基于McDiarmid 界的概念漂移数据流分类算法
2021-10-12李光辉
梁 斌,李光辉+
1.江南大学 人工智能与计算机学院,江苏 无锡 214122
2.物联网技术应用教育部工程研究中心,江苏 无锡 214122
随着物联网技术的快速发展,社会各个领域产生了大量数据流,如传感器数据流、电子商务数据流等。随着时间的推移,数据流的目标概念或潜在分布会发生变化,这种现象被称为概念漂移[1-2]。例如顾客网上购物的喜好分析会随着时间、商品的变化而改变;工厂的用电量随着季节交替出现周期性变化[3]。概念漂移会导致已有的分类模型性能显著下降,因此数据流挖掘算法要求快速准确地检测出漂移并及时调整原分类模型,快速适应当前新概念,提高数据流的分类准确率。目前处理概念漂移的算法大致可分为两类[4-5]:主动检测和被动适应。
主动检测算法具有显式的漂移检测机制,通常与在线分类器组合使用。检测到漂移时,当前分类器被丢弃同时,训练一个新的分类器。如Gama 等提出的DDM(drift detection method)[6]是第一个主动检测型算法,它假设数据流服从正态分布,通过监测分类模型的错误率变化检测概念漂移,但该方法只适合检测突变型漂移,不适合渐变型漂移。Barros 等提出的RDDM(reactive drift detection method)[7]通过周期性地重置DDM 的漂移检测统计量解决DDM 在长期稳定数据流下的漂移检测敏感性下降的问题。Pears等提出的SeqDrift(sequential hypothesis testing drift detector)[8]维护两个相邻的滑动窗口,通过比较两个窗口中的错误率差异是否超过某阈值检测漂移,该阈值由Bernstein界确定。Frias-Blanco等提出的HDDM(drift detection methods based on Hoeffding bounds)[9]利用Hoeffding 界检验当前模型的错误率是否发生显著性变化检测漂移。Barros 等提出的FPDD(concept drift detection based on Fisher's exact test)[10]使 用Fisher's exact test 检验两个相邻窗口中的错误率是否存在统计学上显著性差异,若存在则表明出现概念漂移。针对重复概念问题,Gonçalves 等提出的RCD(recurring concept drifts)[11]在DDM 的基础上,结合多元非参数统计方法识别当前的新概念是否为过去概念的重现。类似的,白洋等提出的DRDM(drift recurrence detection method)[12]在SeqDrift 的基础上,使用有向图保存历史概念并使用Hotelling's T2检验判断新旧概念是否来自同一分布。
被动适应型算法大都为集成算法,没有专门的漂移检测机制,通过调整集成模型的结构和成员分类器的权重被动适应概念漂移。如Brzezinski 等提出的AUE 算法(accuracy updated ensemble)[13],每到达一个数据块训练一个新的分类器添加至集成中,每个分类器的权重由它们的分类准确率决定。进一步,Brzezinski 等提出OAUE 算法(online accuracy updated ensemble)[14],该算法在AUE 的加权公式中引入了时间概念,同时结合在线分类器,更好地处理各种类型概念漂移。Elwell 等提出的LearnNSE[15]使用复杂的加权策略,每个基分类器的权重需要综合考虑当前和过去所有数据块上的错误率。
