多任务学习的中文电子病历命名实体识别研究
2021-11-28余俊康
余俊康
(广东工业大学 计算机学院,广东 广州 510006)
0 引言
中文电子病历(Chinese Electronic Medical Recode,CEMR)是由医务人员撰写的面向患者个体描述医疗活动的记录,包含患者从入院到出院疾病发生、发展、治疗的全过程,蕴含大量的医疗知识和患者健康信息。中文电子病历命名实体识别任务(Chinese Name Entity Recognition,CNER)指从给定电子病历文本中识别出能表达医疗信息的实体和实体边界信息,是医疗信息抽取的基本任务。
近年来,为了推动中文医疗信息抽取工作,中国知识图谱与语义计算大会(China Conference on Knowledge Graph and Semantic Computing,CCKS)连续几年都组织了中文电子病历命名实体识别评测任务评比,是对于给定的一组电子病历纯文本文档,识别并抽取其中与医学相关的实体,并将他们归类到预定好的类别中。
目前,关于中文电子病历实体识别的研究可分为两大类:
(1)单任务命名实体识别模型,通过提高特征工程质量并修改深度学习模型结构以提升模型性能。Qiu 等[1]将字典和汉字特征投影到向量以增强词汇信息,然后通过残差卷积神经网络训练得到临床医学文本的特征信息;Wang等[2]将具有医学特征的字典融入双向长短期记忆神经网络以处理命名实体识别任务;Li 等[3]将注意力机制融入神经网络以捕捉临床医疗文本的特征信息。上述研究受字典质量影响较大,Li 等[3]减少了字典工作,但其提取的特征信息并不全面。
(2)多任务命名实体识别模型,通过学习多个数据集的特征或学习多个不同类型的任务提升对目标域的识别效果。杨晓辉等[4]提出使用共享LSTM 模块捕获分词任务和命名实体识别任务相关信息;Wu 等[5]使用CNN-LSTMCRF 框架获得短距离和长距离的内容依赖,并且将CNN 的输出作为分词任务的输入,达到命名实体识别任务和分词任务联合学习效果,有效地提高了实体识别任务的准确率。上述文献分别研究训练分词任务和命名实体识别任务,未能充分获取两个任务之间的联系。Zhao 等[6]提出一种新的具有两种显式反馈策略的深层神经多任务学习框架以联合建模医学命名实体识别MER 和规范化MEN,但MEN 任务对MER 任务的提高并不明显;罗凌等[7]将笔画ELMO 信息融入神经网络构建多任务学习模型,并提出基于完全共享和基于私有共享的两种多任务模型,通过学习两个数据集的特征提高命名实体识别任务的识别率,通过大量外部资源以提高目标域的识别率,降低了工作效率。
