面向XGBoost 的课程评价文本智能分类模型
2021-09-28晋百川杨鸿波胡大胆
晋百川,杨鸿波,胡大胆
(北京信息科技大学自动化学院,北京 100192)
0 引言
互联网的快速发展带动电商与线上教育平台融合,随之而来的是大量的商品评价和课程评价的文本信息。企业关注的是对大量评价文本信息快速处理,精准地将差评分为一类,再根据差评提取出的关键词确定企业问题所在,据此快速改进问题,弥补损失。
文本信息处理研究较多,如文献[1-5]针对KNN 算法提出了一种基于密度的样本选择算法,对文本特征进行处理,取得较好的分类效果;文献[6-8]结合文本相似度和NaveBayes 方法,提出了新的类别区分词特征选择方法;文献[9-11]提出了一种基于LDA 模型的文本分类算法,对传统的特征降维方法进行改进。以上方法对数据集要求很高,对评价日常文本内容表现欠佳。文献[12-16]采用改进的KNN 算法对短文本内容进行分类,但分类效率还有待提高;文献[17-19]使用改进的CNN 网络,在提高文本分类精度方面效果显著,但在文本处理方面还有一定不足。
以上方法均为在评价文本数据方面进行细致分类与分析。本文使用数据可视化分析方法对特征进行重点关联分析,采用jieba 分词和停用词的处理方法对文本数据进行词向量表示,使用PCA(主成分分析)进行特征降维,采用XGBoost 来训练评价文本分类模型,使用交叉验证方法选取模型的最优参数,对评价文本内容进行快速有效分类。
1 数据预处理
数据中存在一定的错误、缺失和一些劣质数据,劣质数据往往会直接导致模型效果不佳,甚至对模型精准率造成很大影响,所以在建模之前需要对数据集进行预处理。
1.1 数据集概况
本文数据集来自某高校课程反馈评价,进行了人工标注和脱敏处理。数据集分为训练集和测试集两组,其中训练集有9 994 条反馈内容,测试集有1 647 条反馈内容,数据示例如图1 所示,特征字段解释说明如表1 所示。特征“反馈评价”的类别有Z(中肯评价)、G(好评)、B(差评)、N(无参考价值的评价)4 种。

