基于机器学习的缺血性卒中功能预后预测模型研究
2021-10-11上官艺王孟王春娟谷鸿秋赵性泉王伊龙王拥军李子孝
上官艺,王孟,王春娟,谷鸿秋,赵性泉,,3,王伊龙,,王拥军,,3,李子孝,,3,4
卒中是我国居民最主要的致死和致残性疾病之一[1]。缺血性卒中是卒中最常见的亚型,15%~30%的患者会遗留不同程度的神经功能残疾[2-3]。建立预测功能预后的风险模型能够帮助临床医师预测和筛选出卒中后神经功能预后不良高风险的患者,制订更有针对性的治疗方案。现有预测模型如休斯敦动脉内血管再通治疗评分[4]、匹兹堡血管内治疗反应评分[5],以及其他结合实验室检查及影像学的评分等[6-8],已逐步应用于临床实践。
机器学习可以对多维医学数据进行深度挖掘和分析,目前在医学诊断、预测预后等方面已经有了广泛的应用[9-10],但采用机器学习对于缺血性卒中患者的功能预后进行预测建模的研究尚少见,本研究采用logistic回归和基于机器学习的CatBoost、XGBoost、LightGBM三种算法,建立缺血性卒中患者3个月神经功能预后预测模型,并评价和比较模型的预测价值。
1 对象与方法
1.1 研究对象 本研究基于中国国家卒中登记Ⅱ(China National Stoke Registry Ⅱ,CNSRⅡ)研究数据库,以2012年5月-2013年1月登记发病7 d内的急性缺血性卒中住院患者为研究对象。CNSRⅡ数据库覆盖我国219家医院。
纳入标准:①年龄>18岁;②根据世界卫生组织诊断标准诊断为缺血性卒中,且经头颅CT或MRI确诊[11];③发病在7 d内;④住院治疗;⑤患者或法定代表人同意参与研究并签署知情同意。排除标准:①临床信息不完整;②发病3个月内死亡。
1.2 变量采集及标准
1.2.1 预测变量 使用病例报告表收集患者的人口学信息(年龄、性别)、吸烟、饮酒、受教育程度(小学及以下、初中、高中)、既往病史(高血压、糖尿病、脂代谢紊乱、脑血管病、周围动脉病、心肌梗死、颈动脉狭窄、心力衰竭、心房颤动)、合并肺炎、入院时NIHSS评分、发病前mRS评分、入院时实验室检查结果(LDL-C、空腹血糖、血清肌酐、白细胞计数)。数据的完整性、准确性由独立的数据监察员进行审核。