目前处理概念漂移的数据流分类算法主要存在两个问题:一是漂移检测延迟和误报率较高,且难以同时处理不同类型漂移;二是缺乏识别重复概念的能力,当历史概念重现时,当前分类模型无法利用过去所学知识快速适应新概念。为此,本文基于双层模糊窗口和McDiarmid 界,结合半参数对数似然比方法,提出了一种新的可以适应多类型概念漂移的数据流分类算法(data stream classification algorithm based on double-layer fuzzy sliding window and McDiarmid bound,DFWM)。该算法维护一个固定大小的双层滑动窗口,保存当前模型最新的分类结果,根据隶属度函数对窗口中每个数据分配对应权重并计算加权错误率,然后利用McDiarmid 界检验当前窗口中的错误率是否发生显著性变化来检测概念漂移。同时DFWM 维护一个分类器池保存已出现过的概念及其对应的分类器,检测到漂移时,使用半参数对数似然方法判断当前概念是否为某个旧概念的重现,若是则直接复用旧概念对应的分类器,否则重新构建一个新的分类器。实验结果表明,与同类算法相比,所提算法在漂移检测延迟、误报率、分类精度和运行时间上均有一定优势。
1 相关知识
1.1 概念漂移定义和分类
根据文献[2,16-17],概念漂移的定义如下:
定义1概念漂移设[0,t]表示一段时间,数据流可表示为St={d0,d1,…,dt},其中di=(Xi,yi)表示一个实例,Xi为特征向量,yi为标签,i=1,2,…,t。假设St服从某分布Ft(X,y),P(y|X)表示y关于X的条件概率分布,若在t+1 时刻有Ft(X,y)≠Ft+1(X,y)且Pt(y|X)≠Pt+1(y|X),表明原有的决策边界发生变化,这种现象称为概念漂移。
概念漂移的分类普遍是基于概念变化的速度[1-2,7]。当新旧概念过渡很快,旧的概念突然被另一个数据分布完全不同的新概念取代,这种漂移属于突变型概念漂移(abrupt concept drift),如图1(a)所示,其中实心圆代表一段数据,圆内的数字代表到达的时间;反之,新旧概念过渡较慢时,旧概念被新概念逐渐替换,且二者在漂移前后或多或少有些相似,如图1(b)所示,这种漂移则属于渐变型概念漂移(gradual concept drift)。
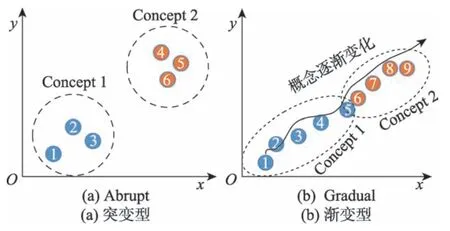
Fig.1 Abrupt and gradual concept drift图1 突变型和渐变型概念漂移
重复概念漂移指过去的某个概念再次出现,既可以有规律地出现,也可以无规律地出现[11],通常与突变型漂移或渐变型漂移联合出现,如图2(a)中的数据段7 和8 即是重复概念,图2(b)中的数据段9 也是重复概念。
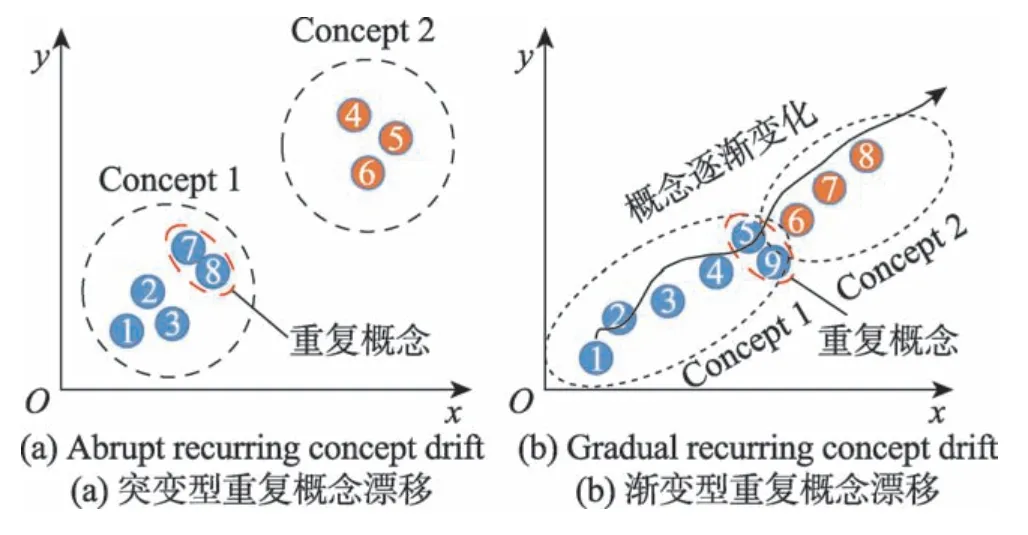
Fig.2 Recurring concept drift图2 重复概念漂移
1.2 模糊集理论和隶属度函数
若论域U中的任一元素x,都有一个值A(x)∈[0,1]与之对应,则称A为U上的模糊集,A(x)称为元素x对A的隶属度。当x在U中变化时,A(x)则是关于x的函数,称为A的隶属度函数。在模糊集理论中,使用取值在区间[0,1]的隶属度函数A(x)表征x属于A的程度。A(x)的值越接近于1,表示x属于A的程度越高;A(x)越接近于0,则表示x属于A的程度越低。常见的隶属度函数有梯形型、对数型和柯西型等[18],本文主要使用了对数型隶属度函数A(x),如式(1)所示。
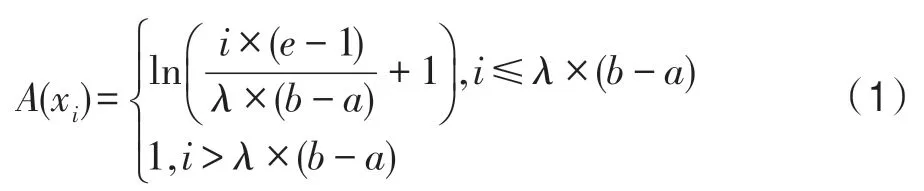
其中,a、b代表区间[a,b]的左右端点,xi为区间中的第i个元素,e为自然常数,λ为自定义常数,用于控制隶属度函数的形状。
1.3 半参数对数似然算法
文献[19]提出了半参数对数似然算法(semiparametric log-likelihood,SPLL),它从似然的角度检验两组多元样本W1和W2是否来自同一概率分布。相较于传统的K-L 散度检验和Hotelling's T2检验,SPLL 的计算更为简单,检验效果更好。它假设样本W1服从分布p1,W2服从p2,则W2中数据的对数似然比LLR如式(2)所示:

式中,L(⋅)代表似然函数。由于W2服从p2,故L(W2|p2)=1。式(2)可改写为式(3),这意味着LLR代表W2中的数据拟合分布p1的程度。

LLR的缩放上界LL,如式(4)所示,其中x为样本W1中的一个实例,n代表x的维度,u为距x马氏距离最近的簇中心,簇中心由K-means 聚类得到,Σ为W1中数据的协方差矩阵。
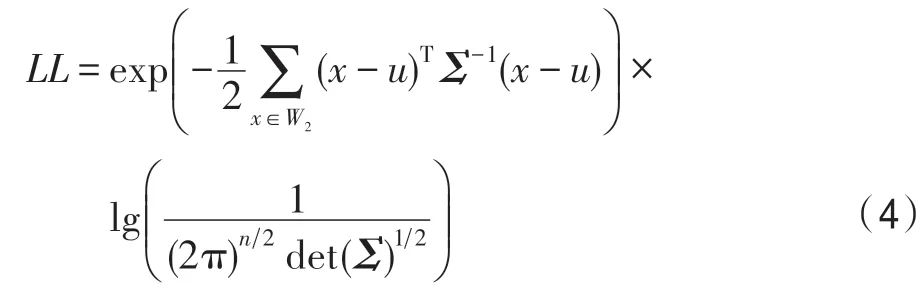
使用LL,可得SPLL的检验统计量δ如式(5)所示:
