基于GF-1数据复杂地区地物类型提取探究
2021-11-11张德军陈志军何泽能饶志杰杨世琦
张德军,颜 玮,陈志军,祝 好,何泽能,饶志杰,杨世琦
1. 重庆市气象科学研究所,重庆 401147; 2. 永川区气象局,重庆 永川 402160; 3. 四川省西充县气象局,四川 西充 637200
随着人类本身对地球环境影响速率的加快,全球变化已成为研究地球系统整体行为的热点问题[1].土地利用/土地覆盖变化作为影响地球环境变化最直接的因素,影响了全球生物多样性、 生物系统的承载力和服务功能[2].因而,能及时有效地获取土地覆盖信息对于研究全球地表环境变化至关重要.
真实有效的土地覆盖数据为监测地球环境变化、 评估可持续发展以及建立生态气候模型提供了重要的数据支持[3].卫星遥感技术具有宏观、 快速、 经济等特点,能实现不同尺度下地表环境的观测[4],为全球范围土地覆盖和地表环境变化监测提供可能.目前,大尺度的地表环境遥感观测主要以低分辨率遥感数据为主(300 m~1 km)[5-6],如美国地质调查局、 马里兰大学、 波士顿大学和欧洲发布的4套空间分辨率为1 km的全球土地覆盖产品,以及欧空局制作的空间分辨率为300 m的GLOBCOVER产品[7].但低分辨率土地覆盖产品存在空间分辨率低、 时间跨度短以及分类精度低等问题[8].中高分辨率土地覆盖产品数据虽然具有高精度、 高空间分辨率等优点,但此类产品制作过于依赖分类算法和人工目视解译,存在自动化程度低、 效率差、 费时费力等缺点[4,9].如何利用中高分辨率遥感数据实现土地覆盖类型的快速、 自动化提取以及动态监测已成为遥感研究的热点和难点.
人工智能技术的加入,使得土地覆盖分类催生出了诸多新的算法,其中包括人工智能神经元网络分类方法[10]、 决策树分类法[11-12]、 支持向量机法[13-14]和随机森林算法[15-16]等.人工智能与遥感技术的结合,为实现土地覆盖类型的自动化识别和提取提供了可能.新算法充分利用了中高分辨率遥感数据的光谱、 纹理和空间特征,极大地提高了土地覆盖产品的制作效率和分类精度.李亚飞等[17]以向量的形式融合了遥感图像的光谱、 纹理和空间结构等特征,并将特征融合后用于卷积神经网络模型中,使得融合后的模型能识别更抽象、 更具有代表性的高层特征,提高了土地覆盖信息的分类精度.王恩德等[18]设计了一种结合ResNet18网络预训练模型的双通道遥感图像特征提取网络,同时采用标准化层和带有位置索引的最大池化方法进一步优化网络结构,提高了遥感图像的语义分割效果和分类精度.肖国峰等[19]利用Landsat数据和HJ-1A数据采用CART决策树法,提取得到1990-2017年山东省庆云县和无棣县土地利用图,并制定了撂荒地的识别规则,依据识别规则提取了研究区的撂荒地空间分布.为推广国产高分数据在森林树种分类方面的应用,同时探究不同时相、 分类特征及分类器的组合对树种分类结果的影响,李哲等[20]利用3景高分二号影像构建了3种单时相和4种多时相,通过多尺度分割、 C5.0特征优选及SVM和RF两种分类器分别实现了不同时相及特征维度下面向对象的8个树种的分类.为评估机器学习算法在复杂地表环境下覆盖类型土地分类的精度,本文以国产GF-1 PMS为数据源,利用支持向量机、 随机森林和人工神经网络算法提取重庆市永川区土地覆盖类型,并结合不同地物类型之间NDVI以及形状因子的差异,对机器学习算法分类结果中混淆像元进行修正,以期最终得到高精度、 高空间分辨率的地物分类结果.
1 研究区及数据
1.1 研究区概况
研究区位于105°48′E~105°52′E,29°8′N~29°11′N的重庆市永川区南部,东西横跨6.9 km,南北向宽5 km,区域总面积为34.5 km2.该区域地貌主要以丘陵、 低山和平坝为主[21],海拔高度介于280 m~506 m.土地覆盖类型主要包括林地、 农田、 建筑、 道路、 水体和大棚等.为详细分析试验区各典型地物的提取效果,本文选择了5个559×559像元大小的区域(图1).其中,红色区域被用于分析林地和道路提取效果,紫色区域为建筑物聚集地,黄色区域为农田,浅绿色区域为不规则水体,蓝色区域含有部分种植大棚.
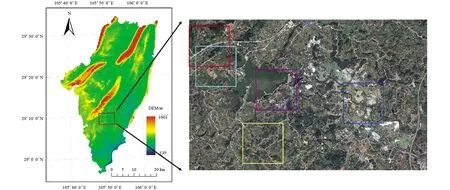
底图来源于自然资源部标准地图服务网,审图号: CS(2019)3333.图1 研究区地理位置及GF-1号真彩色图像
1.2 数据及预处理
文中数据源为国产GF-1 PMS影像,包括空间分辨率为2 m的全色波段和8 m的多光谱波段,PMS数据波段介绍如表1所示.影像时间为2017年7月10日,云覆盖量为1%.GF-1 PMS数据处理主要包括辐射定标、 大气校正、 正射校正、 图像融合、 图像镶嵌和裁剪等步骤[14].公式(1)为GF-1图像辐射定标方程,式中Gain为定标斜率,DN为卫星载荷观测值,Bias为定标截距,Lλ的单位为W/(m2*um*sr),各定标参数来源于中国资源卫星应用中心(http: //www.cresda.com).辐射定标后,利用FLASSH模型进行大气校正,校正后的数据借助DEM对图像中的每个像元进行地形误差校正,使得遥感图像满足正射投影的需要.然后采用NNDiffuse融合技术生成高光谱、 高空间分辨率的图像.最后,利用研究区矢量范围对融合后的高光谱、 高空间分辨率数据进行拼接和裁剪.

Lλ=Gain*DN+Bias (1)
2 研究方法
2.1 支持向量机法
1995年Vapnik等人基于统计学理论的VC维理论(Vapnik-Chervonenkis)和结构风险最小化(Structural Risk Minimization,SRM)准则提出了一种机器学习方法——支持向量机法[22].该方法具有易用、 稳定和精度高等特点,能较好地解决小样本、 非线性、 高维数据等实际问题[4].
