基于属性相关分析与聚类的铁路列车时刻表非均衡数据集预处理方法
2021-11-05孔德越周姗琪朱建生闫力斌
孔德越,周姗琪,朱建生,闫力斌,吴 颖
(1. 中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081;2. 中国国家铁路集团有限公司,北京 100844)
随着铁路客运市场化改革的 不断深化,高速铁路动态列车开行方案、“一日一图”等铁路客运精细化管理策略正在逐步实施[1],列车运行图调整(简称:调图)日趋频繁。调图时,不同车次时刻表的变动频率和属性调整范围不尽相同,部分车次时刻表调整频率极低,但调整幅度大,甚至会改变开行区间;部分车次时刻表逐周、逐月调整,但每次仅对某一属性进行小幅微调[2]。对列车时刻表数据进行挖掘分析时,会面临非均衡数据集问题,即数据集中不同车次的时刻表数据样本量差别较大,不同时期运行图中同一车次的时刻表数据样本的属性差异不大。通常,非均衡数据集会对数据分析模型的适用性和准确度产生不利影响,在选择数据分析模型时存在较大局限。因此,解决数据集不均衡问题是高效、准确地提取列车时刻表数据所蕴含信息的关键[3]。
在实际数据分析工作中,为解决非均衡数据集问题,通常需要进行数据预处理。常用的数据预处理方法有重采样算法和惩罚模型算法,这2类算法各有利弊。重采样算法是解决非均衡数据集最通用的一类方法,近年来学术界提出合成数据采样、聚类采样以及集成采样等多种具体算法,其中最常用的是SMOTE算法[4-5]。重采样算法根据需要从原数据集中随机选择数据样本,生成新的均匀数据集,常用于音频、图像数据处理,其缺点是:新数据集与原数据集存在一定差异,且随机性较大,采样结果不可重现,影响后续数据分析中模型的应用效果[6-7]。惩罚模型算法是在分类模型的损失函数中引入惩罚项,通过合理分配错误分类样本的惩罚系数,对样本中数量多、属性值差异小的类别分配更低的误分类惩罚系数,以降低其影响[8];这类方法多应用于样本中分类不均衡的场合[9-10],但对于类别较多的数据集,采用惩罚模型算法会出现数据集权重分配规则计算量大、算法复杂、且惩罚权重选择较为困难等问题。因此,这2类算法无法有效处理列车时刻表非均衡数据集问题。
本文研究提出一种基于属性相关分析与聚类的非均衡列车时刻表数据集预处理方法,可有效合并相似数据,降低数据集中此类相似数据的占比,削弱非均衡数据集对后续数据分析的不利影响,并能保留数据所蕴含的主要信息,是一种行之有效的数据预处理方法。
1 列车时刻表属性相关分析
1.1 列车时刻表数据集特征
目前,在我国铁路运输生产中,调图是一项经常性工作。每次调图时,会对列车时刻表的始发时间、停站方案、运行编组等属性进行调整[11-12]。由于不同车次的时刻表调整频率不同,一段时期内不同车次的时刻表数据记录的数量存在较大差异,形成不均衡的列车时刻表数据集;不同车次时刻表调整幅度不尽相同,调整较大的会对列车运营造成较大影响,而有的车次仅只微调时刻表的某个特定属性,调图前后的列车运营情况基本一致,可将这些车次调图前后的时刻表数据记录视作重复数据样本。
