基于Mask R-CNN的车位状态智能识别算法
2021-11-17程远航
程远航,余 军
(贵州大学科技学院,贵州 贵阳 550003)
1 引言
图像目标检测技术随着深度学习技术的成熟得到快速发展。作为主要深度学习技术之一,R-CNN(Reigions with CNN features,递归神经网络)算法是典型的目标检测算法[1],该算法主要在GPU内实现,计算效率与准确性能够得到保障。因此R-CNN算法普遍应用在图像目标检测领域中。近些年,R-CNN算法在目标检测领域中不断创新,先后提出Fast R—CNN、Faster R—CNN、YOLO、SSD等算法[2]。Mask R—CNN算法是在Fast R—CNN算法基础上添加了并行的mask分支[3],可针对不同ROI构建一个像素级别的二进制掩码。利用Mask R—CNN算法不仅能够分割图像边界框,同样适用于图像内物体的细粒度分割,并且具有较高的检测精度与效率。因此,将Mask R—CNN算法应用于车位状态智能识别过程中,提出基于Mask R-CNN的车位状态智能识别算法。
2 车位状态智能识别算法
2.1 Mask R-CNN网络
Mask R-CNN网络的本质为Faster R-CNN网络的并行扩展,通过增添一个分支网络不仅完成目标检测,并且能够分割目标像素。利用该算法可实现目标检测、图像实例分割与车辆关键点检测等过程。图像检测技术后的下一过程即实例分割,通过图像目标检测分类不同单体目标并逐一标记后,通过实例分割在各像素上明确目标的具体类别[4]。Mask R-CNN网络模型框架如图1所示。
利用Mask R-CNN网络检测图像目标过程中,首先确定图像内的ROI(感兴趣区域),利用ROI ALign修正各ROI内像素,利用Faster R-CNN网络框架预测各ROI实例类别,由此获取图像实例分割结果。将Faster R-CNN网络内添加的mask分支作为Mask R-CNN网络内的损失函数,其表达式为:
S=Scls+Sbox+Smask
(1)
上式内,Scls、Sbox和Smask分别表示分类误差、检查误差和分割误差,其中Smask描述各ROI内像素通过sigmod函数获取的平均熵误差。采用mask编辑输入目标空间布局的代码。预测ROI过程中主要采用m*m的矩阵,主要是由于这样可以最大限度上确保ROI空间信息的完整性[5]。在智能查找停车位过程中,ROI区域内通常为“车辆”,所以式(1)内的Smask可理解成“车辆”的分支的mask。Mask R-CNN网络整体由三部分组成[6],分别是特征提取阶段的主干网络、识别分类边界框的头结构和区分不同ROI的mask预测。
Mask R-CNN网络与Faster R-CNN网络的区别是该算法中针对当前RCNN头结构进行了扩展。
2.2 基于Mask R-CNN图像中汽车检测
在具有时变性与复杂性的交通路线内查找并定位车位[7],可通过视频监控实现,检测停车位视频图像内的车辆,同时确定不同帧图像内车辆是否产生位移,以此预测车位位置。
检测视频图像内车辆信息时在GPU内采用Mask R-CNN网络,可实现数帧/s的高分辨率目标检测。用Mask R-CNN网络在确定视频图像内不同对象位置的同时,还可以描述不同对象的大体外框结构。