将深度学习方法应用于中文电子病历命名实体识别任务时,存在一些不足:①深度学习方法对于标注数据的依赖性非常强,然而当前一直缺乏大量的中文电子病历实体标注数据;②特征工程的质量对深度学习模型的效果影响较大,导致领域特征通用性较差。
与传统的词嵌入模型相比,BERT[8]等预训练语言模型在自然语言任务上表现更好。但是一般的预训练语言模型的计算代价较大,在资源有限的设备上难以执行。华为实验室提出改进的BERT 模型NEZHA[9],有效地解决了内存大、模型运行效率慢的问题。
在前人工作基础上,本文提出一个基于NEZHA 和具有交叉共享结构的多任务模型。首先使用NEZHA 来训练大量的无标注中文医疗数据,以此学习中文医疗文本的特征;然后构建具有交叉共享结构的双向LSTM 模块充分学习CCKS2017 和CCKS2018 两个中文电子病历数据集的相关性,进一步提升模型的精确率。本文具有交叉共享结构的多任务模型,在使用NEZHA 学习大量的无标注中文医学数据后,通过学习多个任务的特征,可以有效解决低资源数据带来的模型性能不足的问题。
1 相关工作
中文电子病历实体识别任务可以转化为序列标注问题。双向长短期记忆网络[10](Bi-LSTM)在序列标注问题上有着较强的处理能力,条件随机场[11](CRF)被广泛应用于序列标记任务,因此将Bi-LSTM 神经网络结合CRF 作为传统的命名实体识别方法。
1.1 多任务模型
多任务模型(Multi-Task Model,MTM)可分为基于完全共享的多任务模型(Full-Shared Multi-task Model,FSMTM)和基于私有共享的多任务模型(Shared-Private Multi-task Model,SP-MTM)两种[12]。其中,FS-MTM 的模型结构是将两个命名实体识别任务通过完全共享Bi-LSTM模块进行模型训练。SP-MTM 的模型结构有两个用于执行各自任务的私有Bi-LSTM,一个用于获取共享特征的Bi-LSTM。在SP-MTM 中,共享Bi-LSTM 和私有Bi-LSTM 分别捕获共享的特征和各自私有的特征,CRF 层是基于与任务相关的特征表示产生不同的标签序列。
1.2 基于NEZHA 的预训练语言模型
大部分现有的数据增强方式都是通过预训练语言模型增强训练集数据,并且是基于英文语料实现,基于中文语料的模型较少。Google 的BERT、百度的ERINE[13]、BERT-WWM[14]是目前较为常用的中文预训练语言模型。本文选取NEZHA(Neural Contextualized Representation for Chinese Language Understanding)对中文医学文本进行预训练。NEZHA 作为BERT 的改进模型,采用相对函数位置编码,获取句子中不同字词之间的相对位置信息,并以词嵌入的方式进行模型输入,并且使用混合精度训练和LAMB训练器优化训练效率,提升模型性能。
