战场可疑目标智能识别与跟踪框架研究
2021-10-29管秀云崔令飞修全发
管秀云,史 超,崔令飞,修全发,李 理
(1.中国兵器工业标准化研究所,北京 100089;2.中国兵器工业计算机应用技术研究所,北京 100089)
在现代战场环境中,无人机、高精度卫星等各类尖端侦查设备的广泛应用已经积累了海量的目标图像,如何有效利用这些图像素材以及获取目标关键信息,以便在未来战场中能够智能识别可疑目标、定位敌我已经成为军事领域的研究热点。本文提出了基于海量数据和深度学习的战场可疑目标智能识别与跟踪框架,包括人脸检测与识别、装备目标检测与识别以及可疑目标跟踪等模块。人脸检测与识别基于MTCNN检测人脸位置以及人脸中左眼、右眼、鼻子、左嘴角、右嘴角等5个关键点;装备目标检测基于YOLO v3对装备目标进行位置检测和目标识别;可疑目标跟踪基于BACF算法对标记的可疑目标进行目标跟踪。通过对人脸检测与识别、装备目标检测与识别和可疑目标跟踪等模块构成的智能识别与跟踪框架进行研究,达到对战场典型目标的快速检测与识别以及对标记的可疑目标进行跟踪的要求。
1 人脸检测与识别
人是构成战场情报的最重要因素,设计基于人脸识别的智能算法对敌进行人脸检测和识别,可以统计敌方人数,获得敌方信息,确定敌方位置,了解敌人分布态势等。人脸检测与识别子模块基于MTCNN进行人脸检测与对齐,基于FaceNet进行人脸识别,分类器选用了性能较好的随机森林算法。
1.1 MTCNN网络
Multi-task Cascaded Convolutional Networks(MTCNN)[1]为多任务级联卷积神经网络。它通过三阶的级联卷积神经网络对任务进行从粗到细的处理,每个阶段的网络都是一个多任务网络。处理的任务包括3个:人脸/非人脸判定、人脸框回归和特征点定位。人脸/非人脸判定采用cross-entropy损失函数,人脸框回归和特征点定位采用欧式距离损失函数。定义其损失函数表达式分别为:
为应对人脸目标不同尺度的问题,图像输入调整成为多个尺寸。第1阶段,通过一个浅层的CNN快速生成候选窗口,该CNN全部由卷积层构成,取名P-Net,获取候选人脸窗口以及人脸框回归向量。
第2阶段,通过一个更复杂的CNN否决大量非人脸窗口,从而精简人脸窗口,取名R-Net,第1阶段输出的候选窗口作为R-Net输入,R-Net能够进一步筛选大量错误的候选窗口,然后再利用人脸框回归向量对候选窗口做校正。
第3阶段,使用更复杂的CNN进一步精简结果并输出5个人脸特征点,与第2阶段类似,但是这一阶段使用更多的监督识别人脸区域,而且网络能够输出5个人脸特征点位置坐标。P-Net、R-Net和O-Net 3个阶段的网络结构如图1所示。

图1 P-Net、R-Net、O-Net网络结构图
1.2 FaceNet网络
FaceNet[2]可以直接进行端到端学习,通过获得图像空间到欧式空间的编码方法,然后基于该编码再进行人脸识别、人脸验证和人脸聚类等任务。目标函数采用三元组的表示方法,同时优化了2种策略:线下数据集每N步生成一些三元组;线上生成三元组时,在每一个mini-batch中选择难以确认的正负样例。目标函数表达式为:
FaceNet采用了2种网络模型作为线下的训练模型,第1种模型为NN1的网络结构,共有22层,140万参数需要训练;第2种网络结构采用了GoogLeNet的Inception结构,并且减少了模型的大小,形成了NNS1(2 600万参数)和NNS2(430万参数)。整体网络结果如图2所示。