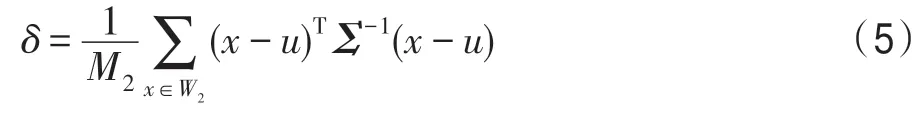
若δ服从自由度为n的卡方分布,表明W2中的数据服从分布p1,即W1和W2中的数据来自相同的分布。
2 基于McDiarmid 界的概念漂移数据流分类算法(DFWM)
DFWM 由两部分组成:概念漂移检测模块和重复概念识别模块。本章先介绍基于双层模糊窗口和McDiarmid 界的概念漂移检测机制,并给出了漂移检测阈值的计算方法,然后介绍如何识别重复概念,最后描述DFWM 的算法流程。
2.1 概念漂移检测机制
根据PAC(probably approximately correct)理论,随着数据流规模的增加,分类模型的错误率应该逐渐下降或保持不变。否则,数据流中有很大可能出现概念漂移[6]。基于此,概念漂移检测问题可转化为检测分类模型的错误率是否发生显著性变化。数据流的长度是无限的,无法获取所有数据,因此通常使用固定长度的滑动窗口来获取当前最新数据,根据滑动窗口内的错误率的变化情况检测概念漂移也是漂移检测领域的常用方法[8,18,20-21]。然而,滑动窗口大小的选择对概念漂移检测的效果至关重要。大量实验发现(如3.4 节的实验结果),面对突变型漂移,使用短窗口具有更低的检测延迟。而面对渐变型漂移,使用长窗口的检测延迟更低,漏报率也显著低于使用短窗口,因此仅使用一个单层滑动窗口难以同时适应突变型和渐变型漂移。为此,本文在靠近长窗口头部的位置分割窗口,形成长短嵌套的双层滑动窗口。每次检测先使用短窗口,若未检测到漂移,再使用长窗口检测,可以兼顾不同类型的漂移。双层窗口结构如图3 所示,短窗口位于长窗口的头部(图3 中双层窗口的右侧为窗口头部,左侧为窗口尾部),负责检测突变型漂移,而长窗口用于检测渐变型漂移。
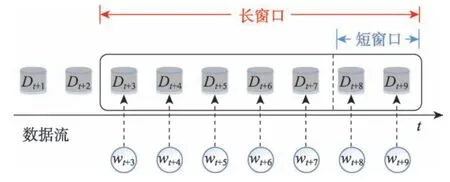
Fig.3 Structure of double-layer window图3 双层窗口结构
窗口中每个数据的到达的时间不同,当前的数据必然比过去的数据更能代表当前概念,因此在计算窗口内错误率时,应该对靠近窗口头部的数据分配更大的权重,以便更快速地检测概念漂移。隶属度函数可以很好地反映集合中每个元素对集合的隶属程度,当出现概念漂移时,窗口头部的数据对新概念的隶属程度必然大于窗口尾部的数据,因此使用1.2 节中介绍的对数型隶属度函数对窗口中的每个数据分配权重,权重计算方法如式(6)所示:
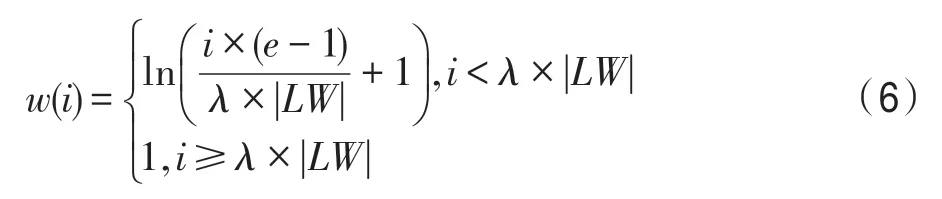
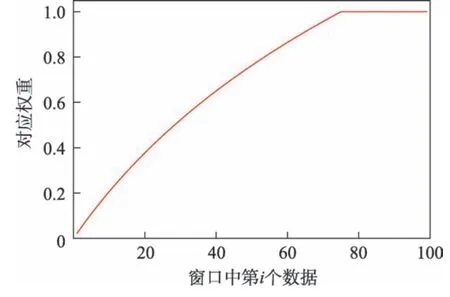
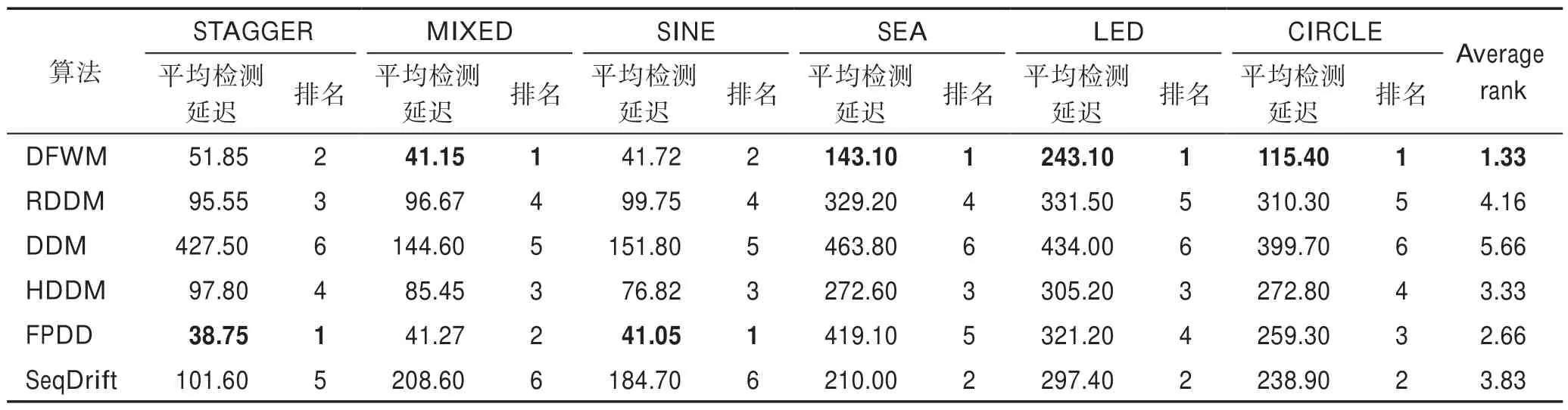
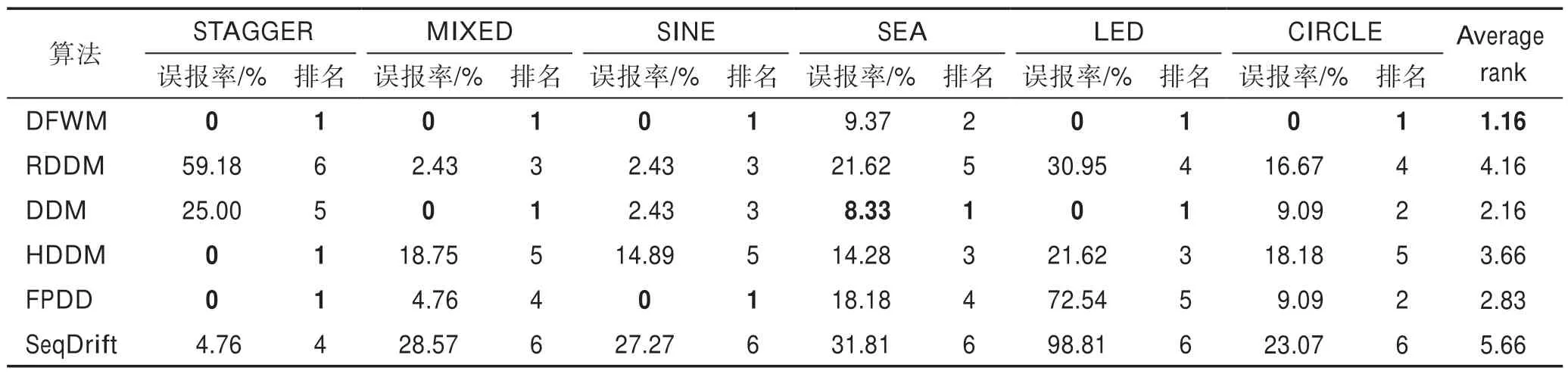
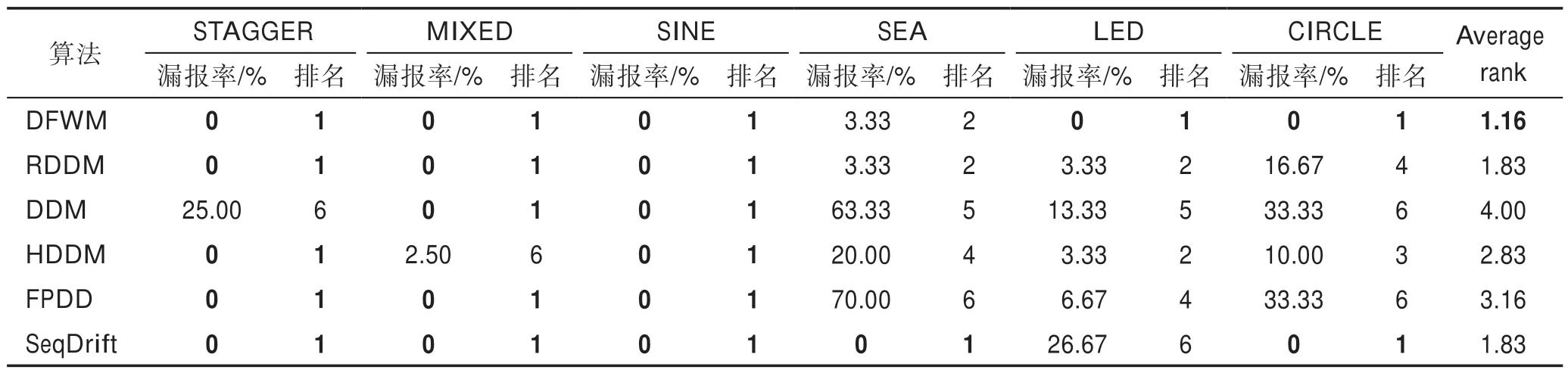
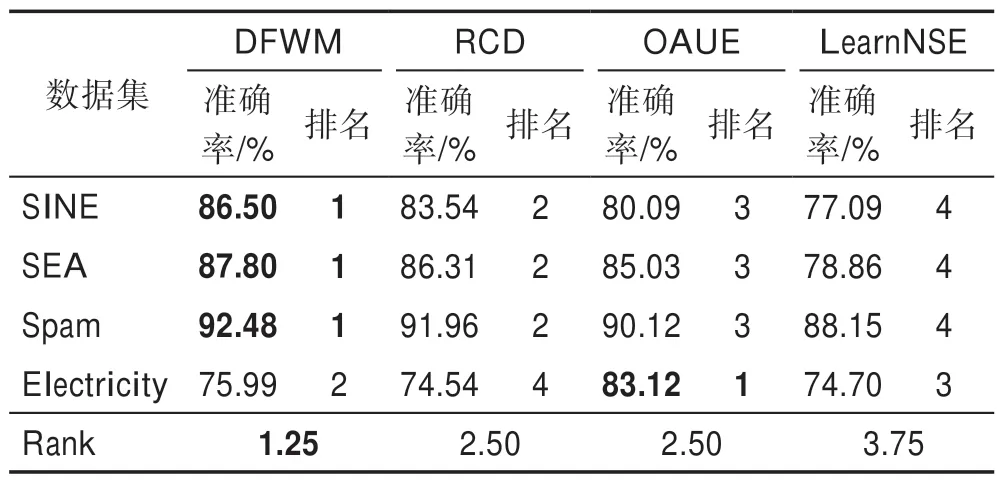
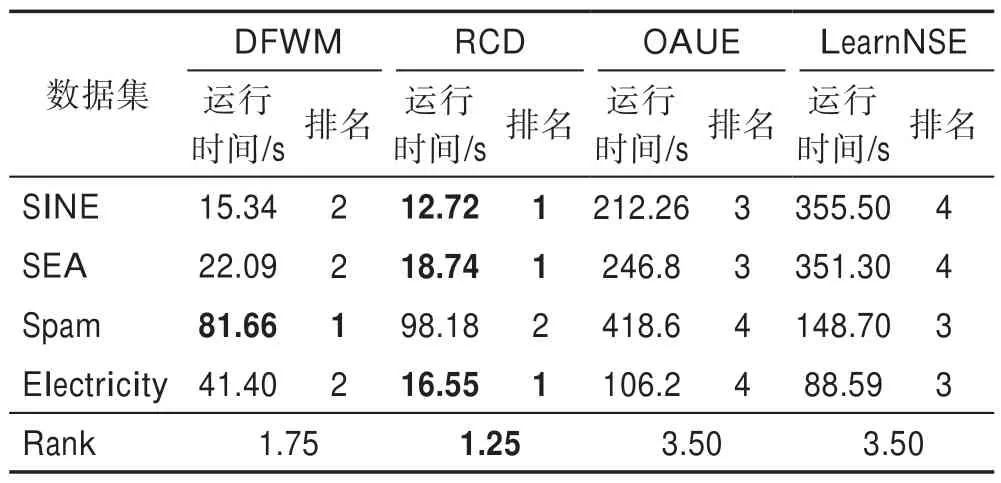
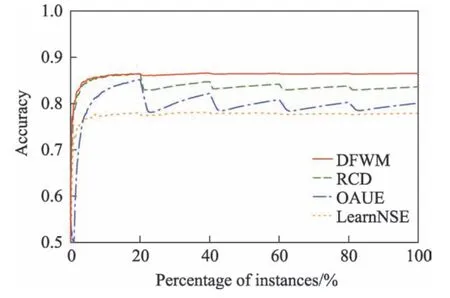
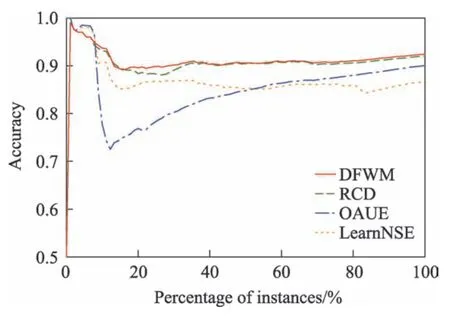
其中,w(i)表示双层窗口中第i个数据(窗口尾端的数据为第1 个数据)的权重,表示长窗口的大小,e为自然常数,λ为预设值,决定隶属度函数的形状。式(6)为分段函数,靠近窗口头部,即短窗口中的数据最能代表当前概念,因此权重均设为最大值1,之后数据的权重根据对数函数逐渐衰减,当1 Fig.4 Weight distribution of each data in window图4 窗口中每个数据权重的分布 DFWM 的漂移检测过程如下:每到达一个实例,先使用当前模型获取分类结果并添加至双层窗口中,分类错误记为1,正确记为0。然后根据式(8)计算短窗口内数据的加权错误率,其中di是窗口中第i个元素,wi是其对应的权重,如果psw 若当前短窗口内错误率psw与其历史最小值psw′满足式(9),表明当前短窗口内错误率psw较过去出现了显著性变化,即数据流中出现了概念漂移。