基于目标检测的鲁棒视频跟踪技术研究
2021-11-28王正华
郭 睿,蓝 龙,王正华
(国防科技大学 计算机学院,湖南 长沙 410073)
0 引言
视频目标跟踪是一个具有较大挑战性的计算机视觉研究方向,也是计算机视觉应用领域的基础性研究内容,在众多社会生产实践中有着广泛应用,如视频监控、智能机器人、无人机等。视频目标跟踪旨在根据初始视频帧中给定感兴趣物体的初始位置信息,在后续视频帧中连续锁定该物体,即给出该物体在后续视频帧中的位置信息。近年来,深度学习技术取得了长足发展,成为计算机视觉领域的关键技术之一,极大地推动了视频目标跟踪技术的进步,且显著提高了视频目标跟踪效果。然而,在面对诸如遮挡、模糊等复杂的视频应用场景时,设计一个具有高鲁棒性的视频目标跟踪器仍具有很大的挑战性。
视频目标跟踪的核心在于如何根据外观及运动推测信息有效地检测目标,并连接视频帧序列中的已检测目标,从而获得稳定、健壮、平滑的跟踪轨迹。视频目标跟踪主要包括针对多目标的跟踪以及针对单目标的跟踪两个方向。多目标跟踪是跟踪领域中一个更复杂的研究方向,相比单目标跟踪,多目标跟踪还需要正确识别不同视频帧中的目标ID[1]。本文中提到的跟踪都为单目标跟踪。
视频目标跟踪与目标检测、视频目标检测有着紧密联系。目标检测是将单张图片作为研究对象,对图片中所有感兴趣的物体进行检测,给出待检测物体的位置信息和类别信息。由于目标检测仅依赖单张图片中的信息,相比于视频目标检测,目标检测的性能仍然受到一定限制。视频目标检测利用待检测目标在连续视频帧中的时序相关性,能够显著地提高检测性能,甚至在模糊、遮挡等场景下也能较准确地输出检测结果。视频目标检测与视频目标跟踪在研究目的上存在交集:二者都需要在视频帧中准确给出感兴趣物体的位置信息。如果不考虑输出感兴趣物体的类别信息等,而仅是研究视频帧中感兴趣物体的位置信息,视频目标检测与视频目标跟踪没有明显区别。
传统的视频目标跟踪根据第一帧中给定物体的初始位置对后续视频帧中感兴趣的物体进行位置预测,跟踪器在后续帧中根据物体的外观特征与前序帧的运动信息预测感兴趣物体位置。这种类型的方法往往更关注跟踪器速度,通常应用于简单的场景中。但现实中更多不可预知的情况会显著降低视频帧质量,如视频帧中物体间的遮挡、模糊,待跟踪物体尺寸大小和外观在不同帧中的变化以及光照影响等[2]。对于传统跟踪算法,预测待跟踪目标的位置信息主要取决于特征信息丰富与否,而上述因素会显著削弱神经网络对待跟踪目标的特征提取能力,进而造成包括目标颜色、纹理等诸多特征信息的缺失,以及前后背景差异的减小,容易导致目标跟踪错误或丢失;特征信息的突变也极易造成跟踪结果漂移,从而很大程度上影响最终的跟踪效果。为设计出更健壮的跟踪器以解决这些问题,研究者们提出一些新算法。对于目标跟踪而言,更多特征信息即意味着算法拥有更多输入信息,因而能有效提升跟踪效果。如文献[3]提出Gradient-Guided 网络并将其应用于跟踪领域,利用梯度信息得到更丰富的特征信息;文献[4]提出基于子帧分析的方法以减少运算的高开销,其将视频帧分成若干子帧,通过对每一个子帧中的目标进行检测,再对检测结果进行后处理以达到跟踪目的,从而实现了将跟踪算法部署在低算力设备上的可能。
