基于线性分位数组合的兴安落叶松冠幅预测
2021-10-10王君杰姜立春
王君杰, 姜立春
(东北林业大学林学院,森林生态系统可持续经营教育部重点实验室, 黑龙江 哈尔滨 150040)
树冠大小作为树木的基本属性,与树冠表面积和体积呈显著正相关,影响树木的光合和呼吸作用[1-2],进而影响树木活力[3]、林木竞争[4]、林分健康[5]及生物圈中的碳循环[6],是预测森林动态的重要指标[7]。冠幅(crown width)是判断树冠大小的主要指标,常作为重要变量引入生物量模型[8]、削度方程[9]和树干材积[10]等单木模型中,此外冠幅大小影响林冠的光截获量[11],从而影响林下的生物多样性和野生动植物分布[12]。冠幅用途广泛,但测量费时费力,因此林业上经常采用相关模型对冠幅进行预测[2]。冠幅大小受立地条件、林分密度和林分中各种随机因素的影响[13],通常将胸径和其他单木或林分变量引入到基础冠幅模型中,以降低模型预测误差[1-2,7,12-13]。
单木冠幅数据通常来自样地的每木检尺或重复测量,常呈层次嵌套结构[14],这导致构建冠幅模型时存在异方差和自相关等问题。虽然可以通过加权回归和引入自相关函数来矫正这些问题,但会增加模型的拟合难度,有时矫正效果并不理想。分位数回归(quantile regression)[15]对数据以及模型误差项的假设条件比较宽松,保证了参数估计的稳健性和可靠性,同时也可以评估不同分位数对响应变量的影响[16-17]。近年来,分位数回归在林业中得到一定的应用,但这些大多都是研究自变量对因变量在某个特定分位数水平上影响的边际效应或平均效果,如模拟自稀疏边界线[16]、直径分布[17]、树高曲线[18]、潜在最大冠幅[19]、削度方程[20]等。虽然一些学者使用不同分位数组合对胸径生长[21]和削度方程[22-23]进行预测,但由于方法的限制,都只探讨了一个抽样数量对模型预测精度的影响。虽然Özçelik等[24]提出使用多个抽样数据和分位数组合对树高曲线进行预测,但没有深入研究不同抽取方案 (随机抽样、选取最大树、平均木和最小树)对预测结果的影响。
兴安落叶松(Larixgmelinii)是大兴安岭地区的主要树种,林木蓄积丰富,被广泛用于木材生产和造林,同时在区域碳储存和碳循环中起着重要的作用。因此常常需要利用模型对兴安落叶松的冠幅进行准确预测。目前综合应用分位数组合和不同抽取方案对兴安落叶松冠幅模型的研究还未见报道。因此,本研究使用传统方法构建大兴安岭落叶松基础和多元冠幅模型,评估影响冠幅变化的主要因素;利用分位数回归和分位数组合对基础和多元模型进行拟合和预测,对比三分位数、五分位数、七分位数和九分位数组合的预测能力,评价传统回归、分位数回归和分位数组合的预测效果;评估模型实际应用时的抽取方案,以期为野外实际应用提供指导。
