ES+Pandas实现文档中数据提取
2021-11-03卡斯柯信号有限公司刘艳青王婷婷
卡斯柯信号有限公司 刘艳青 王婷婷
众所周知,典型的软件生命周期模型包括:迭代模型、快速原型模型、V模型、W模型。每个模型中都必然包含的几部分:需求、用例、报告。需求的作用往往是决定了软件功能的走向,用例是根据需求描述设计出来并对软件功能进行测试的参考依据,报告往往是决定软件是否能够发布的重要参考要素。报告中一般要罗列出需求、用例的最终状态,遗留的问题以及需求、用例的测试通过率等等。需求和用例在逻辑上存在N对N的关系,部分公司使用线上系统,将需求和用例条目化管理,这样就能很好的根据用例状态提取需求的状态,但是也有大部分公司使用word文档管理需求和用例,这种情况将耗费大量的人力在测试报告的编写上。
1 现状
对于小型的软件而言,可能只有1份需求、1份用例,对于这种软件而言,编写报告的难度并不大,也可以人工完成。但是如果是一个大型的系统,例如1个系统包含5个子系统,每个子系统中又包含多个软件,那么这个项目的文档工作将是巨大的,尤其是测试完成后报告的数据收集将是一个非常耗时的过程,以我们公司的产品为例,新系统报告编写的时间一般是在2周左右。进一步分析会发现,大部分的时间是用在需求状态的收集上。主要原因是最上层的大系统无法精准的测试一些功能,因此需要子系统或者软件级完成测试,或者需要多个子系统共同完成测试,因此这部分需求会直接分配给其它阶段。但是系统级的报告中又需要收集这些需求的状态及证据,这个收集的工作会涉及到不同的部门不同的人员,因此整个工作特别耗时,如何能够提高这项工作的效率呢?首先需要了解人工收集这些状态需要参考的文档,然后根据人工查找的逻辑,将整个工作程序化。用工具代替人力收集需求状态。
2 尝试使用ES+Pandas实现文档中数据的收集
非关系型数据库中ES因交互性好,支持全文检索、倒排索引、对文档内容的搜索速度快的特点,经常被用于实时日志分析。因此,对于使用word及excel管理需求、用例和报告的项目,ES可以更快的查询到需求对应的用例及用例的执行结果。
首先,要将word及excel中需要的信息,条目化并存到ES数据库中,这里建议使用正则表达式识别要存储的内容,使用正则表达式的前提就是,需要提取的内容要满足一定的格式要求,例如有明确的起始与结尾标识。一个标准的需求一定是要包含需求ID,需求内容,需求属性标签的,可以根据业务需求,通过正则表达式将后续要用到的信息全部提取出来,本文主要提取了需求ID、需求内容及需求来源。一个标准的用例一定是包含用例ID,用例描述,执行步骤,追踪的需求等。本文主要是提取了用例ID,用例描述,追踪的需求ID。对于每一个阶段的测试,都有一个对应需求的分配情况,本文称作VAT表格,这个表格中包含了需求ID,需求描述,需求属性及分配阶段,这里的分配阶段都是由测试人员提前定义好的。最后需要的就是每个阶段的用例执行结果,包括用例ID、用例描述、用例执行结果、备注等,本文主要提取了用例ID、用例描述、用例执行结果。ES数据库索引结构如图1,各文档存储规则如图2。

图1 ES索引结构
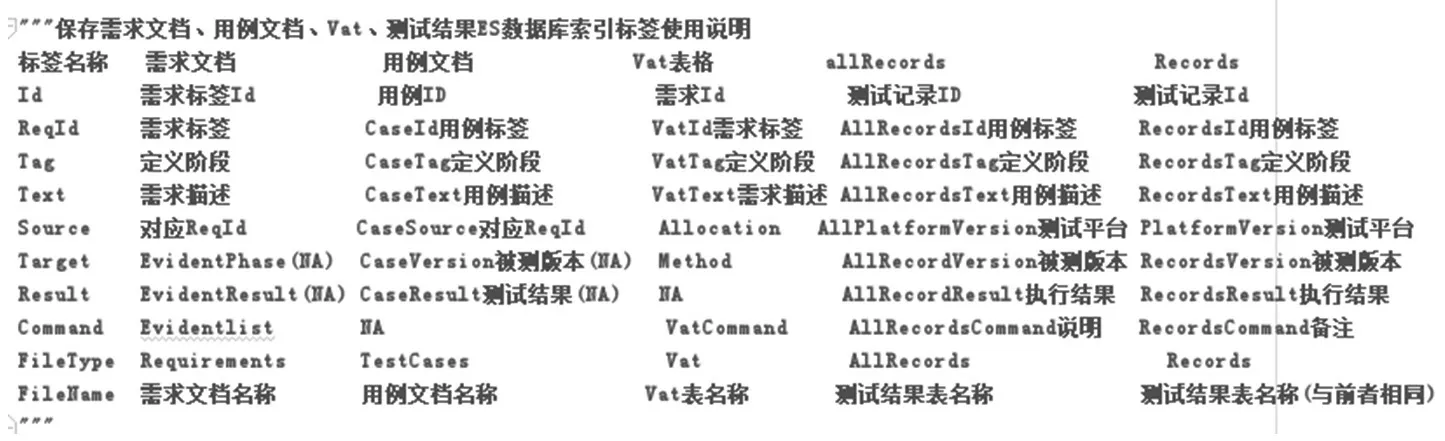
图2 各字段使用情况说明
其次,需要总结整个测试数据生成的逻辑,以图3中这个系统结构为例,大系统1对应的系统需求可能会分给到A、B、C、A1、A2、B1、B2任意一个阶段。

