基于优化稀疏编码的超短期负荷滚动多步预测
2021-10-24储晨阳赵静波
储晨阳 秦 川 鞠 平 赵静波 赵 健
(1.河海大学能源与电气学院 南京 211100 2.国网江苏省电力有限公司电力科学研究院 南京 210008 3.国网南京供电公司 南京 210013)
0 引言
超短期负荷预测是指利用从电网中采集的实时负荷功率数据,对未来几分钟到几小时内的负荷进行预测[1],从而实时监控负荷的变化情况。超短期负荷预测是电力调度部门制定实时调度计划和日内滚动计划的基础和依据。以日内滚动计划为例,电力调度部门一般以小时级的超短期负荷滚动预测为基础,15~60min为启动周期,实时对未来几个小时的有功调度计划进行滚动修正,从而逐步降低日前计划的不确定性[2-3]。因此,精准的超短期负荷预测,对电网的安全经济运行具有重要意义。
从预测方法的角度,国内外相对成熟的超短期负荷预测模型主要分为统计模型和机器学习模型两类。统计模型主要包括线性、非线性回归模型和时间序列模型等[4-6],机器学习模型则主要包括人工神经网络、支持向量机、深度学习等[7-10]。相对而言,统计模型算法简单,但预测精度受限;机器学习,尤其是深度学习模型预测精度较高,但训练、调参相对复杂。
从预测策略的角度,现有的超短期负荷预测包括单步预测和多步预测。其中,多步预测又可分为两类:①多步递推预测,即多步预测过程中,下一步的预测值由上一步的预测值递推预测获得[11];②多步并行预测,即根据历史数据,通过一次预测直接获得多步预测值[12]。现有的超短期、短期负荷多步预测大多采用递推预测,但可能存在误差累积的问题,并且多步预测的难度会随着步数的递增而变大[13]。
从预测模型输入特征的角度,尽管负荷功率受多种外部因素的影响,但对于超短期预测而言,最重要的输入特征还是历史负荷数据,如何挖掘负荷数据自身的变化规律,并据此合理选择历史负荷输入变量是提高预测精度的关键之一。文献[14]采用长短时记忆神经网络(Long Short-Term Memory,LSTM),对仅包含历史负荷的输入特征以及包含历史负荷、温度等外部因素的输入特征集进行了对比测试。结果表明,相比于增加外部因素特征,历史负荷输入时步的合理优化更能够提高预测精度。
文献[15]提出利用基于字典的稀疏编码(Sparse Coding,SC)算法进行时间序列的回归预测。该算法充分利用历史时间序列数据构建具有时延的输入-输出数据组,包括构建“特征字典-特征向量”数据组用于求解稀疏权值向量、构建时延的“目标字典”与稀疏权值向量内积后直接获得多步的预测输出。与传统的K近邻(K-Nearest Neighbors,KNN)回归算法仅根据欧式距离提取邻近模式不同,SC算法可以充分挖掘时间序列数据的内在模式。与深度神经网络等方法相比,SC算法无需模型的训练阶段,且预测输出可以表示为目标字典中少量原子向量的线性组合,计算复杂度低。
据此,本文结合电网日内滚动计划的需求,提出了基于优化稀疏编码(Optimized Sparse Coding,OSC)的超短期负荷滚动多步预测算法,每隔15min对未来4h的负荷进行滚动多步并行预测。利用历史负荷序列构建字典,并借助用来描述负荷曲线变化趋势相似性的拓展符号化表示(Extended Symbolic Aggregate Approximation,ESAX)距离对字典原子进行优化更新,从而实现历史负荷输入的时步优化。针对预测算法在负荷高峰爬坡期间精度下降的问题,提出区间修正模型,有效地提高了超短期负荷滚动多步预测模型的整体预测效果。
1 超短期负荷多步预测方法
1.1 稀疏编码算法
SC算法的原理是寻找一组超完备字典来表示样本数据,可表示为

式中,z为样本数据;φi为字典ψ中的原子,ψ= [φ1φ2…φN];αi为稀疏权值向量α中的元素,其中大多数为零。
考虑到超短期负荷预测最重要的输入特征为历史负荷数据,本文利用历史负荷序列构建字典,优化问题的损失函数为
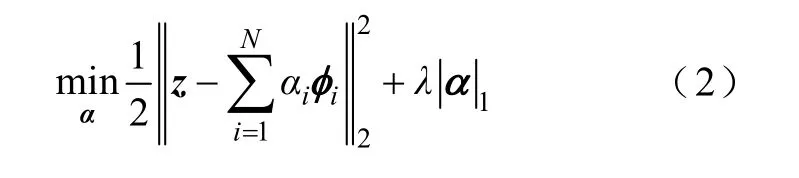
式中,前半部分表示利用基向量将特征集重构为输入样本后所产生的经验损失;后半部分表示稀疏编码的l1范数正则化;λ为用于调整经验损失与l1范数惩罚的相对贡献的超参数。
式(2)是典型的LASSO(least absolute shrinkage and selection operator)回归模型。该模型通过l1范数正则化算子压缩模型的系数,使得大多数系数为零或绝对值近似为零,从而达到稀疏系数的目的,然后通过最小回归角(Least Angle Regression,LARS)算法[16]进行求解。
在获得稀疏权值向量α后,样本负荷数据z可以表示为α中少量非零系数所对应原子向量(历史负荷模式)的线性组合。因此,借助SC算法,可以有效挖掘负荷数据序列的变化规律,有利于提高超短期负荷预测的精度。
1.2 基于SC的超短期负荷多步预测
基于SC的超短期负荷多步并行预测示意图如图1所示,稀疏编码负荷预测原理图如图2所示。采用当前时刻之前的m+n+h个历史负荷数据,构建“特征字典-特征向量”数据组,并据此计算稀疏权值向量α;将特征字典进行时延获得目标字典,与α内积后直接获得未来h步负荷的并行预测结果。图中,h取16,即每隔15min并行预测未来4h负荷,m、n为字典的维数。