文献[5]引入SA-Siam 网络以提高实时跟踪性能,网络结构包括语义分支和表观分支,两个分支相互作用以提升跟踪效果;文献[6]提出Siamese-RPN 算法,RPN 概念首先被应用于检测领域,将其应用于跟踪中,可提高视频目标跟踪性能。然而,这两种方法都忽略了视频中镶嵌在前序帧序列中的信息。从跟踪的另一个方面来考虑,研究视频目标跟踪,还在于如何有效利用历史信息提高物体在当前帧的位置预测精度。文献[7]利用RNN 进行跟踪,其基于RNN 对视频中的物体运动进行预测;文献[8]利用STLSTM 实现跟踪,LSTM 按照用途可分为两大类,一类是空间LSTM,用于提取视频帧的空间特征,另一类是时间LSTM,用于获取时间相关变化特征,通过对时空两个维度的研究提高跟踪效果。
由于视频目标检测与目标跟踪在研究目的上的相似性,因此一些视频目标检测研究方法也给视频目标跟踪研究带来了一定启示。文献[9]引入关键帧技术,并在关键帧筛选方面进行创新,取得了理想的视频目标检测效果;文献[10]提出一种STSN 算法,该算法的时空采样模块会根据当前帧的特征图,从临近帧的特征中提取所需特征并进行融合,然后作为检测的输入信息产生检测结果;文献[11]对视频帧进行特征提取得到特征图,根据光流推测的帧间运动信息对临近帧进行warp 操作,并将其与当前帧特征图进行融合;文献[12]从pixel-level 和instance-level 两个角度进行特征对齐,能更好地处理遮挡问题。
2017 年,文献[13]提出目标跟踪算法ROLO,ROLO 是基于YOLO 并将LSTM 引入目标跟踪中的算法。YOLO 是you only look once 的简称,是一个高性能的目标检测算法。ROLO 将YOLO 作为特征提取模块,以生成初始位置信息与当前视频帧的特征信息,并采用目前普遍使用的循环神经网络LSTM,根据特征预测感兴趣物体的位置信息。RO⁃LO 从时间和空间两方面研究跟踪,该思想也被广泛应用于多目标跟踪中[14]。
基于上述算法可得出如下结论,检测器与丰富的历史信息两个因素在视频目标跟踪中起着重要作用。在面对复杂场景时,比如受到物体间遮挡、目标物体外形剧烈变化以及光照等因素影响,由于特征表达的缺失,会导致跟踪算法对目标跟踪丢失或漂移。因此,本文针对目标跟踪问题设计一款基于IOU 匹配的跟踪器,利用检测信息与历史信息,使其在实际跟踪过程中面对复杂场景具有更强的鲁棒性、检测速度更快。
1 相关理论
1.1 检测器
