标签扩展的协同过滤推荐算法 *
2021-10-26陈海龙闫五岳孙海娇
陈海龙,闫五岳,孙海娇,程 苗
(哈尔滨理工大学计算机科学与技术学院,黑龙江 哈尔滨 150080)
1 引言
随着互联网技术的迅速发展,互联网人口快速增长,随之导致网上数据呈指数级增长态势,从而导致了严重的信息过载。为了使用户能够快速准确地获取自己感兴趣的物品,推荐系统应运而生。推荐系统能够分析系统中的用户数据,根据用户的喜好为用户推荐商品或服务,能够有效地解决信息过载带来的问题。目前,成熟的推荐算法有很多,如基于内容的推荐[1]、协同过滤推荐[2]和基于关联规则的推荐[3]等。
在有关的推荐算法中,协同过滤推荐算法应用最为广泛。但是,协同过滤模型的一大问题是数据稀疏,该问题影响了推荐算法的推荐质量。为了缓解数据稀疏对推荐算法的影响,研究人员进行了许多尝试。例如Cui等[4]为解决个性化兴趣点POI(Point-Of-Interest)推荐数据稀疏问题,从多角度来扩展协同过滤模型。Guan[5]提出了一种三维协同过滤框架,通过使用用户和项目的特征进行相似度计算来处理数据稀疏性问题。除此之外,为了实现推荐算法的高效性,将深度学习融入推荐算法成为了热点。Mohammad等[6]在推荐系统框架下集成深度神经网络和矩阵分解并使用显示反馈进行协同过滤。Huang等[7]利用基于多注意深度神经网络实现准确的组推荐,采用多注意网络捕获内部社交特征,采用神经注意机制来描述每个组和成员之间的偏好交互。另外,Huang等[8]还提出了一种基于多模式表示学习模型,通过项目的多峰特征和用户的全局特征来计算用户对项目的偏好。Fu等[9]提出了一种基于深度学习的智能推荐,通过学习用户和项目的相应低维向量采用前馈神经网络模拟用户和物品之间的交互。Zhao等[10]提出了一种预测协同过滤方法,利用部分观察到的用户-项目矩阵和基于项目的辅助信息来产生推荐。
近年来,标签[11]的应用越来越广泛。标签是一种无层次化结构的、用来描述信息的关键词[12],它可以用来描述物品的语义。根据给物品标注标签的人的不同,标签应用一般分为2种:一种是专家给物品标注标签,一种是普通用户给物品标注标签,也就是UGC(User Generated Content)。UGC的标签系统可以用来表示用户兴趣和物品语义。社会化标签[13]可以看作用户与物品之间的纽带,将原本不相关的项目联系起来,既表达了用户自身的兴趣爱好,又反映了物品的主题。