式(9)中阈值的θ1由McDiarmid 界决定(2.2 节详细介绍阈值的计算)。 若使用短窗口未检测到概念漂移,继续计算长窗口内数据的加权错误率plw,计算方法与计算psw相同。如果plw 若式(9)、式(10)均不满足,表明当前数据流处于稳定状态,无概念漂移。 DFWM 中的漂移检测阈值的计算依赖于McDiarmid 界[22-23],该统计边界不需要对数据流的分布做任何假设,给出了样本的函数f与其期望值E[f]之差的上界,如定理1 所示。 定理1McDiarmid 界设X1,X2,…,Xn为n个独立有界随机变量,其中Xi∈A∈[a,b]。设f:An→R 为X1,X2,…,Xn上的一个函数,且满足∀i,∀x1,x2,…,xi,…,xn,xi′∈A,|f(x1,x2,…,xi,…,xn)-f(x1,x2,…,xi′,…,xn)|≤ci,即使用集合A中的任意值xi′替换函数f中的第i个元素xi最多改变函数f的值为ci。对于任意θ>0,则有: 式(11)表明f与其期望值E[f]之差大于θ的概率受到关于θ的指数边界控制,在给定显著性水平α下,令式(11)中不等号的右侧等于α,θ值可由式(12)获得: 在DFWM 中,双层窗口中保存的分类结果di均为二值变量,即di∈{0,1},分类错误记为1,正确记为0。因此式(8)中的加权错误率就是窗口中数据的加权平均值。以短窗口检测漂移为例,介绍2.1 节中的阈值θ1的计算过程(长窗口中的阈值θ2同理)。首先将式(8)改写为式(13): 其中,vi如式(14)所示,wi为短窗口中第i个数据di对应的权重,|SW|为短窗口大小。 式中,psw是关于di的函数,记作psw(d1,d2,…,di,…,d|sw|),且满足∀i,∀d1,d2,…,di,…,d|sw|,di′∈{0,1},|psw(d1,d2,…,di,…,d|sw|)-psw(d1,d2,…,di′,…,d|sw|)|≤ci,其中ci=(1-0)vi,即ci=vi。当数据流处在稳定状态,无概念漂移时,短窗口内错误率psw会逐渐下降最终稳定在其最小值psw′附近,因此psw′可以代表psw的期望值。将psw和psw′代入式(11)可得式(15): 在给定的显著性水平α下,根据式(12)可得短窗口漂移检测阈值θ1,如式(16)所示: DFWM 检测到概念漂移时,表明数据流中出现了新概念,当前分类器不再适用。通常的做法是丢弃当前分类器,重新训练一个新的分类器去适应新概念。然而,如果当前的新概念是某个历史概念的重现,即数据流中出现了重复概念,重新训练一个分类器的代价比复用旧分类器大得多。复用旧分类器可以充分利用过去已学习到的知识,更快地适应新概念。基于此,DFWM 使用分类器池和1.3 节中介绍的SPLL 处理重复概念。具体来说,使用C={C1,C2,…,Ci,…,Cm}表示由m个分类器组成的分类器池,其中每个分类器Ci附带它的使用频率k和一个数据块Bi,Bi用于保存分类器Ci的错误率达到最小值时对应的若干数据,因为此时数据流最稳定,这些数据最能代表当前概念,Bi的大小和长窗口|LW|大小相同。检测到漂移时,若分类器池非空,根据池中每个分类器频率的高低,使用SPLL 依次对每个分类器对应的数据块和当前窗口中的数据检验,若二者来自相同分布,表明出现了重复概念,直接复用该分类器,并将它的使用频率加1。否则,表明数据流中出现了全新的概念,将当前的分类器和它对应的数据块添加至分类器池中,使用频率置为1,然后使用当前数据重新训练一个新分类器。出于占用内存的考虑,不可能把所有出现过的概念及其对应分类器都保存到分类器池中。频率最低的分类器表明它对应的概念最少出现,因此分类器池容量达到上限时移除该分类器。DFWM 是基于单分类器的分类算法,只使用当前分类器进行预测,分类器池只保存若干训练过的旧分类器。如果被删除的最低频率分类器对应的概念再次出现,DFWM 会立即使用当前数据重新训练一个分类器,这只会增加一定的时空开销,不会影响信息的完整性。识别重复概念进而复用过去已训练好的旧分类器,可以充分利用过去所学知识,快速适应当前概念,有效提高DFWM 的分类速度和准确率。同时避免了重复概念导致重复训练的问题,降低时间和空间的开销。 DFWM 的执行流程图如图5 所示。 