基于日志数据的局域底层软件运行故障定位
2021-11-17曹丽娜朱方娥郭建方
曹丽娜,朱方娥,郭建方
(石家庄铁道大学四方学院,河北 石家庄 051132)
1 引言
目前,局域底层软件在通信技术、航空航天等技术领域得到了广泛应用。但与此同时,局域底层软件的工作运行负载压力也越来越大,使得局域底层软件容易出现运行故障等问题。程度较轻的故障可能会造成通信或网络中断,为企业工作造成一定影响,严重的工作问题可能会给整个公司带来比较严重的经济损失[1-2]。因此,对局域底层软件进行故障检测与维修必不可少。
近年来关于局域底层软件故障检测的研究也受到了广泛关注。目前应用较为广泛的故障定位方法主要有基于改良程序谱的软件故障定位方法[3]和基于聚类分析的软件多故障定位方法[4]。但在实际应用中发现,传统的故障检测定位方法虽然能够实现定位工作,但是在时间效率和准确程度上都略有不足。
“日志数据”是指计算机操作系统或者有些应用软件在运行时,为了在今后进行系统维护起来比较方便,而将系统或者应用软件在运行过程中产生的各种数据(比如:用户名、用户执行的程序名、日期、时间等)写入到一个日志文件中,以便今后系统出现故障时可以有据可查。通过将日志数据结合到局域底层软件故障信息的检测记录程序中,有利于提高故障检测定位的准确性。综上所述,本文基于日志数据研究了一种新的局域底层软件运行故障定位方法,并通过实验验证了新方法的有效性。
2 基于日志数据的局域底层软件运行数据采集
为了实现基于日志数据的局域底层软件运行故障定位,首先需要对设备的日志数据进行信息数据采集。通过建立一个完整全面的日志数据库以便对系统程序进行全面清晰的数据管理。
局域底层软件运行采集数据库结构如图1所示。
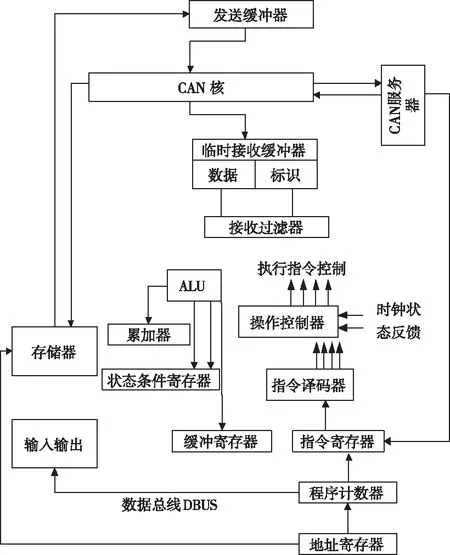
图1 局域底层软件运行采集数据库结构
观察图1可知,本文建立的数据库可以分别为系统日志、防火墙日志、网络访问日志设置一个线程函数运算程序,通过设定自定义的执行规则,实现对各部分程序日志数据的定期数据提取采集[5-6]。同时,本文还根据局域底层软件使用对象的不同类型,提供了不同的日志数据提取模式,普通的数据提取一般具有读取与保存功能,对于工作中身份比较重要的用户还拥有数据编辑、传递及抽取等功能权限[7]。