图1 多步并行预测示意图Fig.1 Schematic diagram of multi-step prediction

图2 稀疏编码负荷预测原理Fig.2 Schematic diagram of sparse coding load prediction
SC超短期负荷预测的具体步骤包括:
1)字典构建
根据历史负荷序列X构建特征字典ψ(p)和目标字典ψ(t)。其中ψ(p)用于计算稀疏权值向量,ψ(t)用于进行多步并行预测。
特征字典ψ(p)可表示为

目标字典ψ(t)中的原子则通过对特征字典ψ(p)中对应的原子进行时延获得。假设多步并行预测的步数为h,则

本文研究的是周期为15min的超短期负荷的滚动预测,当滚动到下一时刻后,预测模型中的双字典及特征向量y(p)均根据最新的负荷值进行更新。
2 基于ESAX拓展符号化距离的字典优化
由上文所述,SC超短期负荷预测的关键步骤在于字典构建和稀疏权值向量计算。为了全面掌握负荷序列的变化规律,特征字典ψ(p)的维数m、n可能取值较大。假设取前14天采样间隔为15min的历史负荷数据,如图1所示,m+n+h= 1 344。根据图2所示的ψ(p)结构,字典中可能包含上千个原子,而其中可能只有部分原子与特征向量y(p)强相关,从而对稀疏权值向量计算有贡献。
为此,本文借鉴传统负荷预测中的模式匹配、相似日选择思路[17-18],采用综合考虑“符号化距离”和“趋势距离”的ESAX拓展符号化距离[19]对特征向量y(p)与特征字典ψ(p)中原子的时间序列相似性进行度量,并据此进行字典原子的优化筛选,以提高稀疏权值向量计算与负荷预测的精度和效率。
1)时间序列降维
首先,对1.2节中特征向量y(p)和特征字典原子φ(p)利用分段累积近似算法(Piecewise Aggregate Approximation,PAA)分别进行降维[20],如式(7)所示。
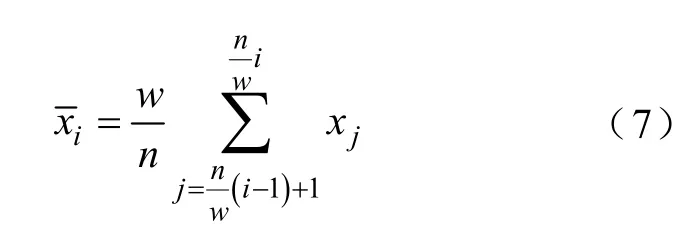
式中,xj为原始时间序列中的元素,xj∈ {x1,x2,…,xn};为降维后序列中的元素,;w<n。
某一实际日96点负荷曲线的降维示意图如图3所示,式(7)将长度为n=96的负荷曲线分为等长的w段子序列,其中w=8,然后再以每段子序列的均值来代替这段子序列。
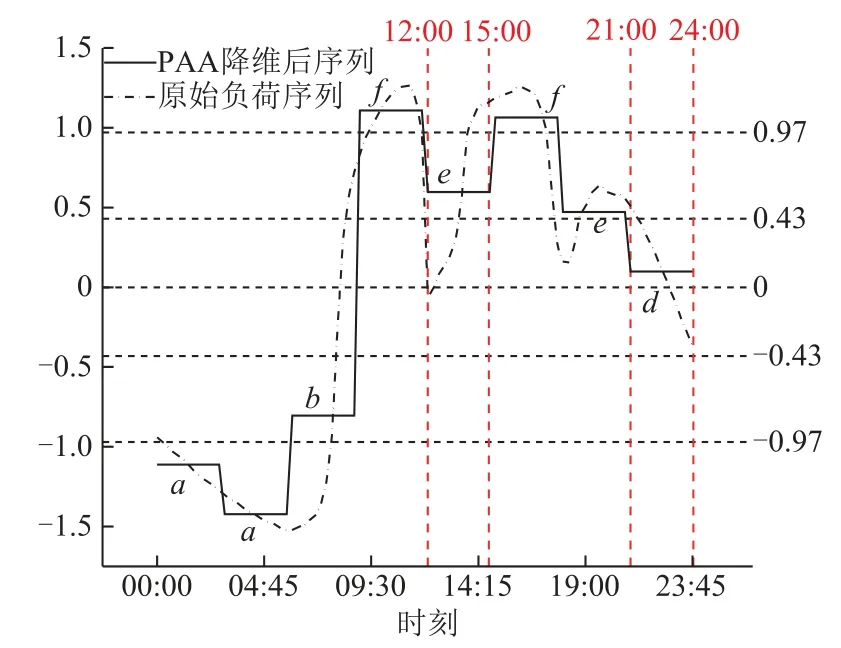
图3 SAX符号化距离示意图Fig.3 Schematic diagram of SAX distance
2)符号化距离计算
将降维后的序列值按高斯分布密度曲线分割成γ个等概率的区间,并将处于同一概率区间的序列值用同一个符号表示,可以得到时间序列的符号化表示,如图3中的字母所示。
两个子序列之间的符号化距离为[19-20]