基于标签的推荐系统一般应用在音乐网站、视频网站和电影书籍评论网站中,最具代表性的网站有Delicious、Last.fm和豆瓣等。标签系统的最大优势是可以发挥群体智能,获取对物品内容信息比较准确的关键词描述,而准确的内容信息是提升个性化推荐系统性能的重要资源[14]。
基于标签的推荐算法通常使用用户标注项目的频率反映用户的兴趣,用户使用标签的次数越多,则代表该用户越喜欢标签代表的特定项目类别。Ignatov等[15]将标签频率分析应用于标签推荐算法中,用来发现用户的兴趣。Gedikli等[16]认为应该在项目的上下文中考虑标签偏好,并提出了一种在推荐过程中利用上下文的标签偏好的推荐方案。但是以上研究没有考虑到由于用户标注标签的随意性导致的标签信息稀疏问题。由于用户个体不同,用户对相同项目的理解不同,导致不同的用户对相同的项目标记的标签会有所不同,从而导致标签信息的稀疏性。因此,仅通过用户-标签和项目-标签的匹配程度来衡量用户相似度和项目相似度是不准确的。赵宇峰等[17]通过标签聚类降低标签稀疏度,进而提高推荐精度。除此之外还存在以下现象:用户给物品标注的标签不同,但是在语义上可能相近。针对这种现象需要对标签进行语义分析。在语义分析方面,可以利用基于WordNet词典的方法。颜伟等[18]提出了一种基于WordNet的英语词语相似度计算方法,从WordNet中提取同义词并采取向量空间方法计算英语词语的相似度。
在上述研究的基础上,本文提出了一种标签扩展的协同过滤推荐算法。本文通过扩展标签来缓解标签信息稀疏问题,提高算法推荐精度。利用标签相似度进行标签扩展,计算标签相似度的方法有2种:一种是基于用户标注标签的行为进行计算,另一种是根据标签的语义进行计算。现有的标签扩展方法多数是根据标签共现计算基于用户行为的标签相似度实现的,未充分考虑标签的语义相似度。因此,本文从用户行为和标签语义2方面考虑,分别运用标签共现和WordNet词典计算标签相似度。通过结合基于用户行为的标签相似度和基于标签语义的标签相似度,进一步提升标签扩展的效果,进而提升推荐算法的性能。
2 算法设计
传统基于标签的推荐算法,利用标签频率反映用户的兴趣。但是,用户标注标签的随意性,可能会导致出现以下2种情况:
(1)标签t1被用于标注项目ij,标签t2也被用于标注项目ij,相同的项目ij被用户标注了不同的标签t1和t2。
(2)用户u1为项目ij标注了标签t1,用户u2为项目ij标注了标签t2,用户为项目ij标注了不同的标签t1和t2,虽然标签t1和t2不相同,但在语义层面表达了相近的意思。