在日志数据提取过后,需要经过数据处理程序对日志数据进行具体的分析审核。由于数据数量的庞大、内容的复杂,日志数据审核程序必须具备高效率、高精准等属性,满足数据实时化的处理要求,保证数据的安全性合法性。通过将数据审核系统与网络服务平台进行合作,使审核系统具有广泛的、跨平台的数据检索环境,提高数据审核的检测效率,庞大而全面的搜索范围也进一步保障了数据信息的安全性[8-9]。
基于日志数据的局域底层软件运行数据采集流程如图2所示。
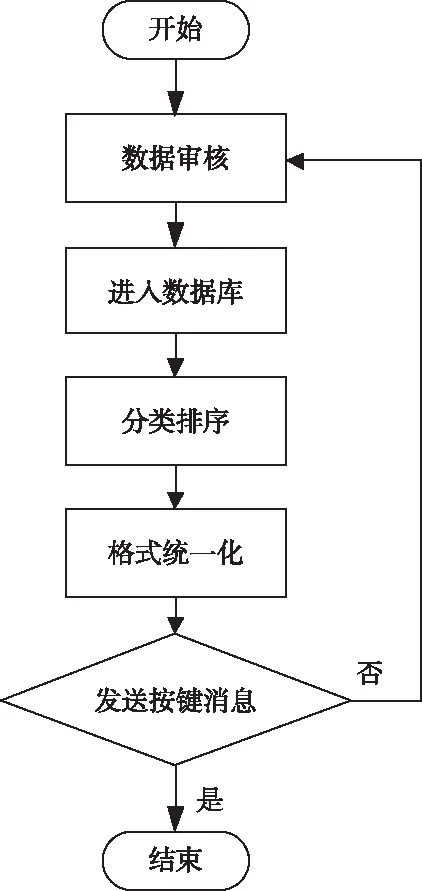
图2 基于日志数据的局域底层软件运行数据采集流程
观察图2可知,经过审核程序的日志数据会根据分析结果被有条理的分类存储到日志数据管理数据库,按照用户或企业定义的分类规则逐一分类排序[10],同时已录入的日志数据还会根据格式规则进行格式的统一化,并通过备份程序对整理归纳好的数据进行备份保存,以应对突发状况。至此,关于软件程序的日志数据提取收集完毕,为局域底层软件运行故障的检测与定位提供了有利数据信息支持。
3 局域底层软件运行故障定位
3.1 构建日志数据统计量
基于以上日志数据的采集情况,构建日志数据的统计量。通过对日志数据进行分析推测,得到局域底层软件运行过程中的各种变量之间存在的关系,提取出含有变量信息较多的变量,并针对这些变量的信息进行处理,采用变量成分分析法对每一组变量进行解析统计,构建日志数据信息统计量[11]。
从多个数据库中提取数据统计量,提取过程示意图如图3所示。
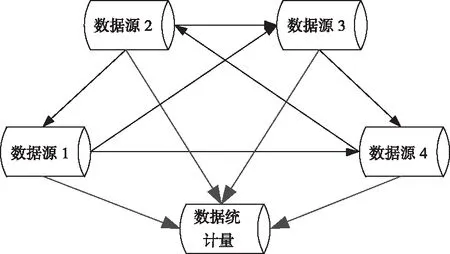
图3 数据统计量提取示意图
构建统计量时,首先要对目标运算数据变量进行计算处理,通过对区域底层软件运行过程中的日志数据变量进行分析整理,依据相应的分类规则归类到对应的数据库,并从中筛选出符合运算要求的数据变量,导入到计算程序中对其进行变量分析运算。变量分析法的运算过程主要采用的公式如下

(1)
式(1)中,I表示日志数据中变量之间的关联度,x表示质量变量,y代表运算过程中的运行变量,p代表着局域底层软件运行中的数据变量与数据边缘之间的概率函数。通过该公式运算能够得到数据变量的关联函数,然后对关联变量进行排列运算,过程如式(2)所示