1 材料与方法
1.1 研究地概况
研究地点位于黑龙江省大兴安岭新林区(123°41′~125°25′E,51°20′~52°10′N)。新林区地处大兴安岭山脉东坡,伊勒呼里山北坡。气候寒冷湿润,气温年较差和日较差较大,年平均气温为-2.6 ℃。降水多集中于7—8月,年降水量为513.9 mm。8月下旬开始出现初霜,无霜期平均为90 d左右。风速较小,年平均风速一般为2~3 m/s。新林区水系为外流流域,河谷密集,年平均秒流量20.95 m3/s。植被属于寒温带针叶林区的大兴安岭山地寒温针叶林带,森林覆盖率达84%,但植物种类相对贫乏。主要乔木树种有兴安落叶松(Larixgmelinii)、樟子松(Pinussylvestrisvar.mongouca)、白桦(Betulaplatyphylla)、山杨(Populusdavidiana)等。
1.2 数据来源及统计
研究用数据为2012年和2017年调查的65块落叶松天然林样地(各样地落叶松断面积比例≥65%)的3 452株落叶松。样地涵盖广泛的林分结构和立地条件,面积大小取决于林分密度,范围为0.02~0.10 hm2。实测每个样地胸径大于5 cm的所有树木的胸径(DBH,记为DBH)、树高(HT)、枝下高(HCB),并记录每株树的相对位置。测量东、南、西、北4个方向的最大树冠半径,得到东西、南北两个方向的树冠宽度,冠幅(CW,记为WC)计算为两个方向树冠宽度的算术平均值[1]。除上述变量,还计算了每株树的冠长率(RC)、高径比(RHD)、样地平均树高(Hmean,m)、优势木平均高(HDOM,m)、优势木平均胸径(DDOM,cm)、每公顷断面积(AB,m2/hm2)、每公顷株数(N,株/hm2)、相对间距指数(SR)、样地内所有大于对象木胸径的立木断面积总和(BAL,m2)、样地内落叶松断面积(Glarch,m2)。所有单木及林分变量统计信息见表1。
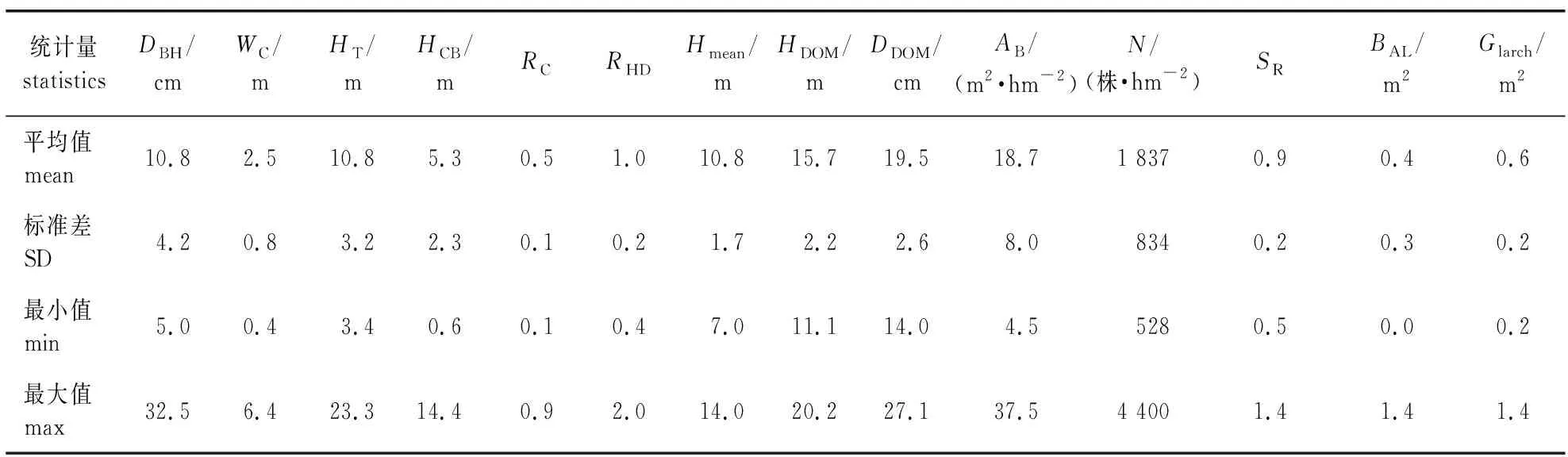
表1 落叶松天然林各样木调查因子数据Table 1 Deseriptive statistics for Larix gmelinii sample trees
1.3 基础冠幅模型选择
