基于大数据分析的影音推荐系统研究
2021-11-22信晓艺
信 晓 艺
(德州学院 数学与大数据学院,山东 德州 253000)
随着互联网技术的飞速发展,网络中相同类型的信息越来越多,互联网用户每天都会面临各种各样的选择。互联网用户这种需求的逐渐增多,促使个性化推荐方法查找相关信息逐渐得到推广。个性化推荐方法不仅有助于根据用户的兴趣特征和历史行为过滤掉不必要的信息,还可以更深入地挖掘用户的潜在兴趣。以电影为例,当前视频网站上有大量电影资料,并且每天都会发布新电影。但是,互联网用户无法在视频页面上快速找到需要的电影数据,导致用户花费大量的时间来搜索数据,减少了看电影的时间,而个性化推荐系统可以帮助用户过滤掉不需要的信息,对于需要的信息,系统可以帮助用户按兴趣或其他形式寻找并分类。在大数据时代,个性化推荐系统已在每个人都最熟悉的电子商务行业中采用。系统根据用户之前的购买数据确定用户的偏好,或者对数据进行分析,然后根据分析结果推荐产品,以满足用户的最大需求并进一步提高销售量。当前,一些大型网站(例如Amazon、T-mall和JD.com)都在使用个性化推荐服务,个性化推荐在实践中可以说是非常重要的[1-5]。
国内对推荐算法的研究与西方发达国家之间存在很大差异。近年来,相关领域专家学者的研究越来越全面深入。卢永祥等人[6]对中文文本过滤技术进行了深入研究,最终提出了一种组合文本过滤模型,该算法主要基于内容过滤和协同过滤。单晓磊等人[7]提出了一种基于网络密度的用户偏好偏差检测方法,该方法可以快速检测用户偏好偏差,消除系统建议用户的影响,提高系统建议的准确性。赵涛等人[8]提出了一种算法,该算法推荐从二元晶格模型派生的材料的扩散出发,假设每个项目节点都有自己的初始资源,在第一次扩散之后,它均匀地分布在所有节点上,然后用户共享自己的资源,接着以相同的方式将其返回项目的节点,获取项目之间的建议资源并编写建议。高锐[9]提出了一种将社交媒体和协作过滤算法结合在一起的视频推荐方法,并根据目标用户的朋友的实例和他们的评分,通过计算候选电影的得分来生成推荐。本文介绍了K-means聚类算法和SVD算法,并结合视听推荐系统的当前状态,优化并提出了一种基于过滤器的协同过滤影视推荐算法。从推荐系统的应用场景出发,结合目前在影视网站上广泛使用的影视内容推荐系统,介绍了当前流行的算法分析及推导过程,基于针对协同过滤算法的数据稀疏性和冷启动问题,提出改进算法。
1 基于降维和聚类的协同优化算法
本文提出的基于降维和聚类技术的新型协同过滤推荐算法的目标在于缓解稀疏性、冷启动以及可伸缩性等问题对推荐内容的影响,提高推荐算法的性能。通过K-means算法(K均值算法)和Singular Value Decomposition算法(SVD算法)分别对相似的用户或内容进行聚类和降维处理。
本文的主要贡献点在于构建了一个有效的两阶段推荐系统,无论数据集的大小如何,该系统都可以生成准确的推荐信息。第一个阶段为离线模型的创建,在这一阶段中,通过以下方式构建推荐模型:根据用户的偏好对用户的评分进行聚类,缩小数据的维度,计算相似度。在这一阶段中,主要利用K均值算法和SVD算法进行优化。第二阶段是在线模型的利用,利用创建得到的模型为给定的用户生成高质量的准确的推荐内容。在聚类过程中,使用K-means算法将用户分组以形成K个聚类,并且每个聚类由具有相似排名首选项的用户组成。 这可以帮助提高推荐算法的性能,因为当仅考虑集群中包括的用户而不是考虑所有人员时,它需要更少的计算和更准确的推荐内容[8]。
本文在研究过程中进行了部分修改,以在协作过滤算法中更好地使用原始的K-means算法进行用户聚类。第一,选择一个随机用户K作为K聚类的初始中心。第二,根据用户和每个集群中心之间的距离,将其分配给最近的集群。第三,计算用户集群的新均值,以确定每个集群的新质心。第四,对于每个用户,重新计算距离以确定应将用户添加到哪个集群。第五,它重复用户距离的计算和用户的重新分配,直到满足条件的命令完成。具体的分组步骤如下:(1)输入用户对影视内容的评分矩阵,以及需要聚类的类别数目K;(2)随机选择初始的K个用户作为聚类中心;(3)计算距离并分配集群;(4)对于每个用户集群计算平均值作为新的分类中心;(5)使用新的分类中心将用户重新分配到新的集群中;(6)判断算法是否收敛到稳定的分类,否则重复执行(4)和(5);(7)输出K个聚类。
通过上面的步骤可以得到对用户进行集群聚类的结果,具体的聚类效果如表1和表2所示。