图2 FaceNet网络结构示意图
1.3 随机森林
随机森林[3](Random Forest, RF)是Bagging的一个扩展变体。随机森林在以决策树为基分类器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。在随机森林中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优解属性进行划分。参数k控制了随机性的引入程度:若令k=d,那么基决策树的构建与传统决策树相同;若令k=l,则随机选择一个属性用于划分,在一般情况下,取值k=log2d。
2 装备目标检测与识别
装备是战场环境中重要的组成部分,设计基于YOLO v3的目标检测与识别模块,可以快速侦测到战场环境下使用的主战坦克、步兵战车、火箭炮等多类别典型陆战武器装备。图像特征提取使用了基于卷积神经网络的Darknet,目标检测与识别基于YOLO的第3个版本——YOLO v3,能够实现复杂战场背景下实时的装备目标检测与识别。
2.1 特征提取网络Darknet-53
YOLO v3[4]沿用了在YOLO v2中的Darknet作为图像特征提取网络,并且网络深度由YOLO v2中的19层增加到53层。Darknet-53采用全卷积形式替换掉Darknet-19中的最大池化层,引入ResNet中的residual结构用来减少网络太深而出现的梯度弥散问题。最终得到的特征提取网络为Darknet-53,包含了52个卷积层和1个平均池化层。网络共使用了包含不同数量和的卷积层构建了23个residual结构,借鉴了Network in Network的思想,最后使用了全局平均池化进行预测,每个卷积层使用批量归一化操作并且去掉了dropout操作,没有出现过拟合现象。Darknet-53与Darknet-19、ResNet-101、ResNet-152的性能对比见表1,Darknet-53的Top-1和Top-5的准确率分别为77.2%和93.8%,分别高于Darknet-19的74.1%和91.8%,同时比ResNet-101和ResNet-152更加有效率。性能测试实验中,GPU均为Titan X,图像的输入尺寸均为256×256。
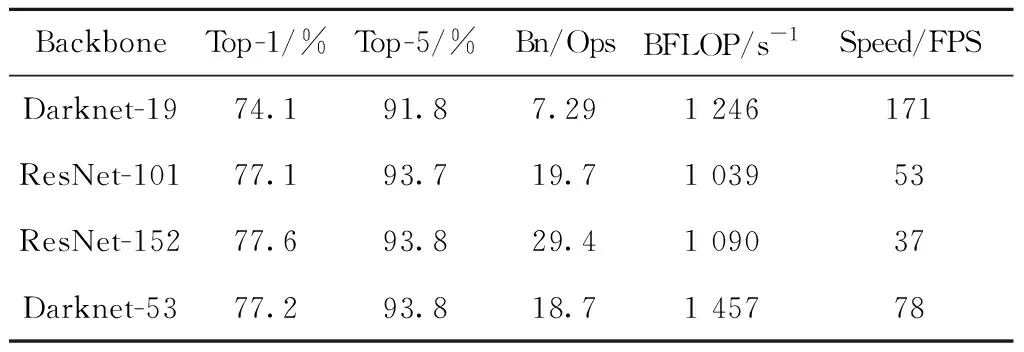
表1 Darknet-53与Darknet-19、ResNet的性能对比
2.2 YOLO v3网络结构
YOLO v3检测网络以Darknet-53为基础模型进行特征提取,并对网络结构进行相应修改,Darknet-53只是作为图像特征提取网络,将原网络的最后一层Avgpool去掉,使得最后的卷积层可以有更高分辨率的特征。和YOLO相比,该结构移除了全连接层,整个网络均为卷积操作,保留了空间信息,最终得到的每个特征点与原图中的每个网格一一对应;和YOLO v2相比,不同于它采用pooling层做特征图的降采样,众多的3×3卷积增加了通道的数量,1×1卷积可以有效提高压缩3×3卷积后的特征表示信息。YOLO v3同样借鉴了Faster R-CNN中的anchor思想:使用k-means算法对数据集中的目标进行维度聚类,确定anchor的大小和数量,YOLO v3共使用了9个anchor。并且没有采用标准k-means算法中的欧式距离来衡量差异,定义了新的距离公式:
d(box,centroid)=1-IOU(box,centroid)
YOLO v3中目标物的边框由bx、by、bw、bh共同决定。tx、ty、tw、th分别表示模型预测的中心点位置坐标、宽和高,cx和cy表示目标物中心点所在网格的坐标,pw和ph表示先验边框的宽和高。则目标物的边框为:
bx=σ(tx)+cx
by=σ(ty)+cy
bw=pwetw
bh=pheth
YOLO v3中采用每隔训练几轮就改变输入图像尺寸的方式,以使模型对于不同尺寸的图像具有稳健性,同时这种操作也加强了对于小目标检测的精确度。YOLO v3采用上采样和融合方法,可以在多个尺度的特征图上进行检测。模型对于小尺寸的输入处理速度更快,因此YOLO v3可以按照需求调节速度和准确率。
YOLO v3与其他目标检测框架性能对比见表2。
传统教学模式的出发点,在教学中忽视了学生的主体地位,没有很好地解决“学生如何去学”这一问题,导致学生在被动学完课程后仍不能熟练地综合应用课程的内容、原理和方法。学生主动性不足,必然导致学习效率不高。
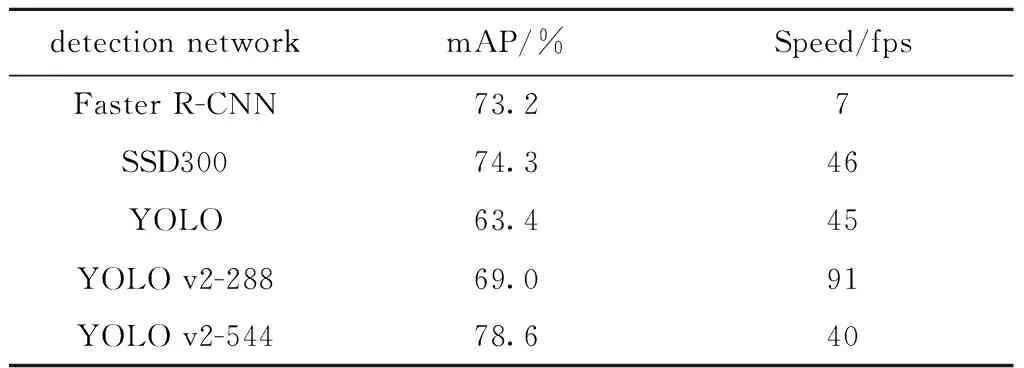
表2 目标检测框架性能对比
3 可疑目标跟踪
基于BACF算法对于战场出现的可疑目标进行标记,然后对标记目标进行实时跟踪。
Background-Aware Correlation Filters(BACF)是Hamed Kiani提出的基于HOG特征的目标跟踪算法。采用较大尺寸检测图像块和较小尺寸滤波器提高真实样本的比例,滤波器填充0以保持和检测图像一样大。算法为最小化目标函数:
式中,P是一个D×T的二值矩阵;xk∈RT;y∈RT;h∈RD且T≫D。目标函数可以用下式表示;