近年来,目标检测同样是计算机视觉领域一个重要的基础性研究方向,因此目标检测技术的发展也经历了从传统到融合深度学习的过程。传统检测器基于滑动窗口选择区域,然后对区域进行特征提取,再使用分类器进行分类,从而达到检测目的[15-16]。然而传统目标检测方法的检测精度仍有较大提升空间,而且基于滑动窗口获取区域会产生巨大的计算开销。随着深度学习的发展,目标检测与卷积神经网络的结合突破了目标检测领域的研究瓶颈,检测效果得到了大幅提高。基于深度学习的目标检测算法有两大分支:①两阶段的目标检测算法,典型代表包括RCNN[17]、Fast R-CNN[18]、Faster R-CNN[19]算法等;②单阶段的目标检测算法,也称为端到端的目标检测算法,典型算法包括SSD[20]与YOLO[21]系列算法,目前众多版本的YO⁃LO 系列算法已广泛应用于检测领域[22-23]。ROLO 采用YO⁃LO 作为特征提取模块,YOLO 是由Redmon 等[21]于2016 年提出的一个端到端的目标检测算法。在该算法中,待检测图片只需被处理一次即能得到物体的位置信息和类别信息。YOLO 的核心思想是把一张图片划分为S*S的网格,每一个小网格负责预测中心落在该网格中的物体。网络以一张图片作为输入,将其大小调整为448*448,经过神经网络的处理,最终输出S*S*(B*5 +C)维度大小的张量。其中,S 一般取7,B 代表每个网格预测的检测框个数(B 一般取2),5 代表检测框的坐标信息、高度、宽度及置信度,C 代表待分类别总数。YOLO 网络包括24 个卷积层,在网络最后有两个全连接层,维度分别为4 096 和1 470。在深度神经网络中,全连接层能融合先前神经网络层的输出,因此全连接层常被应用于分类中。在YOLO 中,网络中的全连接层包含了待检测图片极其丰富的特征信息,因而ROLO采用YOLO 网络中4 096 维全连接层的输出作为重要的特征来源。
1.2 循环神经网络
循环神经网络是一种专门处理序列问题的神经网络,其能充分利用历史信息进行相应运算,因此被广泛应用于自然语言处理与计算机视觉领域。一些研究人员将循环神经网络应用于目标跟踪中,如文献[24]采用循环神经网络进行多人跟踪。LSTM(Long Short-Term Memory)是一种特殊的循环神经网络,其可以克服循环神经网络梯度消失的缺陷,因此在处理长序列问题时具有独特优势[25]。通常而言,循环神经网络有两类输入,x 与h,x 是当前输入信息,h 是先前循环神经网络单元的输出信息。相比于普通循环神经网络,除x 与h 两类输入外,LSTM 还有一个特殊结构:cell state(c)。LSTM 会根据xt和ht-1的输入决定丢弃一些用处不大的状态信息,在完成丢弃操作后,LSTM 会对状态信息进行更新:将ct-1更新为ct,并将有价值的信息存储进状态中。状态信息的引入极大地提高了LSTM 处理长序列问题的能力。因此,在ROLO 中使用LSTM 预测视频中感兴趣的物体位置。
1.3 ROLO