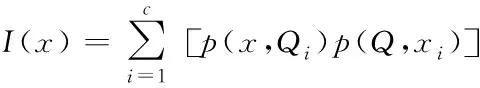
(2)
式(2)中,p(x,Qi)与p(Q,xi)分别表示变量x与边缘函数变量Q在对应常数同一常数i的情况下的相应概率,由此对关联函数I进行升序排列,获得相应的日志数据排列情况。之后可以通过设定不同的阈值对数据变量进行二次筛选,排除无法增权的函数变量,然后根据变量的排列情况构建日志数据统计量映射矩阵,矩阵运算公式如下:

(3)
式(3)中,t表示软件运行过程中的投影变量,p仍表示各变量的概率密度函数,I表示各部分经过增权的函数变量与函数投影变量之间存在的关联。
关联函数是按照从小到大的顺序排列的因此会形成变量数据由小到大的变量矩阵,矩阵中相对应的函数与投影函数形成一对数据统计量。由此,构建出基于日志数据的局域底层软件运行数据统计量,为基于日志数据统计量的软件运行故障定位系统程序的故障检测提供数据信息基础。
3.2 基于日志数据统计量的故障定位
基于以上局域底层软件日志数据的统计量的构建,进行基于日志数据统计量的软件运行故障定位检测。局域底层软件结构如图4所示。
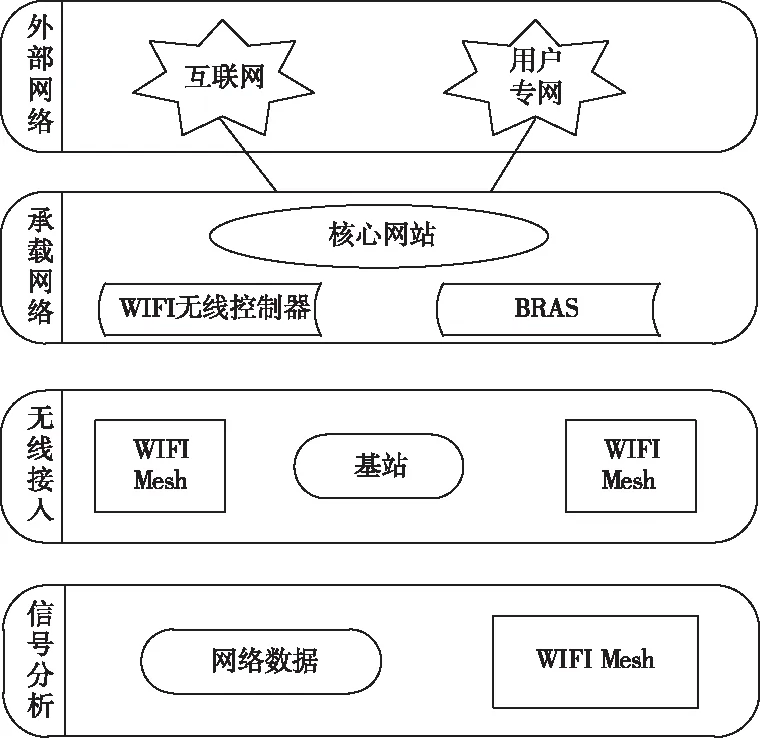
图4 局域底层软件结构
首先确定日志数据统计量与故障定位系统程序的适配性,根据不同的检测目标或设备型号,调整故障定位系统各方面的检测参数。故障定位检测程序采用数据统计量模型分析方法,对局域软件运行低阶障碍进行分析检测,获取障碍的信息特征数据,并通过相应的数据转换运算将低阶故障特征进行投影构建出相对应的高阶障碍特征,根据高阶障碍特征数据统计量选取适当的故障检测数据信息值域,再通过数据元素分析法对值域范围内的数据统计量进行分析,分层次的对故障信息进行检测。
同时,根据局域底层软件的运行周期,对运行过程中各方面的日志数据按周期进行划分,并通过数据运算程序对周期内的日志数据进行方差矩阵运算。结合上述运算获取的故障高阶数据统计量,形成关于该周期内局域底层软件运行数据变量的线性相关矩阵,通过对线性矩阵的分析处理,寻找数据变量之间的相关性。故障定位过程如图5所示。
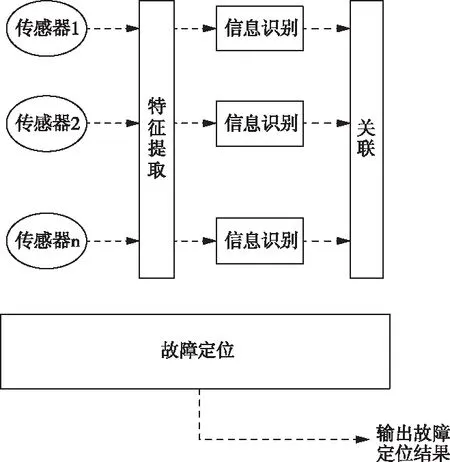