上述问题导致了在利用标签进行推荐时,与标签相关的用户-标签和项目-标签矩阵稀疏,从而导致推荐精度下降。
为了降低矩阵稀疏度,提高推荐算法的精度,本文提出了标签扩展的思想。在进行标签扩展时,需要先进行标签相似度计算。在计算标签相似度时,根据情况(1)和情况(2)的描述,本文从用户行为和标签语义2方面进行标签相似度计算。
用户为相同的项目标注了不同的标签,根据用户的行为,本文利用标签共现的思想计算标签相似度。利用标签共现来表示标签相似度的基本思想是:如果2个标签在项目中同时出现的次数越多,则这2个标签的相似度就越高。
用户为项目标注了不同的标签,但标签在语义上相同,根据标签语义,本文利用语义分析的思想计算标签相似度。利用语义分析计算标签相似度的基本思想是:判断词语之间的相似度。本文利用WordNet语义词典在信息处理方面的优势,将WordNet应用到标签的语义分析中,用于计算标签相似度。
综上所述,本文提出了一种标签扩展的协同过滤推荐算法。该算法的流程如下所示:
(1)根据数据集构建项目-标签矩阵,并创建标签集合。
(2)利用标签共现信息,计算标签共现矩阵,得到基于用户行为的标签相似度矩阵。
(3)根据标签集合并利用WordNet语义词典计算基于标签语义的标签相似度矩阵。
(4)结合基于用户行为和标签语义的标签相似度矩阵,并利用标签相似度矩阵进行标签扩展,重构项目-标签矩阵。
(5)利用重构后的项目-标签矩阵计算项目相似度,并通过基于项目的协同过滤方法进行推荐。
2.1 基于标签共现计算标签相似度
本文所用的数据集示例如表1所示。正如前面提到的,用户个体不同会导致不同用户对相同项目标注的标签不同,因此本文根据用户标注标签的行为,通过标签共现思想来整合标签之间的相似度。标签共现就是指用2个标签标注同一个项目,如标签t1和t2共同标注了某一个项目,则称标签t1和t2共现。
不同用户可能为相同项目标注不同的标签。正如表1所示,用户20对电影1 747所标注的标签为politics和satire,而用户49对电影1 747 所标记的标签为Robert De Niro。
网站中的用户组成了用户集合U= {u1,…,um},网站中的商品组成了商品(项目)集合I={i1,…,in},用户对商品标注的标签组成了标签集

Table 1 Data format
