基于树到串模型强化的神经机器翻译模型构建
2021-11-17邹德芳胡秦斌
邹德芳 ,胡秦斌
(1.广西中医药大学,广西 南宁 530200;2.南宁师范大学计算机与信息工程学院,广西 南宁 530001)
1 引言
人工智能与自然语言[1]技术蓬勃发展,利用计算机的机器翻译对自然语言进行自动转换成为了重要的研究方向。机器翻译不仅可以打破语言屏障,实现国家与民族之间信息的有效传递,而且对文化交流、民族团结以及对外贸易等方面,均具有着强有力的推动作用。机器翻译经历了主导时期为理性主义方法与经验主义方法的两大发展阶段,尽管前者根据人提取到自然语言间的转化规律来描述翻译知识,可以对自然语言进行分析、转换与形成,但随之而来的还有增加的翻译知识整合难度、较长的开发周期以及高额的人工成本等诸多弊端;大数据与云计算的飞速进步,掀起了经验主义方法的盛行之风,采用数学模型完成自然语言的转换,统计机器翻译就是该时期的典型代表。由于统计机器翻译性能具有严重的依赖性,且通过局部特征无法获取全局关系,因此,使神经机器翻译得到了迅速普及,因其翻译质量的明显提升,从而在各个翻译领域占有了重要的一席之地,演变为机器翻译研究的前沿热点。
文献[2]通过数据增强技术,扩充了资源贫乏语种的训练数据量,从而使神经机器翻译的泛化性能得到加强;而文献[3]则提出亚词及单词的维汉神经机器翻译模型,把词的翻译单元转换成词与亚词的混合翻译单元,将ALU的非线性单元作为GRU的神经非线性单元,进而对神经机器翻译模型进行改进。
由于上述翻译模型无法完成结构差异较大的语言对翻译任务,构建了基于树到串模型强化的神经机器翻译模型,通过连续性的神经网络编码,取得词向量及其对应的隐状态,利用源输入文本矢量来界定编码器隐状态输出,从而得到输入层、输出层以及正反向编码层之间的权重关系,依据接收的终止标识符开启解码操作,将编码器输出的中间矢量更改为目标矢量进行输出,并计算目标词汇的条件概率,基于句法分析与翻译构成的树到串模型,采用GHKM算法提取对齐结构中的翻译规则,通过搜索最优推导强化树到串模型,根据解码器叶子节点推算出非叶子节点状态,最后利用各神经网络单元构建神经机器翻译模型。
2 传统神经机器翻译模型分析

