基于Spark Streaming的视频大数据并行处理方法 *
2021-10-26张元鸣虞家睿陆佳炜
张元鸣,虞家睿,陆佳炜,高 飞,肖 刚
(浙江工业大学计算机科学与技术学院,浙江 杭州 310023)
1 引言
视频设备被广泛应用于公共区域、智慧城市和智慧工厂等许多领域,其产生的视频数据具有体量巨大、速度极快、价值稀疏和完全非结构化等典型大数据特征[1,2]。与此同时,视频数据中蕴含了丰富的有价值的信息,如根据电梯视频数据可以进行乘客数统计、不文明乘梯检测和运行异常报警等。由于视频数据体量巨大,如何提高处理性能以快速执行视频分析成为视频大数据面临的难题。
为了提高视频数据处理的性能,研究者提出了一些视频大数据并行处理框架。Tan等[3]提出了一种将视频数据放至Hadoop分布式框架上作多节点检测以提升运算效率的计算平台,详细比较了不同节点与文件大小的效率差异;Lü等[4]通过Spark云计算平台进行分布式存储,引入CaffeOnSpark提供深度学习支持,通过层次特征完成人脸并行分类计算;叶锋等[5]提出一种将方向梯度直方图HOG(Histogram of Oriented Gradient)特征检测与Spark大数据框架相结合,并辅以射频识别技术实现车辆计数的方法;张洪等[6]通过将帧差法与Spark分布式框架相结合,利用多节点的方式实现车流量并行统计;王丽园[7]通过将电梯监控数据与分布式框架相结合,利用在线学习算法对电梯运行状态进行高效监测。但是,这些研究侧重于视频并行处理框架的设计与实现,并未针对算法的特点给出相应的并行策略,制约了视频数据处理性能的进一步提升。
在视频数据处理优化方面,研究者们也进行了相关研究。郑健等[8]将流式计算和在线分析处理OLAP(On-Line Analytical Processing)框架相结合,提出了一种基于流式计算的实时视频分析方法,对海量视频数据进行高效的实时查询;李海跃等[9]提出了将视频转化为图像集,通过比较曼哈顿距离的方式去冗余帧以提高查询效率;张晓宇等[10]提出了基于融合特征的关键帧提取方法;Lü等[11]通过对比颜色名称CN(Color Name)、尺度不变特征变换SIFT(Scale Invariant Feature Transform)和局部最大发生LOMO(Local Maximal Occurrence)3种图像特征提取图像关键信息,并结合分布式框架完成图像检测。然而,以上研究仅适用于帧间无关分析算法,不适用于帧间相关分析算法。由于帧间相关算法存在前后帧依赖关系,无法直接通过去冗余帧等方法提高性能,也无法用简单的节点拆分进行并行化。
为了进一步提高视频大数据处理性能,满足视频大数据性能需求,本文提出了基于Spark Streaming的视频大数据并行处理方法,其主要贡献包括:
(1)针对帧间无关分析算法,提出基于数据并行机制的视频大数据并行处理策略,将视频数据转换为字节型数据,然后将各个字节型数据划分到不同的节点上并行处理。
(2)针对帧间相关分析算法,提出基于流水线并行机制的视频大数据并行处理策略,建立算子之间的依赖关系,将各个算子分别映射到不同节点以流水线的方式重叠执行。