1.2.2 结局变量 采用中心化电话随访的方法,使用mRS评估发病3个月时患者的功能预后,随访由经过统一培训的中心化随访员进行。将患者按照预后良好(mRS 0~2分)和预后不良(mRS>2分)分为两组。
1.3 预测模型建立方法 将纳入的研究对象按8∶2随机分为训练集和测试集,利用训练集数据建立预测模型。传统预测模型采用非条件logistic回归的方法,将单因素logistic回归中P<0.1的预测因素纳入多因素分析,使用逐步回归法建立预测模型。机器学习采用Boruta算法筛选特征,流程如下:①对特征矩阵的各个特征取值进行随机打乱,将随机打乱后的特征与原特征拼接构成新的特征矩阵;②使用新特征矩阵作为输入,训练可以输出特征重要性的模型;③计算新特征与原特征的Z值;④在新特征中找出最大Z值记为Zmax;⑤Z值大于Zmax的原特征标记为重要,小于Zmax的原特征标记为不重要,并从特征集合中永久剔除小于Zmax的原特征;⑥删除所有打乱后的特征;⑦重复上述过程,直到所有特征都被标记为重要或者不重要[12]。使用Boruta算法选出的变量,采用CatBoost、XGBoost、LightGBM三种机器学习的方法分别建立预测模型。在测试集内对各个预测模型的预测性能进行内部验证。
2 结果
2.1 基线信息 本研究共纳入19 604例急性缺血性卒中患者,排除mRS缺失2251例,血液指标缺失2468例,共14 885例纳入研究,平均年龄64.34±11.71岁,其中男性占63.96%(9521/14 885)。将患者随机分为训练集11 908例和测试集2977例,两组功能预后不良率分别为17.36%(2067/11 908)和17.06%(508/2977),差异无统计学意义(χ2=0.1438,P=0.7045)。
训练集中预后不良组的既往高血压、糖尿病、脑血管病、心力衰竭、心房颤动病史及合并肺炎的比例,年龄、入院时NIHSS、发病前mRS>2分的比例均高于预后良好组,入院检查中的LDL-C、空腹血糖、白细胞计数水平高于预后良好组,男性、吸烟史、饮酒史的比例低于预后良好组,差异有统计学意义。另外,两组受教育程度分布差异也有统计学意义(表1)。