为此,在对列车时刻表数据进行预处理时,判断是否合并样本数据,主要考察属性值变化是否对列车运营产生显著影响:对于不显著影响列车运营的时刻表调整,视为列车时刻表记录的属性值无显著变化,故将调图前后的数据记录合并后生成一条新的记录,原记录中相同的属性值保留在合并后的新记录中,而不同的属性值则经同化处理得到新记录对应的属性值;对于调图后列车运营情况发生显著变化的车次,该车次调图前后的时刻表记录全部保留,视为不同的数据。
1.2 列车时刻表属性与列车运营指标的相关分析
列车时刻表调整涉及的主要属性包括:列车始发/终到时间、停站个数、开行区间等。列车运营通常采用旅客发送量、旅客周转量、列车客票收入及客座率等指标进行评价,本文选用客座率作为被解释变量[13-14]。
鉴于普速列车与高速铁路动车组列车是不同性质的客运产品,需分别分析两类列车时刻表属性调整对列车运营的影响。使用历史上几次大规模调图前后的列车运营数据,对调图前后两类列车的客座率变化与列车时刻表属性变化进行相关分析。
1.2.1 未调整时刻表的列车
未调整时刻表的列车总样本数共计4 031条,采用单因素方差分析法(one-way ANOVA),分析调图日前后这些列车的客座率是否发生显著变化,检验结果如表1所示。表中:SS表示离均差平方和,df表示组间自由度,MS表示均方差,F表示F检验的检验值,P- value表示F检验的结果值,即出现F值的概率,其小于0.05时可以认为两组数据相同的可能性较小,存在显著差异,F crit表示结果显著时F值的临界值。故结果显示,调图后未调整开行计划的列车客座率降低0.2%,方差分析P=0.986>0.05,由此表明:在观察期内,未调整时刻表的列车客座率没有显著变化。
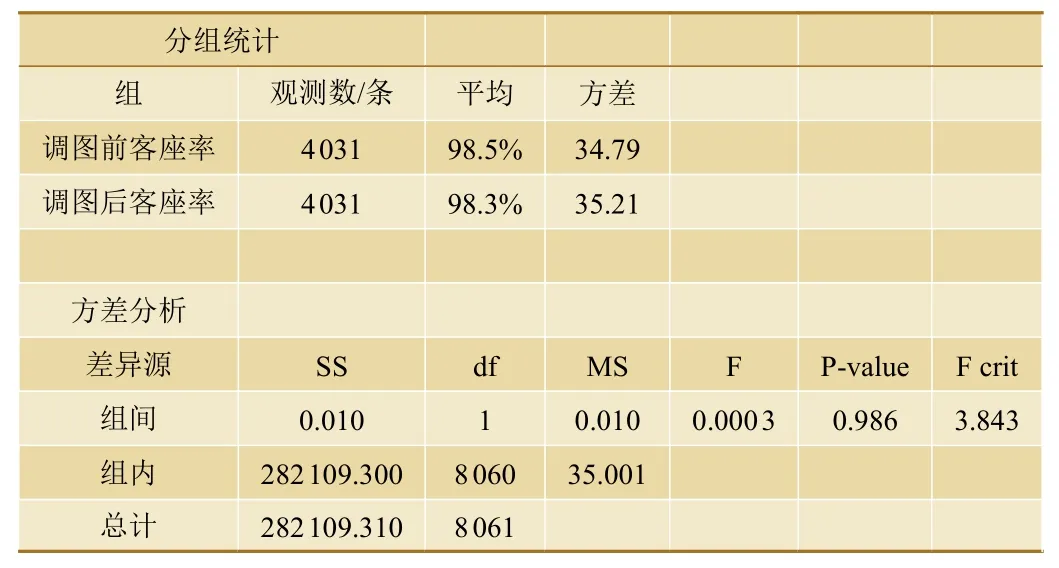
表1 调图前后单因素方差分析结果
1.2.2 仅调整始发时间的列车
对于列车时刻表数据集中仅调整始发时间的列车,按始发时间调整幅度划分为7组,分别对列车始发时间调整时长与列车客座率变化进行相关性分析,如图1所示。

图1 调图前后列车始发时间调整与列车客座率变化的相关分析结果
由图1可知:(1)动车组列车始发时间调整在30 min以内,对列车客座率变化无显著影响;列车始发时间调整在30 min以上,对列车客座率变化有显著影响;(2)普速列车始发时间调整在60 min以内,对列车客座率变化无显著影响;列车始发时间调整在60 min以上,对列车客座率变化有显著影响。
1.2.3 调整停站个数的列车
对于列车时刻表数据集中开行区间(即列车始发站与终到站)不变、始发时间不变、仅调整停站个数列车,分别对动车组列车与普速列车调图前后列车客座率进行单因素方差分析,其结果如表2和表3所示。