(3)以电梯视频大数据为例,对典型视频分析算法进行了并行化,通过实验证明2种策略在Spark Streaming框架上能够获得更高的处理性能。
2 视频大数据并行处理框架
Spark是一个基于MapReduce并行计算框架的开源实现[12],由美国加州大学伯克利分校AMPLab实验室开发,基于内存计算对数据读写过程进行优化,具有更小的I/O开销,支持批处理、迭代计算、交互式查询和流处理等多种计算模式。弹性分布式数据集RDD(Resilient Distributed Dataset)是Spark最基本的抽象概念,它提供了一种共享内存式的并行运算,将数据加载到内存中,使得不同的RDD之间存在一定的依赖关系。
Spark Streaming是Spark框架的实时流处理组件[13],其采用了一种新的离散流处理模型,计算流程是将数据流以时间片为单位进行切割形成弹性分布式数据集RDD,随后通过Spark引擎将数据集经过处理得到的中间结果保存在内存中,最后再根据业务需求对中间结果进行叠加或存储到外部设备。Spark Streaming流处理的基本模型如图1所示。

Figure 1 Spark Streaming processing model图1 Spark Streaming流处理模型
为了提高视频数据处理的实时性,本文设计了基于Spark Streaming的视频大数据处理框架,其层次结构如图2所示,该框架包括数据分发层、数据传输层、数据处理层和数据应用层:
(1)数据分发层:该层用来采集与分发各摄像头的视频数据,通过4G/5G或有线网络将视频传入Kafka消息队列作为消息生产者,根据视频线路将数据分发至不同的传输层节点。
(2)数据传输层:该层用于传输解码后的视频帧序列,通过Receiver接收视频数据流,使用Broker代理节点对消息进行缓存与传输,为每路视频数据设置相应的主题,每个代理节点根据主题的不同将视频数据传输至不同的处理层区域。

Figure 3 Parallelization of inter-frame independent video analysis图3 帧间无关视频分析算法并行化方法
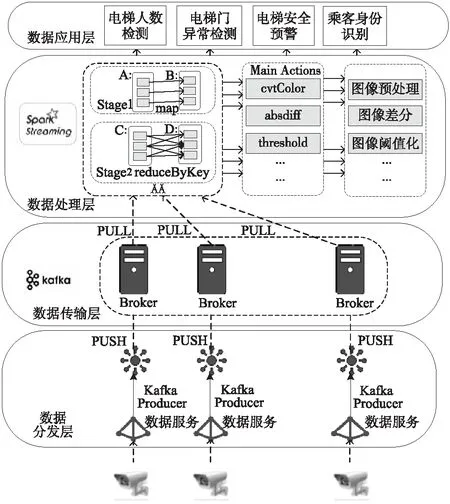
Figure 2 Video big data processing framework based on Spark Streaming图2 基于Spark Streaming的视频大数据处理框架
(3)数据处理层:该层对视频流数据解码并分析,通过流处理的方式将数据流转译成字节数组,以字节流形式生成RDD数据集[14],通过Spark Streaming对各个RDD并行处理,根据视频分析算法采用不同的并行策略,随后通过视频算法对数据进行分析,将分析结果传入数据应用层。
(4)数据应用层:该层用于展示视频处理与分析的结果,设置相应的功能模块,为用户提供统一的可视化界面。
3 视频大数据并行处理策略