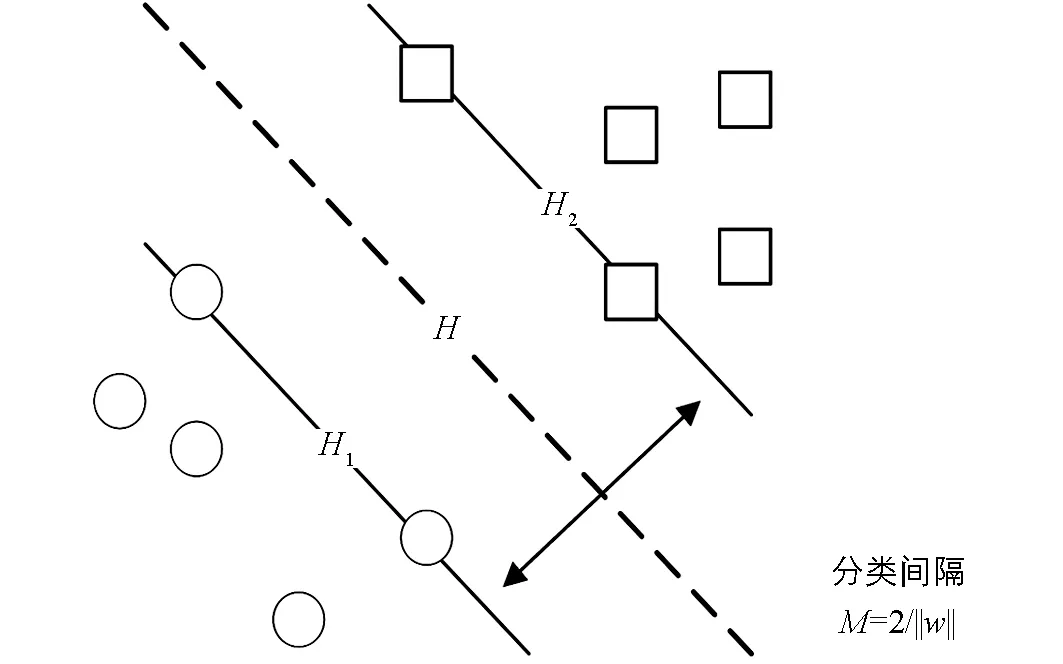
图2 线性可分条件下的最优平面
SRM的基本思想是寻找能够正确划分训练数据集,且划分的几何间隔最大的分离超平面[22].此平面有许多种可能性,因此需要找出最佳的超平面(Optimal Separating Hyperplane,OSH),使类别间区分距离最远.一般情况下,样本到超平面距离的远近被用于表征样本分类预测的准确程度.图2中H为线性可分条件下的OSH[4],H1和H2之间的距离M称为分类间隔.
2.2 随机森林算法
2001年Breiman L提出了一种利用多棵树对样本进行训练和预测的分类方法——随机森林算法[23].该算法很好地解决了决策树过拟合的缺点,较好地容忍了训练过程中出现的噪声和异常值,在高维度数据分类过程中具有良好的并行性和可扩展性[24].其优异的分类性能,使得RF分类算法在医学、 生物学、 地理学等领域得到广泛的应用.RF模型中包含了多个由Bagging集成技术训练生成的决策树,以这些决策树为分类器,由各单个决策树分类结果进行投票决定最终的分类结果(图3).
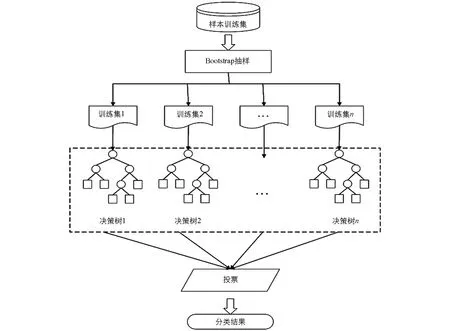
图3 随机森林算法示意图
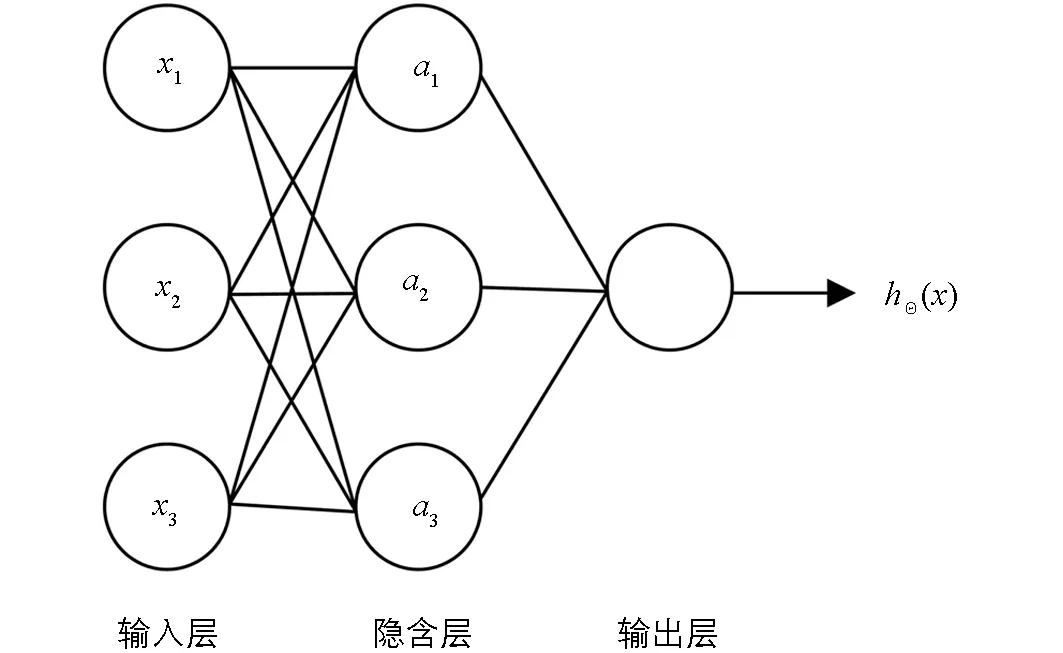
图4 人工神经网络算法示意图
2.3 人工神经网络算法
人工神经网络最早于20世纪40年代,由心理学家W. S. McCulloch和数理逻辑学家W. Pitts提出的,他们通过MP模型提出了神经元的形式化数学描述和网络结构方法,证明了单个神经元能执行逻辑功能,从而开创了人工神经网络研究的时代[25].到了20世纪70年代,拥有自学习、 联想存储和高速寻找优化解等优势的ANN算法开始被应用于高分辨率遥感影像地表覆盖类型分类中,由于ANN算法在地表含混度较高、 地物纹理特征丰富的区域分类效果较好,通过改变隐含层的节点,从而较好地解决了地物分类过程中存在的“同物异谱”和“异物同谱”的现象[26].图4为人工神经网络算法结构图,图中xi为输入层接收的特征向量,hΘx为输出层预测的结果,介于输入层与输出层之间的是隐含层.