采用ADMM算法可以近似得到g和h的最优解,分别为:

4 战场目标智能识别与跟踪框架
4.1 算法总体框架
目标智能识别与跟踪框架包括人脸检测与识别、装备目标检测与识别和可疑目标跟踪等3个模块。人脸识别、装备检测与识别采用线下模型训练与线上模型调用相结合的方式,用于识别数据库中已经存储的人物目标和主战坦克、步兵战车以及火箭炮等各式陆战装备。人脸检测与可疑目标跟踪采用无监督的方式,直接进行线上人脸的检测与被标记可疑目标的跟踪。框架各模块之间的关系如图3所示。

图3 智能检测与识别框架模块图
人脸检测基于MTCNN中P-Net、R-Net和O-Net 3个网络;人脸识别基于FaceNet网络结构,并且使用FaceNet在2个庞大的数据集Wild和YouTube Faces上训练的模型参数作为初始参数,以采集到人脸图像作为训练集进行训练;装备目标检测与识别以YOLO v3在CoCo数据集上训练的模型参数作为初始参数,以采集到的主战坦克、步兵战车和火箭炮等图像作为训练集进行训练;可疑目标跟踪基于BACF算法不断更新带有拉格朗日乘子的目标函数,得到最优的和,达到线上实时的目标跟踪策略。智能识别与跟踪框架算法流程如图4所示。