Fig.5 Flow diagram of DFWM图5 DFWM 的流程图 为验证DFWM 的性能,本文在6 个人工数据集和2 个真实数据集上进行了两方面的实验:(1)与DDM[6]、SeqDrift[8]、HDDM[9]、RDDM[7]和FPDD[10]五种算法进行对比实验,从漂移检测延迟、误报率和漏报率三方面验证DFWM的漂移检测性能;(2)与RCD[11]、LearnNSE[15]和OAUE[14]三种算法进行对比实验,从分类准确率和运行时间两方面验证DFWM 的分类性能。本文的实验环境为一台处理器为Intel Core i7-7700HQ,内存为16 GB 的笔记本电脑,运行Windows 10 系统和python3.7。在该环境下,分别实现了本文算法和各种对比算法。DFWM 的参数均根据大量实验结果设置:长窗口大小|LW|设为100,隶属度函数参数λ设为0.75,显著性水平α为10-7,分类器池的最大容量m为10,池中分类器对应的数据块B的大小为100。对比算法保持与原论文完全相同的参数设置。所有实验采用test-then-train 策略,即每个实例先用作测试数据,然后作为训练数据,这种策略不用划分数据集,可以充分利用每个数据的信息。 人工数据集在概念漂移检测领域十分重要,因为可以人为定义概念漂移的数量、位置和持续时间,以模拟不同的场景。本文用到的6个人工数据集均为概念漂移领域的Benchmarks,可通过python 的skmultiflow[24]包生成,详情如下所示: SINE:该数据集包含突变重复型漂移,它有两个属性x和y。分类函数是y=sin(x),在第一次漂移之前,函数曲线下方的实例被标记正,曲线上方的被标记为负,共有两个类别。在漂移点,通过突然反转分类规则来产生漂移。数据集共包含100 000 个实例,每隔20 000 个实例产生一次漂移,共有5 个概念,其中第1、3、5 个概念互为重复概念,第2、4 个概念互为重复概念,含10%噪声。 STAGGER:该数据集包含突变型漂移,它有3 个离散属性和2 个类别,每隔33 333 个实例通过突然反转分类规则产生漂移,共100 000个实例,含10%噪声。 SEA:该数据集包含渐变重复型漂移,有3 个连续属性,其中第3 个属性与类别无关,如果x1+x2<θ,实例分类为正,否则为负,x1、x2表示前两个属性。每隔20 000 个实例,通过逐渐改变阈值θ来产生渐变型漂移,共包含100 000 个实例,含10%噪声。阈值θ∈{5,15,5,15,5},其中第1、3、5 个概念互为重复概念,第2、4 个概念互为重复概念。 LED:该数据集包含渐变型漂移,有24 个属性,共10 个类别。通过逐渐改变相关属性值来产生渐变型概念漂移,共包含100 000 个实例,每隔25 000 个实例产生一次渐变型漂移,含10%噪声。 MIXED:该数据集包含突变型漂移,它有两个连续属性x和y以及两个布尔属性v和w。如果满足条件v,w,y<0.5+0.3×sin(2πx),实例被分类为正,否则为负,共有两个类别。在漂移点,通过突然反转分类规则产生漂移。数据集共包含100 000 个实例,每隔20 000 个实例产生一次漂移,共有5 个概念,其中第1、3、5 个概念互为重复概念,第2、4 个概念互为重复概念,含10%噪声。 CIRCLE:该数据集包含渐变型漂移,它有两个连续属性x和y。4 个圆方程表示4 个不同概念,圆内的实例被分类为正,圆外为负,共2 个类别。在漂移点通过逐渐改变圆的方程来产生漂移。数据集共包含100 000 个实例,每隔25 000 个实例产生一次渐变型漂移,含10%噪声。 人工数据集中的数据均为随机产生,因此使用skmultiflow 包在每类人工数据集上生成10 个不同的子集,做10 次实验,取平均值作为最终结果。 2个真实数据集均为概念漂移领域的Benchmarks,详情如下所示: Spam:该数据集包括9 324 个实例和500 个属性,每个实例表示一个邮件的信息,有两个类别垃圾邮件和合法邮件,其中垃圾邮件的特征会随着时间变化。可在http://mlkd.csd.auth.gr/concept_drfit.html下载。 Electricity:该数据集收集了1996 年 至1998 年澳大利亚新南威尔士州电力市场的45 312 个实例,包含8 个属性和2 个类别。