2.4 分类精度验证
目前,用于评估土地覆盖类型分类精度以及分类算法可靠性检验的方法有两种,一种是通过混淆矩阵计算得到总体分类精度(公式2)和Kappa系数(公式3); 另一种以ROC曲线图形来表达分类精度.本文选择利用分类后结果与检验样本间的混淆矩阵,以数字的形式更直观地评价各分类算法的精度.
(2)
(3)
公式(2)为总体分类精度P0的计算公式,式中n为被正确分类的像元总数,n′为图像内总像元个数.公式(3)为Kappa系数的计算公式,其中P0是总体分类精度; 假设每一类的真实样本格式分别为α1、α2、 …、αn; 而预测出来的每一类的样本个数分别为b1、b2、 …bn,总样本个数为m,则有:
(4)
3 结果及分析
3.1 样本提取及可分离性检验
在选择训练样本时,必须遵循样本本身典型、 具有足够的充分性,且样本个数要满足分类器的要求.本文结合研究区地表实际情况,将研究区土地覆盖类型划分为林地、 道路、 大棚、 农田、 水体以及建筑用地6类,每类地物选择50个训练样本以及100个用于评估分类精度的检验样本.
为检验地物样本选择的合理性,避免人为误差对地物分类造成的影响,本文利用Export ROIs to n-visualizer 将样本进行多维展示,以判断不同样本间的分离程度.图5为不同地物训练样本在三维空间上的展示,不同地物数据团离得越远,表明分类效果越明显.在不同角度下,林地、 建筑、 农田数据团间距离相对较远,不存在混杂融合的情况,说明林地、 建筑和农田3类地物训练样本间可分离性较好.但林地与水体,大棚与道路地物样本点混合在一起,可分离性相对较差.为更直观地判断训练样本间可分离度,本文采用Compute ROI Separability工具对各样本可分离性进行定量评估,采用Jeffries-Matusita(JM),Transformed Divergence(TD)参数评估不同样本间可分离程度,结果如表2所示.JM和TD的值域范围为0~2.0之间,当JM或TD值大于1.8,表明训练样本间可分离性较好,属于合格样本; 当JM或TD值介于1.0~1.8,则需要对样本进行编辑或修改; JM或TD值小于1则需要考虑将两类样本合成一类样本.从表2中可以发现,林地和水体之间的JM为1.01,TD值为1.25; 农田和大棚之间的JM值为1.30,大棚与建筑之间的JM值为1.38.较低的JM和TD表明,林地与水体、 农田与大棚以及大棚和建筑训练样本间可分离度较低,在执行分类运算前,我们还需对这部分训练样本进行修正.
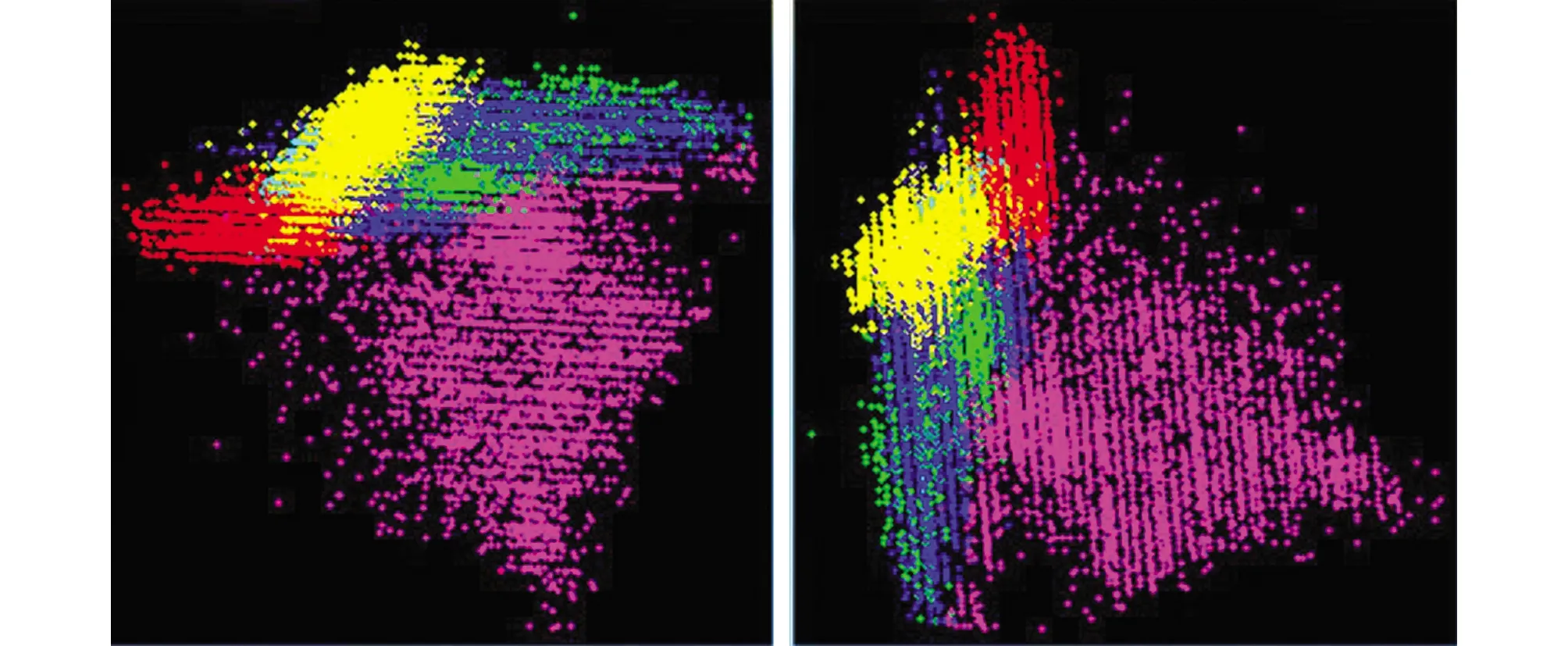
林地(红色)、 道路(绿色)、 农田(黄色)、 水体(蓝绿色)、 建筑(紫色)和大棚(蓝色).图5 不同训练样本在三维空间上的分布
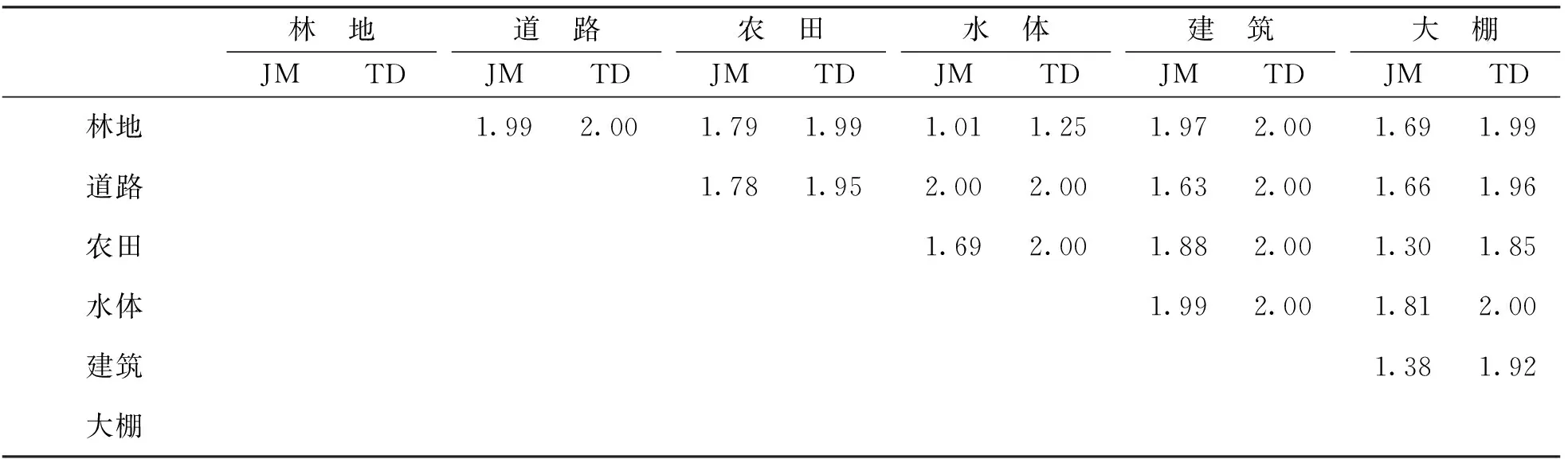
表2 ROI样本可分离性
3.2 地物分类对比分析
图6为RF算法(a)、 SVM算法(b)和ANN算法(c)提取的研究区地表类型分类结果.对比图6a、 图6b和图6c可以看出,在相同的训练样本条件下,RF、 SVM和ANN 3种分类算法分类结果差异相对较大,尤其是水体和林地两类地物分类差异最明显.结合原始高分数据(图1)目视判断可知,RF算法的分类结果与原始高分数据中地类分布较为一致,SVM和ANN算法分类结果中明显存在大量林地像元被错分为水体和农田的现象,ANN算法分类结果中还存在道路像元被错分为大棚.