3)趋势距离计算
从图 3还可以发现,虽然 12:00~15:00、21:00~24:00两个子序列的符号化表示(d和e)紧邻前后,但变化趋势明显相反。因此,本文在进行相似性度量时,除了符号化距离以外,还引入了趋势距离。
图3中虚线标注2段子序列的放大如图4所示。对于子序列q,可以获得其起始值qs、均值和终点值qe,从而可以计算该子序列的趋势变化特征。如图4中所示,对于子序列c,同样进行相应计算,则可以获得两个子序列的趋势变化特征{Δqs,Δqe}、{Δcs,Δce}。

图4 符号化表示相近下的子序列趋势变化对比Fig.4 The trend change comparison under similar SAX subsequence
从图4中可以看出,当Δqs与Δcs同号时,q、c两个子序列整体变化趋势相同;异号时则不同。Δqe、Δce的比较同理。为了从数值上描述此类趋势变化,q、c两个子序列之间的趋势距离可表示为

由式(9)可见,变化趋势相同的趋势距离Dt(q,c)必然小于变化趋势不同时的值。
4)ESAX复合距离计算
上文以某一日负荷曲线中的不同子序列为例,介绍了符号化距离和趋势距离的计算方法。则对于特征向量y(p)和特征字典中的原子φ(p),两者之间的ESAX复合距离可表示为

在序列长度n确定时,wn越大,降维分割区间数量越多,每段区间长度越小,则趋势为线性(单调上升或者下降)的可能性越高,因此趋势距离的权重很高。相反,当wn越小,分割区间数量越小,每段区间长度越长,区间内可能趋势复杂,因此趋势距离的权重较低。
5)相似性度量及字典优化
最后,设定距离阈值dh,并依次计算特征向量y(p)与特征字典原子φ(p)的复合距离,从而进行两者的相似性度量和字典优化,其流程如图5所示。
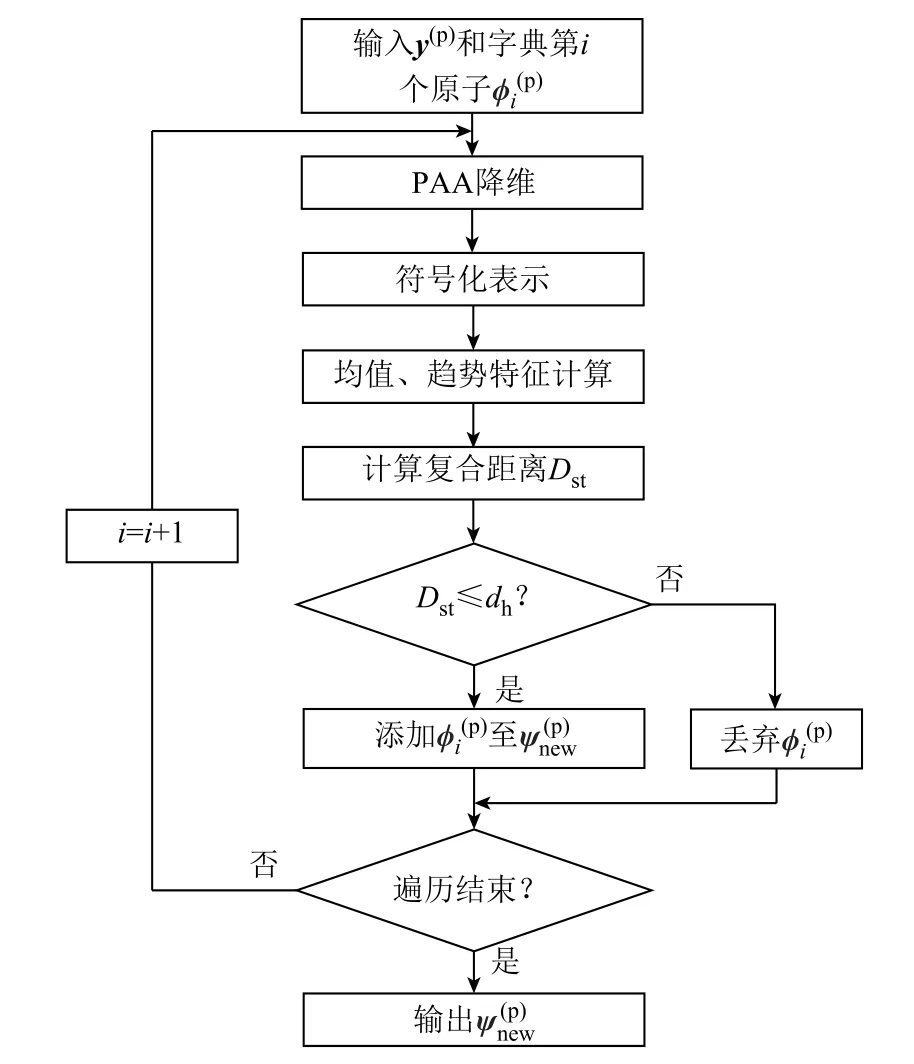
图5 ESAX符号化距离优化字典流程Fig.5 The flow chart of ESAX distance optimization on dictionary