该数据集可在http://sourceforge.net/projects/moa-datastream/files/Datasets/Classification/下载。 所有数据集的信息总结如表1 所示。 根据文献[2],概念漂移数据流分类算法通用的评价指标有平均检测延迟(average delay of detection,ADOD)、误报率(false positive rate,FPR)、漏报率(false negative rate,FNR)、运行时间和分类准确率。特别地,平均检测延迟、误报率、漏报率定义如下: (1)平均检测延迟(ADOD):假设第i个漂移发生的时刻为Ti,漂移被检测到的时刻为Ti′,则检测延迟为(Ti′-Ti)。平均检测延迟,其中dist=为所有检测延迟之和,n为检测到的漂移个数。 根据文献[7],通过定义可容忍的最大检测延迟Δd来定义误报率和漏报率,Δd通常为概念长度的2%。例如在SINE数据集中,概念长度为20 000,则Δd为400。设漂移发生的时刻为T,则在区间[T,T+Δd]内检测到的漂移个数视为正确检测个数(TP)。基于此,误报率和漏报率的定义如下所示: (2)误报率(FPR):在区间[T,T+Δd]外检测到漂移的个数视为误报个数(FP)。 (3)漏报率(FNR):在区间[T,T+Δd]内漏检的漂移个数视为漏报个数(FN)。 Table 1 Datasets of experiments表1 实验数据集 本节通过与DFWM_S、DFWM_L 的对比实验来验证DFWM 中双层窗口的有效性,其中DFWM_S 只使用大小为25 的短窗口,DFWM_L 只使用大小为100 的长窗口,其他设置相同。每个表中的检测指标的最优值加粗表示,排名1 表示在某个数据集上的效果最好。由表2 知,DFWM_S 在STAGGER、MIXED和SINE 3 个突变型漂移数据集上平均检测延迟较低,与DFWM 相似;而在其他3 个渐变型漂移数据集上平均检测延迟显著高于DFWM。DFWM_L 与它正相反。误报率方面,由表3 知,DFWM_S 没有出现误报,而DFWM、DFWM_L 在SEA 上出现了少量误报。漏报率方面,由表4 知,DFWM_S 在LED、SEA和CIRCLE 3 个渐变型漂移数据集上的漏报率远高于其他两种算法。综合来看,使用短窗口的DFWM_S适合检测突变型漂移,而使用长窗口的DFWM_L 更适合检测渐变型漂移,DFWM 使用双层窗口结合了二者的优点,在突变型和渐变型漂移数据集上均获得了较好的检测效果。 表5~表7给出了6种算法(DFWM、DDM、SeqDrift、HDDM、RDDM 和FPDD)在6 个人工数据集上的平均检测延迟、误报率和漏报率的实验结果。由表5知,在平均检测延迟方面,DFWM 在MIXED、SEA、LED 和CIRCLE 这4 个数据集上最低,排名第1,较第2 名分别降低了0.12、66.9、54.3、123.5。在SINE 和STAGGER 数据集中位列第2,检测延迟略高于FPDD,在所有数据集上平均排名第1。误报率方面,如表6 所示,DFWM 仅在SEA 上出现了误报,误报率较第1 名高出了1.04%,在所有数据集上平均排名第1。由表7 知,DFWM 仅在SEA 数据集上存在漏报,漏报率较第1 名高出了3.33%,在所有数据集上平均排名第1。 具体来看,DDM 在各数据集上均有较高的检测延迟和漏报率,在包含渐变型漂移的数据集上更为严重。RDDM 则在DDM 基础上,通过设定阈值周期性地重置DDM 的漂移统计量来提高检测漂移的敏感性,一定程度上降低了检测延迟和漏报率,但也增加了误报的风险。在6 个人工数据集上平均检测延迟和漏报率都低于DDM,但误报率都高于DDM。HDDM 的效果与RDDM 相似,在所有数据集上较DDM 有更低的检测延迟和漏报率,但这以增加误报为代价。FPDD 在STAGGER、SINE 和MIXED3 个突变型漂移的数据集上检测效果很好,具有极低的检测延迟、误报率和漏报率,而在其他3 个渐变型漂移的数据集上效果很差。SeqDrift 在渐变型漂移的数据集上的检测延迟要好于突变型漂移数据集,而在所有数据集上均存在较高的误报率,但漏报率极低,仅在LED 数据集上出现了漏报。