根据兴安落叶松冠幅和胸径的关系,即冠幅随胸径的增大而增大,本研究选用了6个生长模型:线性、逻辑斯蒂(Logistic)、幂函数、理查德(Richards)和威布尔(Weibull)函数来模拟落叶松冠幅和胸径的关系。具体模型形式见表2。

表2 候选冠幅基础模型Table 2 Candidate basic crown width models
1.4 多元冠幅模型构建
选用胸径作为唯一预测因子的基础冠幅模型不能反映其他单木因子和林分变量对冠幅的影响[1],因此本研究考虑引入其他影响冠幅的因子,如树木大小、立地条件和林分竞争等变量[2,7,13-14]。基于最优基础冠幅模型构建含有其他变量的多元冠幅模型,采用多元逐步回归技术,同时考虑冠幅与其他自变量的相关关系,筛选模型中的其他自变量,包括表1中提到的变量及变量的变形形式,如对数转换和开方等,同时考虑多变量的多重共线性,剔除方差膨胀因子(VIF)大于5的自变量[25]。
1.5 分位数回归
分位数回归可以对数据的任意分位点进行响应变量的估计。第τ个分位点的参数估计可以通过最小化残差绝对值的非对称损失函数来估计[16]。如式(1)所示:
(1)

1.6 分位数组合应用方法
本研究主要是应用分位数组合对冠幅模型进行预测,测试了7种分位数组合:三分位数组合 (τ=0.1, 0.5, 0.9和τ=0.3, 0.5, 0.7)、五分位数组合 (τ=0.1, 0.3, 0.5, 0.7, 0.9和τ=0.3, 0.4, 0.5, 0.6, 0.7)、七分位数组合(τ=0.1, 0.2, 0.3, 0.5, 0.7, 0.8, 0.9和τ=0.1, 0.3, 0.4, 0.5, 0.6, 0.7, 0.9)、九分位数组合(τ=0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9)[21,26]。

(2)


1.7 分位数组合抽取方案
应用分位数组合时需要使用抽样树木的数据对模型进行样地局部化校准,从而预测未抽样树木的冠幅。采用以下4种抽取方案得到抽样数据:① 每个样地随机抽取1~9株树。为了得到可靠的结果,此过程重复100次,然后计算平均值。② 选取每个样地胸径最大的1~9株树。③ 选取每个样地与该样地平均胸径最接近的1~9株树。④ 选取每个样地胸径最小的1~9株树。
1.8 模型评价和检验指标