本文从原始高分图像中每类地物选择100个检验样本,用于定量评估各算法的分类精度.表3、 表4和表5分别为研究区域RF算法、 SVM算法和ANN算法转移矩阵,从表3中可以看出,检验样本中98.2%的林地、 92.68%的道路和97.85%的农田被正确分类,而在水体分类检验中仅有72.31%的像元被正确分类,建筑和大棚被正确分类的像元百分比分别为79.60%和70.12%.在SVM转移矩阵中,林地、 道路、 农田、 水体、 建筑和大棚的正确划分百分比分别为69.40%、 86.26%、 98.11%、 73.95%、 80.75%和39.59%.ANN算法分类转移矩阵中,林地、 道路、 农田、 水体、 建筑和大棚的正确划分百分比分别为63.95%、 38.44%、 97.65%、 75.42%、 77.67%和37.02%.对比可知,RF分类结果中林地、 道路和大棚3类地物被正确分类的比例与SVM和ANN算法分类结果间存在较大差异,且RF分类结果中正确分类像元所占百分比均高于SVM和ANN算法.
总精度验证结果表明(表6),RF算法的总体分类精度为85.74%,Kappa系数为0.828; SVM算法的总体分类精度为73.17%,Kappa系数为0.679; ANN算法的总体分类精度为63.80%,Kappa系数为0.57.表明在复杂地表环境下RF算法地表分类精度最高,SVM次之,ANN算法的分类精度最差.为详细分析3种算法不同地物的分类精度,本研究通过转移矩阵获得RF、 SVM和ANN 3种算法不同地物的精度评价结果(表6).除建筑地物外,其余地物SVM算法的错分误差均高于RF算法,而ANN算法所有地物的错分误差均高于RF算法.尤其是道路、 水体和大棚3类,ANN算法错分误差高达49.59%、 40.87%和49.99%; SVM算法错分误差高达50.97%、 40.61%和25.28%; 而RF错分误差则为33.68%、 2.11%和13.53%.ANN算法林地、 道路和大棚的漏分误差分别为36.05%、 61.56%和62.98%; 相对应的SVM算法的漏分误差分别为30.60%、 13.74%和60.41%; RF算法的漏分误差分别为1.80%、 7.32%和29.88%.RF算法林地、 道路和大棚的制图精度(98.20%、 92.68%和70.12%)均优于SVM算法(69.40%、 86.26%和39.59%)和ANN算法(63.95%、 38.44%和37.02%); 除建筑地物RF算法用户精度与SVM算法相近外(RF为98.55%; SVM为98.99%),其余各类地物RF算法的用户精度均高于SVM算法和ANN算法.
以上精度验证结果表明,在复杂地表环境状态下,基于RF算法地物分类精度要优于SVM算法和ANN算法,尤其是林地、 道路和大棚3类地物RF算法分类精度与SVM算法分类精度之间具有较大差异; 而相较于ANN算法,RF算法在各地物的分类精度均优于ANN算法.综上所述,本研究将采用RF算法实现复杂地表环境下地物覆盖类型的精确提取.