图4 智能检测与识别框架算法流程图
4.2 数据采集与仿真实验配置
装备目标图像库通过互联网爬取了20种主战坦克、步兵战车和火箭炮等陆战主要装备的图像;人脸目标图像库通过互联网爬取了10位在战争片中饰演士兵的角色人脸进行仿真试验,每一个角色选取不少于300张人脸图像构成训练集。装备目标图像利用图像增强技术进行数据集的扩充,所采用的方法包括水平翻转、一定程度的位移和翻转,添加椒盐噪声、高斯噪声以及改变图像的对比度、亮度等[5]方式,达到增加图像训练样本的目的。
基于数据增强技术[6],装备目标图像扩充至20种,每种200张图像;人脸识别图像为10种,每种3 000张图像。训练模型使用单GPU,型号为GeForce GTX 1070,显存为8G,CPU型号为Inter(R) Core(TM) i7,操作系统为Windows 10,深度学习框架为TensorFlow和Kreas。
4.3 仿真实验结果分析
4.3.1 人脸检测与识别
人脸检测使用Opencv读取图像或者从摄像头读取视频帧,基于MTCNN网络对图像中的人脸进行检测,在自然光环境下,可以做到人脸表情变化更具有鲁棒性,同时内存消耗不大,可以实现实时人脸检测。也可以将人脸中眼睛、鼻子、嘴巴等5个关键点进行标记。人脸检测结果如图5所示。

a) 多人人脸与关键点检测

b) 单人人脸与关键点检测
人脸识别采用仿真实验数据,获取训练集同样基于MTCNN[7]网络,并且将获得的人脸图像剪裁至,以适应FaceNet的输入,采用FaceNet[8]已经训练好的模型参数为网络初始参数,MTCNN中3个阶段P-Net、R-Net和O-Net分别设置阈值,同时设置和的2个参数,分类器采用随机森林算法,设置树的棵数为300。数据集采用五折交叉验证的方式进行验证。取10%作为测试集进行测试,准确率能够达到94.76%。人脸识别结果如图6所示。

a) 有迷彩遮挡人脸识别
由图6可知,王宝强在电视剧《士兵突击》中饰演军人许三多,许三多是10位训练集人物中的一位,将其他王宝强的图像输入到训练好的模型中,同样可以进行人脸识别,说明模型具有不错的泛化能力。
4.3.2 装备目标检测与识别
采用YOLO v3网络对装备目标进行检测与识别,设置网络参数为score=0.01,iou=0.5,batch=64,learning_rate=0.000 1等,anchors采用YOLO v3默认的9个anchors的大小,分别为:
(10,13),(16,30),(33,23),(30,61),(62,45),(59,119),(116,90),(156,198),(373,326)
当网络迭代次数超过2万次时,各个参数变化基本稳定。随着迭代次数的增加,类别准确率和召回率逐渐接近于1,平均重叠率稳定在0.83。从各参数的收敛情况来看,网络的训练结果比较理想。装备目标检测与识别的部分结果如图7所示。

a) 99A主战坦克检测

b) T-90主战坦克检测

c) ZBD-04步兵战车检测

d) M1A2坦克检测
4.3.3 可疑标记目标跟踪
对测试视频选取第1帧图像作为基准,对可疑目标进行标记,基于BACF算法[9]对测试视频中的被标记目标进行跟踪。在10个10 s测试视频中,跟踪准确率为80%,输出速率为18 fps。对视频3选取第10帧、第167帧、第330帧输出如图8所示。

a) 第10帧

b) 第167帧

c) 第330帧
5 结语
本文将人脸检测、人脸识别、装备目标检测与识别、可疑目标跟踪等子模块融合构造战场可疑目标智能识别与跟踪框架,对战场图像情报的获取与积累具有一定的意义。本文所构造的人脸识别和装备识别模型具有较好的准确率,能够满足不同光照条件、不同环境下的目标检测与识别。但是本文也存在一些不足,例如,无法识别较模糊的人脸以及在较复杂背景下会跟丢标记的可疑目标,这都是今后需要研究的方向。