3 误差分析与修正
本文采用第九届电工数学建模竞赛A试题区域一负荷数据进行测试,数据集为官方提供的某城市2014年全年的电力负荷数据,数据采样间隔15min。由于每次预测并行输出16步、4h的负荷预测结果,本文采用16步预测输出的平均绝对百分比误差MAPE作为滚动一次预测的误差进行分析。
3.1 预测模型参数
预测模型中需要预设的参数包括:字典参数n和m、ESAX符号化表示中降维后的维数w和符号数γ、以及相似性度量的距离阈值dh。在实际的超短期滚动预测中,可以每隔较长的一段时间,通过网格搜索(Grid Search,GS)算法[21]对参数进行优化更新,从而提高模型的适应性和预测效果。
本文以稀疏编码预测模型中字典参数n和m的取值为例说明GS算法的具体应用。由上文可知,字典原子由历史负荷序列构成。如果以历史天数T进行量化,则历史负荷序列的数据为96T点。根据图1、图2,m、n取值满足
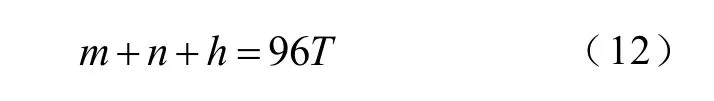
式中,h为并行预测步数,取16。n、T确定后,m值可以根据式(12)计算获得。
图6给出了不同天数历史负荷、不同n取值对预测误差的影响。从图中可以看出,选择不同天数历史负荷时,误差随着n取值的变化都表现出先降后增的趋势。而且,当T取14天、n取24时,误差最小。由此,根据式(12),m取值为1 304。为了进一步验证m的取值,图6中还给出了当n=24时,不同m取值对误差的影响,从图中可以看出,当m=1 304,也即T=14天时,误差最小。

图6 不同m和n的取值对预测误差的影响Fig.6 The influence of different values of m and n on the multi-step prediction error
在得到字典大小参数后,考虑到ESAX度量函数中系数w/n较小时能够更好地描述负荷曲线的趋势变化特征[20],本文ESAX符号化表示中符号数γ取6,子序列数w取值为8。距离阈值dh同样可采用网格搜索算法确定,多次实验后由图7平均百分比误差随阈值的变化曲线得,本文dh取值为1.4。
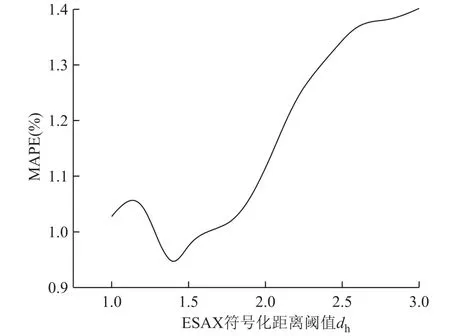
图7 距离阈值dh取值对预测误差的影响Fig.7 The influence of dh on prediction error
综上所述,本文优化稀疏编码预测模型的关键参数由网格搜索算法所得结果确定,具体见表1。

表1 优化稀疏编码预测模型关键参数Tab.1 Key parameters of OSC forecasting model
3.2 误差区间分析
在初步确定模型关键参数后,本文对数据集中一天进行滚动预测,即每隔15min滚动预测4h的负荷,从而每隔15min可以获得16步的MAPE误差值,ESAX符号化优化字典前后的误差曲线对比如图8所示。

图8 ESAX优化字典前后负荷多步滚动预测误差对比Fig.8 Comparison of multi-step rolling load prediction errors before and after ESAX optimization of dictionary
从图8中可以看出:①总体而言,ESAX距离优化字典后,预测误差平均值从1.326%下降至0.947%,优化效果较好;②在预测当天05:00~08:00区间,优化前后的误差均明显偏大,进行多次实验后,发现该误差偏大的情况多发生在早高峰负荷爬坡期间,即负荷快速增长的阶段。
为了提高负荷早高峰期间的预测精度,降低整体平均误差,对该区间进行进一步分析。当天滚动预测到7:15时刻,负荷实际值y(t)与超短期负荷预测值、实际值增量 Δy(t)与预测值增量之间的对比如图9所示。其中