合T= {t1,…,tk}。根据以上信息构建标注矩阵K,K的大小为n*k,n为项目个数,k为标签个数,矩阵中的元素kpj表示标签tp标注商品ij的次数。根据矩阵K构建共现矩阵C,C的大小为k*k,k为标签个数,矩阵中的元素cpq表示标签tp与标签tq标注同一个商品的频率。本文通过余弦相似度来评估每2个标签的共现分布,即:
(1)
其中,nti,ij表示标签tp标注项目ij的数目,ntq,ij表示标签tq标注项目ij的数目。N(tp)表示标签tp标注的项目集合,N(tq)表示标签tq标注的项目集合。N(tp)∩N(tq)表示标签tp和标签tq共同标注的项目集合。p(tp,tq)在[0,1],且p(tp,tq)越接近1,tp和tq越相似。
通过式(1)得到标签共现矩阵,本文将标签共现矩阵作为基于用户行为的标签相似度矩阵。基于用户行为的标签相似度矩阵C的表达形式如式(2)所示:
(2)
2.2 利用WordNet计算标签相似度
由于用户个体不同,导致用户为项目标注的标签可能不同,但某些标签可能在语义上相近。本文利用WordNet语义词典在信息处理方面的优势,将WordNet应用到标签的语义分析中,计算标签的相似度。利用WordNet计算标签t1和t2的相似度的过程如下所示:
(1)利用Stanford CoreNLP和Lemmatization对标签进行预处理。
(2)利用WordNet分别生成(t1,t2)的同义词集(s1,s2)。
(3)对每个同义词集检索注释并利用文本预处理方法(拆分、删除停用词、词性标注、词形还原)为s1和s2提取注释G1和G2。
(4)基于集合之间相同的词汇数量越多,相似度越高的思想,根据s1和s2、G1和G2计算标签t1和t2之间的语义相似度。
具体的流程如图1所示。
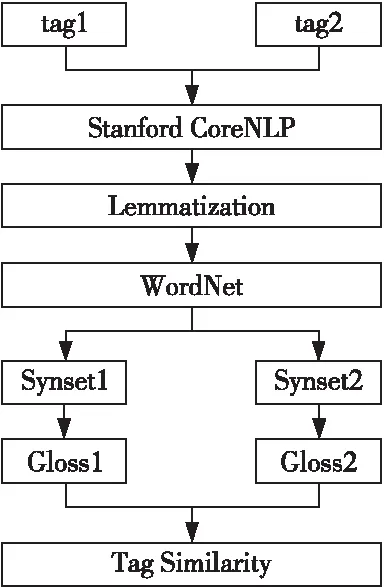
Figure 1 Calculation flow chart of tag similarity图1 标签相似度计算流程图
利用s1和s2、G1和G2计算标签相似度的公式如式(3)所示:
(3)
通过上述方法计算出2个标签的语义相似度,得到基于语义的标签相似度矩阵N。N的表示形式如式(4)所示:
(4)
2.3 合并标签相似度矩阵
将得到的基于用户行为的标签相似度矩阵C和基于标签语义的标签相似度矩阵N进行合并,合并公式如式(5)所示:
sim(ti,tj)=α*p(ti,tj)+
(1-α)simT(ti,tj)
(5)