ROLO 沿用传统的检测—跟踪模式,使用循环神经网络学习历史信息以达到跟踪目的[13]。ROLO 利用LSTM 处理融合特征信息,并对其进行运算。算法主要由两部分组成:第一部分用来提取特征,在该模块中,ROLO 使用YOLO网络提取视频帧特征,ROLO 把重心放在YOLO 网络末端的全连接层上,将全连接层输出的4 096 维度特征与6 维的检测输出结果[class,x,y,w,h,confidence]融合(class 为检测输出的类别信息,x、y 为检测框坐标信息,w、h 为检测框的宽、高信息,confidence 为检测输出的置信度信息),生成4 102 维的特征向量,以其作为LSTM 单元的输入产生最终结果。对于跟踪问题,类别信息和置信度信息不是核心研究目标,因此将6 维特征[class,x,y,w,h,confidence]中的class 和confidence 置零,变为[0,x,y,w,h,0],将4 096 维的特征与调整后的6 维特征拼接在一起成为新的特征向量。第二部分是LSTM 模块,也是ROLO 跟踪算法的核心模块,该部分负责解释融合后的4 102 维度特征向量以产生最终的位置信息。每个LSTM 单元的输入来自于两部分:一是当前视频帧融合后的4 102 维度特征向量,二是LSTM 单元的状态信息。
在训练阶段,ROLO 采用Mean Squared Error 作为损失函数,计算预测的x、y、w、h 与ground truth 中各自对应属性的均方差,采用Adam 方法优化网络,以期获得更优的网络。
针对LSTM,LSTM 单元需要学习来自前序状态中的历史状态信息,因此ROLO 探究了LSTM 单元步长对实验结果的影响。具体而言,ROLO 选取步长为3、6、9 分别进行实验,所有实验都在OTB-30 数据集上展开,以22 个场景的数据集作为训练集、剩余8 个场景作为测试集展开实验。从实验结果来看,步长为6 获得了最好的实验效果。
2 基于IOU 匹配的跟踪器
本节提出一个简单的基于IOU 匹配的跟踪器与ROLO算法进行对比。在跟踪过程中,视频中紧密相连的视频帧仅有非常微小的变化,相应地,待跟踪物体的位置变化幅度也很小。受此启发,本节通过计算当前帧的检测候选框与前一帧跟踪框之间的IOU 预测物体位置。相比跟踪器的位置预测,检测器拥有比跟踪器更精确的位置输出,加上利用前序帧的跟踪结果,从视频首帧层层传递跟踪结果,有效避免了由于特征信息缺失等原因造成跟踪神经网络输入特征信息受限,进而影响最终跟踪结果的情况。该算法在第一帧中使用ground truth 明确指出待跟踪的物体,在剩余帧中使用IOU 匹配策略预测待跟踪物体的位置信息。具体方法如图1 所示。
图1 左侧为输入的视频帧,从上到下依次是视频的序列帧。视频帧首先经过YOLO 检测网络的处理,输出检测到的物体位置信息,绿色检测框即是初始的检测输出。对于t+1 帧,红色跟踪框代表第t 帧的跟踪结果,绿色检测框代表当前帧的检测结果。本文方法就是要从绿色候选检测框集合中选择一个最合适的检测框作为当前帧的跟踪结果。具体筛选流程如式(1)-式(5)所示。
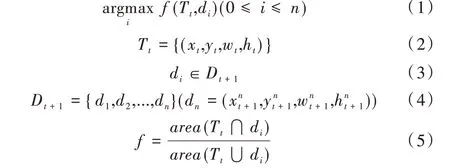
其中,Tt代表第t 帧的跟踪结果,xt、yt、wt、ht代表跟踪框的坐标信息和宽高信息,Tt即是图中的红色框。Dt+1代表第t+1 帧的检测结果(即图中的绿色检测框集合),dn代表检测框集合Dt+1中的第n 个检测框,是第n 个检测框的坐标信息和宽高信息。具体而言,计算Dt+1集中每一个检测框和Tt的IOU 数值,当IOU 数值最大时,选择此时用于计算的检测框作为当前帧跟踪结果。