图9 7:15时刻多步负荷预测结果Fig.9 The multi-step forecasting results at 7:15
由图9a可知,在负荷爬坡阶段,预测误差开始增大,并逐渐偏离实际负荷增长趋势。由图9b可得,实际值增量 Δy(t)和预测值增量之间的偏差除了负荷爬坡期间偏差增大以外,其余时间段偏差均在合理范围。可见,图9a中的预测误差越来越大主要是由负荷爬坡期间的累积误差引起的。因此,如果在负荷爬坡阶段对预测模型进行修正,提高预测值增量的精度,则之后的负荷预测效果也会得到一定程度的改善。
3.3 基于负荷增量预测的修正模型
3.3.1 负荷增量预测
由图9b可知,比较实际值增量 Δy(t)和预测值增量可以快速地判断出需要进行修正的区间。但进行超短期负荷预测时,实际增量Δy(t)是未知的,因此需要在预测前一天先行预测当日的负荷增量Δy∗(t),并以此代替实际值增量Δy(t)。考虑到负荷增量预测模型只是主要用于早高峰负荷爬坡期间,即负荷快速增长的阶段,为了简化整体模型,本文通过基于最小二乘法的分时回归预测模型(Time-Sharing Least Square Regression Model,TLSR)进行负荷增量预测[22]。
基于相似日预测思想,TLSR预测模型的输出变量为t时刻待预测负荷增量 Δy∗(t),输入变量为前N周相同类型日,如周一、周二…周日同一时刻的负荷增量 ΔYk,t={Δy1,t,… ,Δyk,t,… ,ΔyN,t}。其中Δyk,t为预测日前第k周同类型日t时刻的负荷增量实际值。由于篇幅所限,详细的预测方法不再赘述,可参考文献[22]。
为了确定TLSR模型中历史周数N的取值,本文选取预测日前3~20周同类型日的历史负荷增量数据,分别进行连续一周的负荷增量预测,得到如图10所示的箱线图。由图中可以看出,当选取前7周同类型日负荷增量数据时,TLSR预测模型的效果最好。因此,本文TLSR预测模型中N的值为7。
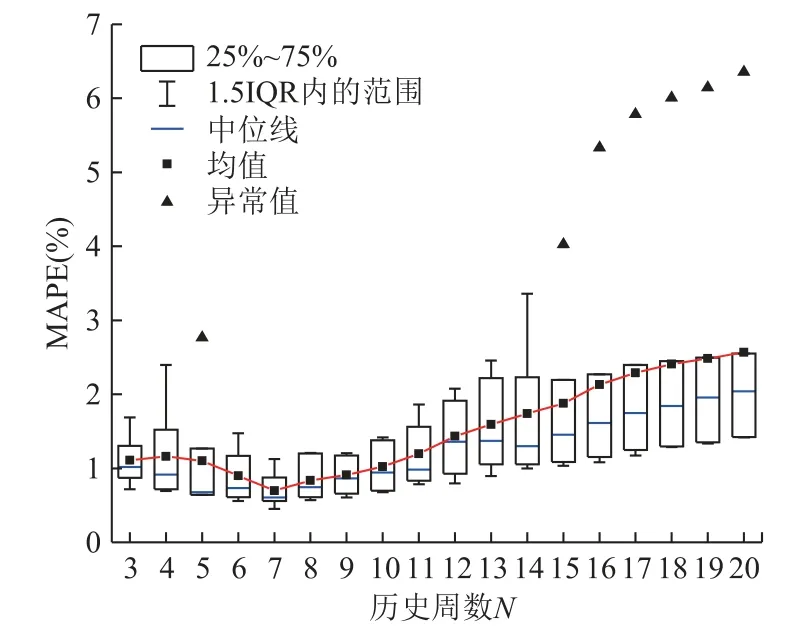
图10 不同周数下TLSR预测模型效果的箱线图Fig.10 Boxplot of TLSR model performance based on different weeks
3.3.2 负荷增量修正模型
在得到预测当日的负荷增量预测值 Δy∗(t)后,可以在超短期负荷滚动多步预测的基础上判断是否需要修正。具体修正判别指标C(t)为
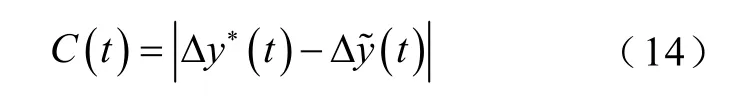