其中,系数α是用于调节的合并权重。经过式(5)得到合并后的标签相似度矩阵M。M的表达形式如式(6)所示:
(6)
在得到标签相似度矩阵M后,利用M进行标签扩展。
2.4 标签扩展
大多数使用标签的推荐算法都会考虑到用户-标签和项目-标签之间的关系。但是,由于用户为项目标注标签的随意性,会导致标签信息稀疏;由于标签的多样性,会导致标签信息稀疏,因此,利用项目-标签衡量项目相似度是不准确的。所以,本文提出了一种扩展标签的方法,通过利用标签相似度矩阵产生的标签之间的关联,评估用户未使用的标签的可能频率来进行标签扩展,从而降低标签信息的稀疏度。
对于已经标注项目ij但没有标注项目ii的标签tz,根据标签tz与标注到项目ii上的所有标签共现分布,估计标签tz标注到项目ii上的可能概率。概率估计公式如式(7)所示:
(7)

(8)
其中,Ni表示标注项目ii的标签总数,nt,i表示标签tt标注项目ii的次数。
通过上述方法,本文对项目-标签矩阵进行了标签扩展,重建了项目-标签矩阵,降低了该矩阵的稀疏度。
2.5 计算项目相似度并推荐
在得到重建后的项目-标签矩阵R后,利用余弦相似度计算项目之间的相似度得到项目相似度矩阵S。项目相似度的计算公式如式(9)所示:
(9)
其中,Ti,j表示在矩阵R中项目ii和项目ij共有的标签集合。Ti表示标记项目ii的标签集合,Tj表示标记项目ij的标签集合。simiz表示标签tz标记项目ii的概率,simjz表示标签tz标记项目ij的概率。在得到项目相似度矩阵之后,利用基于项目的协同过滤算法为用户生成推荐。
3 实验
3.1 实验数据集
实验采用MovieLens数据集,该数据集含有电影的标签数据。为了验证本文算法的效率,在2个基准数据集上进行实验。较小的数据集为ml-latest-small,该数据集由164 979部电影和671个用户组成,含有1 296个标签记录。较大的数据集为ml-10M100K,该数据集由71 567个用户和10 681部电影组成,含有95 580个标签。本文按照8∶2的比例将数据集分成训练集和测试集。
3.2 评价标准
准确率(Precision),其值表示的是在产生的推荐结果中,正确推荐给用户的项目数在推荐给用户的项目总数中的占比,如式(10)所示:
(10)
召回率(Recall),其值表示的是在产生的推荐结果中,正确推荐给用户的项目数在用户实际评价过的项目总数中的占比,如式(11)所示:
(11)
其中,R(u)是用户u推荐的项目集合,T(u)是测试集中用户u评分过的项目集合。