根据视频帧之间的相关性,典型的视频分析算法可以被划分为帧间无关分析算法与帧间相关分析算法[3]。帧间无关分析算法不需要考虑前后帧的依赖关系,可以独立处理各个视频帧,例如目标检测等属于此类算法的应用范围;帧间相关分析算法则需要考虑前后帧的依赖关系,需要分析连续的视频帧才能得出结果,例如目标跟踪、背景差分等属于此类算法的应用范围。针对以上2种类型的视频分析算法,本文给出不同的并行化策略。
3.1 帧间无关分析算法并行化
由于帧间无关分析算法不存在前后帧依赖关系,因此本文采用数据级并行机制对分析算法并行化。为了使视频分析算法与Spark Streaming框架相兼容,本文使用JavaCV作为视频帧分析算法库,先对视频流进行解码,将视频解析成视频帧,缓存到内存中;将视频帧转化成字节数组,提取帧的长宽和颜色信息生成对应的图像数据结构,再转化为字节数组作为输入数据流;将数据流写入队列,构建分布式视频流数据所特有的格式JavaDStream,视频帧被转化为JavaRDD,同时每帧数据都由字节数组构成;将JavaDStream流数据格式转换为键值对数据,并控制视频流处理的速度,各个键值对数据并行地在各个节点处理,最终输出分析结果。在分配集群资源时,尽量将压力较大的节点上的Receiver接收器分配至空闲的节点上[15]。帧间无关分析算法并行化方法如图3所示,图中不同节点表示视频流处理过程中格式转化过程,其中n表示数据流中总视频帧数。
为了去除冗余帧来提升视频处理性能,可结合帧差法捕捉关键帧。帧差提取法是一种常用的去冗余帧算法[16],通过帧差法可在视频流传入消息分发系统前进行关键帧的筛选,当画面变动超出阈值时,将视频帧传入Kafka中进行分发,以此减少视频帧处理数量。
3.2 帧间相关分析算法并行化
帧间相关分析算法要求依次处理各视频帧才能得到正确的结果。为此,本文给出一种基于流水线并行机制的帧间相关分析算法并行化方法,将分析算法的各个步骤抽象为算子,建立算子之间的依赖关系,并基于算子间的依赖关系在Spark Streaming上以流水线并行机制执行。
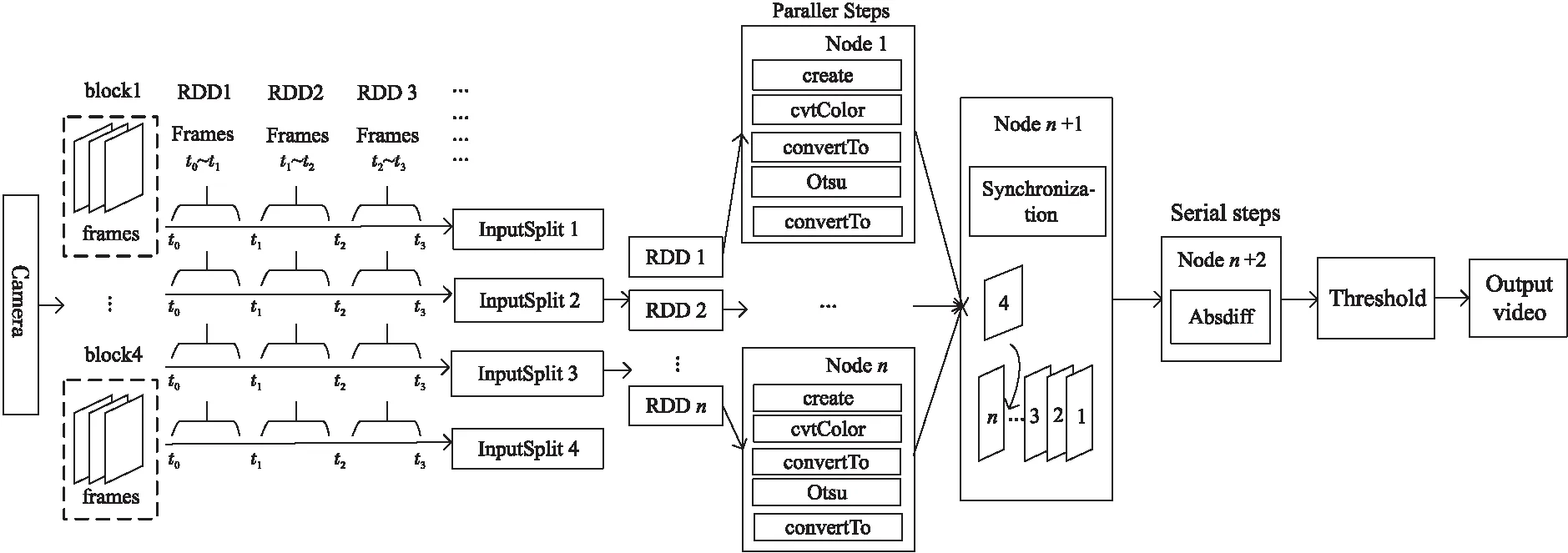
Figure 5 Parallelization of video background difference algorithm图5 视频背景差分算法并行化方法
视频背景差分算法属于典型的帧间相关分析算法,其包括8个算子,这些算子之间的依赖关系如图4所示。根据该依赖图,颜色滤镜(cvtColor)算子、背景创建(create)算子、格式转换(convertTo)算子可以并行执行,前后帧相减(Absdiff)算子和阈值判定(threshold)算子须串行执行,输出视频帧分析结果。根据视频分析算法内各个算子之间的依赖关系,对视频分析算法进行并行化。
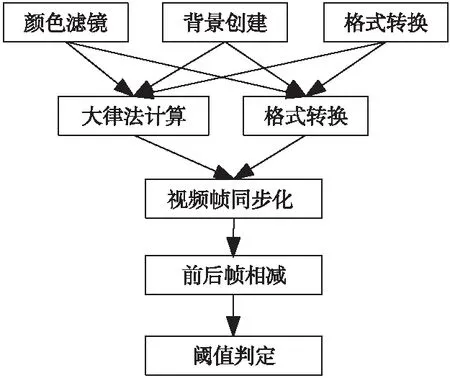
Figure 4 Dependency diagram between operators in the video background difference algorithm图4 背景差分算法内算子间的依赖关系图