2 基于NEZHA 和多任务学习的中文电子病历命名实体识别模型
针对中文电子病历实体识别任务,本文提出具有交叉共享结构的多任务学习模型(Cross-sharing Multi-Task Model,CS-MTM)。
2.1 CS-MTM 模型
CS-MTM 由嵌入层、特征提取层及序列标注层构成,其模型结构如图1 所示。
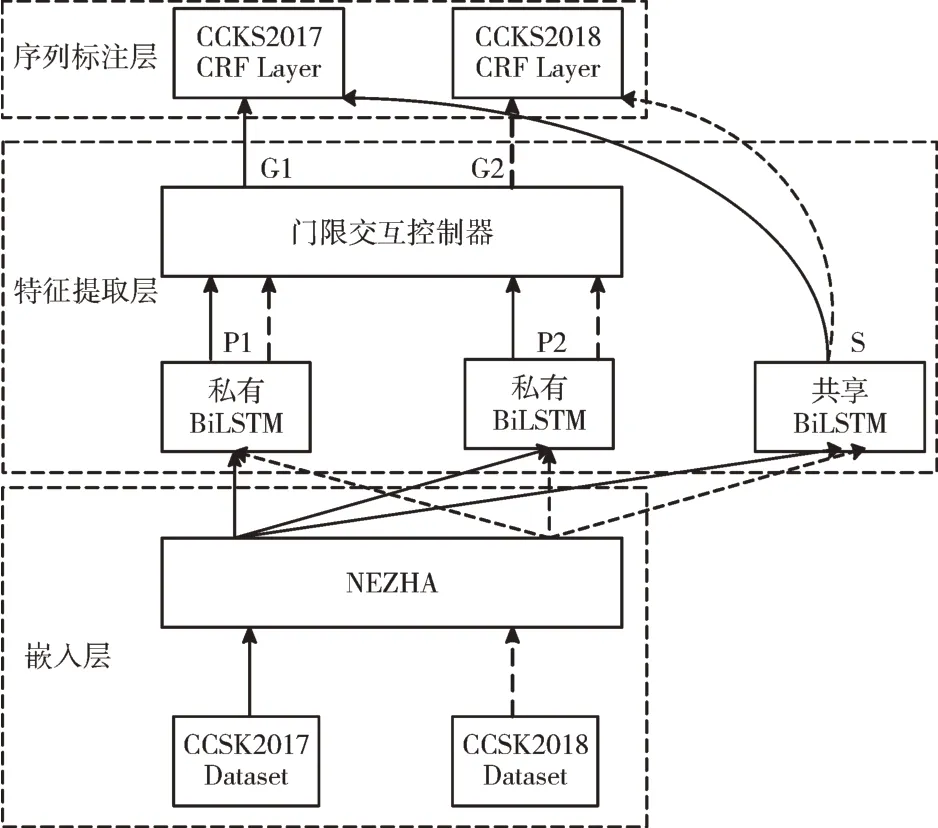
Fig.1 Multi-task model based on cross sharing(CS-MTM)图1 基于交叉共享的多任务模型(CS-MTM)
MTM 模型的主要思想是,借助来自于其他数据集的信息,提高源数据集的性能。而在SP-MTM 和FS-MTM 这两种多任务模型中,在训练时,输入的特征信息只有源数据集的特征信息,但是其他数据集的特征信息可能也会有用,因此,这样训练形成的模型,会发生部分信息延迟。
与SP-MTM 和FS-MTM 不同的是,本文提出的CSMTM 在嵌入层之后的特征提取层,使用交叉共享结构获取两个数据集的交互信息。
交叉共享结构有两个私有Bi-LSTM 模块、一个共享Bi-LSTM 和一个门限交互控制器。在嵌入层后,嵌入层的输出为字符的向量表示,将其复制成3 份分别作为共享Bi-LSTM 和私有Bi-LSTM 的输入。如图2所示,P1和P2是两个私有Bi-LSTM 的输出,S是共享Bi-LSTM 的输出。私有Bi-LSTM 捕获的是与另一个任务不相关的特征信息,共享Bi-LSTM 捕获的是两个任务共同的特征信息。因此,P1和P2是两个数据集的特征表示,S是两个数据集的共享特征。
上述SP-MTM 和FS-MTM 中,P1和P2分别只计算了数据集D1和数据集D2 的特征信息,没有计算出两个数据集的交叉信息。而在本文的CS-MTM 中,P1和P2是两个数据集的特征信息交互后的结果,解决了上述多任务模型带来的信息延迟问题。对于D1,P2包含来自D2 且不能直接用于D1 实体识别任务的特征;与之类似,对于D2,P1则应包含来自D1且不能直接用于D2 实体识别任务的特征。否则,这些互通的信息将会被共享的Bi-LSTM 模块所获取。
然后,在门限交互控制器中,P1和P2是门限交互控制器的输入,G1和G2是它们的输出,G 代表两个数据集的特征P1和P2可以交互产生新的混合特征信息,计算公式分别如式(1)、式(2)所示。
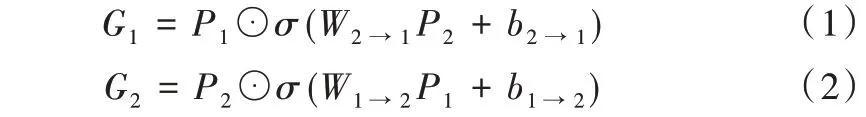
其中,⊙是元素智能乘法,σ是sigmoid 激励函数,W2→1、b2→1、W1→2、b1→2是可训练参数。在训练时,可以通过调整这4 个可训练参数学习两个数据集共享的特征信息。