与其他算法相比,DFWM 处理突变型漂移的能力仅次于FPDD,由表5知,在STAGGER、SINE 和MIXED 3 个突变型数据集上,FPDD 的平均检测延迟最低,DFWM 次之。而DFWM 处理渐变型漂移能力显著强于其他算法,在LED、CIRCLE 和SEA 3 个渐变型数据集上平均检测延迟、误报率和漏报率均最低。这主要得益于DFWM 的双层滑动窗口和基于隶属度的加权机制,使其可以快速处理多种类型的概念漂移,具有较强的鲁棒性。除DFWM 外,FPDD 和SeqDrift 也是基于滑动窗口的算法,但它们均使用一个固定长度的窗口,缺少加权机制,只适用于某一种特定类型概念漂移。由表5~表7 知,FPDD 只适合处理突变型漂移,而SeqDrift 只适合处理渐变型漂移,具有较大的局限性。而DDM、RDDM 和HDDM 三种算法是基于统计过程控制的算法,没有使用滑动窗口,在所有数据集上的检测延迟和误报率均高于DFWM,因此处理突变型漂移和渐变型漂移的能力均弱于DFWM。 Table 2 Comparison of average delay of detection表2 平均检测延迟对比 Table 3 Comparison of false positive rate表3 误报率对比 Table 4 Comparison of false negative rate表4 漏报率对比 Table 5 Comparison of algorithm average delay of detection on synthesized datasets表5 人工数据集上的算法平均检测延迟对比 Table 6 Comparison of algorithm false positive rate on synthesized datasets表6 人工数据集上的算法误报率对比 Table 7 Comparison of algorithm false negative rate on synthesized datasets表7 人工数据集上的算法漏报率对比 检测概念漂移的目的是为了及时发现数据流中概念的变化,调整当前分类模型,提高分类准确率。为进一步验证DFWM 的概念漂移检测机制和重复概念识别机制能否有效提高分类准确率,本文选取了RCD、OAUE 和LearnNSE 三种算法进行对比。在SINE、SEA、Spam 和Electricity 4 个数据集上分别比较它们的分类准确率和运行时间。SINE 和SEA 包含重复概念,Spam 和Electricity 为含有概念漂移真实数据集,但漂移的类型、发生的时间未知。DFWM 和RCD 是基于单分类器的算法,使用skmultiflow 包中的HoeffdingTree做分类器。OAUE 和LearnNSE 为集成算法,根据文献[14-15],OAUE 使用Hoeffding Tree做基分类器,而LearnNSE 使用CART 决策树做基分类器。 表8 给出了各算法在4 个数据集上的分类准确率。4 个算法中,只有DFWM 和RCD 具有重复概念识别机制。可以看出,在SINE 和SEA 两个具有重复概念的数据集上,尽管DFWM 是单分类器算法,但由于可以识别重复概念,直接复用过去已训练好的旧分类器,避免重建分类器,更快地适应新概念,获得了最高准确率。在Spam 上,DFWM 的准确率最高,略高于RCD,而在Electricity 上,OAUE 获得最高的准确率,DFWM 次之。 Table 8 Comparison of classification accuracy表8 分类准确率对比 每个算法的运行时间如表9 所示。在4 个数据集上,RCD 的运行时间最短,本文算法DFWM 略高于RCD。而OAUE 和LearnNSE 是集成算法,运行时间远高于基于单分类器的RCD 和DFWM。特别地,在SINE 和SEA 两个数据集上,LearnNSE 的运行时间显著高于OAUE,而在Spam 和Electricity 上则相反。这主要因为LearnNSE 没有剪枝策略,会保留在所有数据块上训练的分类器。