图5给出了背景差分算法并行化方法,将颜色滤镜、背景创建、格式转换、大律法和格式转换5个算子作为子任务,为其分配独立的计算资源,以分节点方式并行执行。由于背景差分算法需要前后帧相减得出结果,因此通过同步算子将视频帧重新序列化,使其在之后的节点按序串行执行,经过前后帧相减算子与阈值判定算子后输出结果。
上述以背景差分视频算法为例给出了帧间相关视频算法并行化过程。对于一般的帧间相关视频分析算法而言,提取算子的基本策略是对算法内部的关键步骤进行分析并划分,将划分得到的关键步骤提取为算子,然后建立算子之间的数据流依赖关系;在输出分析结果时,如果需要同步算子的输出,则插入同步算子Absdiff以确保算法的正确性。在算子抽取过程中,尽可能地提取细粒度的算子,以增加视频分析算法的并行度。
4 实验方案与评价
电梯是人们日常生活中重要的交通设备,为了提升电梯的安全性,不少电梯都配置了监控设备,其产生的数据具有典型的大数据特征。本文以电梯乘客数检测算法和电梯门开关检测算法为例对视频大数据处理并行化方法进行评价,前一个是帧间无关分析算法,后一个是帧间相关分析算法。
实验环境是具有16个结点的集群,每个结点为8核CPU,内存16 GB,带宽50 Mbps,操作系统为Ubuntu 16.01,集群上部署了Spark-2.3.1,开发环境是Java JDK 8.0,在OpenCV 3.3.0上编写程序,使用JavaCV 1.4.2进行语言转化。电梯监控视频共32段,每个视频时长38 min,测试用视频大小约为8.28 GB,总时长约为6.5 h,视频大小为1280×720,帧率为24 f/s。
4.1 电梯乘客数并行检测算法
电梯乘客数检测算法采用Haar特征对图像进行特征提取与识别[17],读入视频时将视频数据解析成为图像数据,转换为字节数组,通过Spark Streaming中的Parallelize方法将字节数组划分为RDD作为处理对象。
视频字节数据流作为电梯乘客数检测算法的输入,分析时将电梯编号作为Key值,RDD作为Value值,生成流数据键值对;以Rect为单位,将键值对数据中的RDD数据用列表形式存储,用以记录每帧数据中检测到乘客的位置与数目,在提取图像像素值后对像素颜色进行灰度化并对其进行图像预处理,以降低光照变化对其产生的影响;调用训练所得的分类器并配合机器学习检测方法检测此时图像中的乘客目标;将检测所得的乘客位置放入Rect列表中,提取列表长度作为检测到的人数;最终在后台记录检测后生成键值对数据流,检测出每路视频中的乘客数。电梯视频乘客数检测效果如图6所示。

Figure 6 Elevator passenger detection effect图6 电梯乘客数检测效果
检测算法采用Haar分类器检测,训练样本包括8 235个正样本和37 885个负样本,其中正样本截取自电梯环境下拍摄的乘客头肩部分,负样本源自各种电梯环境和乘客物品;在保证准确度的情况下,设置训练层数为21层,每层正样本数为1 500,负样本数为3 000,子节点分裂数为2次。