表2 动车组列车停站个数调整后客座率变化单因素方差分析结果
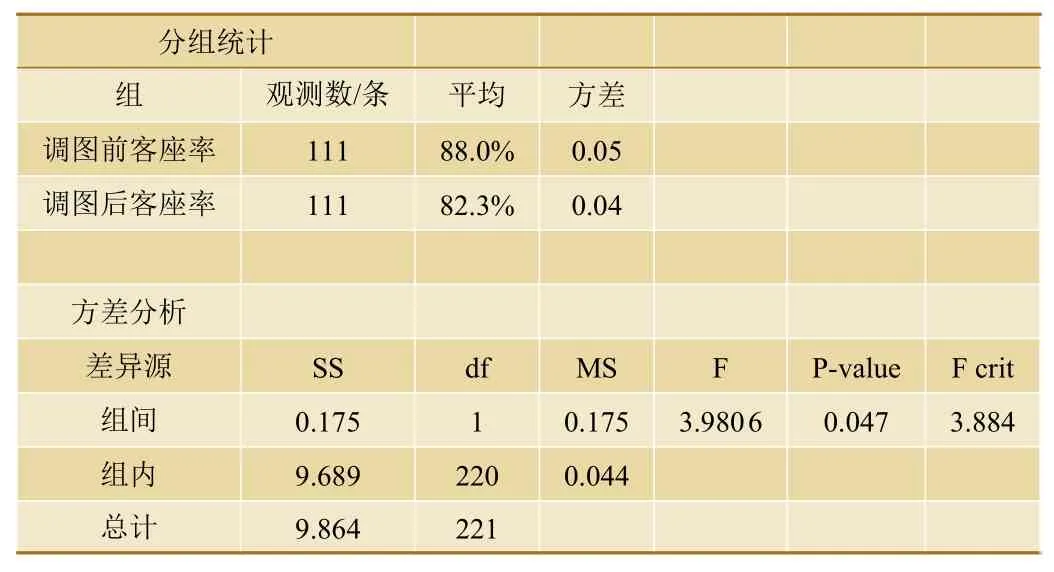
表3 普速列车停站个数增加1站客座率变化单因素方差分析结果
(1)对于动车组列车,当开行区间不变时,不论停站个数如何调整,其客座率均不会发生显著变化(P=0.559>0.05,不显著),即停站个数调整对客座率无显著影响;
(2)对于普速列车,当开行区间不变时,即使仅增加1个停站,其客座率也会发生显著变化(P=0.047<0.05,显著),即停站个数调整对客座率变化有显著影响。
2 列车时刻表数据聚类(合并处理)
由1.2小节的列车时刻表属性相关分析可知:
(1)对于动车组列车,其它属性不变时,如果始发时间调整在30 min以内的列车时刻表样本数据可以进行合并处理;仅停站个数调整的,也可以进行合并处理;
(2)对于普速列车,其它属性不变时,始发时间调整在90 min以内的时刻表样本数据可以进行合并处理;停站个数有调整的,不能进行合并处理;
(3)当动车组列车或普速列车的开行区间发生变化时,客运产品的实质已发生变化,不能进行合并处理。
以某普速列车Z(X)为例,假设某一年度内Z(X)次列车共有4条时刻表数据记录,编号分别为A、B、C、D,如表4所示。其中,记录A与记录B的基础属性相同,记录C与记录D的基础属性中仅始发时间相距1 min,其它属性值相同,记录A、B与记录C、D的始发时间及停站个数不同。

表4 普速列车Z(X) 某一年度时刻表原始数据
因此,可将记录A和B进行合并,以记录A和B的相同基础属性值作为合并后的新记录A'的基础属性值,以记录A和B的运营结果之和作为新记录A'的运营结果。同理,对记录C和D也进行合并,以开行天数更多的记录D的基础属性值作为合并后的新记录B'的基础属性值,以记录C和D运营结果之和作为记录B'的运营结果,如表5所示。

表5 普速列车Z(X) 列车时刻表数据的预处理结果
由表4和表5可知:对普速列车Z(X)时刻表数据进行聚类处理后,普速列车Z(X) 原先的4条数据记录可合并为2条运营结果不同的数据记录,既消除了属性值相似数据记录造成的数据集重复问题,又能够保留属性值差异对运营结果的影响特征,可有效提升列车时刻表数据质量。
3 一般数据集的属性相关分析与聚类算法
对于具有与列车时刻表相同特征的非均衡数据集,即不同类别的数据记录数量差异较大、相同类别的数据记录属性值相似,可使用基于属性相关分析与聚类算法进行预处理,具体处理流程如下。
(1)初步清洗数据集:纠正明显的错误数据,如检查出有异常值或缺失值的数据记录,对其进行修正、填充或将错误记录删除,统一属性值格式。
(2)连续属性离散化:对数据集中所有连续属性进行离散化划分,通过分组分析找出某一属性引起被解释变量显著变化的属性值差异的最小值;进行属性离散化划分时需要根据数据集特征慎重权衡划分粒度,如果划分粒度过大,会导致找出的最小属性值精度不足,而划分粒度过小则会导致计算量增大,影响效率。