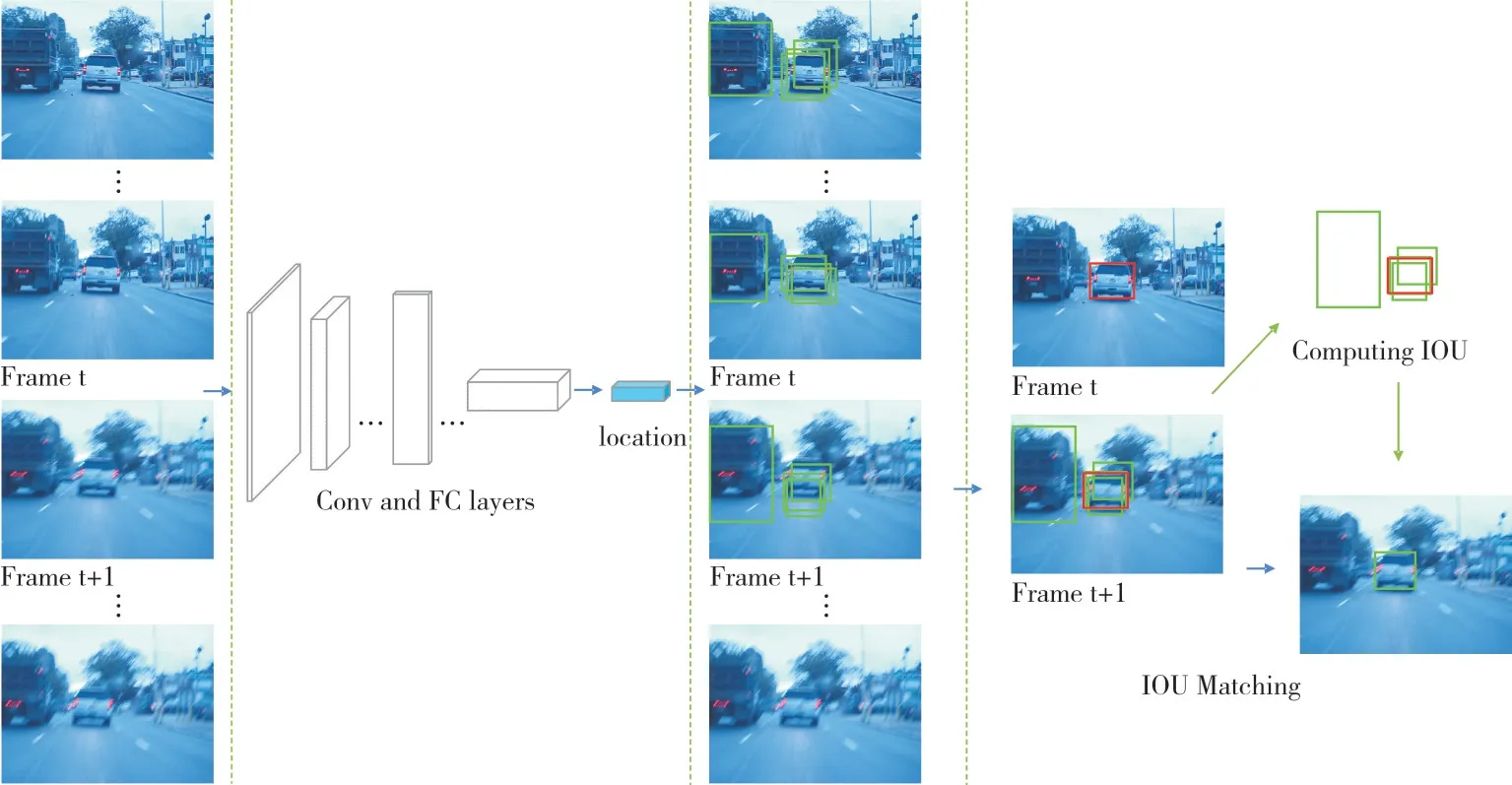
Fig.1 Tracker based on IOU matching图1 基于IOU 匹配的跟踪器
基于IOU 匹配的跟踪器以一段待跟踪的视频作为跟踪器的输入,在视频帧首帧中给出拟跟踪目标的初始位置信息,之后将视频每一帧依次输入网络。首先经过YOLO 检测模块,给出视频帧中的初始检测结果集合,然后以前后紧邻的视频帧为研究对象,关注后一帧的检测结果与前一帧的跟踪结果。具体地,前序帧跟踪结果与当前帧检测结果作为IOU 匹配的输入,按照式(1)-式(5)的IOU 匹配策略从当前视频帧的检测结果集合中筛选出跟踪结果,以此作为当前帧跟踪目标的位置信息,再进行bounding box 输出,将整个视频的跟踪结果依次输出,即达到了跟踪目标对象的目的。
3 实验结果与分析
3.1 实验环境及数据集
本文实验基于Python 与Tensorflow 深度学习框架,在配置有Intel Core i9-9820X CPU 和NVIDIA RTX 2080Ti 的机器上完成。实验选择OTB100 作为测试数据集来源,该数据集包含98 个场景,其中大部分场景都属于复杂场景,如遮挡、形变、尺度变化、模糊等。为与ROLO 进行公平的对比,本文选择ROLO 所用的实验数据集OTB-30 进行实验(该数据集选自OTB100 数据集中比较复杂的30 个场景),文献[13]证实了OTB-30 数据集比OTB100 数据集具有更大的挑战性。
图2 展示了OTB-30 的一些场景,实验中使用bounding box 框定物体来显示跟踪对象。红色框是真实值,绿色框是ROLO 的结果,蓝色框是本文提出跟踪器的结果。
3.2 实验设置
为了与ROLO 进行公平的对比,本文采用与ROLO 相同的实验设置。ROLO 进行了3 组定量实验,一组的实验背景与监控场景有关,另一组实验用来证明训练图片数目对实验结果影响较大,这两组实验对通常意义上的目标跟踪评估参考价值不大。除这两组实验外,另一组实验是常规实验,ROLO 在OTB-30 数据集上选择22 个场景进行训练,并在剩余8 个场景中进行测试。

Fig.2 Qualitative tracking results图2 定性跟踪结果
3.3 定量结果
对于OTB 数据集,最重要的评估指标为success plot。该评估指标反映了跟踪框与真实值之间的重合度,具体如图3 所示(彩图扫OSID 码可见,下同)。其中,横坐标为阈值,范围为0~1。对于范围内的每一个阈值,计算在当前阈值下,跟踪框与ground truth 之间的IOU 超过该阈值的视频帧数量占整个视频帧数量的比例,曲线下方面积即为最终的定量结果。