在训练过程中,若选择的数据为D1或D2,则双向LSTM的输出分别为P1或P2。门限交互控制器G 的最终输出由目标数据集确定,如式(3)所示。
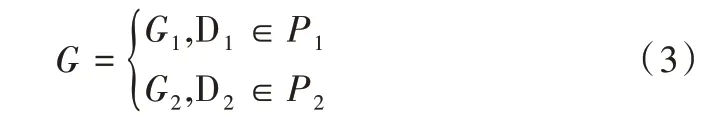
2.2 多任务模型训练
假设将中文电子病历的病历数据记作Z={z1,z2,…,zn},zi是病历数据中的第i个字。
传统的词嵌入模型有Word2vec[15]和Glove[16],它们是将词汇表中的每一个字词转换成相应的全局向量,也即在不同上下文中相同词语使用同一个词向量。因此,传统模型构造出来的词向量无法获取上下文相关信息[17]。本文CS-MTM 模型在嵌入层将Z 输入到NEZHA,持续进行前向和后向的双向训练,以此形成上下文相关的词向量X={x1,x2,…,xn}。将X作为特征提取层的输入,中文电子病历中的上下文信息对实体识别任务是很重要的信息,故本文使用双向LSTM 获取病历数据中的上下文信息。令LSTM的输出为h={h1,h2,…,hn},在CS-MTM 模型的双向LSTM模块中,其输出为正向LSTM的输出序列和反向LSTM 的输出序列按位置拼接,如式(4)所示。

将嵌入层的输出X输入到特征提取层中,将X复制成3份分别输入到共享Bi-LSTM 和两个私有Bi-LSTM。经过两个私有Bi-LSTM 模块得到的输出分别为P1和P2,通过共享Bi-LSTM 模块得到共享特征表示S,将P1和P2输入到门限交互控制器中,通过式(1)和式(2)计算得到两个数据集的混合特征G1和G2。
在序列标注层中,使用CRF 进行序列标注训练。通过特征提取模块提取出的信息为G和S,通过式(5)将其拼接起来,得到共享特征表示V,作为CRF 的输入,并根据标签进行序列预测。

为了解决多任务模型带来的损失平衡问题,本文所使用的目标函数为最大化两个方向的对数自然数。若共享特征V={v1,v2,…,vn},则经过CRF 训练得到的输出为Y={y1,y2,…,yn},所有可能的标注集合为ϕ={V},则标注序列y的概率如式(6)所示。
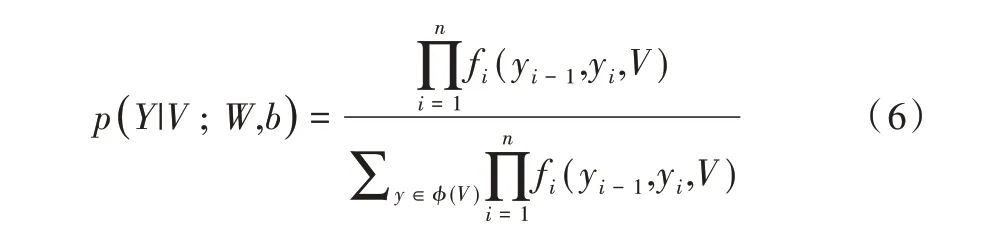
其中,函数fi(yi-1,yi,V)=exp(Wyi,yk vi+byi,yk),Wyi,yk是权重矩阵、byi,yk是偏置向量。
本文使用的实体识别任务的交叉熵损失函数如式(7)所示。
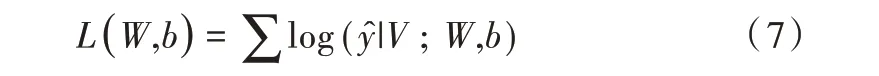
则CCKS2017 和CCKS2018 两个任务的总交叉熵损失计算如式(8)所示。
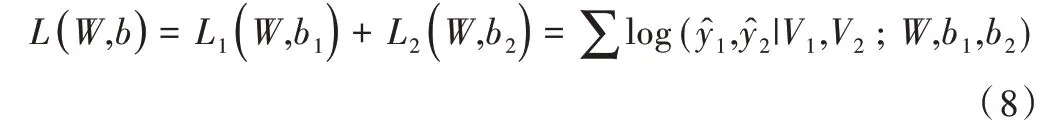