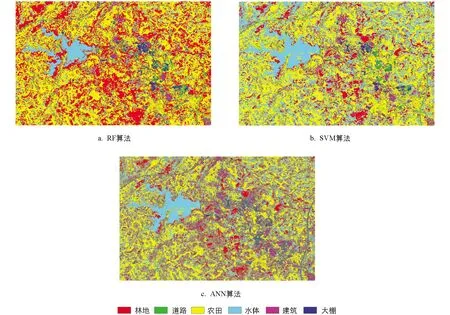
图6 基于RF算法(a)、 SVM算法(b)和ANN算法(c)试验区地表分类结果图
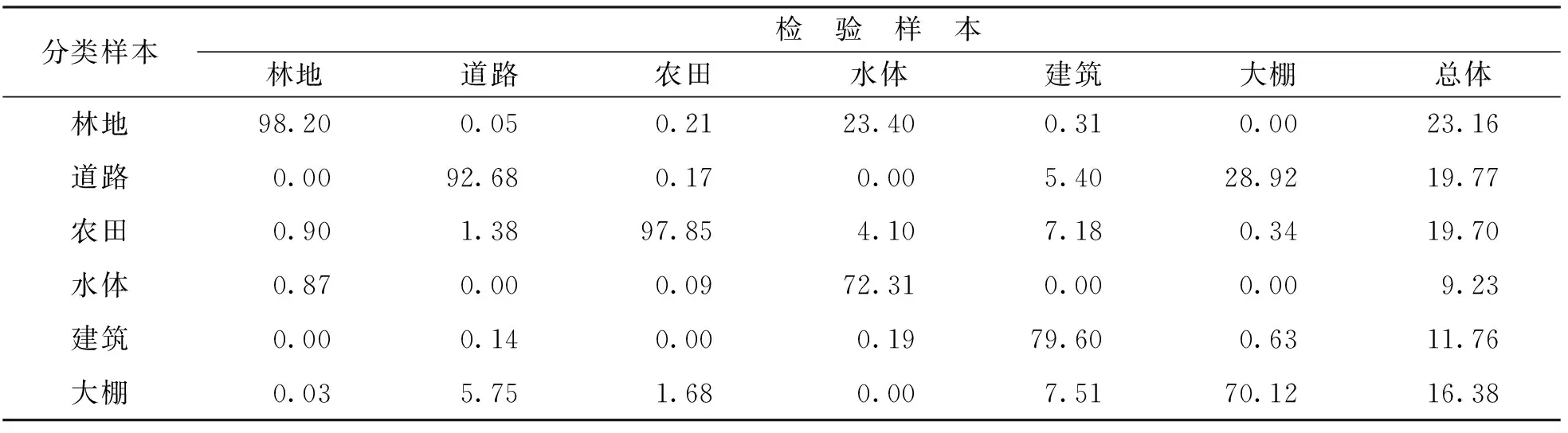
表3 RF转移矩阵
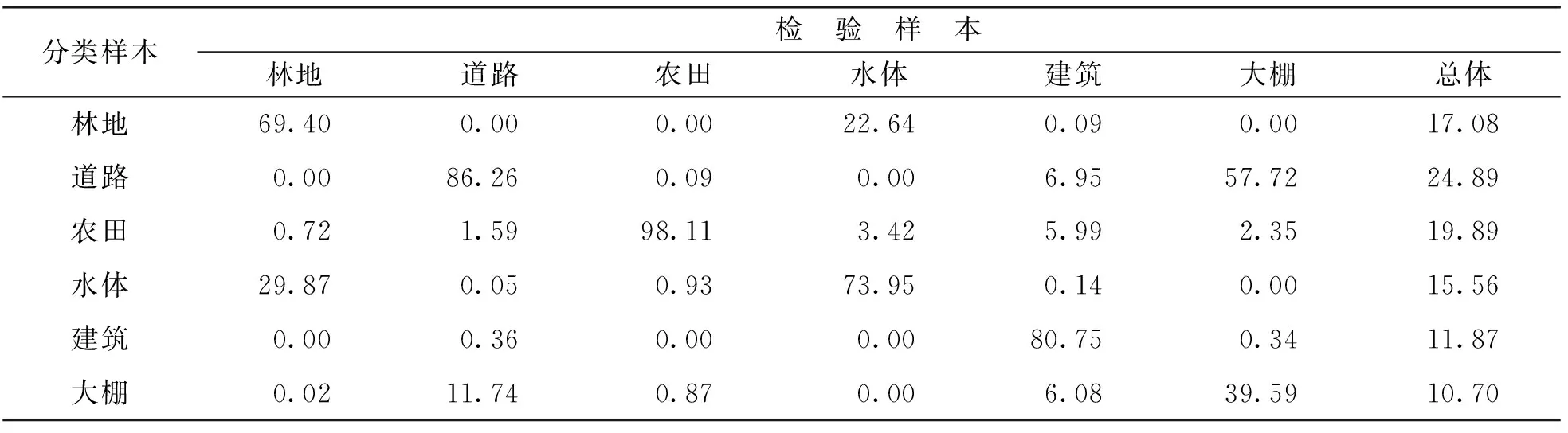
表4 SVM转移矩阵 %

表5 ANN转移矩阵 %
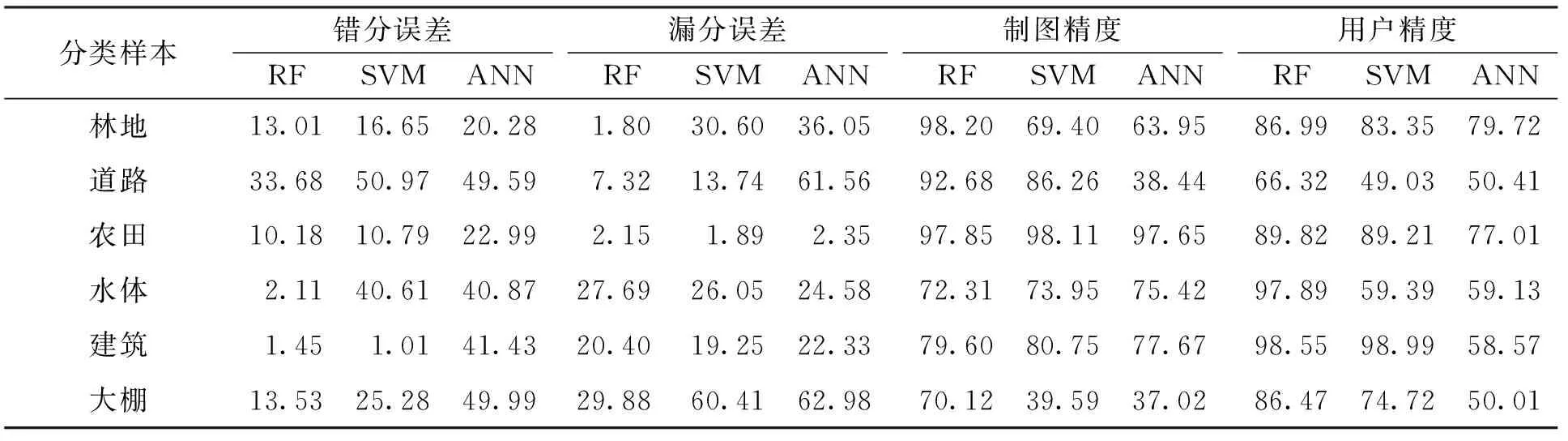
表6 精度评价结果
3.3 RF算法地物分类后处理
3.3.1 区分易混淆像元
虽然在复杂地表环境下,RF算法的分类精度明显优于SVM算法.但结合RF地表分类结果(图6a)和转移矩阵(表3)中可以发现,RF分类结果中依旧存在部分林地和水体、 道路和大棚像元错分和漏分现象(图7).对比真彩色高分遥感图像,图7a黑色框体内地物类型为水体,而在RF分类结果图7a′中,该区域被错分为林地; 在图7b中,黑框内地物类型实为大棚,而在RF分类结果图7b′中,该部分像元被错分为道路.精度评价表6显示,RF分类结果中林地、 道路、 农田和大棚的错分误差均超过了10%,水体、 建筑和大棚的漏分误差超过了20%.较大的错分和漏分误差,使得基于RF算法直接得到的地物分类结果不满足当前精细化遥感业务的需求,因此,针对机器学习分类结果的处理至关重要.
