关联挖掘在图书馆读者分类中的应用探索
2021-10-25郭明环代素香吕亚娟
郭明环,代素香,吕亚娟
(西安科技大学 图书馆,陕西 西安 710054)
关联挖掘[1],又称联系发现(Link Discovery),是当前大数据分析发展中的一个新阶段实用型数据分析产品,该模型将对待分析的数据进行分类、产生的数据重构产生判断,并在它们之间产生关联模式。同时,允许分析员从相关数据库中查找/调用匹配数据,使其在海量的重构数据库中挖掘有强关联的信息,为决策和优化方案提供有价值的信息。基于归纳逻辑的关联挖掘方法可处理多关系型的数据,为不同实体之间强弱关系的信息采集分析提供了高效的可视化手段[2]。
关联挖掘技术,可以先挖掘实体之间的联系,从联系入手先对数据进行预处理,然后再进行聚类处理,可以有效地提高聚类的准确性。传统的聚类方法在进行实体划分时,往往多从实体间的欧氏距离起步,并以此作为划分的依据进行聚类分析。但是,这种分析的方法忽略了实体之间意义上的关联这一重要属性,因而聚类的结果往往不容易理解,或者只能从距离的角度予以理解,而关联挖掘恰恰可以解决聚类分析中的这一难点[3]。
图书馆作为信息资源的仓库和提供者,在大学里对广大的师生读者发挥着关键作用。图书馆需要在新形势下利用大数据技术,深入挖掘读者的信息需求,推测识别不同读者的意图和风格,对读者群体进行科学的类别划分,对其感兴趣和关注的主题类型进行标签化处理,通过智能化标签判定不同读者的动态需求,把馆藏信息和推荐材料发给特定群体,为不同的图书馆读者群体,提供针对性和个性化的服务产品,为高校的选修、选课和毕业论文的撰写方向提供有价值的参考信息,最大程度上指导读者高效获取直接的相关动态和信息等。
1 相关研究
国外关于关联挖掘的研究有:Adibi J等人认为,应用范围包括社会关系分析、诚信度分析、图形识别、模式分析和关联探索等[4];Lin S D等人论证了用关联挖掘方法可以发现隐藏的关联群体或组织结构、判断仿真群体可能的行为及提前预测可能发生的新的威胁及欺诈行为[5];Mooney等人研究发现,关联挖掘能从大量的关系数据中甄选出可能的潜在的不良活动模式,且这些模式是关系复杂的、可操控的[6];Han和Kamber认为,关联挖掘的方法是一种新的大信息容量数据发掘方法[7];Sentor把关联挖掘描述为:发现已知模式的证据和未知模式的联系[8]。国内的关联挖掘研究有:倪志伟等人验证了在金融领域的证券市场,基于对样本客户行为信息的关联分析,可以对客户进行高效率分类[2];李玉华等人基于图熵的链接发现算法给出了其在银行反洗钱领域的应用[9]。
目前,关联挖掘已广泛应用于社会生活的许多领域,如:反欺诈行为的侦破、法律诉讼方面的调查取证、网络信息的分析和电信通讯业务的关联调查等[4]。可以预见,还有很多领域的应用有待探索,关联挖掘将会在未来社会生活的诸多方面起到巨大的作用,比如金融领域的反洗钱案件的侦破、医学领域一些疾病的诊断以及信息检索领域用户的识别等[10]。