图3 为实验的success plot 结果,将本文提出的跟踪器与ROLO、跟踪算法FOT(OTB 数据集官网公布的跟踪器)进行对比。实验中,本文按照ROLO 从OTB-30 中选择8 个场景作为测试集,分别为[Human2,Human9,Suv,BlurBody,BlurCar1,Dog,Singer2,Woman](该场景集合称为场景A 集合),可以看出,本文方法在精度上超过了ROLO、FOT。
为避免偶然因素对实验的影响,本文进行了另外一组对比实验,仍然从OTB-30 数据集中随机选择另外8 组场景作为测试集,分别为[Skater,Skater2,Dancer,Dancer2,CarScale,Gym,Human8,Jump](该场景集合称为场景B 集合)。这8 个场景与上一组实验场景完全不同,并且这两组实验测试的16 个场景覆盖了OTB-30 数据集场景的一半以上。
实验结果如图4 所示,本文方法取得了与ROLO 相似的结果。
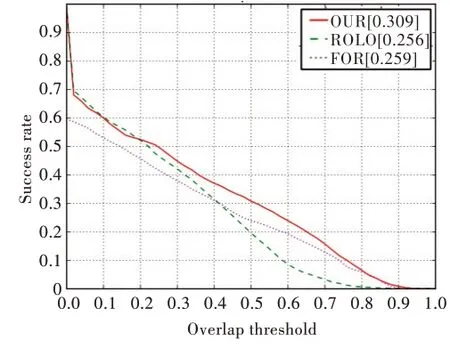
Fig.3 Comparison of tracking algorithms under scene A set图3 场景A 集合下各跟踪算法对比
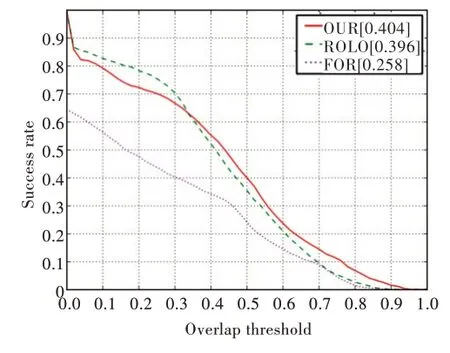
Fig.4 Comparison of tracking algorithms under scene B set图4 场景B 集合下各跟踪算法对比
3.4 消融实验
为探究本文方法在采用不同策略时的性能,设计了两组消融实验,具体如下:实验中通常选择紧邻前序帧的跟踪结果,然而在现实情况下,由于视频帧质量的原因,紧邻前序帧不一定都能稳定输出跟踪结果。为解决该问题,需要继续寻找合理的前序跟踪结果以帮助当前帧输出跟踪结果。特别地,当紧邻前序帧中没有跟踪结果时,依次向前寻找次紧邻帧的跟踪结果,如果都没有跟踪结果,则使用ground truth,上述过程称为策略1(trick1)。本文对应又提出策略2(trick2),针对单目标跟踪,由于待跟踪物体大都是视频帧中最明显的目标,因此在遇到前序帧没有跟踪结果的情况时,选择当前视频帧中置信度最高的检测结果作为跟踪结果,策略2 为前面实验默认的设置。
对于测试集合A,两种策略的对比实验结果如图5 所示,可看出策略1 取得了更好的结果。针对测试集合B,采用两种策略进行了新的实验。实验结果如图6 所示,可看出策略2 取得了更好的结果。
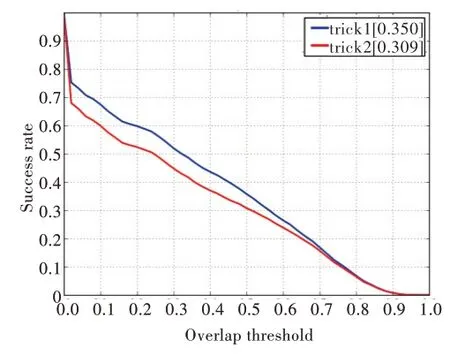
Fig.5 Comparison of two tricks under scene A set图5 场景A 集合下两种策略对比
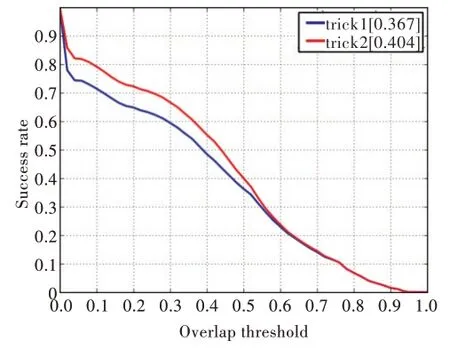
Fig.6 Comparison of two tricks under scene B set图6 场景B 集合下两种策略对比
综合两个实验结果,本文推测两种策略对场景的差异比较敏感。场景A 集合大多属于MB(Motion Blur)属性,而场景B 集合大多属于SV(Scale Variation)属性,两种策略在面对不同属性的场景时,实验结果存在差异。