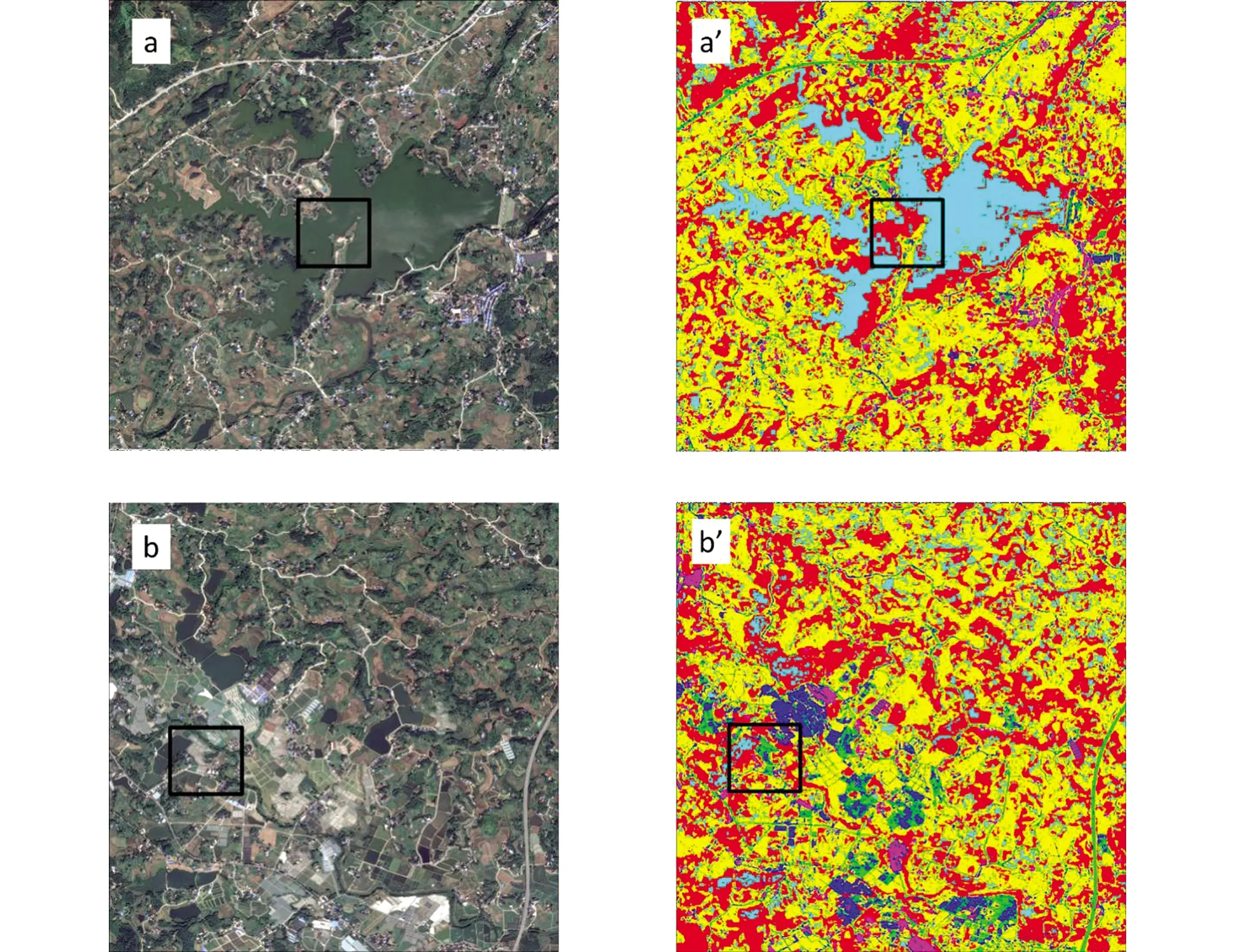
图7 部分区域GF-1真彩色图像(a、 b)与对应的RF分类结果(a′、 b′)
通常,利用机器学习和人工目视解译相结合的方法可以实现分类后数据的再处理[4].虽然人工目视解译的加入会提高高分辨率遥感数据地物分类的精度,但该方法存在工作量大、 效率低等缺点.本文通过对RF地物转移矩阵(表3)的分析发现,分类结果中易混淆的地物类型主要为林地和水体以及大棚和道路,这是因为RF算法是通过训练样本的光谱特征来区分地物,而本文仅从GF-1 RGB波段组成的真彩色图像中选择的训练样本,常存在异物同谱或同物异谱现象,致使水体与林地,以及大棚与道路像元混淆难以区分.
为快速准确地实现易混淆像元的区分,作者对研究区内各典型地物分别提取了50个像元样本(图8),并统计了典型地物样本的NDVI值(图9).NDVI统计结果显示,水体和林地之间NDVI值相差较大,林地像元NDVI值介于0.5~1.0之间,水体像元NDVI值小于0,通过NDVI值域范围的差异能快速分离混淆的林地和水体像元.
