基于网络爬虫的青花瓷文物图像数据集设计与构建
2021-11-27郭丽胡志恒赵恒谦张瑞彬吴瑞翔高振肖珂珂
郭丽 胡志恒 赵恒谦 张瑞彬 吴瑞翔 高振 肖珂珂


DOI:10.16661/j.cnki.1672-3791.2108-5042-3116
摘 要:深度學习模型结构复杂,利用其进行图像分类需要庞大的数据量,图像数据集的规模和质量直接影响模型的效果,同时人工获取文物图像时,存在诸多不便。该文利用网络爬虫技术在故宫博物院官网批量获取不同年代的青花瓷文物图像,大大提高工作效率,然后对获取的文物图像进行全方位的分析和处理,为用户之后进行不同年代的青花瓷图像分类提供数据源。
关键词:网络爬虫 青花瓷文物 数据裁剪 数据增强 数据集构建
中图分类号:TP391.41 文献标识码:A文章编号:1672-3791(2021)08(a)-0015-04
Design and Construction of Blue-and-White Porcelain Image Dataset Based on Web Crawler
GUO Li HU Zhiheng ZHAO Hengqian* ZHANG Ruibin WU Ruixiang GAO Zhen XIAO Keke
(College of Geoscience and Surveying Engineering, China University of Mining & Technology(Beijing), Beijing, 100083 China)
Abstract: The structure of deep learning model is complex.Using it for image classification requires a huge amount of data. The scale and quality of image data set directly affect the effect of the model. At the same time, there are many inconveniences when manually obtaining cultural relic images. Through web crawler, we obtained images of blue-and-white porcelain from various dynasties in batch from Palace Museum official website, which greatly improves efficiency. We conduct an all-around analysis and processing of these images, thereby provide a data source for any users when classifying blue-and-white porcelain images from different dynasties.
Key Words: Web crawler; Blue-and-white porcelain; Data clipping; Data augmentation; Dataset construction
我国历史源远流长,文物遗存丰富,其中古陶瓷类文物种类繁多,工艺精湛,文化内涵丰富,具有极高的科技研究价值。成熟的青花瓷出现在元代景德镇,明清时期是青花瓷发展的主流,对青花瓷器文物的研究不仅可以反映出当时的社会文化,更是对传统文化的一种传承与保护。采集青花瓷文物图像并对其进行预处理,是便于后续对不同年代的青花瓷文物进行分类。
