不平衡数据分类中,单纯使用准确度评估算法的优劣已不再适用。当数据集的不平衡率较高时,即使将正类样本全部预测为负类,分类器仍然可以获得很高的预测准确度。因此,本文采用查全率(recall)、查准率(precision)、F1-score 和G-mean 4 个性能度量指标对模型进行评估。以上指标可根据表2 所示的混淆矩阵得到,具体表达如式(7)—式(10)所示。

Table 2 Confusion matrix表2 混淆矩阵
查全率(Recall)计算公式为:
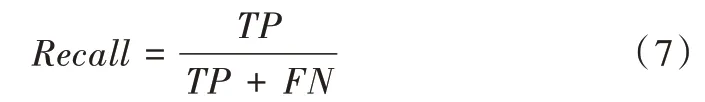
查准率(Precision)计算公式为:
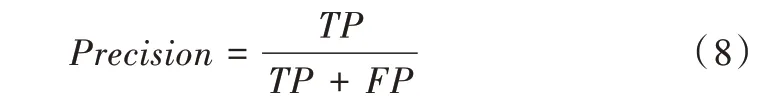
F1-score 计算公式为:

G-mean 计算公式为:
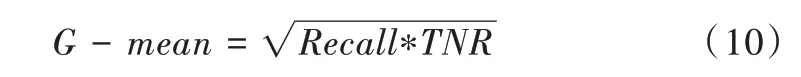
4.3 算法结果比较分析
采用十折交叉验证方法,将数据随机分为10 等份,取9份作为训练集,1 份作为测试集,依次进行实验,10 次实验评价指标的平均值作为1 次十折交叉验证的最终结果。
通过调整Focal Loss 损失函数中的γ值,可以动态调节易分样本与难分样本在损失函数中的权重,从而使模型更专注于难分样本。图1、图2 分别为在数据集HTRU2、Yeast3 上,不同γ值下训练损失随迭代次数的变化情况。可以看到,随着γ值的上升,模型收敛速度明显加快。由图1 可知,当γ=2 时,数据集HTRU2 在第13 次迭代就接近收敛;当γ=1 时,需要约16 次迭代;当γ=0 时,则需要20 次以上迭代才逐渐收敛。由图2 可知,当γ=2 时,数据集Yeast3 只需要14 次迭代便接近收敛;当γ=1 时,需要20 次迭代;当γ=0 时,则需要20 次以上迭代才逐渐收敛。
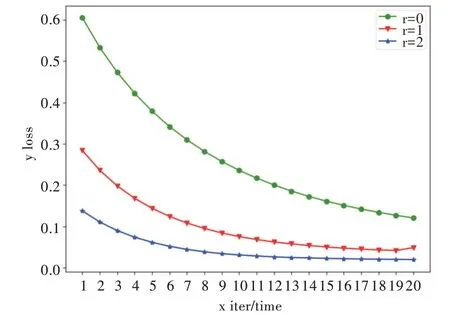
Fig.1 Change of training loss with the number of iterations under different γ(HTRU2)图1 不同γ 值下训练损失随迭代次数的变化(HTRU2)
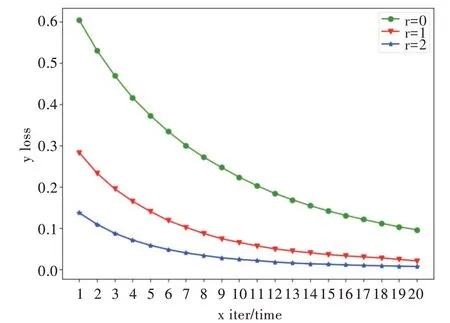
Fig.2 Change of training loss with the number of iterations under different γ(Yeast3)图2 不同γ 值下训练损失随迭代次数的变化(Yeast3)
在数据集HTRU2 和Yeast3 上改变Focal Loss 的调节参数γ,采用Recall、Precision、F1-score 和G-mean 4 个指标评价不同γ 值下的分类器性能,实验结果如表3 所示。Test 数据集的数据量过少,很容易产生过拟合,因此并没有加入对照。采用Borderline-SMOTE 结合随机森林的分类算法作为对比,首先对不平衡数据集进行过采样,获得平衡数据集后再使用随机森林进行分类,实验结果如表4 所示。本文算法在Recall、Precision 和F1-score3 个指标上表现较佳,但与对照算法相比优势并不显著。在HTRU2 数据集上,本文算法F1-score 最佳值为0.970,而Boderline-SMOTE结合随机森林算法的F1-score 为0.972,相差甚微。因此,单纯改变模型中参数γ的值对分类效果的提升有限。
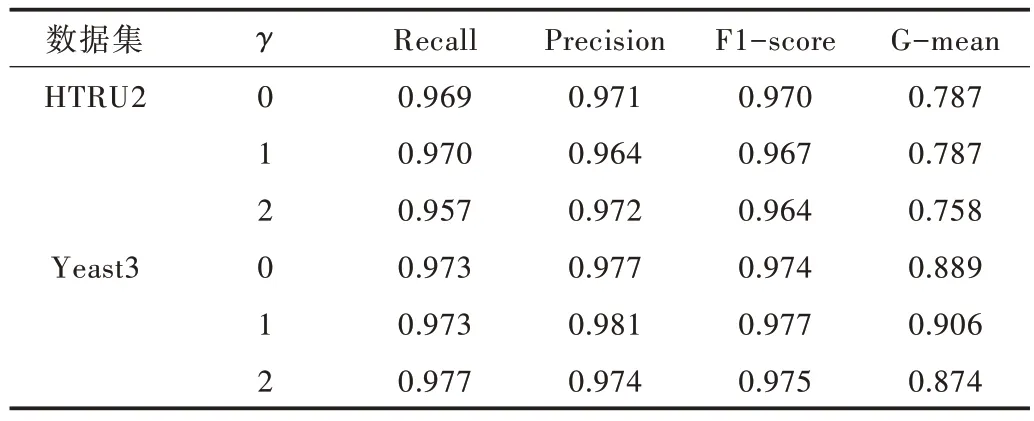
Table 3 Classification results of established algorithm under different γ表3 不同调节参数γ 下本文算法分类结果
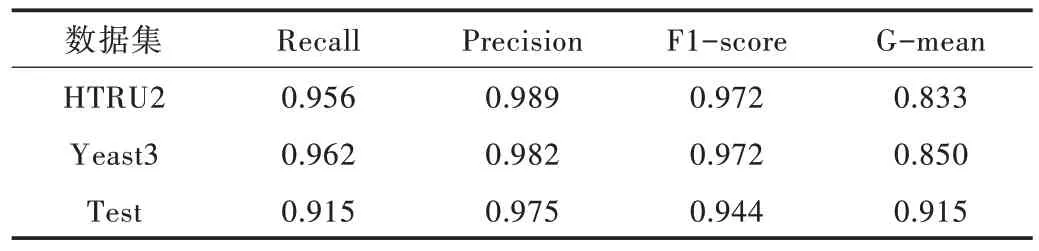
Table 4 Classification results of Boderline-SMOTE with gradient boosting tree表4 Boderline-SMOTE 结合梯度提升树分类结果
5 结论
针对分类任务中的类别不平衡问题,本文提出结合Fo⁃cal Loss 损失函数的梯度提升树算法,在数据集上进行验证实验后发现调整权重γ值可大幅提高算法的收敛速度,但对不平衡数据集分类效果的提升较为有限。后续可尝试在损失函数中加入平衡因子以提升算法的性能。此外,本文主要讨论了二分类问题,今后可针对多分类问题进行探讨。