大棚和道路两类地物,由于其光谱特性接近,加之其NDVI值也接近(图9),直接通过RF算法和NDVI无法将两者区分开.但我们发现两地物在形状上存在明显的差异,道路接近于线状,大棚更接近于面状.本文利用IDL程序语言,以道路(或大棚)为中心像元,建立了一个101×101的移动窗口(图10),通过统计移动窗口内道路(或大棚)像元占总像元的百分比可以发现,3个试验区道路像元占总像元的百分比分别为8.66%、 4.77%和15.46%; 3个大棚试验区像元占比分别为48.24%、 32.14%和45.84%.通过以上分析我们发现,带状道路在移动窗口内像元占比小于20%,而成片的大棚在移动窗口内像元占比高于20%.因此,本文设定以20%像元占比为划分界限,当满足中心像元为道路(或大棚),且101×101移动窗口内道路(或大棚)像元所占百分比大于20%,则认定该中心像元为大棚; 反之,当道路(或大棚)像元所占百分比小于20%,则判定该中心像元为道路.
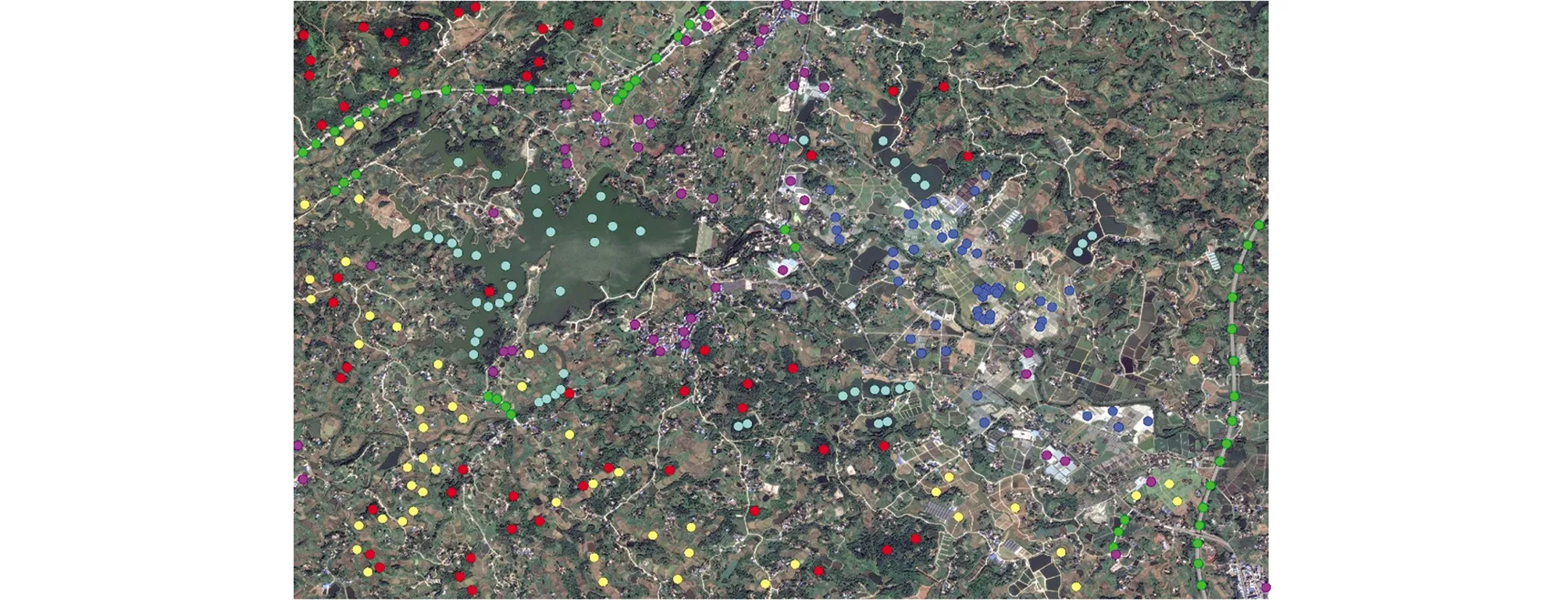
红色为林地,绿色为道路,黄色为农田,浅绿色为水体,紫色为建筑,蓝色为大棚.图8 各类地物特征分析提取点
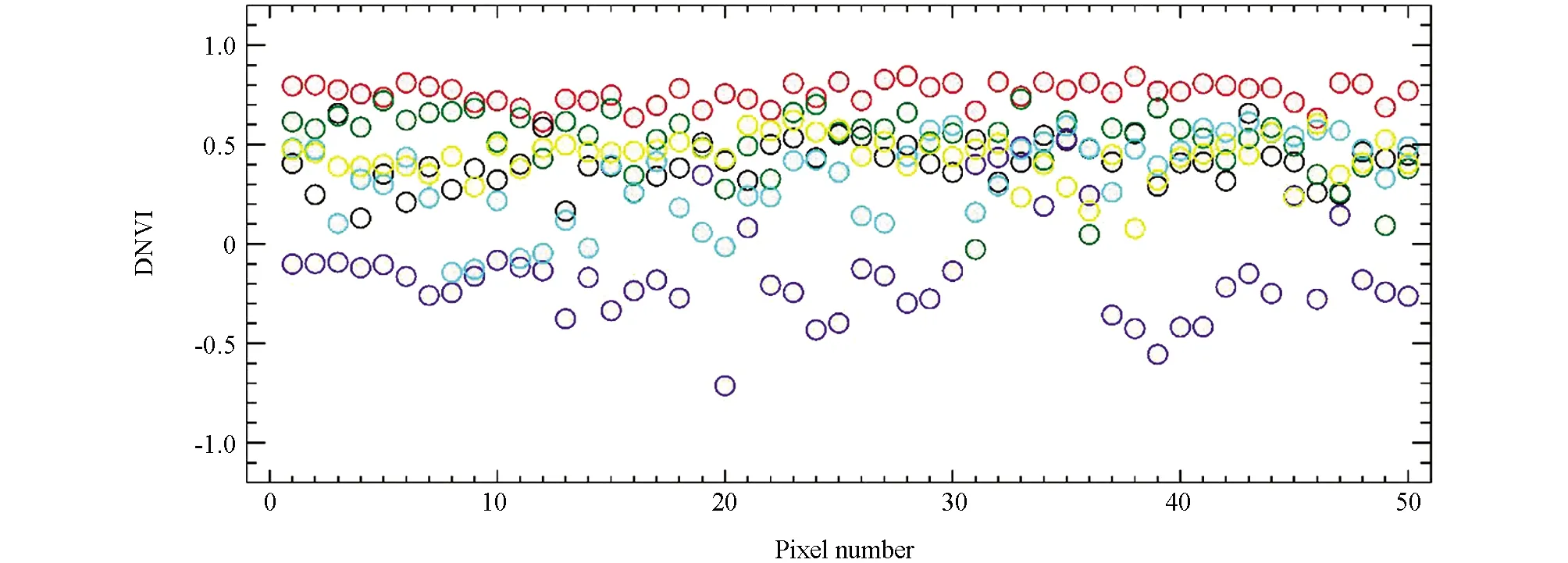
红色为林地,绿色为道路,黄色为农田,浅绿色为水体,紫色为建筑,蓝色为大棚.图9 研究区内典型地物NDVI值分布图
图11为经上述判定规则修改后的分类结果.对比图10a-10c与图11a-11c,基于道路和大棚形状上的差异,道路中夹杂的被错分为大棚的像元已经被修正为道路像元,提高了道路的完整性和连续性.对比图10d-10f与图11d-11f可知,在图10e和图10f中大量被错分为道路的像元,经形状因子判识后,将其正确修正为大棚类,并且在图10d中穿插在大棚间的道路像元依旧被较好地保留.以上结果表明,基于形状因子能较好地将大棚与道路地类区分开,修正后的分类结果与地表真实覆盖情况相符.图11g和图11h分别为基于NDVI值修正前后区域内地表分类结果,图11g显示,RF分类结果中部分林地像元被错分为水体像元,而经NDVI值修正后(图11h),错分像元被正确地修正为林地像元,表明利用林地和水体NDVI值域范围的差异能较好地区分两类地物,对提高RF地物分类精度有重要帮助.