其中,L1(W,b1)、L2(W,b2)分别是D1 和D2 两个任务的交叉熵损失,、分别是两个任务的真实解码标签序列,W、b1、b2是可训练的模型参数。
3 实验与分析
3.1 实验数据及训练设置
本文实验采用的数据来自于中国知识图谱与语义计算大会CCKS 提供的CCKS2017 和CCKS2018 两个测评数据集。
CCKS2017[18]:包括300 个医疗记录,包括“身体部位”“治疗”“检查和检验”“症状和体征”4 种医疗实体。
CCKS2018[19]:包括600 个医疗记录,包括“解剖部位”“症状描述”“独立症状”“药物”以及“手术”5 种医疗实体。
此外,本文通过整合多个中文医疗文本数据集,形成较大规模的无标注中文医疗文本数据集,包括“瑞金医院糖尿病数据集[20]”“中文医学问答数据集[21]”以及在知网上下载的医学类文载。在去除原数据的各类标签信息后,总计有182 099 篇中文医学文本数据,下文中的语言预训练模型均是使用此数据集进行预训练。
为了确保实验有效性,按9∶1 划分数据集,分别为训练集和测试集。由于CCKS 测评数据集体积较小,为了防止模型过拟合,本文采用10 折交叉算法[21],即每次训练时选取9 个子集数据训练模型,并使用1 个子集对模型进行验证,直到所有子集都完整地经历了训练及测试。
在模型参数设置方面,本文所有的Bi-LSTM 都使用相同的超参数,如表1 所示。在执行多任务训练时,两个数据集的数据进行多批次轮流训练。

Table 1 Experimental parameter settings表1 实验参数设置
3.2 多任务学习模型性能对比
将单任务模型STM,多任务模型FS-MTM、SP-MTM 以及本文提出的CS-MTM 进行对比,结果如表2 所示。为验证多任务模型的有效性,实验中未加入任何外部资源,仅使用Word2vec 字向量作为所有模型的输入。由实验结果可知,相比于STM 模型,MTM 模型通过学习多个数据集的特征可以更有效地提升模型效果,其中基于交叉共享结构的多任务模型,F1 值在CCKS2017 数据集上达到90.23,表现最好,充分说明了交叉共享结构可以更有效地学习两个任务之间的交互信息。
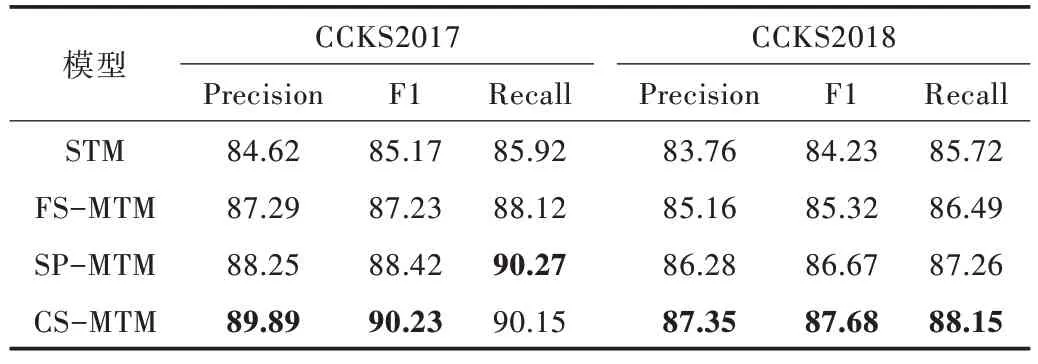
Table 2 Comparison of multi-task models表2 多任务模型对比
3.3 与其他方法性能对比实验
在CCKS2017 和CCKS2018 两个中文NER 数据集上进行实验并与现存优秀模型进行对比,实现结果如表3 所示,使用F1 值作为评价标准,粗体是CCKS 数据集的最佳实验结果。用作对比的模型如下:
(1)Bi-LSTM-CNN-CRF[5]模型。基于命名实体识别任务和分词任务的多任务模型。