图1 神经机器翻译模型示意图
在机器翻译领域中引入深度学习网络,按照网络性能对神经机器翻译模型进行分类,能够得到两个模块,分别是解码器与编码器。前者涉及到的算法为树搜索算法,两模块的连接部分为关注力机制;而后者则常常会对词向量、长短期记忆[4]网络等重要技术进行应用。
编码器将输入端的源语言文本,通过神经网络转变为矢量空间内的向量表示。
神经机器翻译的源输入文本表达式如下所示
X={x1,x2,x3,…,xn}
(1)
其中,句子中的词汇个数为n。
在编码的初始阶段,编码器的Embedding层将对源输入文本的所有词汇xi(i∈n)进行编码,将其转换成下式所示的词向量[5]表达式
Wi∈R|V|
(2)
其中,i=1,2,…,T,且Wi=[n1,n2,…,nm],ni∈R,源语言词汇大小为V。
通过连续性的神经网络编码,所有词向量Wi都会产生一个隐状态hi,该隐状态含有当前的词汇信息,将当前的隐状态作为神经网络下一刻的输入,其会在门阀机制的效用下,对当时的隐状态信息实施保存,因此,在对最后的单词xn进行编码时,隐状态hn将蕴含句子的所有隐状态信息。由于大多数的隐状态均为提取的语义信息[6],所以,利用源输入文本矢量来界定编码器隐状态输出。
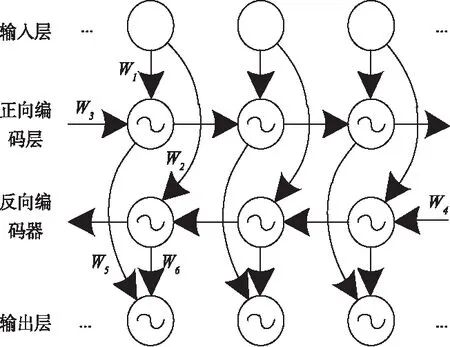
图2 循环神经网络结构示意图
图2中,输入层到正向编码层的权重为W1,到反向编码层的权重为W2,正向编码层的自循环权重为W3,反向编码层的自循环权重为W4,正向编码层到输出层的权重为W5,反向编码层到输出层的权重为W6。所有的时刻流程均将重复利用到上述六个权重,而正、反向编码层箭头流向的去除,也使结构的非循环特性得到了保证。
解码器通过将编码器输出的中间矢量更改为目标矢量后实施输出操作。如果源输入文本的终止标识符被编码器所接收,则停止编码,解码阶段开启。将源输入文本的矢量表示设定为初始化解码器[7]单元,即s1=hn。
解码就是对所有目标词汇在已知部分输出时的条件概率进行计算的过程。根据当前解码器的隐状态sj与前j-1个输出成功的目标词,就能够推算出第j个目标词的条件概率,其计算公式如下所示
P(yj|yj-1,x)=g(sj)
(3)
式中,非线性函数表示为g,其中的sj则通过下列公式进行表示
sj=f(yj-1,sj-1)
(4)
模型通过条件分布的学习,在已知一个源输入文本的前提下,采用树搜索算法,就可以对具有最大似然估计值的目标词汇进行输出,即翻译输出。
3 树到串模型强化策略
树到串强化模型划分翻译过程为句法分析和翻译两个阶段。设置中文为源语言,英文为目标语言,创建树到串强化模型,如图3所示,该模型主要由源句法分析树、目标串和源端与目标端文本串之间的对齐信息等部分架构而成。

图3 树到串强化模型示意图
通过GHKM算法对上图里的对齐结构进行树到串翻译规则的提取,其规则样例如表1所示。

表1 规则样例统计表
上表中规则内容的左边指代一棵树片段,其中,非终结符表示为x;右边则为对应的翻译信息。因为树到串模型提取的规则,蕴含着较为充盈的层次信息,所以,该模型相对于同步上下文文法的表达性能也具有明显的优越性。
抽取训练集内所有的翻译规则,并利用一个规则统计表对其进行整合,基于句法分析[8]树的全部推导D,完成解码器对最优推导d*的搜索,然后依据匹配规则统计表的翻译原则,实现推导与目标翻译的转换。所以,采用下列优化目标函数,对树到串强化模型的目标进行描述
(5)
上式中,规则统计表的匹配原则表示为r。
由于规则4和7的左边无法匹配完全,在实际情况中将存在较大差异,但该树到串强化模型均将源端的词汇化节点“shalong”翻译为目标端的“Sharon”,证明了该模型具有良好的性能发挥。
4 基于树到串模型强化的神经机器翻译模型构建
传统模型无法对不同语言的差异性进行有效处理,不仅丢失了源语言语法信息,而且也对目标端的翻译内容造成了不流畅的影响。而树到串模型强化的神经机器翻译模型将词汇、短语进行有机结合,利用结构化信息[9]的提取能力,使语句富有一定规则的结构化信息,从而实现在机器翻译中引入更多的语法信息。
解码器属于连续性神经网络解码器,如果将其叶子节点状态用隐状态hj来表示,则可以推算出其非叶子节点状态,表达式如下所示
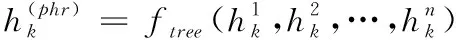
(6)
其中,解码器的叶子节点个数为n。
基于长短期记忆结构分析翻译模型的解码器,将每个长短期记忆单元作为解码器的各个节点,所以,各层节点都包括下一层节点所提取的结构化信息。
该翻译模型的各神经网络单元j均由输入门ij、输出门oj、记忆单元cj以及隐状态hj所组成,其门向量与记忆单元的更新主要依赖于其所有子节点的状态,且该神经网络的所有子节点k都存在一个对应的忘记门fjk,由此导致其神经元可以在各子节点里完成信息的提取与融合。通过创建的翻译模型,既能够在一个语义相关的语料[10]内对强调的语义进行学习,也可以从情感分类任务里对情感信息丰富的子类实施保存。假设神经机器翻译模型源序列内词汇j的一个输入矢量为xj,依据不同的输入形式,将模型中树到串模型强化的神经网络划分成子类与树形长短期记忆、N维树形长短期记忆两个类别。
若一棵树存在一个节点j,其全部子节点的集合设定为C(j),那么,下列各式即为子类与树形长短期记忆神经网络的转换表达式