表1 原始的用户评分矩阵

表2 聚类后的用户集群评分矩阵
表1和表2显示了初始用户评分矩阵通过K均值算法得到用户集群评分矩阵。在用户评分矩阵中,每一列代表系统中的内容,每一行代表用户,ri,j表示用户i对内容j的评分。同样,在用户集群评分矩阵中,每一列代表系统中的内容,每一行代表用户集群,cx,y表示用户集群y对项目x的平均评分。
通过上面的聚类虽然可以减少一部分评分内容,减少矩阵的维数,但是得到的用户集群评分矩阵的维数仍然较高,因此我们利用SVD算法进行进一步降维。SVD算法(奇异值分解算法)是矩阵分解的算法之一,通常用于减少一组数据的特征数量。对于研究中的矩形评分矩阵X[n,m],其中n行代表用户的聚类中心,m列表示内容,因此可以将矩阵X分解为以下形式:X=U·S·VT,其中U表示大小为m×r的正交矩阵,r列为左奇异矢量,S是大小为r×r的对角矩阵包含奇异值,VT是大小为r×n的正交矩阵,具有右奇异值矢量。进一步来说,矩阵X中包括m个用户和r个因子的聚类中心,对角阵S中的r表示的是矩阵的秩,V矩阵中则包括n个用户和r个因子。
因此,通过上面的说明,在离线阶段中算法的步骤可以总结为[9]:
(1)输入包含原始用户评分矩阵的原始用户资料;(2)使用K均值算法创建用户集群,得到用户集群评分矩阵;(3)对于每个集群的评分矩阵,应用SVD算法进行处理获取分解矩阵;(4)对于得到的每个分解矩阵计算相似度;(5)输出推荐模型。
在离线阶段创建并训练了推荐模型后,就可以将模型部署到在线推荐系统中进行预测和推荐任务。在此阶段,还需要进行SVD的计算预测新用户的评分。具体步骤为:
(1)输入新加入的用户u、内容i和推荐模型;(2)使用原始的评分矩阵查找包含对内容i评分的用户集群;(3)预测新加入的用户u的评分情况;(4)输出推荐建议。
用于预测新加入用户评分情况的计算方法如式(1)所示。
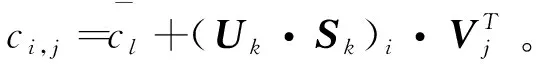
(1)