若指标超过阈值ph,即C(t)>ph,则认为t时刻负荷预测趋势已经偏离实际趋势,需要进行修正。若C(t)≤ph,则认为t时刻负荷预测精度基本满足要求,不需要修正。
当在时刻t1检测到多步预测区间[t1,t1+4h]需要修正后,则实时提取该区间基于TLSR预测的负荷增量预测值 Δy∗(t),t∈ [t1,t1+4h],并且以t1时刻的负荷实际值y(t1)为初始值,通过累加获得修正后的多步负荷预测值为
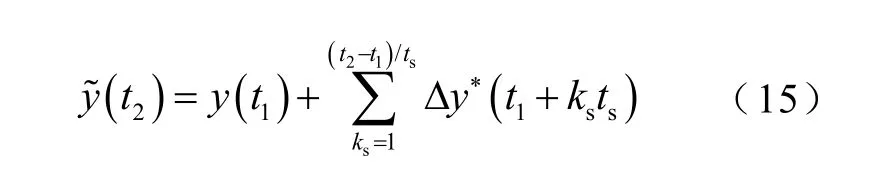
同样以网格搜索法获得修正判别阈值ph,图11给出了ph对修正后预测精度的影响。从图11中可以看出,当ph取150MW时效果最好,因此最终ph取值为150MW。
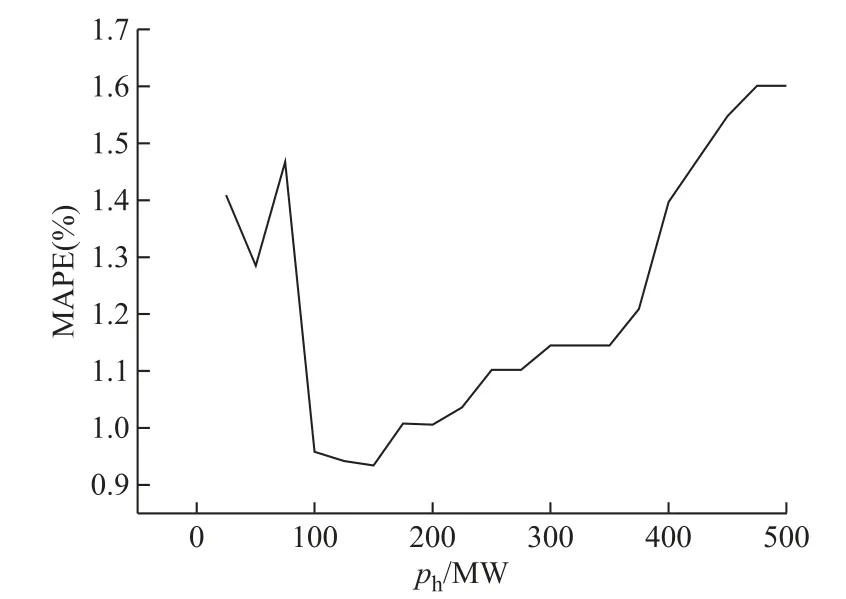
图11 修正判别阈值ph对修正效果的影响Fig.11 The influence of the threshold value on the correction effect
3.4 基于OSC的超短期负荷预测流程
综上所述,基于OSC的超短期负荷预测流程如图12所示。
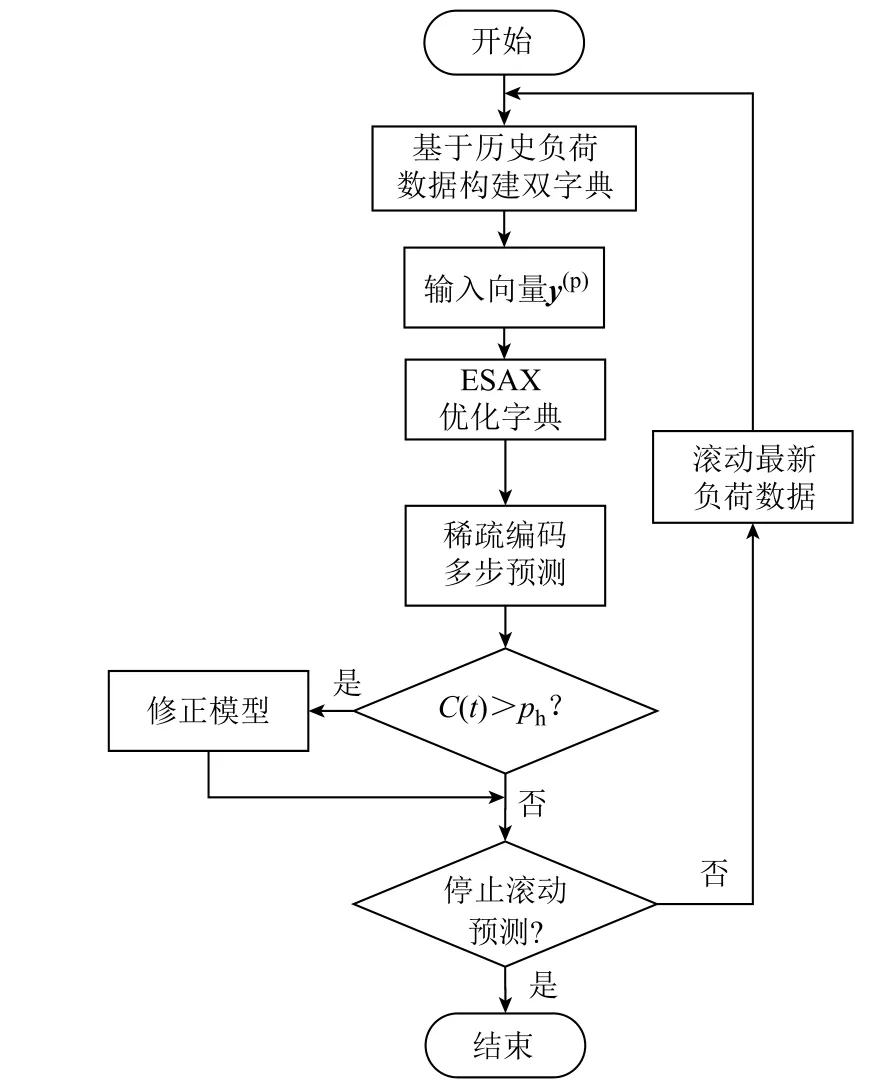
图12 基于OSC算法的超短期负荷预测流程Fig.12 The flow chart of the ultra-short load prediction based on optimized sparse coding
具体预测步骤如下:
1)以15min为采样间隔,输入当前时刻前14天的历史负荷数据,然后对历史数据进行预处理,并根据1.2节构建特征字典ψ(p)与目标字典ψ(t)。
2)基于最新特征向量y(p),通过ESAX扩展符号化距离相似性检索对特征字典ψ(p)进行优化,然后进行稀疏编码预测得到多步预测值。
3)判断是否需要进行区间修正,如需修正则按3.3节中的修正模型对多步预测结果进行修正,否则转入下一步。
4)输出最终预测结果,并且在15min间隔滚动预测结束前,重复上述预测步骤。
4 算例验证
4.1 优化前后预测结果对比
本文对数据集中2014年7月某一日数据采用SC预测算法、式(15)所示累加多步预测算法(Cumulative Multi-Step Forecasting,CMF)及本文提出的OSC预测算法在00:00~20:00进行4h的滚动预测,三种算法的误差曲线如图13所示,预测误差结果对比见表2。表2中,MPE为平均相对误差,也即滚动预测时每隔15min并行预测16步得到的MAPE的平均值;MAXE为滚动预测完成后得到的MAPE的最大值。