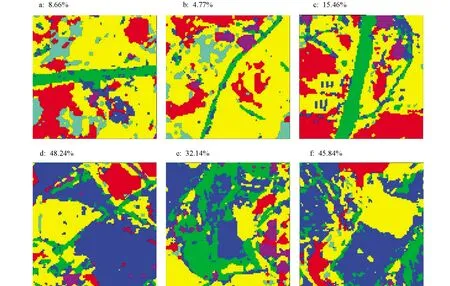
图a-c中心像元为道路; 图d-f中心像元为大棚.百分比值为中心像元对应地物的面积占移动窗口总面积的百分比.图10 移动窗口内地物分布情况
3.3.2 小图斑处理
采用机器学习算法得到的分类结果一般为初步结果,分类的精度难以达到实际业务应用的要求,虽然基于形状特征和NDVI值域差异等特性实现了RF分类结果中混淆像元的修正,但从图11中清晰地看出,修正后的分类结果中存在部分面积较小的小图斑,这部分小图斑不仅会影响后期专题图的制作,在实际应用中也会带来干扰.因此,极有必要对该部分小图斑进行剔除或重新分类.
本文利用ENVI遥感图像处理平台中的Majority/Minority分析工具将较大类别中的虚假像元归到该类中,并借助Clump工具将邻近的类似分类区域聚类并进行合并,从而实现了RF分类结果中小图斑的去除,使得调整后的RF分类结果更符合实际情况.最后利用GIS软件,将栅格数据转换为矢量文件,以供后期分类结果的统计和专题图的制作(图12).
4 结论与讨论
4.1 结 论
为对比RF、 SVM和ANN算法在复杂地表环境下地物分类的能力和适用性,本文以重庆市永川区为例,以国产GF-1 PMS遥感数据为数据源,分别采用RF、 SVM和ANN算法实现研究区内地表覆盖类型的提取.对比结果表明: ① 利用原始GF-1数据目视判断可知,在训练样本相同的条件下,RF算法分类结果与原始高分数据中地类分布较为一致,SVM算法分类结果中明显存在大量林地像元被错分为水体的现象,ANN算法分类结果中还存在大量道路像元被错分为大棚.② 精度评估结果表明,RF算法地物分类精度要优于SVM和ANN算法,尤其是林地、 道路和大棚3类地物RF算法分类精度与SVM和ANN算法分类精度之间差异较大.
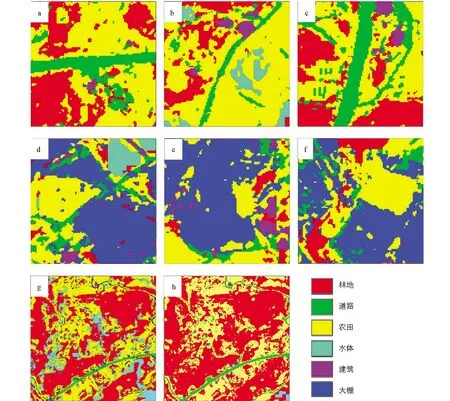
道路(a~c),大棚(d~f),水体与林地(g、 h).图11 修正RF分类结果中的混淆像元
虽然在复杂地表环境下,RF算法的分类精度明显优于SVM算法,但RF分类结果中依旧存在部分林地和水体、 道路和大棚像元错分和漏分现象,不能满足当前精细化遥感业务的需求.本文利用易混淆像元在NDVI和形状上的差异,实现了RF分类结果中易混淆像元的修正,从而提高了地物分类的精度.而后,利用ENVI和GIS软件实现了RF修正后结果中小图斑的去除,栅格数据转换成矢量,并最终制作完成研究区地表覆盖类型分布图.
4.2 讨论与展望
本文虽然利用易混淆像元在NDVI值域和形状上的差异,能较好地实现混淆像元的修正和区分,但依旧存在以下几个问题值得我们继续思考和探究: (1) 复杂地表环境下,混淆在不同背景地物中的目标地物很难通过单一的规则进行提取和修正.虽然利用NDVI值域的差异能较好地区分林地和水体两类地物,但对于建筑和道路两类地物,继续采用NDVI作为区分因子是不合适的.我们可以尝试引入归一化建筑指数(NDBI)作为建筑和道路之间的区分标准,但GF-1 PMS数据中缺少中红外波段,无法生成NDBI,从而失去了区分建筑和道路的能力.(2) 由于矢量数据是由栅格数据转换而成,使得矢量文件中各地物图块边界不平滑.(3) 地物划分种类较少.本文中,作者通过对GF-1 PMS真彩色图像的分析,将试验区地表覆盖类

图a为整个研究区地物分类结果,图b-图g分别为大棚、 道路、 建筑、 林地、 农田和水体分类细节展示图.图12 易混淆像元修正后RF地物分类图
型主要划分为林地、 道路、 农田、 水体、 建筑和大棚,忽略了裸土和草地,这使得被划分为林地的像元中有少量像元真实地表覆盖类型为草地,而裸土像元则更多的被划分为农田.