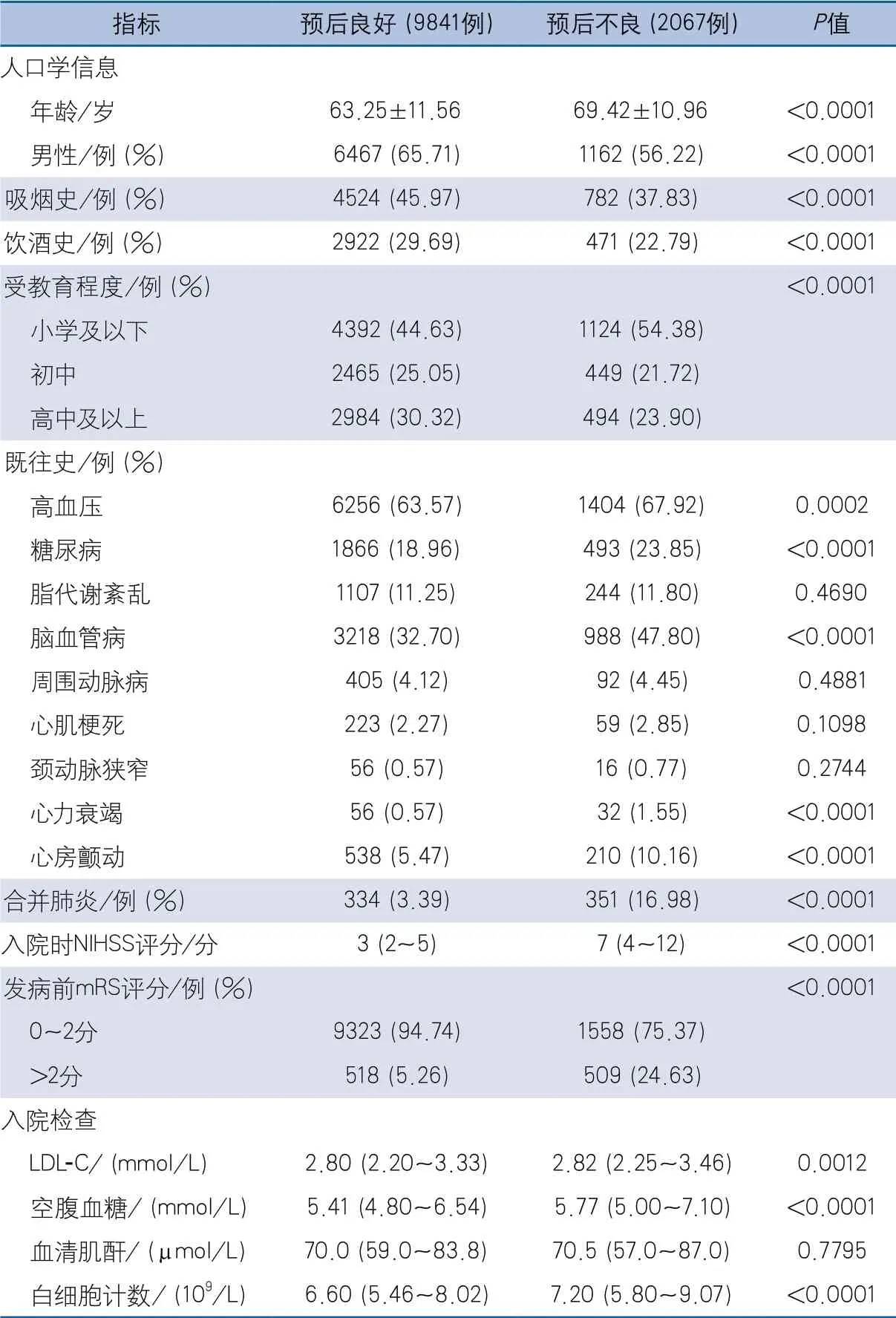
表1 训练集中发病3个月功能预后良好和预后不良患者的基线特征
2.2 logistic回归分析结果 多因素logistic回归结果显示,年龄、男性、糖尿病病史、脑血管病史、合并肺炎、入院时NIHSS评分、发病前mRS、LDL-C、空腹血糖和白细胞计数可作为预测模型的预测因子(表2)。
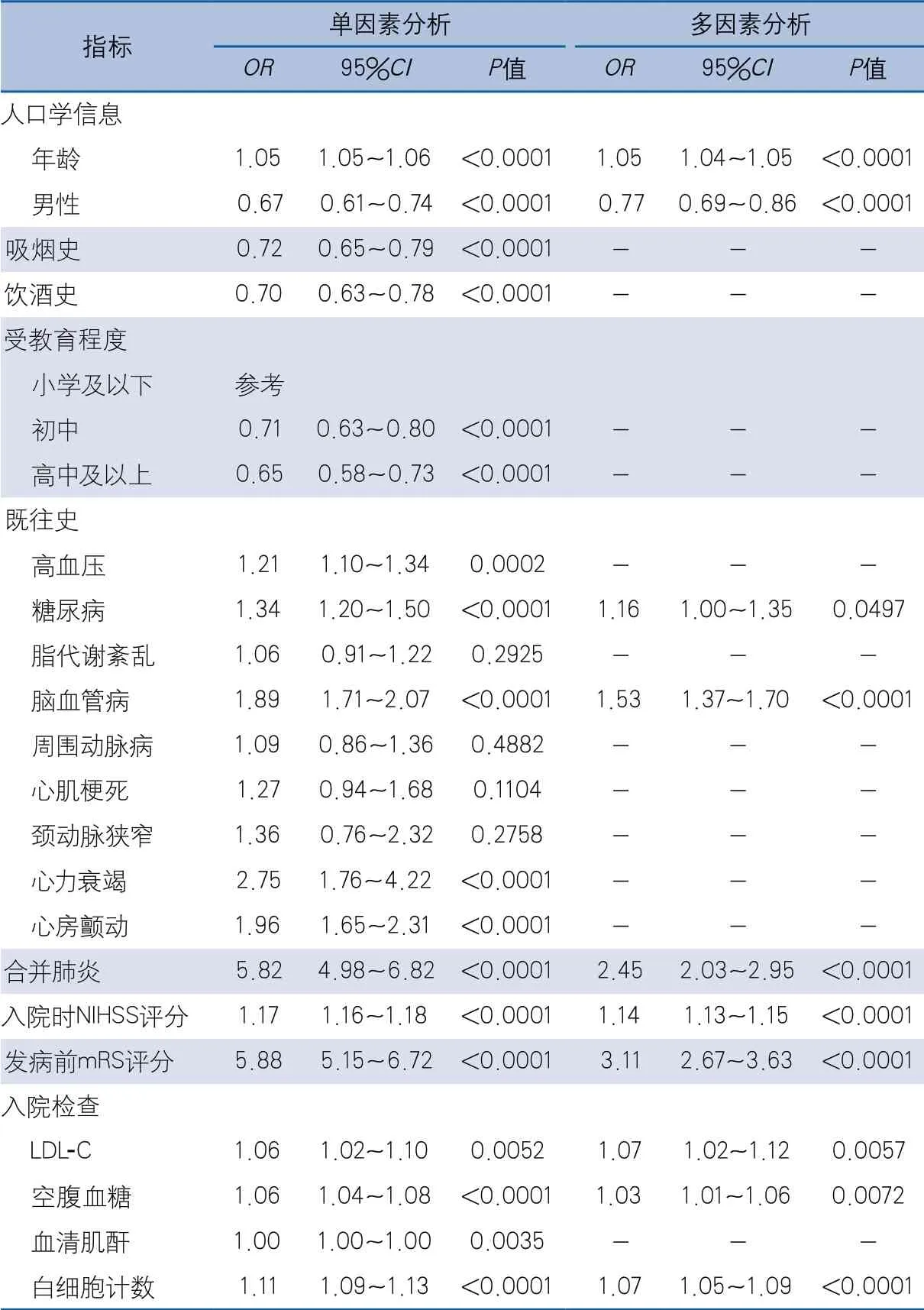
表2 单因素与多因素logistic回归分析结果
2.3 logistic回归和机器学习预测模型的比较Boruta算法选出的3个月预后不良的预测变量包括年龄、性别、受教育程度、脑血管病史、是否合并肺炎、入院NIHSS评分、脑血管病史、LDL-C、空腹血糖、血清肌酐、白细胞计数。在测试集中,CatBoost模型的灵敏度最高,XGBoost的特异度最高;logistic回归、CatBoost、XGBoost、LightGBM预测模型预测缺血性卒中功能预后的AUC分别为0.815(0.801~0.829)、0.828(0.814~0.841)、0.826(0.812~0.839)和0.822(0.808~0.836)。CatBoost(P=0.0023)和XGBoost(P=0.0182)建立的预测模型预测效果优于传统logistic回归模型。具体灵敏度、特异度和AUC数据见图1、表3。

表3 logistic回归、CatBoost、XGBoost、LightGBM四种模型预测性能比较
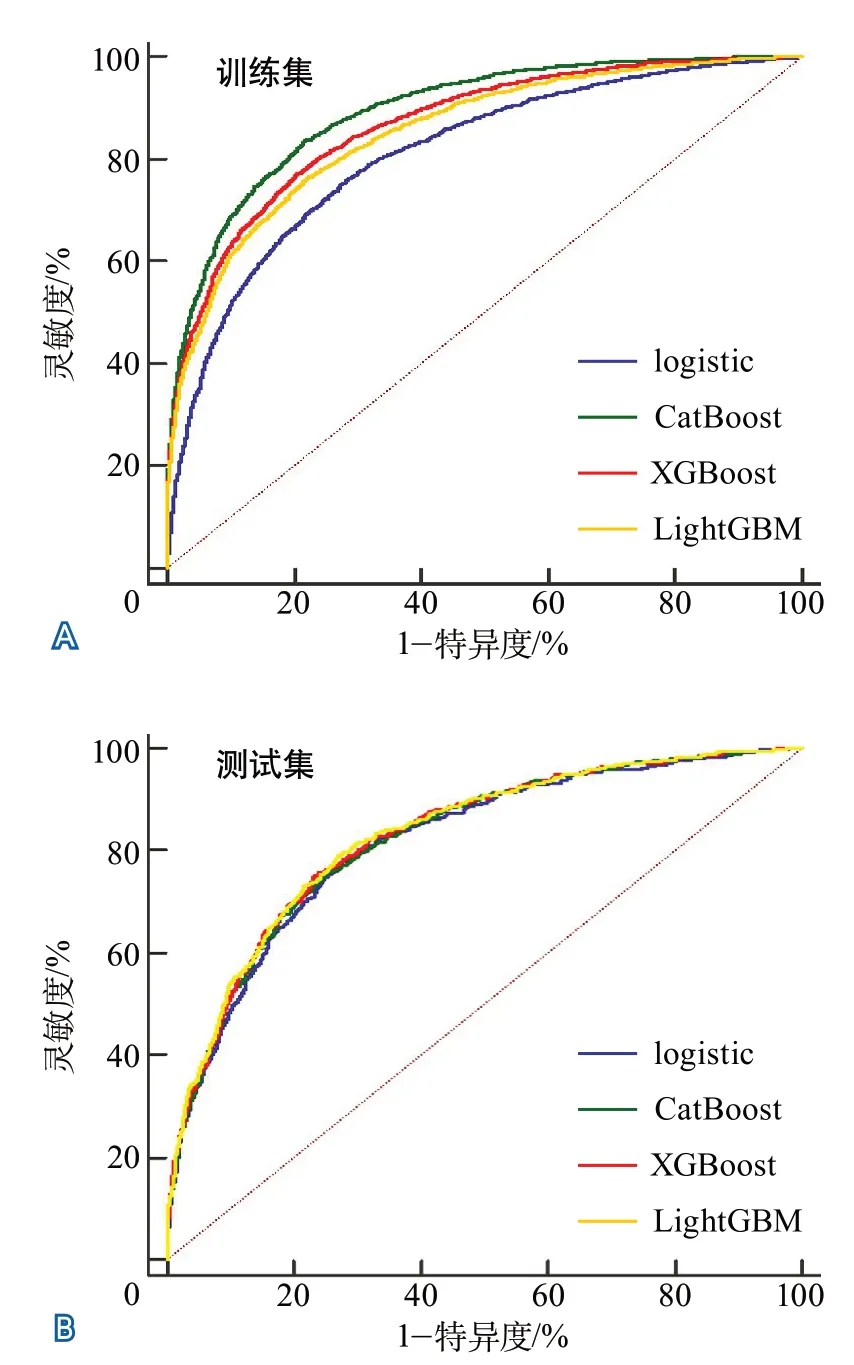
图1 logistic回归、CatBoost、XGBoost、LightGBM四种模型预测性能比较
3 讨论
本研究基于机器学习的方法建立了急性缺血性卒中患者3个月神经功能预后的预测模型,并与传统logistic回归建立的预测模型进行比较。结果提示,CatBoost和XGBoost建立的预测模型对缺血性卒中患者功能预后的预测效果优于传统logistic回归模型。