图3 样例项目
如何能够找到对应的需求状态呢?通过整理分析,逻辑大概如下:
(1)分配给本阶段的需求状态:通过本阶段用例的source属性将用例和需求的关系找出来,每条需求理论上是对应了1~N个测试用例,收集这些用例的执行结果,如果所有用例均为通过,则认为需求通过,否则,认为需求不通过。这里需要将关联到的所有用例ID及用例状态、缺陷ID作为证据回填到需求的备注中。
(2)分配给子系统A、子系统B及软件C的需求状态:通过大系统1的需求与子系统A、子系统B或者软件C的需求的关联关系,找到对应的子系统需求或者软件C的需求,再根据子系统需求或者软件需求找到对应的用例ID,最后再查找用例结果。同样需要将最终找到的用例ID及用例状态、缺陷ID作为证据回填到需求的备注中。
(3)分配给软件A1、软件A2、软件B1、硬件B2的需求状态:与第二种情况类似,只是需要通过需求间的追踪关系先找到A1、A2、B1、B2对应的需求,再找到对应的用例。同样需要将最终找到的用例ID及用例状态、缺陷ID作为证据回填到需求的备注中。
逻辑整理出来后,如何实现呢?我们发现,其实每个需求、每个用例、每个测试报告,都相当于一个关系型数据库中的表,他们有自己的属性,每个表之前还有些关联关系,在ES的基础上,如何能够快速实现这样的逻辑呢,这里我们想到了Pandas库,这个库一般用于数据分析,但是在我们这种场景下使用也是非常合适的。我们将每个类型的文档存储为一个DataFrame,可以通过DataFrame的merge方法实现表格的关联,找到需求和用例之间的对应关系,需求和需求间的对应关系等。
用例与需求的对应关系:
pd.merge(Cases_Table,Requirements_Table,how=‘left’,left_on = ‘CaseSource’, right_on = ‘ReqId’)
其中Cases_Table是用例表格,Requirements_Table是需求表格,两个表格使用左连接做关联,左边的Cases_Table使用CaseSource属性,右边的Requirements_Table使用ReqId属性。作用就是,基于用例中CasesSource属性找到对应的需求,然后将他们合并成一张新的表格,以此找到用例和需求的对应关系。
需求与需求的对应关系:
pd.merge(AllRequirements_Table,AllRequirements_Table,how =‘left’,left_on = ‘Source, right_on = ‘ReqId’)
其中,AllRequirements_Table是所有需求表格,两个表格使用左连接做关联,左边的AllRequirements_Table使用Source属性,右边的AllRequirements_Table使用ReqId属性。作用就是基于需求的source找到对应的需求,然后将他们合并成一张新的表格,以此找到需求和需求的对应关系。
总结:如果项目满足如下几个特点,则可以尝试使用ES+Pandas实现报告的自动生成:(1)需求、用例、测试报告使用离线文档存储,文档格式包括:word、excel、csv等;(2)需求、用例、报告可以提取出条目化信息,如每个需求、用例均有清晰的ID、描述及范围;(3)人工通过现有文档能够编写报告,但是编写报告耗时较多。