在Spark Streaming集群上基于数据并行化策略对电梯乘客数检测算法进行了并行化,实验结果如图7所示。可以看出,对于不同的视频数据量,并行化方法都能够有效地提高性能:当数据量为5 GB时,结点数为2,5,10,16的性能分别比结点数为1时的性能提高了178%,260%,463%,658%;当数据量为8 GB时,结点数为2,5,10,16的性能分别比结点数为1时的性能提高了176%,248%,471%,615%。
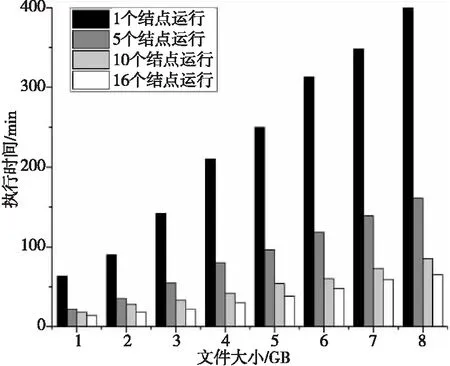
Figure 7 Execution time of elevator passenger parallel detection algorithm图7 电梯乘客数并行检测算法的执行时间
另一方面,当视频数据大小一定时,随着结点数的增加,集群的分析性能并没有呈线性增长。其原因在于结点数增加后结点间的数据传输开销增大,同时部分视频帧计算量大于其它视频帧,如部分视频帧中人数较多,计算量较大,使得分区出现负载不平衡。
为了便于研究算法中各模块性能,本文进一步分析了视频数据处理各环节所消耗时间,如图8所示。以视频数据量8 GB为例,从图8中可以看出,数据分发与人头检测占用了算法绝大部分时间,分别占到分析时间的30.9%和39.2%,其次是关键帧提取,占分析时间的26.9%,最后人头特征提取与数据存储所占时间最少,分别占1.8%和1.2%。
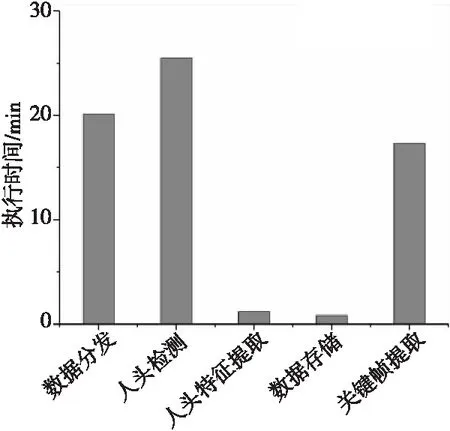
Figure 8 Execution time of each module duringparallel detection of elevator passenger number图8 电梯乘客数并行检测各模块执行时间
针对视频优化算法,本文测试了关键帧提取操作对电梯乘客数并行检测算法性能的影响,图9给出了实验结果。可以看出,当结点数与视频数据大小一定时,关键帧提取能够有效地提升性能。例如,当数据量为8 GB,结点数为5时,通过关键帧提取性能提高了123%,结点数为16时,通过关键帧提取性能提高了105%。结点数增加时,由于分布式系统的通信开销增加,导致性能提升会小于结点数较少时;对于进出人数较少的视频帧,关键帧提取的效果明显高于进出频繁的视频帧。
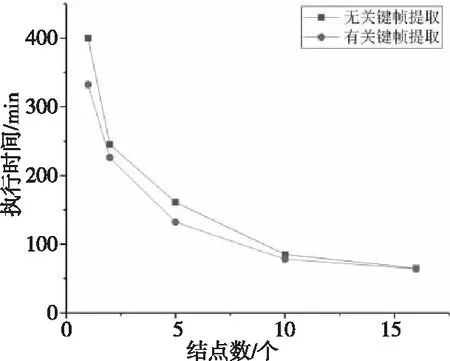
Figure 9 Key frame extraction timefor parallel detection of elevator passenger number图9 电梯乘客数并行检测关键帧提取执行时间
4.2 电梯门开关异常并行检测算法
电梯门开关异常检测算法使用背景差分法检测电梯门开关情况。将视频数据解析为图像数据,并生成对应的灰度图像,把前一帧的图像作为前景与背景,对后一帧的图像进行灰度转换,并将前后帧分别转化为浮点数格式;随后使用大律法算法对前后帧进行直方图计算,选取全局阈值,按照时间戳对视频帧进行同步,确保视频帧按照时间顺序进行后续处理。在处理完成后使用差分算子将视频流前后帧相减,若得到的值超过设定的阈值threshold,则判定电梯门正在开关;若得到的值小于设定的阈值threshold,则判定电梯门已经关闭,此处阈值为经验值,实验中设为30像素。实验效果如图10所示,当有异物或乘客挡住电梯门时,监控视频会马上报警提示后台。从实验中可以看出,在电梯轿厢内的多种环境下,该算法的误检率与漏检率均在3%以下,延时率较低,且对于背景干扰、光照干扰和抖动干扰等该算法都具有一定的适应性,拥有较好的泛化能力,可以满足一般场景下的电梯监测需求。