本研究使用K折交叉验证(K-fold cross validation,K=5)对模型进行检验[27],将数据随机分为5组,每组包含13块样地。使用4组数据估计模型参数,对剩余1组数据预测,该过程重复5次,计算各模型评价指标。使用平均误差[ME,式中记为σ(ME)]、均方根误差[RMSE,式中记为σ(RMSE)]、和决定系数(R2)选择最优基础模型。使用平均绝对误差[MAE,记为σ(MAE)]和均方根误差对各模型拟合优度进行评价。使用平均百分比误差[MPE,式中记为σ(MPE)]、平均绝对百分比误差[MAPE,式中记为σ(MAPE)]、均方根误差和决定系数(R2)对模型K折交叉验证结果进行评价。各评价指标相应的数学表达式为:
(3)
(4)
R2=1-
(5)
(6)
(7)

(8)
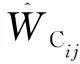
使用R软件的lm过程拟合基础和多元冠幅模型,用quantreg包拟合线性分位数回归(τ=0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9),使用SAS的Proc NLP过程计算组合分位数的插值系数。
2 结果与分析
2.1 基础、多元和分位数冠幅模型确定
利用R软件的lm和nls过程分别拟合候选基础模型的线性和非线性形式,拟合结果见表3。

表3 候选冠幅基础模型拟合统计量Table 3 Fitting statistics with candidate basic crown width models
由表3可以看出,6个模型评价指标都很相近。线性模型参数估计稳定,不受初始值影响,且通常可以很好地拟合冠幅[7,25],因此选择线性模型作为最优基础冠幅模型。模型形式如下:
WCij=β0+β1DBHij+εij。
(9)
式中:WCij、DBHij分别为第i个样地第j株树的冠幅和胸径,β0、β1为模型参数,εij为模型误差项。
基于最优基础冠幅模型,采用逐步回归技术构建多元冠幅模型,最终确定模型包括的变量为:单木枝下高HCB(树木大小)、样地平均高Hmean(立地质量)和样地内落叶松断面积Glarch(竞争)。具体模型形式如下:
WCij=β0+β1DBHij+β2HCBij+β3Hmeani+β4Glarch,i+εij。
(10)
式中:HCBij为第i个样地第j株树的枝下高;Hmeani和Glarch,i分别为第i个样地的平均高和落叶松断面积;β0、β1、β2、β3、β4为模型参数。
将基础和多元冠幅模型分别表示为分位数回归模型,模型形式如下:
(11)
(12)
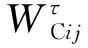
2.2 模型的参数估计