到目前为止,图书馆领域还缺乏用关联数据挖掘的方法来研究读者的个性化服务,譬如流通部的阅读推荐,学科服务部的信息资源推送等针对性的特色服务。笔者将探讨基于相关分析的关联挖掘算法在图书馆读者分类中的应用。我们将不同类型读者网络信息的采集行为作为抽样数据,考虑到读者的多样性。我们以本科生、研究生和教工为例。
2 基于关联挖掘的图书馆读者划分方法
2.1 基于关联挖掘的图书馆读者划分流程
在对读者群进行划分时,基于关联挖掘的图书馆读者划分方法的具体的流程如下:①采集数据并用关联模型处理,提取关联属性信息—某一领域文献下载量,网站浏览次数、登录次数。②通过方程(1)对读者的属性进行关联强度分析,提取图书馆读者间的关联系数,用相关系数作为读者间的关联值,作为分类的权值。构建完全图G(C,E,W)。③设定适当的定义阈值β处理完全图,为提高计算效率,可删除权值阈值以下的关联群落。④利用方程(5/6)获取(3)中各类读者的加权度WDi和加权聚集系数形WCi,再根据公式(8)计算各读者的加权复合值WCFi。⑤对图中加权复合特征值WCFi进行排序。⑥从队列中选取前k个值,以它们对应的节点为聚类初始节点,使用K-means算法,用相关性矩阵对读者进行分类计算,获得读者分类图形。
2.2 聚类前基于关联挖掘算法的预处理过程
关联挖掘方法(link discovery based on correlation analysis,LDCA)是重要图分析方法之一。其相关系数(Pearson相关系数)是两个统计量之间关联强度的数量刻画,描述了两个特定变量间关联的主要信息。计算公式如下:
(1)
(2)
其中,n为抽样个数;xi,yi代表相应参量属性值;mx和my指两个变量的相应参量的平均值;r给出观测的两个变量间线性关联强度,取值在-1与+1之间。这里若r>0,是指两个变量呈正相关,即正向关联;若r<0,表明两个变量是负相关,即反射关联。若r=0,表明两个变量间不是线性相关,可以排除出群落。
利用关联探索方法发掘不同读者读书倾向的相似度,这里特指两个读者数据项之间的模式关联程度,用关联强度构造两实体间的行为联系强弱,其可执行路线图如图1所示。
路线图中,关联设定、关联生成、关联验证是关联挖掘方法的3个关键节点:①关联设定。此过程要定义了任意两个实体之间的关联度量函数F,其提供群落的关联信息,其强度在[-1,+1]之间变化。②关联生成。依据关联设定求出样本中目标对象的相关性大小,以实体属性和相关性权值为参量构造出加权多边完全图G(U,E),其中U表示实体集合,E表示带有相关性权值的边值的集合。③关联验证。关联验证是指用另一个定义了阈值T新的函数P或算法把完全图G匹配到它的某个子集M,M⊂G。该子集中的群落之间呈现不同关联强度。
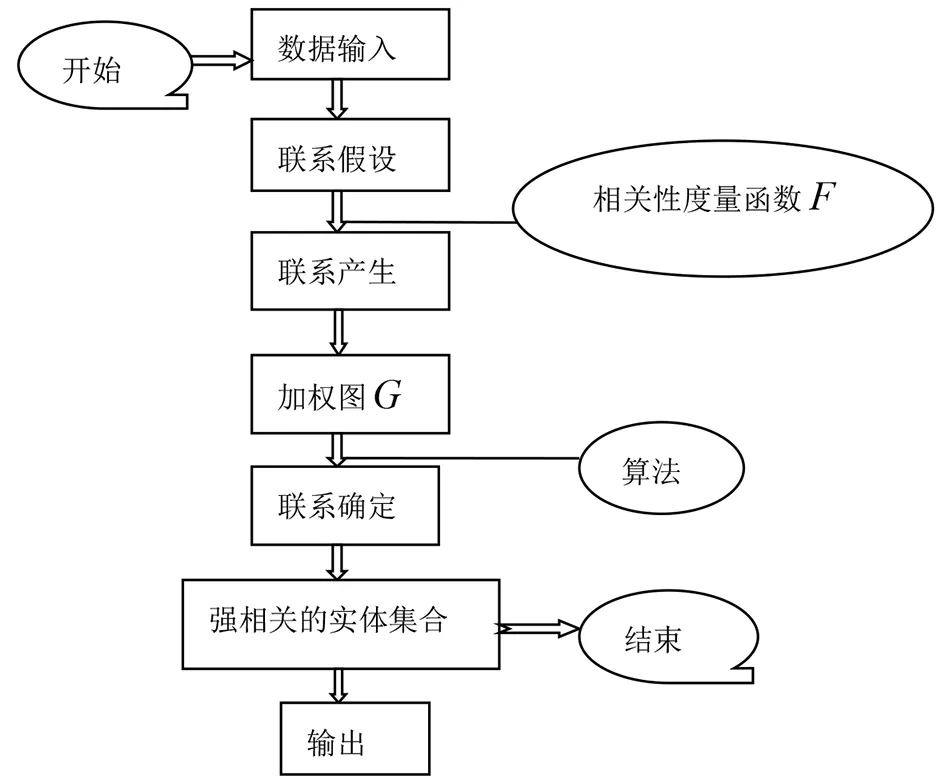
图1 基于相关分析联系发现方法流程
通常情况下,读者分类一般都采用各种聚类方法来进行,这种分类一般都是把读者的属性割裂开来单独考虑。在关联挖掘技术中,属性与属性之间的关联是重点考察的对象,建立属性之间的关联,读者各个属性之间的相互影响,在进行过关联挖掘技术处理之后,再进行聚类运算。