Figure 10 Elevator door switch abnormality detection图10 电梯门开关异常检测效果图
在Spark Streaming集群上基于流水线任务并行化策略对电梯门开关异常检测算法进行并行化处理,实验结果如图11所示。可以看出,对于不同的视频数据量,并行化方法均能够有效地提高性能:当数据量为5 GB时,结点数为2,5,10,16的性能分别比结点数为1时的性能提高了137%,164%,211%,259%;当数据量为8 GB时,结点数为2,5,10,16的性能分别比结点数为1时的性能提高了143%,161%,238%,253%。当结点数目增加时,并行检测算法的性能提升趋向缓慢,其原因是由于结点间数据传输开销以及关键步骤同步开销所引起的部分计算串行化。
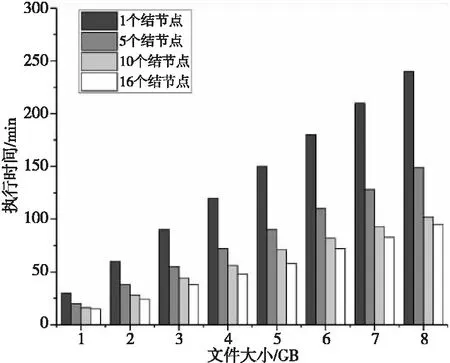
Figure 11 Execution time of elevator door switch abnormality parallel detection algorithm图11 电梯门开关异常并行检测算法执行时间
针对帧间相关分析算法,将流水线任务并行化策略与现有的分段式并行策略[18]进行对比,实验结果如图12所示。从图12中可以看出,当结点数为10时,2种并行化方法均能有效提高视频分析效率,且流水线任务并行化方式明显优于视频流分段并行化方式,当文件大小相同时,流水线任务并行化分析效率同比视频流分段并行高出190%~290%。当视频数据量较大时,分阶段任务并行化策略能有效避免传统的视频分段造成的负载不均衡问题,防止通信限制与负载不均导致分析效率出现大幅下降。

Figure 12 Execution time comparison of inter-frame correlation parallel algorithm图12 帧间相关并行算法执行时间比较
5 结束语
为了提高视频大数据的处理性能,本文设计了基于Spark Streaming的视频大数据并行处理框架,包括视频数据的分发层、传输层、处理层和应用层。根据视频处理算法的特点,结合数据级并行化机制与流水线并行化机制,分别给出了面向视频帧间无关算法的数据并行优化策略和面向视频帧间相关算法的流水线任务并行化策略。以电梯视频大数据为例,采用帧间无关的电梯乘客数检测算法和帧间相关的电梯门异常检测算法对并行化方法进行了评价,结果表明,本文提出的并行化方法能够快速提高视频大数据的处理性能,随着结点数的增加性能得到有效提升。本文提出的视频大数据并行框架也可以应用于其它视频领域,如智能交通、视频安监和工业视频等领域,以提高视频分析的总体性能。
