特征重排序的加权深度森林
2021-09-28周博文
周博文,皋 军
(1.江苏科技大学 计算机学院,江苏 镇江 212032;2.盐城工学院 信息工程学院,江苏 盐城 224000)
0 引言
神经网络算法因其强大的性能被广泛应用,但也存在明显不足:一个大型的神经网络模型往往需要调试大量参数,调参工作耗时耗力,而且对训练模型使用的数据有一定数量要求。Zhou 等[1]提出的深度森林(Deep Forest,DF)模型能在一定程度上缓解上述问题。
但是,传统模型由于自身的限制而存在不足:①在多粒度扫描阶段,需转换的特征子集是按滑动窗口依次选取,显然第一维的特征只被扫描到一次,第二维的特征被扫描到两次……样本后端的特征同理,所以传统模型在此阶段未充分得到待转换的特征子集,在一定程度上忽略了样本两端特征。假如两端特征很重要,则无法充分利用[2];②级联阶段只将上一层级生成的类概率向量作为强化特征,忽视了之前生成的类概率向量,并且强化特征的差异性有限,最后求结果时又仅是简单的求和求平均,使得较低准确率的子分类器和较高准确率的子分类器具有相同权重,没有重视分类器的权重对后续产生的类概率影响,一定程度上降低了模型性能。
1 相关工作
深度森林及其改进模型因其强鲁棒性和方便性被应用在多个领域。文献[2]提出了深度堆叠森林,随机抽取特征子集进行特征转换,并且对二分类任务去除冗余特征,将其应用在检测软件缺陷任务中,但不能保证选中的特征子集中恰恰包含重要度大的特征;文献[3]提出双视角、深层扫描结构,效仿人眼关注一张图片时的情形,把图像中心点作为基准,根据图片周围区域与中心点之间的距离赋予不同的关注度,距离越小则权重越大,将其用于检测火焰;文献[4]指出传统深度森林模型在级联过程中,级联特征本身的有效性会不断退化,从而导致分类性能波动,作者把这种现象称为疏通连贯性。提出一种全级联方法,将每层的特征向量级联到原始特征中;文献[5]认为全级联方法加大了时间和空间开销,故在此基础上继续改进,对之前每层生成的类向量求和取平均值,并且引入Ad⁃aBoost 思想,不再关注每个文本,而是关注每个特征,改进后的算法应用在情感分类任务上;文献[6]将RPN 候选区域网络并入深度森林模型中实现船体目标检测任务;文献[7]改进了深度森林处理小样本生物数据能力,首先使用不同组的数据训练并集成模型,校正误差,给不同的特征赋予不同权重,而且自动确定决策树参数,算法有效实现了癌症分类;文献[8]提出隐语义模型结合深度森林构造隐式融合特征并增加级联子分类器的差异性,将其应用在人力资源推荐任务中;文献[9]为了解决深度森林在不平衡数据中的弊端,提出OSEEN-gcFore 算法,解决了原模型在多数类样本中的过度学习问题并应用在用户流失预测中;文献[10]通过特征融合代替细粒度扫描并在级联过程中自动改变样本权重,将改进模型应用在近红外光谱分类中;文献[11]提出加权的深度森林,对子分类器中的子树投票机制做出改进,给准确率高的子树赋予更大权重;文献[12]通过在多粒度扫描部分增加深度结构,将转换后的特征与原始特征级联,结合传统的目标检测方法执行小目标检测任务;文献[13-17]将传统深度森林算法应用在不同任务中。
由于深度森林的子分类器是随机森林和完全随机森林,且子分类器是根据最优划分特征属性对样本进行分类的,故可以先通过随机森林计算特征重要度。理论上原始特征向量中较重要的特征转换出的类概率作为新特征时也应具有重要的参考价值,所以从两个阶段改进:①针对忽视样本两端信息问题,提出一种特征重排序的扫描方法,重要特征尽量集中在中部,保证可以被多次利用,避免了文献[2]抽取特征过于随机的问题;级联阶段为了重视每层的类概率向量及特征差异性,选取之前生成的类概率之差作为增强向量,这样可以使每次级联的增强特征都与上层保持差异,一定程度上缓解了网络退化现象;②遵循“好而不同”的集成思想,引入线性逻辑回归分类器,增加分类器的差异性。最后的投票阶段加入softmax 层,根据每个分类器的准确率来赋予不同的权重。