图13 预测算法误差曲线对比Fig.13 Comparison of error curves with different forecasting models
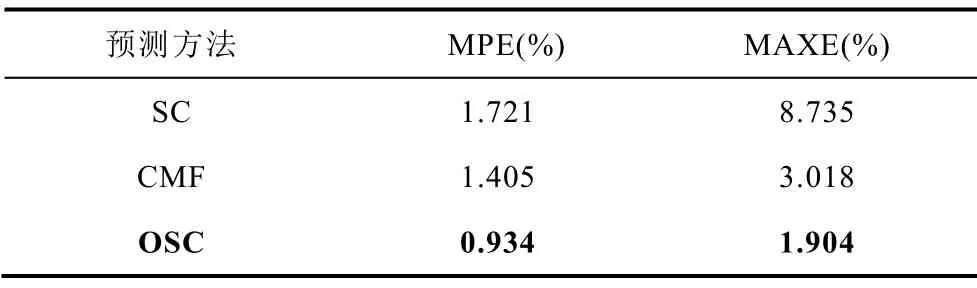
表2 预测算法结果对比Tab.2 Comparison of results with different models
从表2和图13可以看出:①与其他两种方法相比,OSC算法的最大和平均百分比误差均最小,预测效果最佳;②SC算法由于未考虑字典优化及负荷增量修正,因此在负荷爬坡区间存在误差偏大的情况,在其余时间段的误差也大于OSC算法;③CMF算法在负荷爬坡区间误差小,但在其余时间段的误差总体大于其他两种算法。因此,CMF算法仅适用于负荷爬坡阶段的预测修正。
4.2 不同预测方法效果对比
为了进一步验证OSC算法在超短期负荷多步滚动预测上的优越性和实用性,本文分别采用传统线性回归预测方法和常用的机器学习方法与本文方法进行了对比测试。其中,传统预测方法选用的局部加权线性回归(Locally Weighted Linear Regression,LWLR)和自回归移动平均模型(Autoregressive Integrated Moving Average Model,ARIMA)。常用的机器学习方法选用的是多层感知器神经网络(Multilayer Perceptron,MLP)和极端梯度提升(Extreme Gradient Boosting,XGBoost)。
在进行对比测试时,同样对其他算法进行了模型参数寻优,结果见表3。各算法的优化参数分别为:MLP算法中的隐含层个数C及学习率γ;XGBoost算法中的最大深度Z、学习率ε;ARIMA算法中的自回归系数p、差分系数d和移动平均系数q;LWLR算法中的高斯核参数σ。
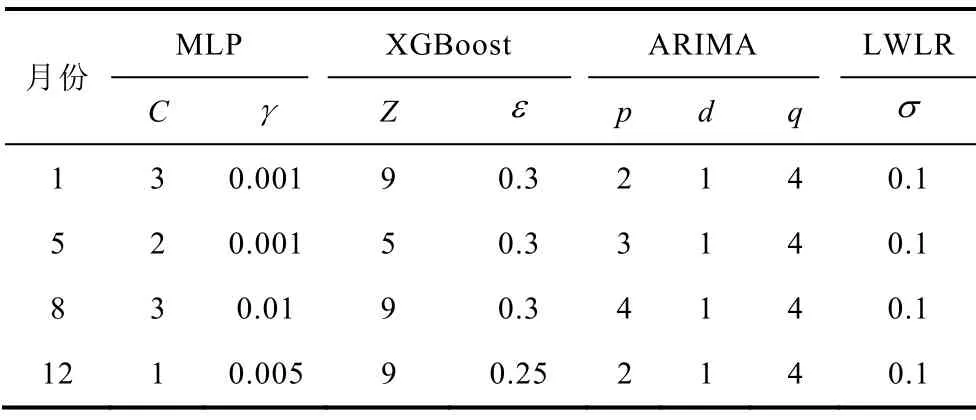
表3 对比方法典型月份优化参数Tab.3 Optimized parameters of methods in typical months
负荷数据集中典型月份连续一周每隔15min、并行预测16步的的滚动预测平均相对误差MPE和误差最大值MAXE见表4~表7。表中RMSE为连续预测一周的平均方均根误差值。