图2 Mask R-CNN图像检测
在训练Mask R-CNN网络过程中选用内涵object masks注释图像的COCO数据集。同时,针对我国实际交通状态特征,在数据集中选取海量汽车图片并追踪选取图片内的全部汽车。另外,针对待检测的视频图像,在获取汽车信息的同时,同样需要综合交通信号灯、树木、行人等信息。
在视频图像中利用Mask R—CNN网络模型检测汽车目标能够获取四种不同类型的信息[8]。分别是:①视频图像内对象类型,通常用整数描述,对COCO数据集中数图像Mask R—CNN网络模型可检测出75种以上、如汽车、人、建筑等不同类型的常见物体。②视频图像内物体目标检测的置信度,其值同Mask R—CNN网络模型准确识别对象的概率之间成正比关系。③视频图像内检测目标的边界框,同时检测目标所在位置通过横、纵坐标位置比描述。④呈现边界框内部分像素归属于检测目标和像素不归属,检测目标的位图“mask”,分析并处理这部分数据,由此确定检测目标的外框结构。
目标识别与分割过程如下:利用Mask R—CNN网络模型检测目标之前,需先训练该模型。因采集视频图像数量较少,为避免Mask R—CNN网络训练过程出现过拟合问题,首先训练COCO数据集,该数据集内包含近9万个样本,且各样本内的物体类别仅具有语义标注,适用于图像目标检测与分割。分别采集锥形、圆柱形、球形、正方形等常见目标物体,通过LableMe标记获取标签图[9]。选取数据增广方式随机旋转原图像角度获取新图像,由此降低样本多样性缺陷的问题。为降低光照电度与颜色波动对于目标识别产生的副作用,选取新的数据增光方式变化视频图像RGB通道强度,对RGB视频图像像素值实施主成分分析后,将视频图像内各像素增加一个随机倍数的主成分,公式描述为:
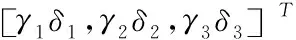
(2)
上式内,y表示RGB视频图像像素值的3*3协方差矩阵的特征向量,γ表示随机变量,δ表示协方差矩阵的特征值。其中γ符合高斯随机分布。
视频图像中通常存在一定程度的噪声干扰,因此在进行Mask R-CNN网络训练时需实施中值滤波操作[10]。训练流程如图3所示。
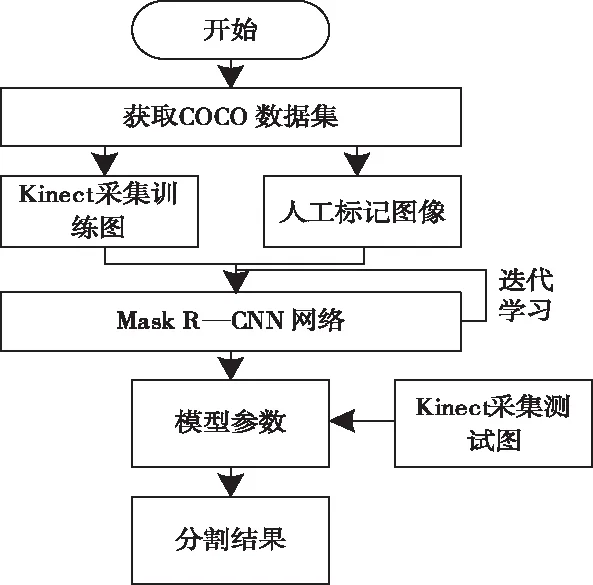
图3 Mask R-CNN网络训练流程图
Mask R-CNN网络训练总共由三部分组成,分别是:利用学习率为0.001训练头部输出网络层;利用学习率为0.001训练四层以后的网络层;利用学习率为0.0001训练整体Mask R-CNN网络层。当模型训练误差固定时训练结束。
为确定训练后Mask R-CNN网络分割结果的性能,以重叠率为指标评价视频图像目标识别与分割的准确度,式(3)描述重叠率计算过程

(3)
上式内,ZE和ZH分别表示Mask R-CNN网络预测分割的区域的实际视频图像中目标区域。
通过上述目标识别与分割过程能够检测到视频图像内的汽车对象,并得到各汽车的边界框和坐标位置,如图4和表1所示。

图4 汽车边界

表1 汽车坐标位置
2.3 识别车位状态
通过Mask R-CNN网络获取单帧视频图像内汽车外边框与像素坐标位置后,连续检测多帧视频图像,若汽车坐标位置未出现变化,则可判断此区域为停车位。
经过分析Mask R-CNN网络检测汽车边界框的结果可知,汽车边界框与停车位边界框存在部分交叉区域,因此可通过IOU(Intersection over union)法判断两个边界框交叉区域的像素数量,同时确定其与两个汽车目标覆盖区域像素总量的商值。
IOU法实现过程如图5所示。利用Mask R-CNN网络检测视频图像内目标后,得到不同目标的边界框和坐标位置,将得到的全部信息输入IOU法内。
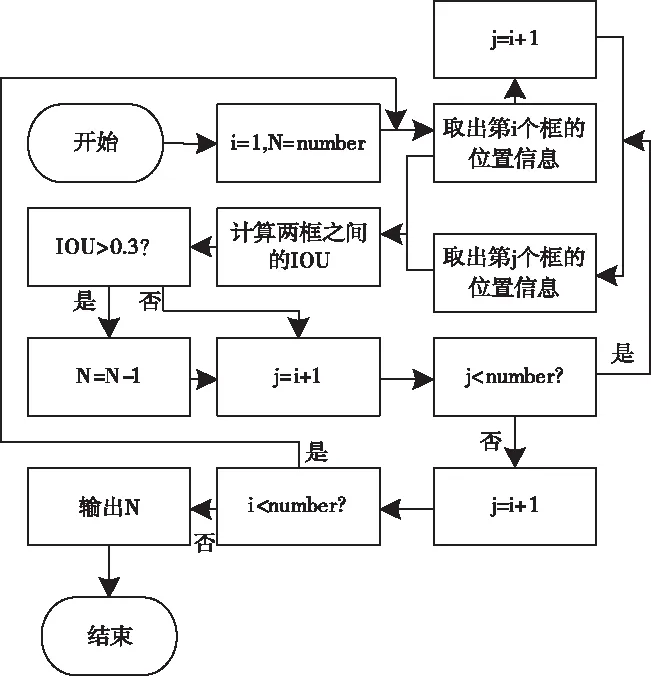
图5 IOU法实现过程
图5中number和n分别为Mask R-CNN网络检测出的汽车数量和通过IOU法过滤后视频图像中实际车辆数。
通过 IOU法可大致确定视频图像中停车位边界框与汽车边界框之间的交叉程度。设两个边界框整体交叉时IOU值为1,在IOU值不大于0.15时,表示停车位绝大部分区域没有被汽车占据,这说明停车位当前处于空闲状态;在IOU值大于0.5时,表示停车位大部分区域被汽车占据,表明停车位当前处于非空闲状态。
3 实验分析
为验证本文提出的基于Mask R-CNN的车位状态智能识别算法的有效性,选取我国南方某城市中凌河区为实验区域,设定实验环境与训练数据集后,进行车位状态识别,结果如下。
实验环境:i7处理器,64G内存。
训练数据集:COCO数据集。
图6所示为本文算法车位状态识别的结果,其中红色边框为非空闲车位,绿色边框为空闲车位。