2.2.1 图书馆读者的属性分析。图书馆读者的属性(数据)是多维的,如使用搜索引擎检索图书的检索信息、借阅图书的统计信息、使用各种电子资源的信息、生活消费信息,教育事务相关信息,科研相关信息等。对于不同的读者类型,需要选取不同的属性进行分析,有的属性能够反映读者的行为特征,有的则不能,从变异性的角度将学校师生的属性分为静态属性和行为属性:①静态属性获取主要包括从图书馆服务系统中获取的读者信息,包括姓名、工号/学号、读者类型、研究领域等个人信息在内的基本信息;②动态属性采集指的读者在阅读中对馆藏资源的使用意愿、跨馆(库)传送的数据,确定读者群体短期、长期目标下的信息需求;也会跟踪图书馆中读者的浏览记录、查询记录等对读者阅读信息行为数据进行深度挖掘[12]。参照高校图书馆管理的规律,对目标读者进行标注。譬如根据读者访问的网站类型,对其进行分类和标注。每学年内如果每个点击的站点次数超过设定次数,它们将被标记,对某一领域浏览次数、文献下载量超过设定次数将被标记,访问的网站将按照图书馆网站、谷歌搜索引擎、360导航、百度网站等导航网络进行分类;根据读者阅读的图书种类不同,标注条件为每学期或每学年借阅次数,借阅册数,排行名次;卡片信息比较丰富,包括用餐、班车、洗衣、超市、医疗、宿舍用电等,这些信息通常用作每学期或每学年的时间线[13]。
下面是西安科技大学图书馆部分读者Web日志的抽样数据,即某一领域的数据库网络记录的原始数据,通过数据挖掘技术进行分析,再通过数据筛选方法剔除与目标读者群体无关的数据,获得强关联数据集合。笔者选取的读者数据见表1。
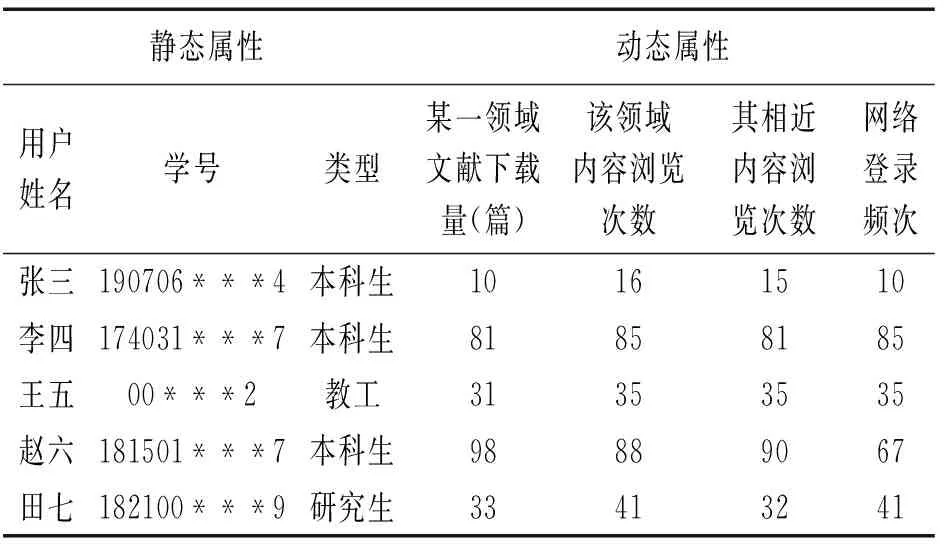
表1 图书馆用户属性
2.2.2 关联设定。对图书馆读者的静态属性确定后,再提取与之对应的动态属性,即某一领域文献的下载量(篇),该领域内容的浏览次数,该领域相近内容的浏览次数,网络登录频次。在关联假设过程,首先定义关联函数来描述图书馆读者间的行为联系程度,依据表1中4个动态属性值,调用Pearson系数公式来模拟图书馆读者间的行为关联信息。
把读者和其关联信息投射到图模型中刻画类型交互关联特征,具体过程如下:
定义1 设c={c1,c2,…,ci,…,cN}为图书馆读者集合,无序偶对(ci,cj)给出读者ci∈C与cj∈C之间的边值,表示读者ci和cj之间的关联。G(C,E)是以C为读者集合,以E⊂{(ci,cj)|ci,cj∈C}为关联集合的图。
定义2 读者Ci的度Di是指其与其他读者相关联的边数,表示了读者ci与其他读者关联的频率强度。公式如下:
Di=|{(ci,cj)|ci,cj∈E,ci,cj∈C}|
(3)
读者的聚集系数是指与该读者相连的近邻读者之间交互的比率。公式如下:
(4)
其中:Ki=|{(cj,ck)|(ci,cj)∈E,(ci,ck)∈E,cj,ck∈C}|