利用R软件的lm过程和quantreg包分别对基础和多元冠幅模型进行线性和分位数回归拟合。线性回归和分位数回归的参数估计值和拟合统计量见表4,所有参数均极显著(P<0.001)。多元冠幅模型(10)的参数β1和β3的估计值为正数,β2和β4的参数估计值为负数,说明冠幅与胸径和样地平均高成正比,与枝下高和落叶松断面积成反比。与基础模型线性回归相比,多元冠幅模型线性回归的MAE和RMSE分别降低6.9%和6.3%。基础和多元分位数模型在不同分位点的参数估计值都显著。分位数回归的高分位点和低分位点的误差MAE和RMSE变化较大,离中位数越远,拟合效果越差。两个中位回归(τ=0.5)拟合效果最好,且评价指标与相应模型的线性回归差异不大,可选为最优分位数回归模型。

表4 线性回归和分位数回归的参数估计和拟合统计量Table 4 Parameter estimation and fitting statistics for linear regression and quantile regression at nine quantiles

表4(续)
为了直观地分析冠幅随胸径的变化,图1绘制了线性回归和基于9个分位点(τ=0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9)的基础冠幅模型和多元冠幅模型的模拟曲线(图1)。可以看出,分位数回归可以提供不同分位点的估计,产生了一簇冠幅预测直线,可以体现整个分布的信息。中位数回归与线性回归预测几乎重合,较其他分位数回归能更好地拟合数据的平均趋势。
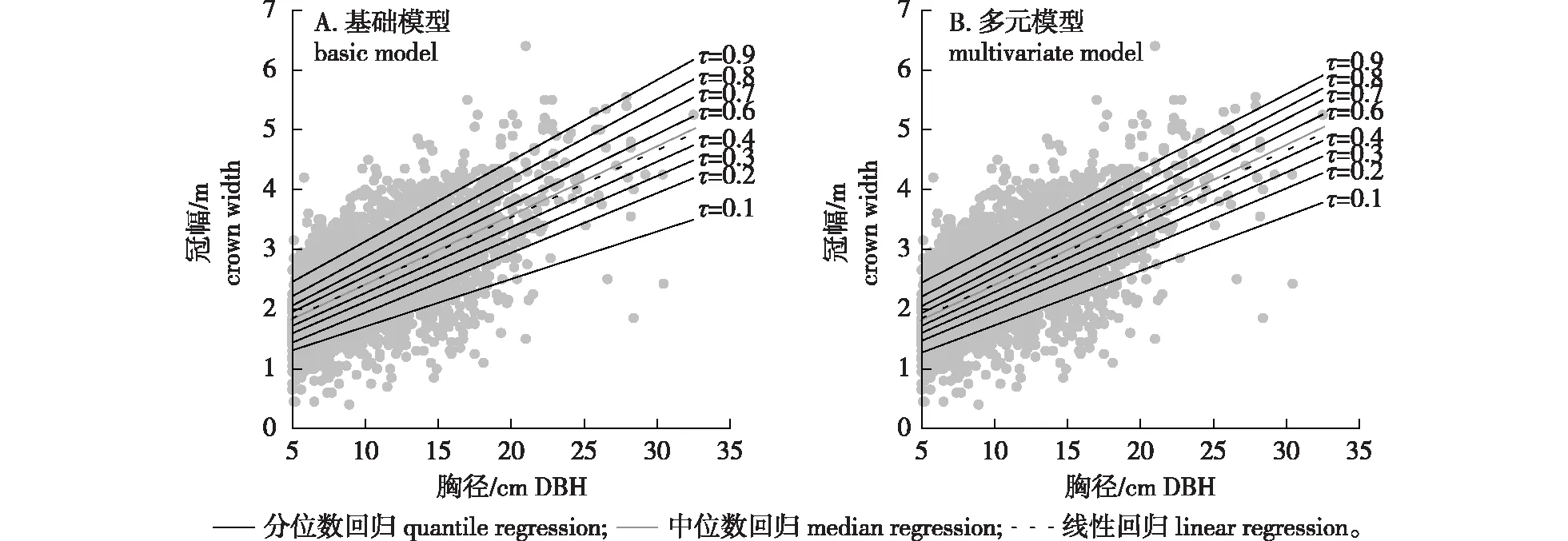
图1 线性回归和基于9个分位点的分位数回归的基础和多元模型的模拟曲线Fig.1 Basic and multivariate model simulation of linear regression and quantile regression based on nine quantiles
2.3 模型比较及组合分位数抽取方案和数量的确定
计算线性和分位数回归各分位数的预测统计量比较简单,就是把参数估计值直接代入相应模型得到预测值,然后计算各模型的统计量。然而,分位数组合的统计量计算需要确定:分位数组合、抽取方式、抽取数量。