Fig.1 Data set example图1 数据集示例

Table 1 Explanation of feature fields表1 特征字段解释说明
1.2 缺失数据统计
首先判断数据是否有重复行,这样做目的是减少一些不必要的训练数据,结果显示本文数据集不存在重复数据;其次查看数据是否存在缺失值,结果显示,特征“文本评价”存在缺失值,但缺失值的数量相比样本数目所占比例很小,最终将所有特征“反馈评价”的缺失值删除,剩余训练集样本数目为9 968。
1.3 数据可视化
对训练集的数据特征进行可视化分析,判断出特征“反馈评论”是最重要的,因此对特征“反馈评论”进行可视化分析,查看该特征在每个分类类别中所占比重,结果如图2 所示。由图2 可以判断数据集存在样本不均衡问题,这样训练后的模型在测试结果上会存在偏差,所以首先需对类别不均衡的数据进行处理。处理方法有两种:①使用过采样方法,增加数量较少类的样本,使正负样本数目均衡;②使用欠采样方法,减少数目较多类的样本,达到类别数目均衡。考虑到数据量可以满足模型训练,所以采用随机欠采样方法处理类别Z(中评)和N(无参考价值的评价),以达到分类数据样本均衡的目的。
1.4 文本类别数据处理
从本数据集可以看出其特征数目为7,特征数目太少容易导致训练的模型过拟合,采用对特征“学科编号”和“校区编号”进行One-hot 编码来增加特征数目。One-hot编码又称一位有效编码,其方法是使用N 位状态寄存器对N 个状态进行编码,每个状态都有独立的寄存器位,并且在任意时候其中只有一位有效。One-hot 编码有两个好处:①解决了分类器不好处理属性数据的问题;②在一定程度上起到了扩充特征的作用。
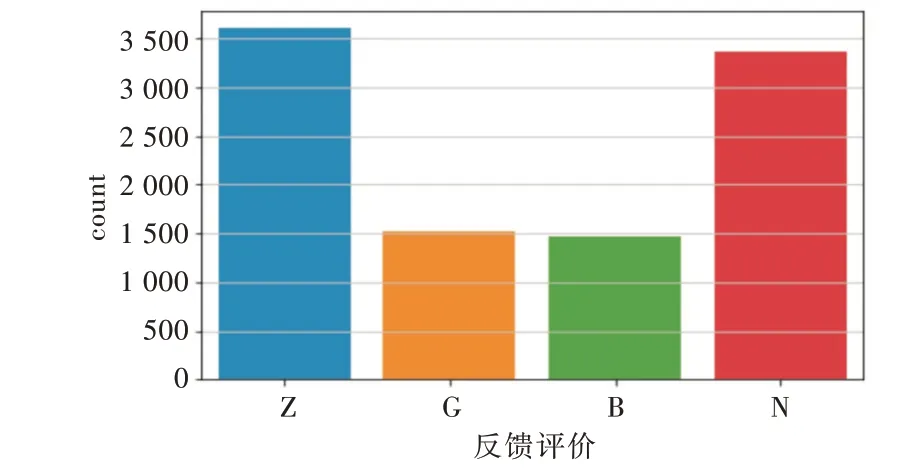
Fig.2 Proportion of important features in each category图2 重要特征在每个类别中所占比重
文本评价是所有特征中最重要同时也是最难处理的特征,处理方法直接影响到最终测试结果,考虑到文本评价都是文本信息,所以首先导入jieba 分词模块,使用现有的jieba 分词对该特征文本信息进行拆分成为独立的词,将这些词与现有的停用词结合。分词过程中对文本内容存在的多余空格、空行、回车等符号进行自动去除,然后使用sklearn 下面的文本特征提取函数CountVectorizer 将文本中的词语转换为词频矩阵,计算词语出现的个数。此时文本信息处理完毕,样本如图3 所示,特征数目为9 345。处理后的数据进行归一化,这样做的好处是可以提升模型的收敛速度和精度。
Fig.3 Processed text data graph图3 处理后的文本数据
2 特征提取
将特征“反馈评价”作为目标值,其他作为特征值,对特征值进行处理。由于特征值维度过大,达到9 384,这样不仅训练时效率低下还容易导致维灾难,所以对特征值进行降维处理。现有的降维方法很多且相对成熟稳定,采用PCA(主成分分析)进行特征降维。PCA 是降维最经典的方法,它旨在找到数据中的主成分并利用这些主成分来表征原始数据,从而达到降维目的,本实验将n_components 设置为0.9,最终将特征维度降至1 179。
3 XGBoost 算法模型
使用机器学习分类算法训练文本特征分类器,使用预先处理好的数据集进行逆行训练,最终得到训练好的分类模型。
XGBoost 算法是在GBDT 算法上改进而来的。与GB⁃DT 相比,XGBoost 对损失函数利用二阶泰勒展开式增加正则项寻求最优解,避免过拟合。对于XGBoost 的课程评价分类模型表示为:

其中,K 为树的总个数,fk表示第k 颗树表示样本xi的预测结果。XGBoost 的目标函数为:

其中,yi代表真实值代表模型的预测值,Ω(fk)为模型的复杂度,可以保证模型在训练过程中控制复杂度,避免过拟合。

XGBoost 在优化过程中采用增量训练方法来保证每一次训练原来的模型不变。加入一个新的函数f到模型中,如式(4)所示:
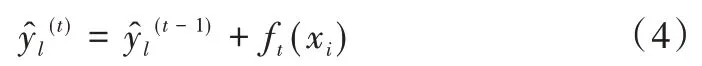
加入f目的是使目标函数尽量减小。因为本文的目标是最小化obj(t)时得到模型f(x),但是obj(t)中并没有参数f(x),所以将目标函数更新为:
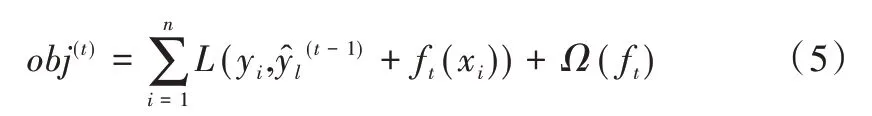
目标函数的泰勒展开式定义为:

从式(6)可以看出,最终的目标函数依赖每个数据点在误差函数上的一阶和二阶导数。利用式(6)对目标函数再次改写成:
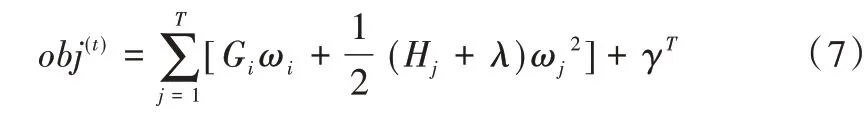
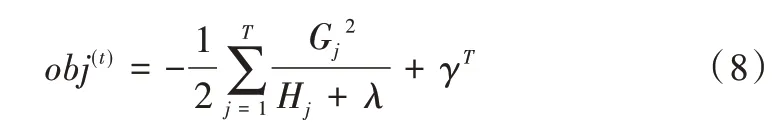
其中,T为叶子节点个数,λ和γ为比重系数,以防止过拟合产生。
模型训练过程中使用交叉验证与网格搜索方法对XG⁃Boost 参数进行调优,最终选取关键参数为:subsample=1,colsample_bytree=0.7,min_child_weight=1,max_depth=3,n_estimators=1000,alpha=0,选取过程如图4 所示。