2.2.3 关联产生。在关联假设阶段,定义了读者间的关联函数,在关联发现过程,将用公式(1)计算读者之间的相关性系数,用于生成关联类型的全貌图WG(V,E,W)。
定义3 设c={c1,c2,…,cN}为读者集合,无序偶对(ci,cj)表示节点读者ci∈C与cj∈C读者之间的边值,wij为读者ci,cj间行为相关性的值,作为边值的权值。则WG(V,E,W)是以C为读者集合,以E⊂{(ci,cj)|ci,cj∈C}边值集合,以W={wij:(vi,vj)∈E}为权值集合的图,读者的加权度反映了该读者与其他读者的连接强度,读者的加权度WDi为:
(5)
读者的权重敛散度将给出该读者在一定类型内的交互关联频率和作用强度。读者加权聚集度WCi为:
(6)
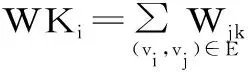
(7)
R={(ci,ck)|(ci,cj)∈E,(ci,ck)∈E,ci,cj,ck∈C}。
其间,为提高计算效率,计算过程可依据类型特征指定阈值,过滤权重小于阈值的读者信息,得到强关联类型关联图形。
2.2.4 关联验证。对于关联验证过程,将依据读者的权重敛散度和聚集系数,给出关联函数的系综函数,表达形式如下:
WCFi=αWCi+(1-α)WDi/N
(8)
其中,α为可调的参数,0<α 特定类型的系综函数展示了读者之间的交互频度与关联强度等指标。依据相关指标信息对读者进行图形划分,并依据类型权重敛散度顺时针排列,不同模块之间聚焦系数相对较低,此处并不显示(见图2)。 图2 读者类型划分 图内RF为关联系数,RF的值越接近,说明读者行为的相似度越大。关联挖掘方法就是根据RF值的接近程度来对图书馆读者群体进行划分的。从图2中我们可以直观地看到,王五、田七两人和张三用户的RF值比较接近,可以归为同类型的读者,即对笔者选定的这一特定领域的兴趣和关注度属于同一个类型。而对于和张三关联系数更低的赵六和李四,他们俩之间的RF值更接近,可以归为同一类型的读者,如果关联系数再低些的读者,通过阈值β排除某些类别,通过模型循环寻找新的类别。 验证:针对笔者抽样的读者,在未被告知访谈目的的情况下,作了一对一的访谈,真实了解了这些读者对被我们抽样的这一领域的点击、浏览及下载的网络行为的初衷。张三和田七都曾选修了涉及该领域的课程,王五是教授这门课程的教师,所以,他们对这一领域有过相近的关注度和信息需求。而李四和赵六对这一领域很有兴趣,二人不仅选修了涉及该领域的课程,而且还准备报考该专业的研究生。所以,他们对这个领域的关注度更高一些,属于同一类型的读者。访谈调查的结果证实了关联挖掘方法在图书馆读者分类中的适用性。 用关联挖掘算法对样表1中的数据计算的结果和我们对相对应的读者访谈调查的结果是高度一致的,由此我们可以得出结论:在动态行为属性关联的条件下,关联挖掘算法可以对图书馆读者的信息需求类别进行划分,且这种划分方法更直观,并且提高了划分的效率。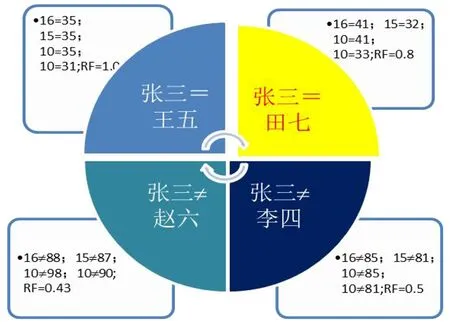
3 结论