本研究分别对比了三分位数组合 (τ=0.1, 0.5, 0.9和τ=0.3, 0.5, 0.7)、五分位数组合 (τ=0.1, 0.3, 0.5, 0.7, 0.9和τ=0.3, 0.4, 0.5, 0.6, 0.7)、七分位数组合(τ=0.1, 0.2, 0.3, 0.5, 0.7, 0.8, 0.9和τ=0.1, 0.3, 0.4, 0.5, 0.6, 0.7, 0.9)和九分位数组合(τ=0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9),采用4种抽取方案(随机抽样、选取最大树、平均木、最小树)和9种抽取数量(1~9株)对冠幅进行预测,分位数组合预测误差RMSE见图2。为了比较分位数组合与中位数回归(最优分位数)的预测效果,中位数回归模型预测误差用横线表示。可以看出利用分位数组合和抽样数据对模型进行校准可以提高模型的预测能力,且抽取方案和数量的不同导致分位数组合的预测能力产生明显差异。7种分位数组合方式在相同抽取方案和样本大小下的差异都很小,特别是对于随机抽样和选取平均木。对于选取最大树和最小树,7种分位数组合方式略有差异,大多数情况下,七分位数组合和九分位数组合的RMSE都比三分位数和五分位数组合大。总体上看,三分位数组合的预测能力较好,因此本研究选用三分位数组合(τ=0.1,0.5,0.9和τ=0.3, 0.5, 0.7)对冠幅进行预测。
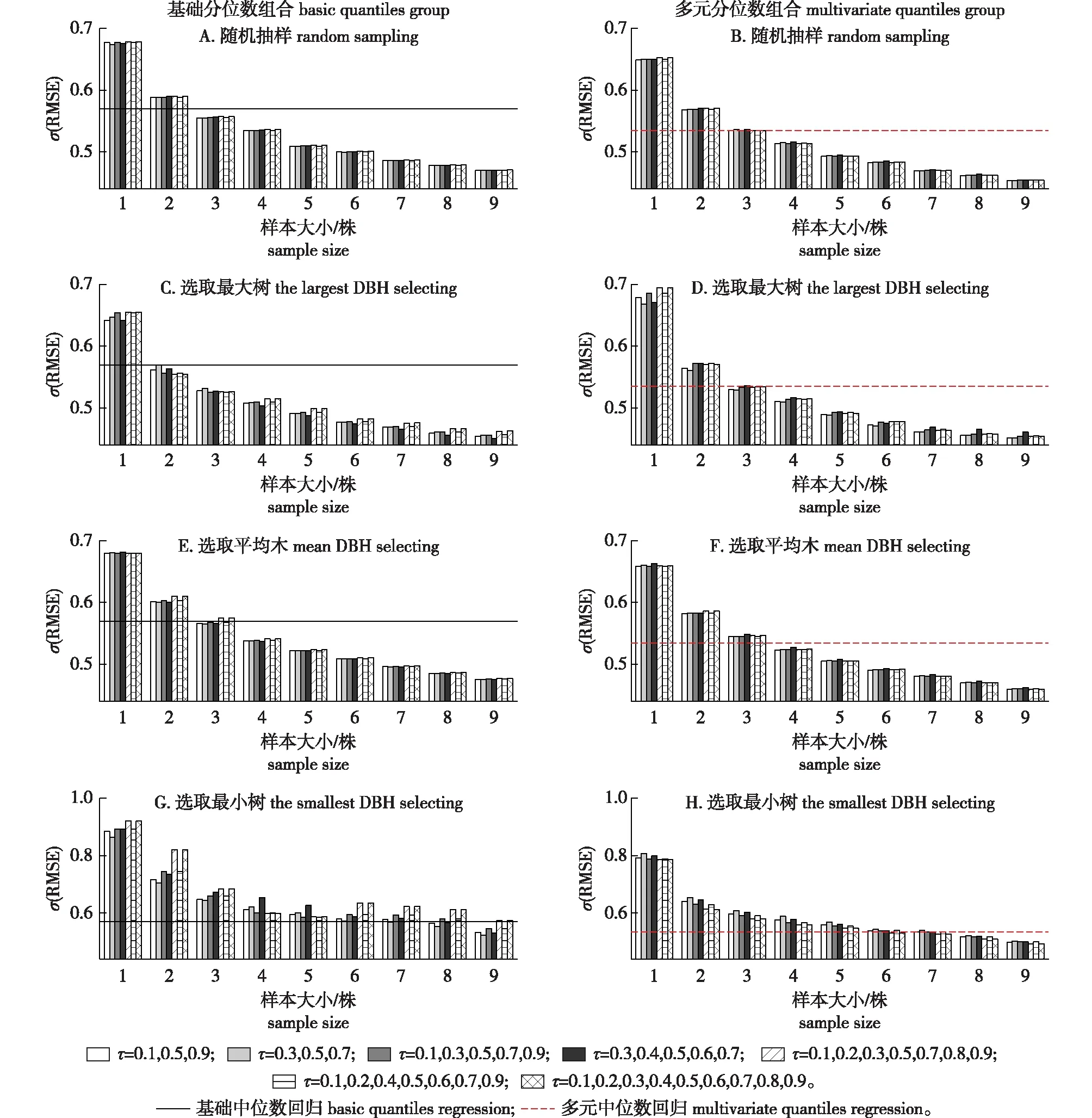
图2 模型预测误差比较Fig.2 Comparison of the prediction errors of the models
随着抽取数量的增加,模型的RMSE越来越小,呈现出先陡后缓的趋势,对于4种抽取方案,选取最小树的预测能力不理想,基础和多元分位数组合的抽样数量分别要超过8株(图2G)和6株(图2H)才能优于中位数回归。从RMSE值来看,其他3种抽取方案的预测能力排序均为:选取最大树>随机抽样>选取平均木。对于基础和多元分位数组合,样本大小分别超过3株和4株时,RMSE即可小于中位数回归。当使用6株最大树进行校准时,与中位数回归相比,基础和多元分位数组合的RMSE分别降低了16.3%和11.6%。虽然选择更多数量的最大树可以进一步降低RMSE,但RMSE的降低速率减缓,且会增加更多采样成本。每个样地测量6株样本可以达到采样成本和预测精度之间的平衡,因此,对于基础和多元分位数组合,建议抽取6株最大树方案。
2.4 模型K折交叉验证评价