图5 基于日志数据统计量的软件运行故障定位过程
由图5可知,根据障碍产生的原因与类型,推测线性矩阵中相关联变量之间存在故障的可能性,并通过概率密度函数计算得到准确的障碍产生的可能性。由于线性矩阵与软件运行结构存在相对应的关系,所以可以针对存在明显异变的数据变量或故障问题,能够通过参数转换寻找确定障碍存在的软件位置。
由于局域底层软件故障检测识别是基于互联网的日志数据,因而具有一定的开放性和通用性,能够对底局域层软件以及相关网络领域进行日志数据训练集提取。并通过日志数据识别匹配程序,对相关的日志数据进行整合,通过对具有一定相似性的日志数据进行匹配对比,能够检测出其中存在缺陷的日志数据[12]。日志数据统计量经过模拟程序能够构建出相应的日志数据模型,首先对数据来源和信息进行检测,筛选过滤掉相似度较低的日志数据,将符合要求的日数据进行相关性处理,之后将数据按类型分别进行模型构建,对局域底层软件的运行过程进行模拟构建,这样能够更直观、更清晰地检测出其运行过程中的故障所在。
上述的基于日志数据的局域底层软件运行过程故障定位检测方法,能够根据用户系统类型进行自定义的检测标准设定,实现有针对性的、个性化的软件故障定位检测。同时,对于软件故障的检测过程与结果,系统程序会进行相应的数据记录并保存在系统数据库,方便用户对故障的产生、检测与解决进行信息回顾查询和情况反馈。
4 仿真与结果分析
为验证上述设计的基于日志数据的局域底层软件运行故障定位方法的实际应用性能,在MATLAB仿真平台中设计如下对比实验。以本研究方法为实验组,以传统的基于改良程序谱的软件故障定位方法和基于聚类分析的软件多故障定位方法为实验组,从故障定位时间和故障定位准确率两个角度验证三种方法的实用性。
局域底层软件网络模型如图6所示。

图6 局域底层软件网络模型示意图
在局域软件网络中输出信号,分析信号的幅值与相位。在实验开始之前,需要分析节点的测量结果,通过采样操作实现傅里叶变换,并将得到的变换结果作为计算量输入。
实验参数设置情况如表1所示。

表1 实验参数设置情况
根据上述实验参数,将本文方法与两种传统方法进行性能对比,得到的实验结果如下。
1)故障定位时间实验对比结果
首先以故障定位时间为指标展开性能测试,结果如图7所示。