Fig.4 Tuning process of key parameters in XGBoost图4 XGBoost 中关键参数调优过程
4 模型评估
根据真实类别和预测类别分为真正类(TP)、真负类(TN)、假正类(FP)和假负类(FN)。采用精准率(Preci⁃sion)、召回率(Recall)及F1 值3 个指标测试分类精度。

精准率是预测为正的样本数与所有实际为正的样本数之比,召回率是预测为正的样本数与该类实际样本数之比,F1 是综合精准率和召回率考虑的文本分类精确度。
5 实验结果与分析
将训练得到的XGBoost 模型最优参数:subsample=1,colsample_bytree=0.7,min_child_weight=1,max_depth=3,n_estimators=1 000,alpha=0 等加入 到面向XGBoost 的评价文本分类模型中,得到最优的评价文本分类模型。为了进一步验证模型的有效性,选用机器学习中经典的分类模型最近邻分类器(KNN)、贝叶斯分类器(NB)、支持向量机分类器(SVM)、lightGBM 分类器,与面向XGBoost 的评价文本分类模型进行比较。最终通过模型的评估指标精准率(Precision)、召回率(Recall)、F1 值进行对比,实验结果如表2 所示。
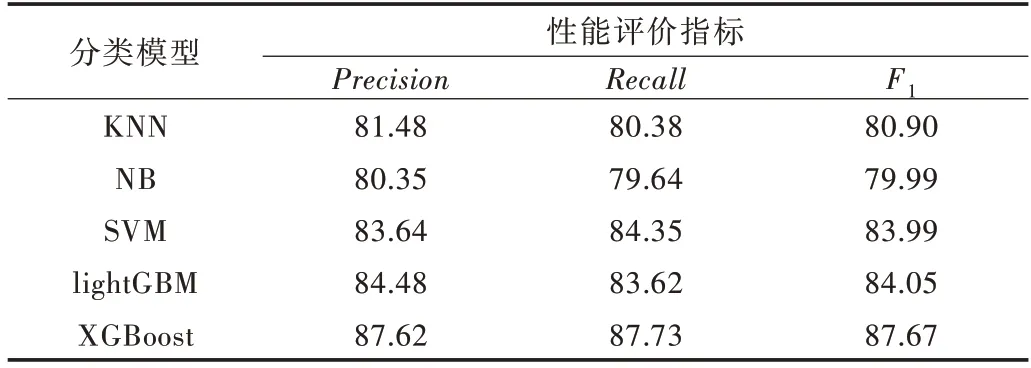
Table 2 Comparison of experimental results表2 实验结果对比 (%)
由于XGBoost 分类器能够对缺失的特征值进行自动学习处理,为避免陷入局部最优进行反向剪枝,可将成百上千个分类精准率低的模型组合成一个分类精准率较高的模型进行分类处理。从实验结果可以看出XGBoost 在精准率、召回率及F1 值3 个指标上均优于最近邻分类器(KNN)、贝叶斯分类器(NB)、支持向量机分类器(SVM)、lightGBM 分类器,在课程评价文本分类中表现出较好的分类效果,具有一定的使用价值。
6 结语
本文建立了一个11 641 条课程评价的数据集并进行人工标注和脱敏处理,使用欠采样方法处理数据中的样本不均衡问题,使用jieba 分词和停用词对文本进行词向量表示,使用PCA(主成分分析)进行特征降维,通过比对一些经典的机器学习分类学习器可以得到面向XGBoost 课程评价文本内容的分类。
本文针对高校课程评价内容进行智能分类,构建了面向XGBoost 的课程评价文本智能分类模型。该模型在评价文本的智能分类中表现出较好结果,对文本分类内容进行了一定的创新。但是本文还存在一些不足,如XGBoost 分类模型训练存在耗时问题,通常一个最优参数的训练要花费很多时间,降低了效率;在分类的精度上还有待提高。后续研究会对这些缺点进行深入研究,争取在提高文本分类精度的同时提高模型训练速度,在保证模型精准率的同时还要提高效率。