分别对基础和多元冠幅模型的线性回归、中位数回归(最优分位数回归)和三分位数组合(τ=0.1, 0.5, 0.9和τ=0.3, 0.5, 0.7)进行K折交叉验证,分位数组合的抽取方案采用选取最大树6株,评价结果见表5。可以看出多元模型的MPE、MAPE、RMSE和R2都优于相应的基础模型。相对于基础模型,多元模型的线性和中位数回归的评价指标有明显改善,多元分位数组合的改善不明显。基础模型中,线性回归与中位数回归的差异不大,2种三分位数组合(τ=0.1, 0.5, 0.9和τ=0.3, 0.5, 0.7)的检验结果相似。多元模型中,中位数回归略优于线性回归,分位数组合τ=0.3, 0.5, 0.7的预测能力略优于τ=0.1, 0.5, 0.9。无论是基础还是多元模型,分位数组合的检验结果都明显优于线性回归和中位数回归,具有更好的预测能力。
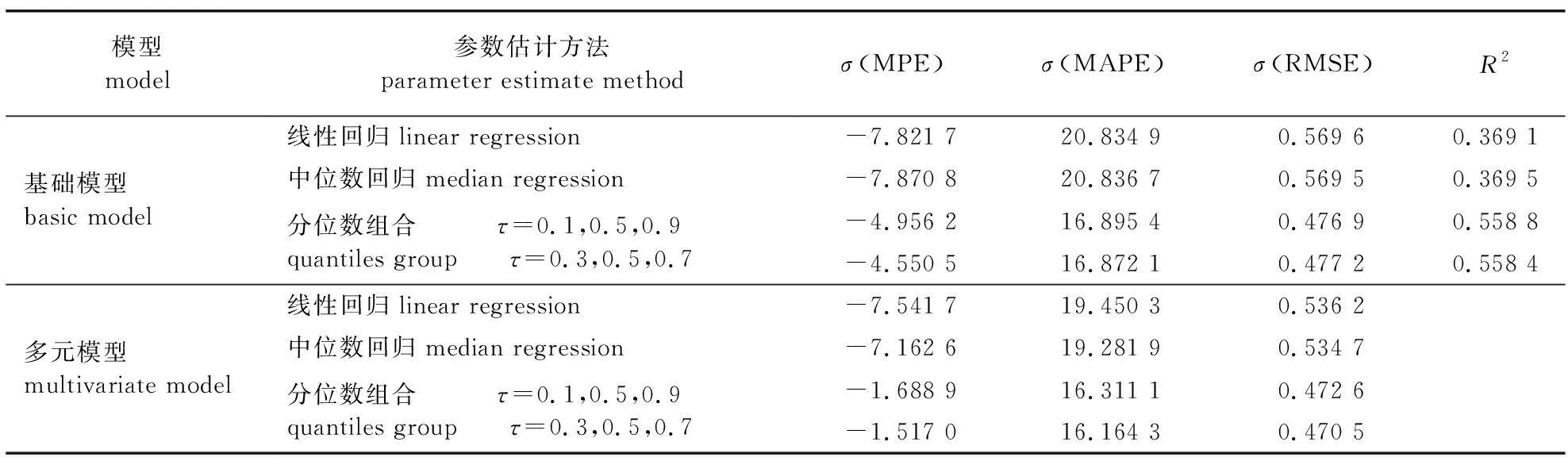
表5 线性回归、中位数回归和三分位数组合的K折交叉验证统计量Table 5 K-fold cross validation statistics of linear regression, median quantile regression and three quantiles groups
3 讨 论
本研究基于大兴安岭东部兴安落叶松天然林数据,构建了基础和多元冠幅模型,并利用线性回归和分位数回归对冠幅模型进行拟合,利用分位数组合对冠幅进行预测,同时考虑不同抽取方案和数量对预测结果的影响。研究表明,线性模型可较好地描述树木冠幅与胸径的关系,这与雷相东等[25]和Bechtold[28]的研究结果一致。加入单木枝下高HCB(树木大小)、样地平均高Hmean(立地质量)和样地内落叶松断面积Glarch(竞争)的多元冠幅模型可以明显提高模型的拟合和预测能力。冠幅随着胸径和样地平均高的增大而增大,随着枝下高和落叶松断面积的增大而减小。Fu等[2]和Sharma等[29-30]分别对杉木(Cunninghamialanceolata)、挪威云杉(Piceaabies)和欧洲山毛榉(Fagussylvatica)的冠幅模型进行研究,得到了类似的结果,即立地质量越好,枝下高和竞争越小,则树木冠幅越大。样地平均高是描述林分立地质量的指标[29],样地平均高越大,林分的生长条件越好,则冠幅越大[2,29-30]。单木枝下高与树冠大小(如冠长率)密切相关,当树冠底部的枝条死亡时,枝下高增大,冠幅变小[2,29-30]。树冠的生长对林分密度非常敏感。样地落叶松断面积是一种与密度相关的竞争指标[5],对于同一林分,落叶松断面积越大,对同一空间资源利用的竞争越大,则冠幅越小[30]。