3.3 实验结果及其分析
3.3.1α的选择
在式(5)中系数α用于调节相似度权重,用来调节标签相似度权重变化对于推荐算法的推荐准确率的影响,其取值在[0,1],每次增加0.1比较Precision的变化,实验结果如图2所示。
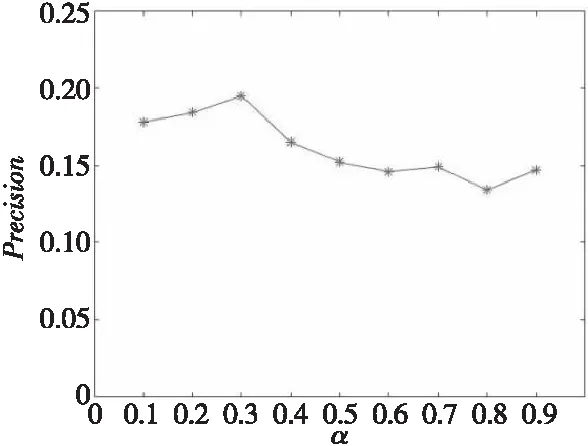
Figure 2 Effect of α on Precision图2 α对准确率的影响
由图2可知,当α的取值为0.3时,Precision值最大,推荐的准确率最高。本文实验中,α取值为0.3。
3.3.2 算法性能比较
为了验证标签相似度的改变对于推荐算法的推荐精度的影响,本文将通过标签共现进行标签扩展的协同过滤CTCF(Collaborative Filtering of tag extension based on Tag Co-occurrence)和结合标签共现与WordNet进行标签扩展的协同过滤CWTCF(Collaborative Filtering of tag extension based on Tag Co-occurrence and WordNet)进行比较分析。实验结果如图3和图4所示。
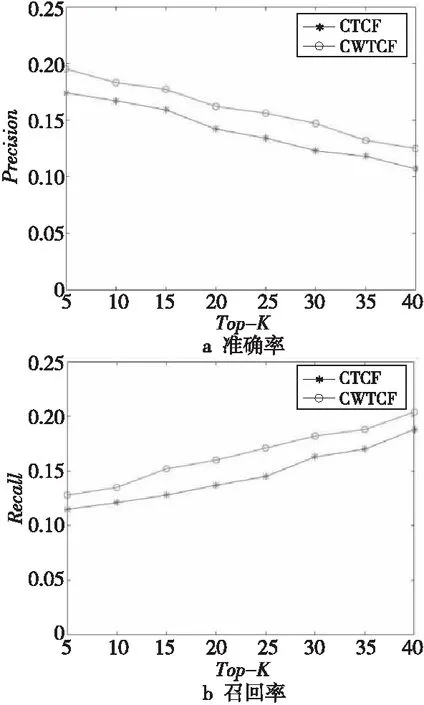
Figure 3 Performance of CTCF and CWTCF on ml-latest-small图3 CTCF和CWTCF在ml-latest-small上的性能
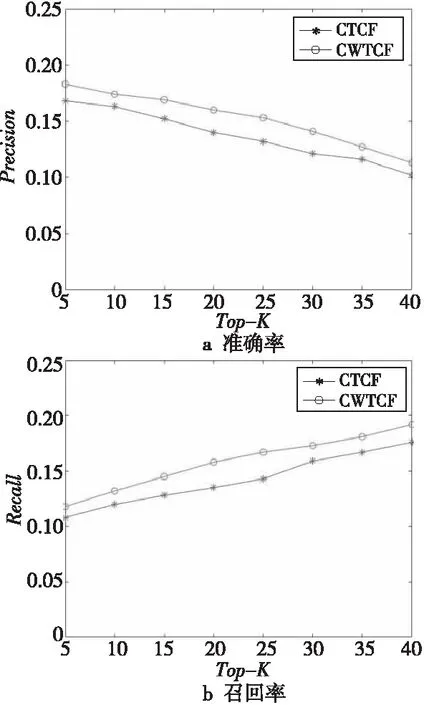
Figure 4 Performance of CTCF and CWTCF on ml-10M100K图4 CTCF和CWTCF在ml-10M100K上的性能
由图3和图4可知,相较于只使用标签共现进行标签扩展的协同过滤或只使用WordNet进行标签扩展的协同过滤而言,将标签共现和WordNet进行结合再利用标签扩展进行协同过滤的推荐算法的Precision有所提高。由此可知,在利用标签相似度进行标签扩展时,应从用户行为和标签语义这2方面考虑,本文通过标签共现思想得到基于用户行为的标签相似度矩阵,通过标签语义得到基于语义相似度的标签相似度矩阵,将2个相似度矩阵进行融合,并在此基础上进行标签扩展,降低数据稀疏度,进行协同过滤,提高了推荐精度。
接着为了验证本文提出算法的性能,本文选取3种算法与本文算法进行比较。