表3 SVD分解用户集群评分矩阵效果
2 算法实验
为了评估本文提出的方法的有效性,我们选择了3个广泛用于评估的数据集。第一个数据集是伯克利大学提出的MovieLens 1 M,它从大约6 000个用户中收集了4 000多个在线电影的收视率,其中收集了大约100万个收视率数据。第二个数据集是MovieLens 10 M,它从大约70 000个用户中收集了大约10 000个在线电影。这两个数据集的电影评分范围均为1~5星。第三个是MovieLens 100 K,它是上面两个数据集的原始版本,并且包含的数据较少。数据集包括80%的训练练习和20%的测试集。实验条件:CPU采用Intel Core i7-8700,内存采用8 GB内存,显卡为Nvidia GeForce GTX 1080ti,显存为11 GB,相关信息如表4所示[10-12]。
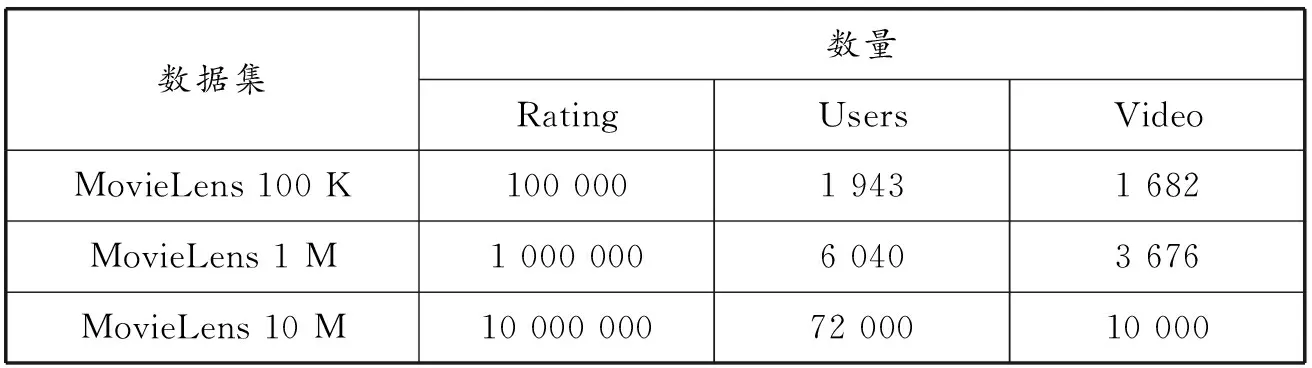
表4 实验数据集信息表
为了比较本实验中方法的性能,采用RMSE作为指标。具体来说,RMSE提供了有关用户选择的真实内容和预测的可能性内容之间的差异。RMSE值越小表明推荐系统性能越好。其计算公式为
(2)
其中:pu,i是用户u对内容i的预测评分,ru,i表示实际评分,而N表示对此内容的总评分。
在实验中我们将本文提出的基于降维和聚类的协同过滤算法与基于K均值算法的协同过滤算法和基于K近邻的协同过滤算法进行比较,邻居范围设定为10~50。实验结果如表5所示,整体的实验对比如图1、图2和图3所示。
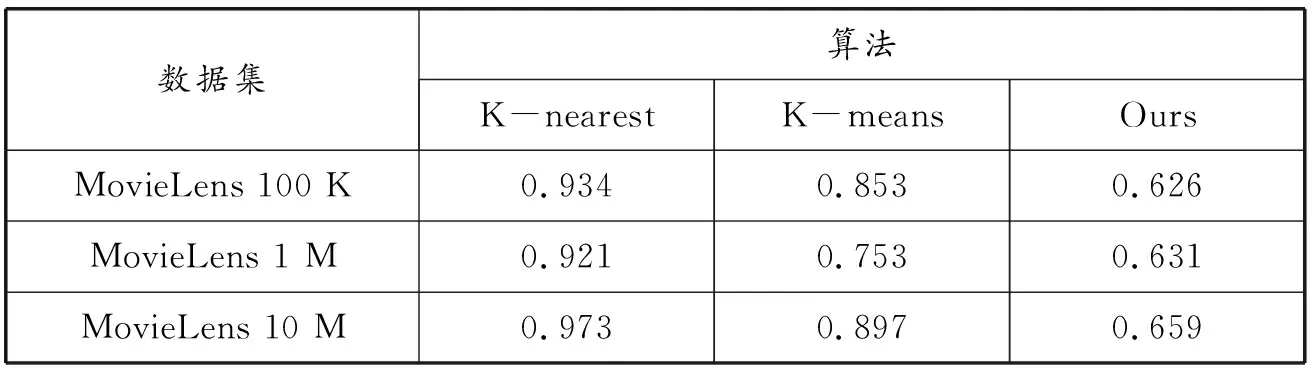
表5 3种算法的RMSE结果比较
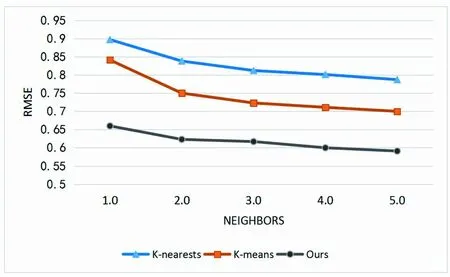
图1 100 K数据集RMSE对比

图2 1 M数据集RMSE对比

图3 10 M数据集RMSE对比
从以上实验结果可以看出,本文提出的降维和聚类的协同过滤推荐算法在所有比较算法中具有最好的推荐效果。在图1中,MovieLens 100 K数据集的降维和聚类协作推荐过滤方法在预测精度方面优于其他两个。还可以看出,基于K均值的推荐优于最近的基于K均值的推荐。图2显示了MovieLens 1 M数据集的3种比较方法的RMSE结果。图3显示了MovieLens 10 M数据集的3种比较方法的RMSE结果。与基于K均值推荐值和最近邻K推荐值的方法相比,可以看出本文方法在所有相邻的RMSE曲线中都保持最低值[13]。
同时为了选取最好的参数,对比不同数据集的K,实验结果如表6所示,可以看出聚类参数K为50左右时取得的聚类效果最好,因此在本文中推荐系统的聚类个数设置为K=50,实验对比图如图4所示。

表6 聚类参数K的RMSE结果比较

图4 不同K值的推荐效果对比
为了更全面地验证本文提出方法的有效性,除了前面提到的RMSE之外,本文还对比了3种方法在指标中的表现,3个指标的具体数值如图5所示。

图5 3种方法推荐质量对比
针对以上算法,建立了基于降维和聚类的系统过滤影音推荐系统,通过设置配置文件web.xml,调用基于降维和聚类的协同过滤推荐模块得到推荐的影视内容,如图6所示。根据用户喜欢的电影,生成对应的影视推荐内容;其中用户喜欢的电影列出了当前用户观看过的电影和对电影的评分以及相应的推荐电影列表,如图7所示。

图6 设置调用基于降维和聚类的协同

图7 基于降维和聚类协同过滤推荐的结果页
3 结语
本文分析了协同过滤推荐算法中存在的数据稀疏性、冷启动等问题的原因,研究并设计了基于降维和聚类的协同过滤影视推荐算法,设计实验对本文提出算法的有效性进行了验证,对比了其他推荐算法的性能;通过K均值算法和SVD算法的优化提升了协同过滤算法的推荐性能。最后,通过设计的实验与其他方法进行对比,证明了本文提出的方法达到了预设的研究目标[14]。