图6 车位状态识别结果
由图6可知,在不同视频图像中采用本文算法均可有效检测出不同环境中的停车位,并准确识别出车位是否为空闲状态,由此可知本文算法可有效实现车位状态识别目的。
表2所示为针对上述三幅视频图像,本文算法、基于边缘检测的识别算法和基于四元数剧理论的是识别算法在目标检测的精度与用时。

表2 目标检测的精度与用时对比
由表2得到,包括本文算法在内的三种算法中本文算法的目标检测精度均在99%以上,而其它两种算法精度在90%—94%之间,其中基于边缘检测的识别算法精度略高于基于四元数剧理论的识别算法。本文算法目标检测用时显著少于两种对比算法,而基于边缘检测的识别算法所需时间略高于基于四元数剧理论的识别算法。由此可知本文算法在目标检测方面的性能显著由于对比算法。
表3所示为三种算法对于车位状态识别的精度与所需时间。

表3 车位状态识别的精度与时间对比
分析表3得到,本文算法在识别车位状态时的精度达到100%,而所需时间也少于对比算法。综合表2内容得到本文算法在识别车位状态时具有较高的精度和效率。
为测试本文算法在识别车位状态过程中的实时能耗,分别采用本文算法、基于边缘检测的识别算法和基于四元数学理论的识别算法识别实验区域内车位状态,对比不同算法识别过程中的实时能耗,结果如图7所示。

图7 不同算法车位状态识别过程能耗对比
如图7可知,本文算法在识别车位状态过程中的实时能耗控制在0.60J/s之下,平均能耗大约为0.35J/s。基于边缘检测的识别算法和基于四元数剧理论的识别算法实时能耗上限值分别达到1.1J/s以上和1.0J/s以上,平均能耗与本文算法相比分别提升0.4J/s以上。上述实验结果说明本文算法识别车位状态过程中实时能耗显著低于对比算法。
不同停车位状态识别算法的核心技术对比如表4所示。通过对比不同算法核心技术的优、劣势,验证本文算法的适用性。
分析表4中的内容可得,相较于其它几种对比算法,本文算法最适合作为车位状态识别算法,这是由于本文算法在查找停车位过程中使用的摄像头成本较低,安装与维护相对简单,利用一个摄像头可监控数个停车位,这将显著降低硬件装配过程的工作量。并且本文方算法的劣势主要针对高速移动车辆,但汽车在驶进/驶出停车位时通常速度不会太快,因此这一劣势可忽略。
由此可知本文算法具有较高的适用性,可普遍推广。

表4 不同车位状态识别算法的核心技术对比
4 结论
相较于以往普遍使用的目标检测算法,Mask R-CNN网络模型检测精度更高,且不通过滑动窗口即可高效检测整副图像内的全部目标,所以本文提出的基于Mask R-CNN的车位状态智能识别算法的寻找效率较高。但通过后续大量实验测试与应用反馈得到,在某些条件下单帧图像内会存在少量汽车被漏检的现象,因此要实际查找车位并判断车位是否空闲时需检测7、8帧的连续视频图像,避免因单帧视频图像漏检问题导致识别偏差。同时这也是后续研究中的主要研究方向。