(7)

(8)

(9)

(10)
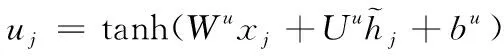
(11)
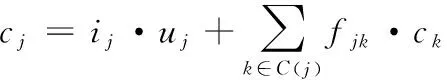
(12)
hj=oj·tanh(cj)
(13)
上列表达式内的所有参数矩阵,都可以直观地理解成神经网络单元里隐藏状态hk与输入向量xj的编码相关参数。以依存树的应用为例,如果输入的是语义信息相对关键的动词词汇,输入门ij的取值约等于1,相反,输入的是比较次要的语义信息词汇,输入门ij的取值约等于0,那么,模型就能够对权重参数Wi进行求取。
而N维树形长短期记忆处理的树到串场景则是分支数量为N,且子类呈有序状态的结构。不同于子类与树形长短期记忆的是,该类神经网络的所有隐状态hj均能在经过训练后,得到结构上相对应的权重矩阵Uj。通过将矩阵添加到所有子类中,令基于单元子类状态方面的N维树形长短期记忆相比子类与树形长短期记忆,具有更好的学习能力,从而获取更多的微调条件。因此,采用下列各式对N维树形长短期记忆神经网络转换进行描述
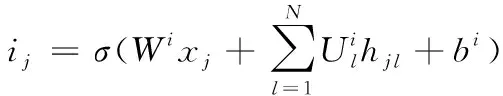
(14)

(15)

(16)

(17)

(18)
hj=oj·tanh(cj)
(19)
5 仿真研究
5.1 仿真环境
为验证所提方法的有效性,设计仿真对比实验。仿真环境的电脑硬件配置为64位Windows7 SP1旗舰版操作系统,实验任务内容为中英翻译,语料的相关信息如表2所示。

表2 实验语料信息统计表
根据表中数据显示,句子结构长度均值比提取最长名词短语的句子长度均值减少了9.22,而相对于提取最长名词短语的句子长度均值,最长名词短语长度均值则下降了14.75。
表3所示为树到串模型强化的神经机器翻译模型参数统计表。

表3 翻译模型参数统计表
在模型仿真的过程中,通过树搜索算法获取译文,将束大小取值10。
5.2 句子敏感性分析
采用文献[2]方法和文献[3]方法作为对比方法,采用对比方法模型与所提模型,分别对实验语料进行翻译,以获取句子长度与译文质量的影响关系,图4为不同句长分布的译文质量BLEU示意图。

图4 基于不同句长分布的各模型译文质量对比
通过上图可以看出,句长的不断上升导致了译文质量的持续降低,尤其是句长大于20之后,文献模型的下降幅度显著变大,但所提模型的曲线走势始终处于相对平缓的状态,波动较小。从侧面说明,句长对所提模型的影响并不明显,且当句长超过一定数量时,所提模型的性能愈发优越。
5.3 翻译效率分析
采用三种不同的模型翻译实验语料50000词,得到翻译效率对比结果如图5示。

图5 各模型翻译效率对比
分析图5可知,文献[2]模型对50000词的平均翻译时间为17s,文献[3]模型的平均翻译时间为23s,所提模型的平均翻译时间为5s。
所提模型利用树搜索算法,对具有最大似然估计值的目标词汇进行输出,有效减少了翻译时间,翻译输出较快。由此可见,所提模型的翻译耗时较短,翻译效率好。
6 结论
本文对基于树到串模型强化的神经机器翻译模型进行构建。经过分析传统神经机器翻译模型的运行原理,获取编码器与解码器的具体工作流程与性能发挥,通过GHKM算法实施对齐结构的翻译规则提取,采用优化目标函数架构树到串模型强化策略,根据语句的结构化信息,实现语法信息的引入,利用隐状态与长短期记忆结构,使神经机器翻译模型构建得以完成。该模型为今后相关领域的探索提出了指导性的建议与方针,具有一定的现实意义与理论意义。