(2)Lattice LSTM[11]模型。一种用于中文NER 的网格结构LSTM 模型,其编码了序列中输入的字符信息和潜在词汇信息,本文依照其文献[11]的方法,在中文电子病历语料上进行实验。
(3)ELMO+FS-MTM 和ELMO+SP+MTM模型。EL⁃MO+FS-MTM 是基于完全共享的多任务模型,ELMO+SP+MTM 是基于私有共享的多任务模型,该模型中加入了笔画特征信息及其他额外特征信息。但本文旨在比较多任务模型性能,故没有加入其他额外特征信息进行实验。
实验结果如表3 所示,使用词和字作为输入向量的Lattice LSTM 对比传统神经网络实体识别方法,相比于STM模型有了很大提升。但本文提出的模型并未加入词信息,使得Lattice LSTM 在少数部位的识别效果上优于本文模型。
STM 模型在中文电子病历命名实体识别任务上的效果并不佳,而使用MTM 模型学习两个数据集的特征,其实验效果提升相对明显。因此,可以证明两个数据集有一定关联性;反之,通过获取数据集的关联性也可以证明多任务模型的有效性。此外,BERT 预训练语言模型的效果不如其他模型的原因在于BERT 只进行了数据增强,并未实现更高层的特征信息提取。
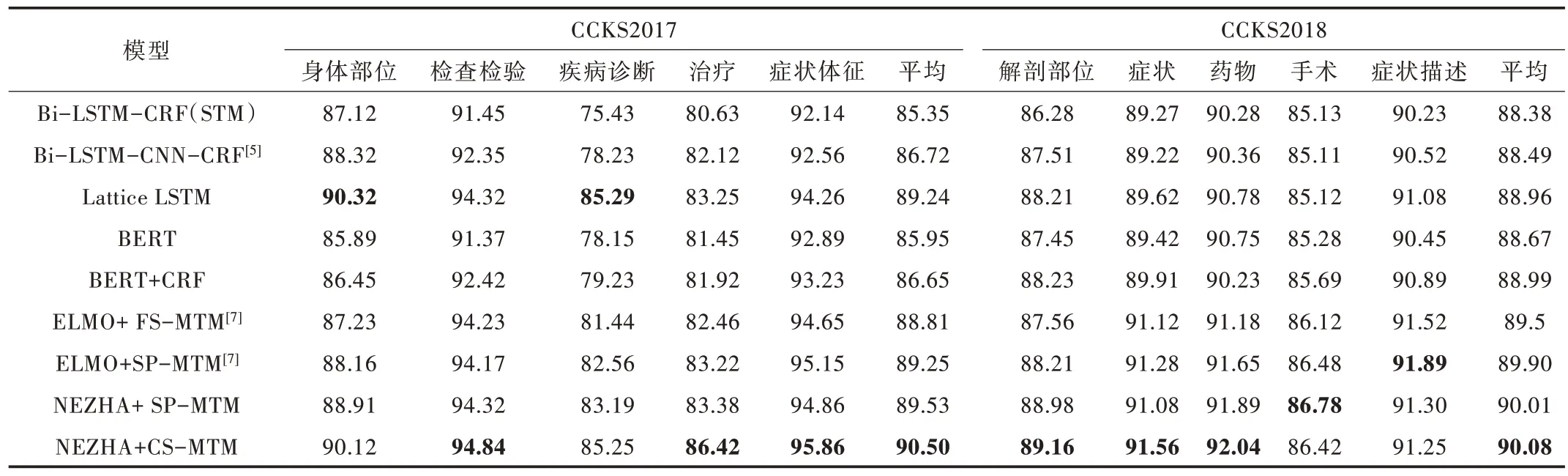
Table 3 Performance comparison experiment with other methods表3 与其他方法性能对比实验
在MTM 的实验结果部分,由于Luo 等[7]在其研究中加入了笔画特征信息及其他外部资源特征,丰富了数据集的特征信息,本文复现其工作时未能达到文中91 的分值。但本文也使用了基于私有共享的多任务模型,通过对比发现,使用NEZHA 的预训练语言模型更能有效地学习中文医学信息特征,而本文的交叉共享结构在与私有共享结构的对比中,实验结果显示更优。
4 结语
本文提出了一种基于NEZHA 和具有交叉共享结构多任务学习的中文电子病历模型CS-MTM。首先,使用NE⁃ZHA 训练大规模的中文医学类语料,通过学习大量的医学类语料,获取其上下文相关信息特征;然后,构建出具有交叉共享结构的多任务模型以学习多个相关任务的交互信息特征;最后,在CCKS2017 和CCKS2018 两个中文NER 任务上进行实验。实验结果表明,NEZHA 预训练语言模型可以很好地丰富语料信息,具有交叉共享结构的多任务模型可以充分学习两个相关任务的特征,并且有效地提高了中文电子病历实体识别任务精确率。后续研究中,考虑Lat⁃tice 结构与多任务模型相结合,将词汇信息与字符信息相结合以提高模型效果,并探索其他相关领域对中文电子病历命名实体识别的辅助效果。