算法1:传统的基于项目的协同过滤推荐ItemCF(Item Collaborative Filtering)算法。
算法2:Guan[5]提出的3DCF(3-Dimension Collaborative Filtering)算法,利用用户和项目的特征进行相似度计算来处理数据稀疏问题。
算法3:Gedikli等[16]提出的Item-specific算法,在项目上下文中考虑标签偏好对推荐的影响。
不同算法性能比较如表2~表5所示。
由表2~表5可知,相较于传统的ItemCF算法,其他3种算法的性能更高,因为这3种算法都在ItemCF基础上进行了一定程度的改进。另外,可以观测到,Item-specific算法的性能比3DCF的更高,可能的原因是Item-specific算法将标签应用到了以协同过滤为基础的推荐算法之中,可以更好地反映用户的兴趣。除此之外,本文算法的性能相较于其他3种算法都高,相较于3DCF在降低数据稀疏度时仅仅考虑用户和项目特征,本文在降低数据稀疏度时充分考虑了标签数的作用,相较于Item-specific仅仅在项目上下文中考虑标签偏好,本文算法利用标签数据降低了数据稀疏度,综上本文算法的性能更好,推荐精度更高。
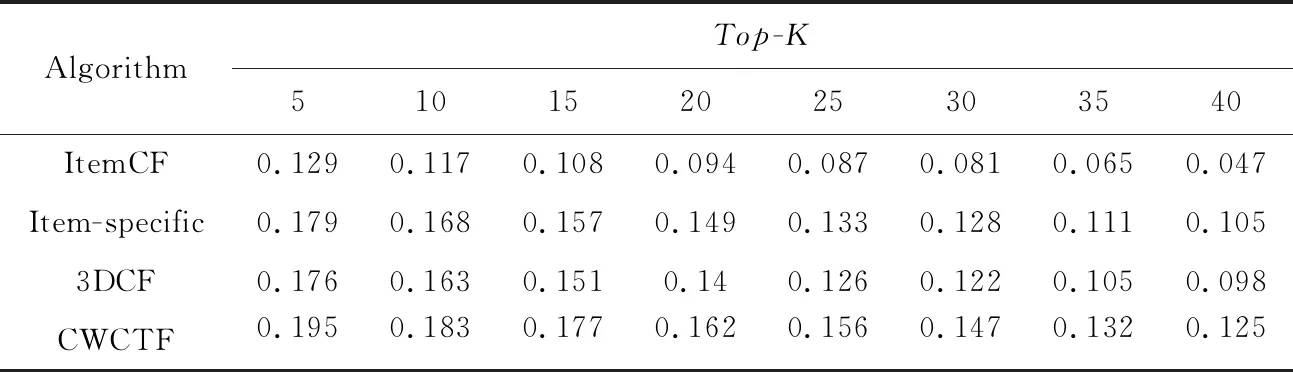
Table 2 Precision of four algorithms on ml-latest-small
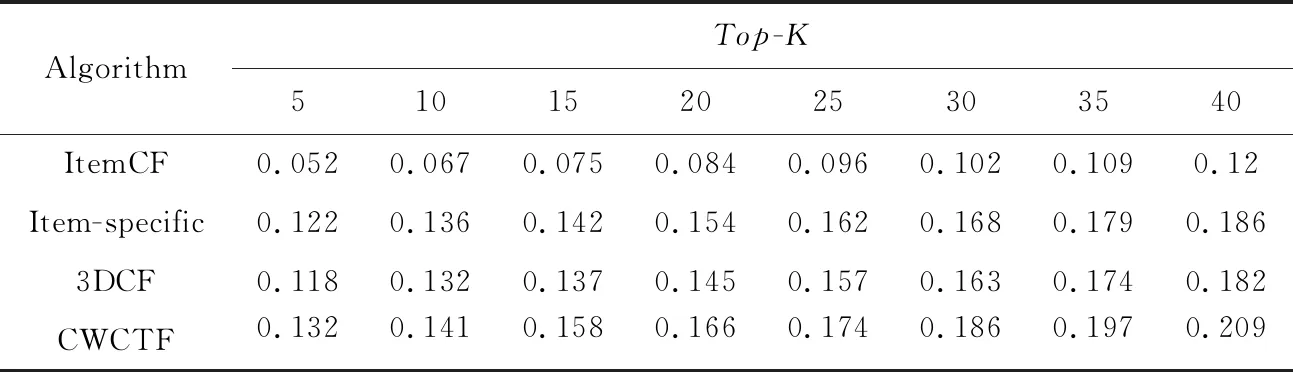
Table 3 Recall of four algorithms on ml-latest-small
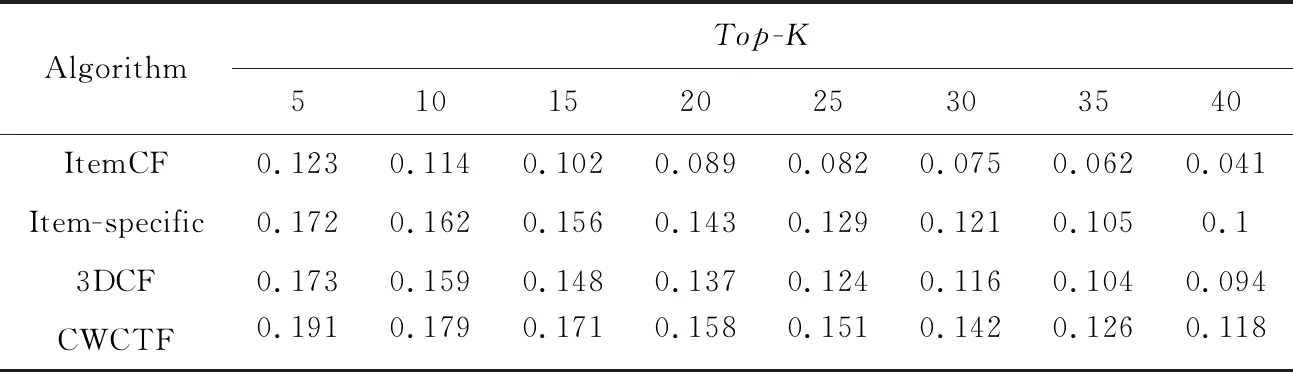
Table 4 Precision of four algorithms on ml-10M100K
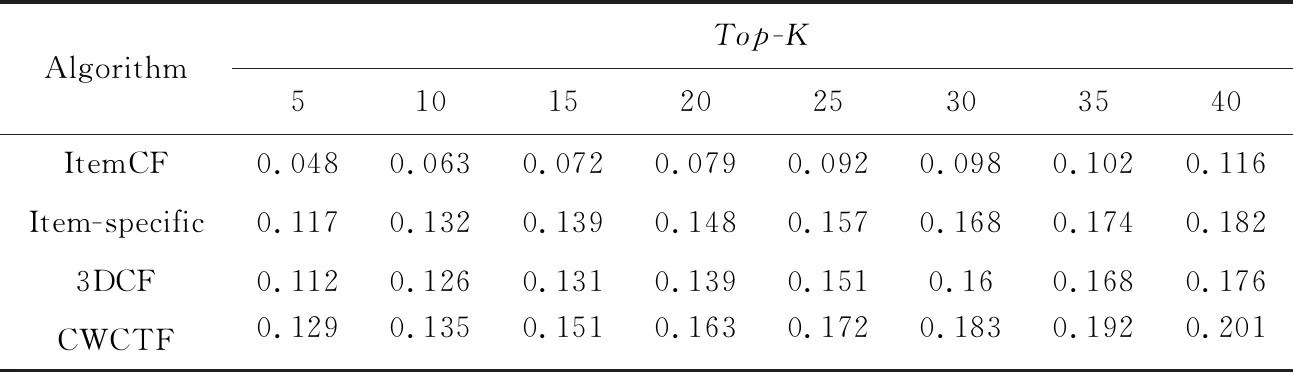
Table 5 Recall of four algorithms on ml-10M100K
4 结束语
大多数利用用户、项目与标签之间的关系进行推荐的算法,都会面临着用户个体不同导致的标签信息稀疏问题,因此,本文进行标签扩展,重构项目-标签矩阵,进行协同推荐,在进行标签扩展时从用户行为和标签语义2方面进行考虑。最终的实验结果表明,本文提出的推荐算法相较于传统的协同过滤算法的推荐效果更好。