分位数回归能灵活地反映冠幅的分布,中位数回归与其他分位点相比拟合效果更好[18],且与线性回归基本一致。Bohora等[21]利用分位数组合对胸径生长进行预测时,发现三分位数(τ=0.1, 0.5, 0.9)、五分位数(τ=0.1, 0.3, 0.5, 0.7, 0.9)和九分位数组合都可以提高预测精度,但九分位数组合会导致预测误差增大。Cao等[22]、Özçelik等[23-24]和马岩岩等[26]分别对削度方程和树高曲线进行研究,发现五分位数组合略优于三分位数组合,但都没有考虑抽取方案对分位数组合的影响。本研究将分位数组合形式扩展至7种:三分位数组合 (τ=0.1, 0.5, 0.9和τ=0.3, 0.5, 0.7)、五分位数组合 (τ=0.1, 0.3, 0.5, 0.7, 0.9和τ=0.3, 0.4, 0.5, 0.6, 0.7)、七分位数组合(τ=0.1, 0.2, 0.3, 0.5, 0.7, 0.8, 0.9和τ=0.1, 0.3, 0.4, 0.5, 0.6, 0.7, 0.9)和九分位数组合(τ=0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9),同时考虑不同抽取方案的影响,发现7种分位数组合都可以提高冠幅模型的预测精度,但各分位数组合间的差异会随着抽取方案的不同产生变化。对于选取最大树和最小树产生的抽样数据,7种分位数组合产生较大差异,而对于随机抽样和选取平均木差异不大。总体上,三分位数组合 (τ=0.1, 0.5, 0.9和τ=0.3, 0.5, 0.7)的预测能力较好且稳定,增加分位数组合个数不能使预测结果有实质性的提高。
分位数组合应用时使用1个已知观测的抽样仅适合部分单木模型预测[21-23,26],对于其他单木模型,使用1个观测值反而会增大预测误差[24],本研究对冠幅模型预测的研究也得到相同的结果。Özçelik等[24]利用多个抽样数据和分位数组合对树高曲线进行预测,但没有对抽取方案进行比较。本研究使用4种抽取方案(随机抽样、选取最大树、平均木和最小树)对分位数组合的预测能力进行比较,发现抽取方案的不同会使预测结果产生明显差异。对于4种抽取方案,分位数组合的预测效果都会随着抽样数量的增加而提高,但选取最小树的效果不理想,这可能是因为小树的代表性较差,不能充分反映样地的信息[31]。对于基础和多元分位数组合,选取最大树的预测能力最好。选取最大树的另一个好处是,可以对材积较大的树木进行更精确的校准[32]。在平衡了模型预测精度和抽样成本之后,建议应用分位数组合进行预测时每块样地抽样数量为6株。当无法获得抽样数据时,可以选择线性回归或中位数回归对冠幅进行预测,多元模型的中位数回归略优于线性回归。