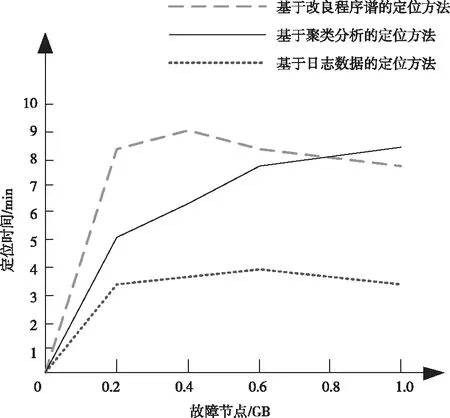
图7 故障定位时间实验对比结果
根据图7所示结果可知,本文设计的基于日志数据的局域底层软件运行故障定位方法定位过程花费的时间远远小于两种传统定位方法。产生这一结果的原因在于本文方法能够对日志数据进行有效采集,在分析多种数据量,如运行能量、工作功率、工作电压后,将这些特征量提取融合到一起,利用数据分析和数据挖掘实现故障定位,从而有效缩短了定位时间。
2)故障定位准确率实验对比结果
在此基础上,以故障定位准确率为指标展开性能测试,结果如图8所示。
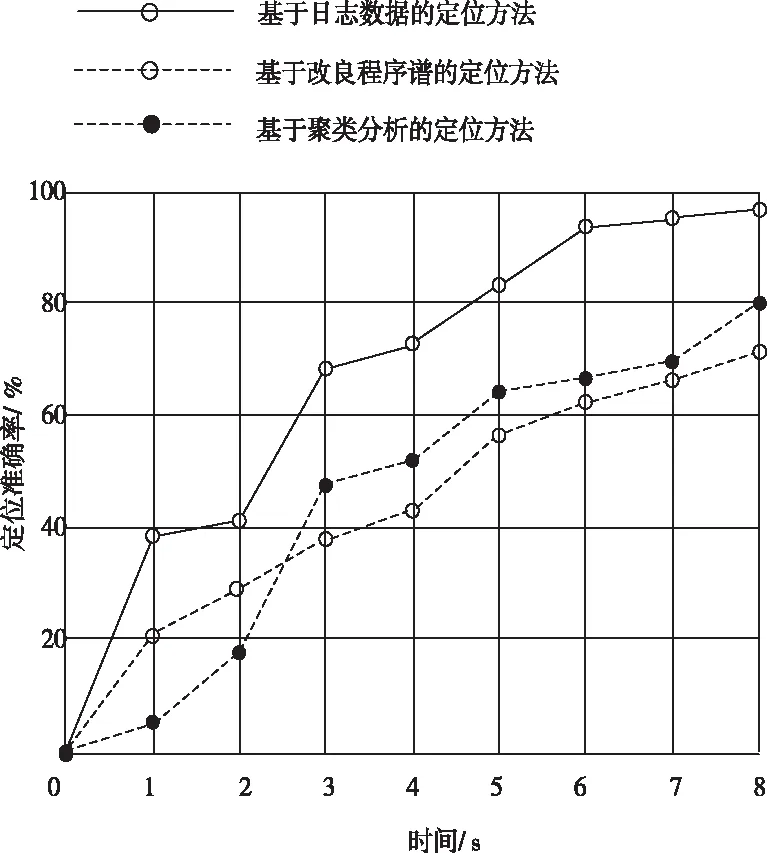
图8 故障定位准确率实验对比结果
根据图8所示结果可知,在相同的定位时间内,相比于两种传统的定位方法,本文方法故障定位准确率更高。产生这一结果的原因在于本文方法在进行故障定位时,引入了参数修正过程,通过分析权值调整增长结果,分析不同参数所占权值,从而更精准地完成故障定位。
综上所述,本文设计的基于日志数据的局域底层软件运行故障定位方法在定位耗时和定位准确率上都有着传统定位方法所不具备的优势。由于日志数据具有很强的记录能力,所以通过采集日志数据可以获得相对完备的局域底层软件的相关信息。本文将采集的日志数据存入到数据库中,在数据库中进行提炼操作后,选取有效的特征数据,形成日志数据统计量,再根据筛选结果得到相对准确的故障定位结果。传统方法虽然都能够实现故障定位,但是由于采集数据量过程耗费时间过长,所以得到的定位结果不具备实时性。由于局域底层软件对于故障定位提出了越来越高的要求,因此,本文设计的故障定位方法具有很大的发展应用空间。
5 结束语
本文针对传统的软件运行过程故障检测方法存在的弊端,结合了互联网日志数据技术,提出了一种基于日志数据的底层软件运行故障定位方法。在分析了日志数据信息采集优势的基础上,根据对日志数据的统计量运算和数据变量矩阵分析与模型构建,对软件运行故障定位检测程序进行了完善。经仿真实验证明了基于日志数据统计量的软件运行故障定位具有良好的开发性和适用性,在故障检测定位的效率上也有所提高,这一方法的研究能够为软件运行故障领域的相关研究提供一定的价值参考。