对不同年代的青花瓷文物的分类离不开深度学习,同时深度学习模型结构复杂,利用其进行图像分类需要庞大的数据量,图像数据集的规模和质量直接影响模型的效果,利用网络爬虫技术批量下载博物馆官方提供的青花瓷文物图像可以大大提高数据获取的效率。图像的预处理工作也是非常重要的环节,预处理的主要目的是筛选特征图像,突出待识别图像的特征,才能有效扩充数据集[1]。该文重点讨论图像的获取和处理工作,为下一步研究做好充分准备。
1 图像获取
为了保证数据来源真实可靠,经过调研最终确定选择故宫博物院提供的陶瓷藏品,同时为了快速批量获取各个年代的青花瓷图像,笔者使用网络爬虫技术从故宫博物院官网批量获取各个年代的青花瓷图像。爬虫使用的编程语言是Python和JavaScript,依赖库主要是lxml、js、py_mini_racer、ScrapyPillow、OpenCV等。其中lxml是一个使用C语言编写的第三方库,它结合了速度以及简单方法提取结构化XML的优点,对于在网页中提取数据很方便[2]。
利用网络爬虫技术获取图像具有快速、方便的特点,但同时也存在一些困难。当下的前端技术发展很快,几乎所有的网站都加入了反爬机制,如果简单的暴力提取,不仅不会提取到大量数据,还会被封掉IP,甚至会封掉账号,所以选择使用大量代理IP和拦截请求,修改js代码的逆向爬虫技术。这样不仅可以不必分析结构化的HTML文件,还大大提高了获取速度,但缺点是接口分析难度相比于HTML分析至少是提高了一个数量级[3]。对于信息量不大且反爬比较严重的网站就会使用lxml直接提取信息[4]。而对于信息量很大,但是接口容易分析而且逆向破解可以实现的话,主要使用逆向爬虫的方法。如果实在是难以实现,我们最终选择使用Selenium获取数据,这是一个网站自动化测试包,在网站前端复杂而信息量不大的情况之下使用它进行数据获取是一个很好的选择[5]。
在图像获取的过程中,会有一些不是青花瓷的图像被意外下载,对待这个问题,我们使用的是TensorFlow Hub的目标探测模型,对于不是瓷器的图像选择放弃下载,很大程度上减轻了人工去错的压力。由于网络请求耗时太长,我们需要充分利用多线程提高效率,同时考虑Python多线程不能充分利用多核,加入了多线程也是提高效率的方法[6]。
最终,使用网络爬虫技术获取到明清时期24个年代的青花瓷图像,为了之后使用深度学习模型进行青花瓷文物图像分类,选择数据量较为丰富且具有代表性的10个年代青花瓷文物图像进行后续研究。其中,10个年代分别为:明成化、明嘉靖、明隆庆、明万历、明宣德、明永乐、明正德、清康熙、清乾隆、清雍正。
2 图像裁剪
基于Python的图像裁剪主要用到的是OpenCV库和PIL(Python Imaging Library)库。OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列C函数和少量C++类构成,同时提供Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。主要用于图像分割、机器视觉、人机互动等相关研究。
PIL是Python一个强大方便的图像处理库。PIL库可以完成图像归档和图像处理两方面功能的需求。
(1)图像归档:对图像进行批处理、生成图像预览、图像格式转换等。
(2)图像处理:图像基本处理、像素处理、颜色处理等。
2.1 整体裁剪
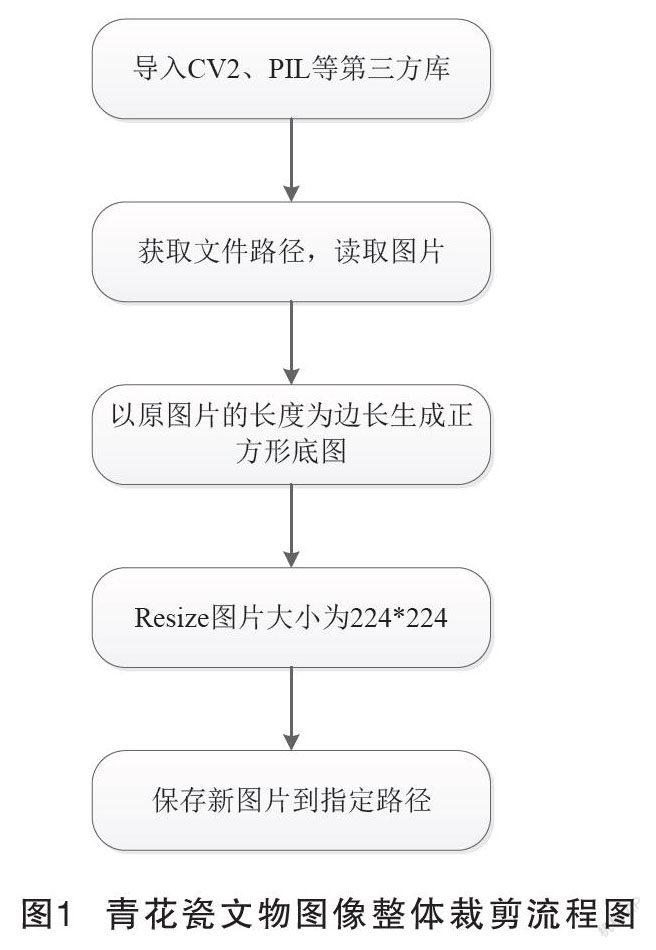
由于获取的图像大小不一,为了便于后续研究工作的顺利开展,先对图像数据进行裁剪处理,统一裁剪成像素大小为224×224。為了避免裁剪后出现变形等失真情况,裁剪之前先将图像补成以原图像的长边为边长的正方形,再批量对其进行裁剪。