3.5 复杂场景性能对比
面对复杂场景,如图7(属性为Scale Variation)、图8(属性为Illumination Variation)所示,由于特征信息的突变或缺失,ROLO 算法对目标的跟踪出现了漂移。然而,本文方法依靠检测信息和历史信息,通过检测可给出精确的位置信息,再利用前序的跟踪结果,有效避免了由于特征信息不足导致位置预测的偏离,能够稳定地输出跟踪结果,展示出较强的鲁棒性。

Fig.7 Scene CarScale图7 场景CarScale

Fig.8 Scene Human8图8 场景Human8
3.6 算法效率
本文分析了ROLO 算法与提出的IOU 匹配跟踪器的效率,实验结果表明,ROLO 算法效率为18fps,而本文提出的跟踪器效率达到了65fps,相比ROLO 提高了约2.5 倍,并且算法的运行对运算资源要求较低,可满足实时性以及部署在低算力设备上的需求。
3.7 实验分析
从实验结果来看,本文跟踪器达到了与ROLO 相似的实验效果。本文跟踪器是将YOLO 的检测结果进行后处理,再将经过处理的检测结果连接起来作为跟踪结果,而ROLO 使用LSTM 解释融合特征,进而输出跟踪结果。
通过对二者进行详细分析,本文跟踪器使用YOLO 作为检测模块,检测模块中4 096 维的特征,再经过全连接层处理并输出检测结果,对该结果进行优化处理后即为跟踪结果。ROLO 算法使用LSTM 对4 102 维的融合特征进行解释,然后输出跟踪结果,其采用的融合特征形式为(f1,f2,…,f4095,f4096,0,x,y,w,h,0)。事实上,4 102 维特征由4 096 维特征与6 维特征(4 维的位置信息加上类别、置信度的2 个置零位)拼接而成,而这6 维的特征信息在整个融合特征中占比较低,与4 096 维特征差距微小,两种方法取得了相似的实验结果,因此本文推测ROLO 中使用的LSTM 起到了全连接层的作用。
在运算开销方面,ROLO 算法在训练阶段首先需要输出所有训练视频帧在YOLO 中的特征提取结果,再以其作为输入来训练LSTM,过程较为复杂,并且使用LSTM 处理4 102 维度特征,运算过程开销巨大,难以部署在低算力设备上。而本文提出的跟踪器运算开销较小,运算速度较快,适合部署在低算力设备上。
4 结语
本文探究了ROLO 跟踪算法,指出ROLO 算法虽然取得了一定效果,但其在复杂视觉场景下鲁棒性不佳,因此提出一款基于IOU 匹配的目标跟踪器。为突出该跟踪器在复杂视觉场景下的优异性能,本文使用OTB-30 作为实验数据集,实验所用数据集的30 个场景相比通常使用的OTB数据集具有更大的挑战性。实验结果显示,基于IOU 匹配策略的跟踪器在处理复杂场景下的跟踪问题时,有效避免了因特征信息缺失对跟踪结果造成的较大影响,实验结果具有更强的鲁棒性,且大幅提高了跟踪速度,在对实时性要求较高且算力有限的条件下具有一定应用价值。