表4 1月份不同超短期预测算法结果对比Tab.4 Comparison of load forecasting results at Jan.

表5 5月份不同超短期预测算法结果对比Tab.5 Comparison of load forecasting results at May.
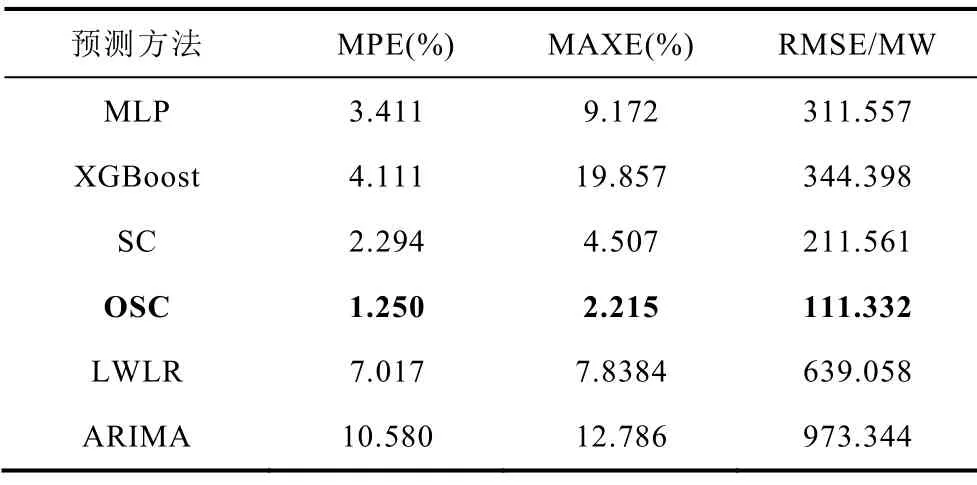
表6 8月份不同超短期预测算法结果对比Tab.6 Comparison of load forecasting results at Aug.
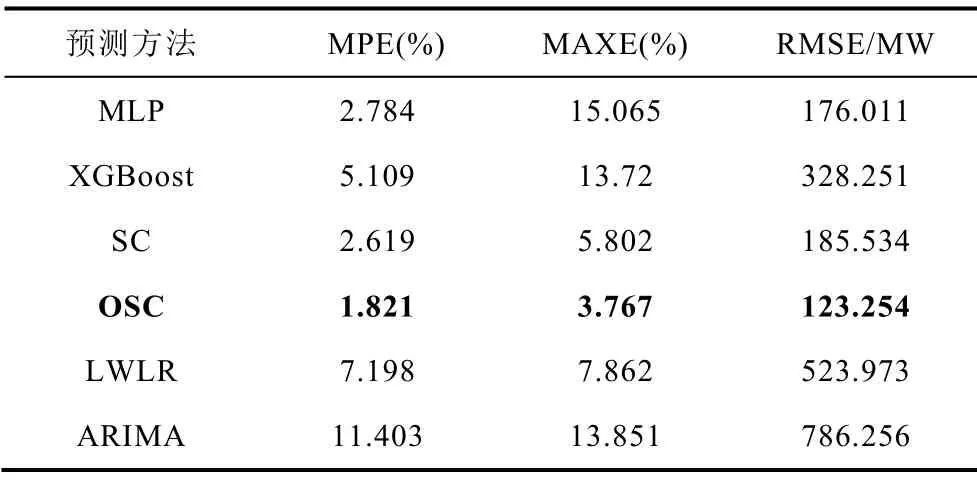
表7 12月份不同超短期预测算法结果对比Tab.7 Comparison of load forecasting results of at Dec.
从表中可以看出,本文所提OSC预测算法在全年的负荷多步预测效果表现良好,且不同典型月份中的平均百分比误差和平均方均根误差均小于其他对比算法,从而验证了本文方法的有效性。
5 结论
本文将稀疏编码算法应用于超短期负荷多步滚动预测,借助包含幅值和趋势变化复合特征的ESAX符号化距离相似性度量方法优化字典,增强了稀疏编码的特征识别能力。基于误差分析,进一步引入了基于负荷增量预测的区间修正模型,改善了稀疏编码预测在负荷爬坡期间误差偏大的情况。采用第九届电工数学建模竞赛的负荷数据集进行了测试,结果表明本文方法具有良好的预测精度。