裁剪流程图如图1所示,为了获得原图像的长和宽,先用Image.fromarray函数实现从数组到图像的转换,再通过函数image.size获取原图像的长和宽,将原图像的长度作为正方形的边长生成正方形的底图,底图的R、G、B赋值都为127,因此生成的是灰色的底图。在此基础上,将图像裁剪成224×224大小,使用到的是image.resize函数。
将图像进行整体裁剪,实际上类似图像缩放,并没有真地裁剪掉图像的有效信息。图2是青花瓷文物图像整体裁剪的结果。
2.2 局部裁剪
为了更细致地描述青花瓷器的特征,同时达到数据集扩充的目的,我们进行了图像的局部裁剪,获得每张图像的一些局部区域来作为输入进行青花瓷器的分类。如果从图像左上角或右下角等处进行裁剪,会得到大量图像的背景信息,为了保证每张裁剪后的图像信息有效,分别以每张图像长和宽的1/1.5处、1/2处、1/2.5处和1/3处为中心进行局部裁剪,裁剪的图像大小为100×100。裁剪用到的函数是image.crop,最后将裁剪后不包含青花瓷器特征的图像或只包含少量特征的图像删除。
3 数据增强
从故宫博物院官网爬虫获取的数据经筛选后,每个朝代只有几十张图像,数据量远远不够,而数据增强可以有效增加训练样本、减少网络的过拟合现象,通过对训练图像进行变换可以得到泛化能力更强的网络,更好的适应应用场景。因此采用数据增强来扩充数据集,使扩充后的数据集满足输入到深度学习模型的需要。具体方法有添加椒盐噪声、高斯噪声、旋转、调整图像亮度等。
首先,由于imread不能直接读取中文路径的图像,所以读取中文路径的图像用cv2.imdecode(np.fromfile(file_path,dtype=np.uint8),-1)来解决——先用np.fromfile()读取为np.uint8格式,再使用cv2.imdecode()解码。然后对每张图像进行以下处理:分别添加30%的椒盐噪声和高斯噪声、以图像中心为旋转中心旋转15°、调整图像的亮度为原来的90%和150%,使其更暗或更亮,这样最终得到的图像数量是原来的5倍。图3是部分青花瓷文物图像数据增强的结果。
4 结语
该文使用网络爬虫技术,同时结合多个第三方库,从故宫博物院获取了多个年代的青花瓷文物图像,经过对其进行分析和裁剪、数据增强等处理,最终选择数据量较为丰富且具有代表性的10个年代的青花瓷文物图像构建数据集。该数据集不仅满足了日后使用深度学习模型进行图像分类工作的要求,还为其他类别图像数据集的构建提供了思路。
参考文献
[1] 曾铭杰.基于深度学习的陶瓷类目识别[J].电脑知识与技术,2021,17(13):174-175.
[2] 张楠.Python语言及其应用领域研究[J].科技创新导报,2019,16(17):128-129.
[3] 吴道君.大数据背景Python在网络爬虫框架中的应用[J].科学技术创新,2021(21):97-99.
[4] 陶卫卫.Python爬虫的Cookie反爬应对策略研究[J].信息与电脑:理论版,2021,33(8):189-192.
[5] 赵涵原.基于Python爬虫的书籍数据可视化分析[J].电子技术与软件工程,2021(14):178-179.
[6] SHANG S T,WU H G,MA J T.An Improved Focused Web Crawler based on Hybrid Similarity[J].International Journal of Performability Engineeri-ng,2019,15(10):2645-2656.