而SINE 和SEA 数据集规模要远大于Spam 和Electricity,因此LearnNSE 在前者上会训练更多的分类器,运行时间更长。 Table 9 Comparison of running time表9 运行时间对比 由图6 可知,SINE 数据集上共发生4 次漂移,分别位于数据流的20%、40%、60%和80%处。在初始阶段,数据流中无概念漂移,所有算法的准确率的变化趋势相似,先上升然后趋于稳定。遭遇概念突变时,所有算法的准确率均出现了不同程度的下降,DFWM 由于可以快速检测到概念漂移,并识别重复概念,及时调整当前分类器,抗漂移能力较强,准确率曲线仅出现了小幅下降,基本保持稳定。而OAUE和RCD 的准确率在漂移处发生了显著下降,然后缓慢上升。LearnNSE 的准确率也基本保持稳定,但整体准确率始终较低。此外,SINE 中含有10%的噪声,表明DFWM 具有一定的抗噪能力。 Fig.6 Comparison of classification accuracy on SINE dataset图6 SINE 数据集上的分类准确率比较 图7 展示了所有算法在Spam 上的准确率变化情况,Spam 为真实数据集,无法确切地知道概念的变化情况,更能反映算法的泛化能力。观察图7 可知,大约在数据流的10%处出现了概念漂移。所有算法的准确率开始不同程度地下降,其中OAUE 下降最严重。RCD 和DFWM 的变化趋势相似,准确率小幅下降后缓慢上升,但DFWM 更为稳定,始终保持最高的准确率,这表明本文算法的抗漂移能力较强,可以很好地适应真实数据环境。 Fig.7 Comparison of classification accuracy on Spam dataset图7 Spam 数据集上的分类准确率比较 通过上述实验,可以得出以下结论:(1)相比同类算法,DFWM 检测漂移具有较低的平均检测延迟、误报率和漏报率,能够快速检测到不同类型的概念漂移。(2)DFWM 的概念漂移检测机制和重复概念识别机制有效提高了分类准确率,尤其在含有重复概念的数据流中,并且在复杂的真实数据环境中也有较强的适应性。(3)如果已知数据流仅包含突变型或渐变型漂移,建议使用单层窗口版本的DFWM_S 或DFWM_L,可以降低一定的内存占用和运行时间。如果数据流包含突变型、渐变型或重复型等多种类型的概念漂移,或者不清楚数据流中的漂移类型,建议使用双层窗口版本的DFWM,它具有更强的性能和鲁棒性。 本文提出了一种新的可以适于多类型概念漂移的数据流分类算法(DFWM)。针对当前主动检测型数据流分类算法存在较高的检测延迟和误报率,无法有效处理不同类型漂移等问题,DFWM 在传统滑动窗口的基础上引入了双层窗口,结合隶属度函数和McDiarmid 界,通过分析当前窗口内数据错误率是否发生显著性变化,可以快速检测到数据流中不同类型的概念漂移。而针对当前数据流分类算法无法有效利用历史信息处理重复概念的问题,DFWM 通过SPLL 判断当前概念是否为历史概念的重现,只有检测到新概念时才重新构建新分类器,否则直接复用旧分类器,有效减少了重复构建分类器的开销,更快地适应当前概念。人工和真实数据集上的实验结果表明,与以往同类算法相比,DFWM 在平均检测延迟、误报率、分类准确率和运行时间上都具有一定优势。 本文只考虑了类别平衡数据流中的概念漂移问题,而数据流中的类别不平衡问题会进一步增加处理概念漂移的难度,下一步将考虑如何处理不平衡数据流中的概念漂移问题,以便模拟更多的实际情况。



2.2 漂移检测阈值计算
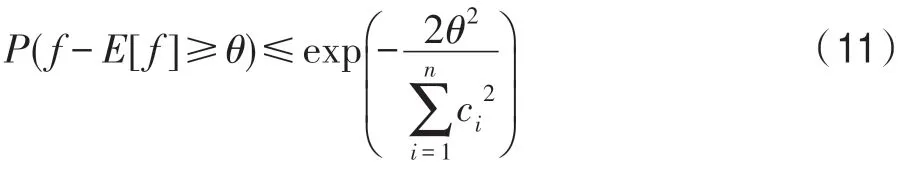



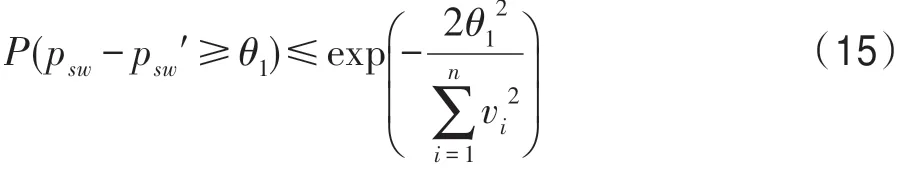

2.3 重复概念的识别

3 实验与结果分析
3.1 实验设置
3.2 数据集介绍
3.3 算法性能评价指标
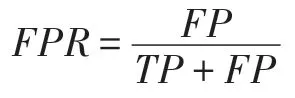
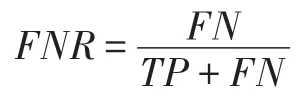
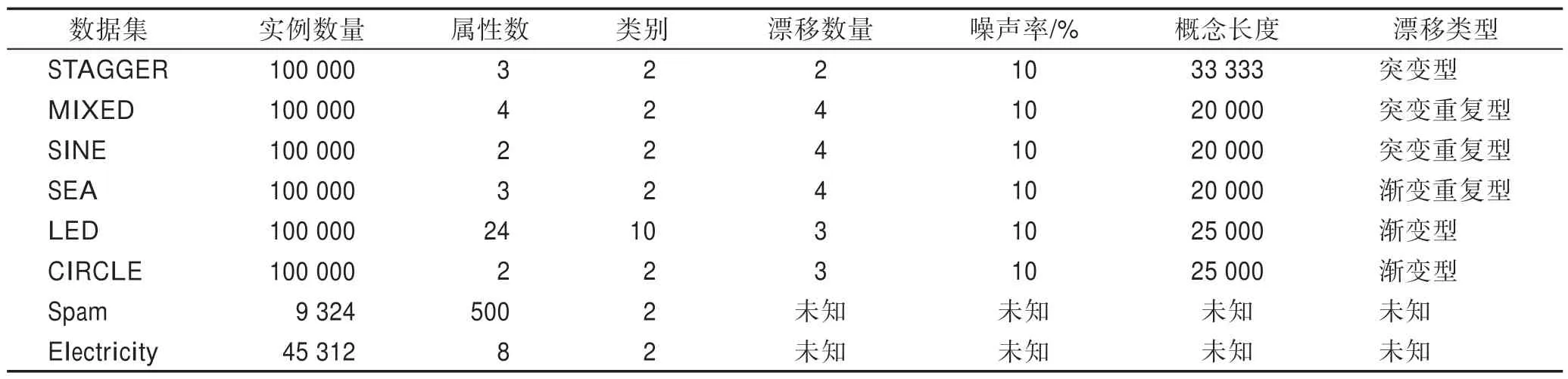
3.4 双层窗口的有效性
3.5 概念漂移检测



3.6 分类准确率和运行时间
4 结束语