常用的缺血性卒中预后预测模型包括Counsell等[13]建立的模型及Ntaios等[14]建立的洛桑急性卒中登记分析(acute stroke registry and analysis of Lausanne,ASTRAL)评分等。Counsell等采用多因素logistic回归的方法,筛选出了包括年龄、独居、发病前日常生活不需要帮助、GCS评分的语言部分、上肢力量以及行走能力6个关键预测变量,在其选取的测试集中预测预后的AUC可达0.84~0.88。不过Counsell等建立的预测模型使用牛津残障评分来定义终点结局,临床已较少使用该评分,因此预测模型不能得到广泛推广。ASTRAL评分同样也使用多因素logistic回归的方法筛选出年龄、入院NIHSS评分、卒中发病至入院时间、视野、快速血糖和意识水平6个变量作为预测预后的变量并对各变量分级赋分。ASTRAL评分在两个外部验证集及它们的集合中预测功能预后的AUC为0.937、0.771和0.902(合并时)。该研究的不足之处在于其对血糖范围的定义与我国不同,不能直接应用于我国卒中患者,另外,预测变量中视野缺损为查体获取的信息,当患者病情严重至意识水平较差时难以配合,可造成部分重症患者被排除。本研究使用mRS作为患者功能结局的评价指标,除纳入年龄、NIHSS评分、既往史等常用指标,还纳入血液检查指标,如白细胞计数、LDL-C等,参与预测模型的构建,一方面用目前临床普遍应用的mRS作为预后指标,利于预测模型在临床中的推广,另一方面汇总了临床常用且简便的检查项目,可以使预测模型尽可能地适用于临床。
本研究采用了多种机器学习的方法,对非线性的数据拟合程度更好。在机器学习的应用中特征选择是一个重要的问题。通常在模型构建的过程中,数据集的数量会很庞大,但是大多数变量与目标问题无关,将所有变量纳入模型进行的方法有以下不足:首先,处理大型的数据集时,运行速度会很慢,占用过多的资源;其次,当变量数过多时,机器学习方法的准确性会显著下降[15]。因此,在解决实际问题时,迫切需要找到变量数量少、分类结果好的特征集。Boruta算法并不针对某种特定的模型,而是首先筛选出所有与因变量具有相关性的特征集合。Boruta基于随机森林分类器的相同思想,即在系统中加入随机性,从随机样本集合中收集结果,减少了随机波动和相关性的误导影响[12]。