(3)确定对被解释变量产生显著影响的属性值差异阈值:采取控制变量法,选取待分析属性值不同、其它属性值相似的数据记录,将待分析属性值离散化分组后,根据属性值大小对各组数据进行升序排列;对首组数据的属性值与被解释变量进行相关性分析,当皮尔森相关性系数达到0.3时,首组数据的属性值变化对被解释变量产生显著影响,此时设定阈值为0,即该属性值的任意变化均对被解释变量有显著影响;若相关性系数小于0.3,则按顺序依次选择首组数据与后续组别数据,分别进行单因素方差分析;当单因素方差分析结果值P<0.05时,两组数据间的属性值差异对被解释变量产生显著影响,此时设定阈值为两组数据属性值下限的差值。
(4)数据集聚类:将其它属性值相同、单属性值差异小于(3)中所确定的阈值的数据记录聚类后进行合并,保留共有属性值,以各记录非共有属性值的均值,或选择其中最重要记录的属性值作为该属性的新属性值,并将各记录的被解释变量按业务规则进行汇总得到新的样本数据,新的数据样本包含合并前各样本数据的主要信息。
4 结果检验与分析
为验证基于属性相关分析与聚类的数据预处理算法的有效性,采用不同的数据预处理方式生成训练集,再利用相同的分析模型对列车客座率进行预测,以检验不同的数据预处理方式对预测结果的影响。
使用某年度历次调图前后的全部列车时刻表数据和列车运营统计数据(即客座率)作为训练集,数据记录属性包括开行区间、始发时间、停站个数、客座率,以次年的数据作为测试集。针对训练集的数据样本非均衡性问题,分别采取不处理、重采样、属性相关分析与聚类3种数据预处理方式,生成3组样本数据;使用R语言,分别利用这3组样本数据训练K近邻算法模型(KNN),再用相同的测试集对列车客座率进行预测,以检验该模型的预测准确度,对应的预测效果对比如表6所示。

表6 3种数据预处理方式对应的KNN算法模型的预测效果对比
由表6可知:未经预处理的原始样本预测准确率最低,为77.9%;重采样处理后的训练集样本数量为2 303条,预测准确率为79.3%,能够有效降低模型计算量,但由于重采样导致未被采样记录所蕴含信息的丢失,限制了预测准确度的提升;经属性相关与聚类算法处理后的训练集样本数量为2 511条,预测准确率达到81.4%,表明该算法对减轻预测模型计算量和提升模型准确度均有良好效果。
5 结束语
针对列车时刻表非均衡数据集的特征,研究提出基于属性相分析与聚类的数据预处理方法,以客座率为被解释变量,分别对动车组列车和普速列车在调图前后的客座率变化与列车时刻表属性变化进行相关分析,依据分析结果完成列车时刻表数据聚类处理;归纳提出一般数据集的属性相关分析与聚类算法流程,适用于具有相似特征的非均衡数据集的数据预处理。经分析验证,此方法可在有效保留原始数据集主要信息的前提下,将属性值相似的数据进行合并,提高数据集质量,有助于减少数据分析计算量,降低过多相似数据对模型分析效果的影响,为后续的数据分析和挖掘提供有利条件。