目前采用机器学习预测缺血性卒中结局的方法已开始在临床应用。有研究者采用包括随机森林、分类和回归树、C5.0决策树、支持向量、机器、自适应提升机、最小绝对收缩和选择算子逻辑回归在内的模型预测发病3个月缺血性卒中患者的功能预后,证明机器学习算法和logistic回归预测患者功能预后具有一定的准确性(AUC 0.66~0.71)[16];Monteiro等[17]也做了类似的研究,对比了传统logistic回归、决策树以及随机森林、XGBoost的预测效果,结果显示,机器学习可以将预测3个月mRS的AUC提高至0.808,但该研究的不足之处在于样本量较少(541例患者),同时未纳入实验室指标,因此预测效果还有待提高。本研究使用Boruta算法,从既往研究提示可影响急性缺血性卒中患者功能预后的危险因素中,选出10种相关因素,选用三种机器学习方法建立的预测模型,结果显示,CatBoost、XGBoost和LightGBM的预测AUC分别为0.828、0.826和0.822,其中CatBoost和XGBoost预测效果优于传统logistic回归,LightGBM未显著提高模型预测效果。
本研究纳入的样本量大,对我国缺血性卒中人群的代表性较好;使用并对比了三种机器学习模型的优缺点,对于非线性数据拟合程度较传统logistic回归分析更高;纳入了实验室指标,特异度高的危险因素可以提高预测模型的准确性。但是本研究也存在一定的局限性:一方面,研究未将影像学指标纳入预测模型,可能导致预测模型的特异度下降;另一方面,尽管CNSR Ⅱ为全国性的多中心队列,在我国卒中人群中有良好的代表性,但本研究的预测模型仍需要进一步在独立的外部人群中进行验证。
致谢:感谢严麦童(北京安德医智科技有限公司)在机器学习算法方法学方面提供的帮助和指导。
【点睛】本研究通过涵盖219家中心的CNSRⅡ数据库的大样本数据,检验了传统多因素logistic回归分析方法和基于机器学习建立的缺血性卒中3个月预后模型的预测效能,结果提示通过CatBoost和XGBoost方法建立的预测模型预测效果优于传统logistic回归模型。