2 深度森林
2.1 多粒度扫描森林
深度森林模型和神经网络算法类似,通过多级多层结构进行非线性映射来提高模型的表征学习能力和泛化能力。第一阶段,多粒度扫描森林可以将原始的样本特征进行特征转换,并重组成为更加有效的特征,进而提高第二阶段级联森林的分类能力。原始的样本经过不同大小窗口的扫描生成更加丰富多样的特征子集,特征子集作为输入进入分类器,产生对应的类概率向量,将其作为新的特征拼接成为级联森林的输入,过程如图1、图2 所示。
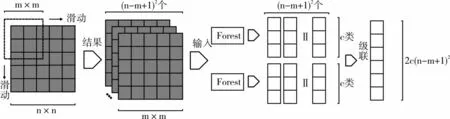
Fig.1 Multi-granularity scanning image data图1 多粒度扫描图像数据
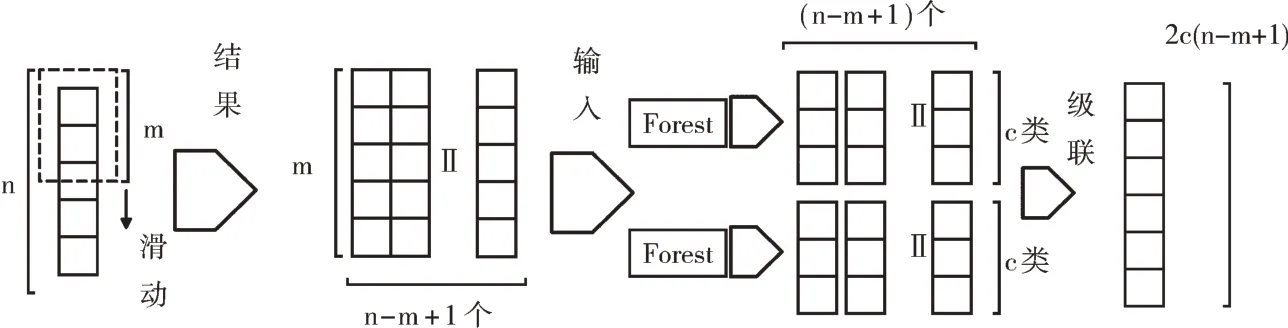
Fig.2 Multi-granularity scanning sequence data图2 多粒度扫描序列数据
假如图像数据大小为n×n,那么首先会按照m×m尺寸大小选择子窗口,从而生成(n-m+1)2个子窗口;接着把每个子窗口分别送入一个随机森林和一个完全随机森林。若任务是c分类的话,每个窗口就会生成一个c维的类概率向量,总共就会生成2(n-m+1)2个类向量。将这些向量拼接,成为一个1×2c(n-m+1)2的输入向量,相当于把n×n的图像数据转换成1×2c(n-m+1)2的序列数据。
序列数据的转换与图像数据类似。假若数据是1×n,先按照1×m的窗口滑动选取子特征集,产生n-m+1 个窗口,类似图像扫描会产生2(n-m+1)个类概率向量,拼接成为一个1×2c(n-m+1)的序列数据。
2.2 级联森林
级联阶段通过引入增强特征来提高表征学习能力,其输入是经过多粒度扫描阶段转换后的概率特征,若是低维数据,也可直接将原始特征作为输入。进入每层的训练层,通过交叉验证来训练分类器,以此避免过拟合现象。然后验证当前层的分类准确率。若层数达到了最大值或者准确率在预先设定的层数阈值内未提升,则停止进入下一层级。在对测试集数据进行验证时,会级联到训练层数最高的一层停止,并把最后一层每个分类器生成的类概率向量求和取平均,根据投票结果预测最终类别。假如多粒度扫描阶段转换后的特征是m维向量,且是c分类任务,那么首先经过随机森林和完全随机森林产生4c维的类概率向量,后续层的输入为原始特征与4c维特征级联,共m+4c维。级联阶段如图3 所示。
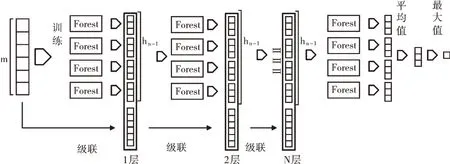
Fig.3 Cascade forest图3 级联森林
3 加权深度森林
不难发现,原始深度森林模型在多粒度扫描阶段一定程度上忽视了边缘数据特征,若样本是n维数据,选取子特征集的窗口大小为m,m>2,则首先被选中的特征子集是从第一维到第m维,接下来被选中的是从第二维到第m+1 维……显而易见,第一维的特征只被扫描了一次,第二维的特征被扫描了两次,样本后端的特征同样面临这个问题。只有从第m维到第n-m+1 维,每一维的特征才能够被充分选中并且进行特征转换。级联森林在特征向量更新时,每一层得到的新特征有限,仅考虑到了一层的类概率向量,且在首次级联后,后续的特征差异性较小,表征学习能力得不到有效提高,且在投票阶段忽略了子分类器的权重。RFDF 从两个阶段分别做出改进,首先通过特征重排序对边缘数据加以重视,然后考虑到多层的类概率向量并加强差异,增大子分类器的差异性,在投票阶段引入soft⁃max 层来根据准确率赋予子分类器不同的权重。
3.1 特征重排序森林
传统的深度森林模型在多粒度扫描阶段进行特征转换时,由于模型自身的局限性,不可避免地会忽略样本两端所携带的部分信息。在窗口扫描过程中,两端信息不能被充分提取,无法转换成类向量,从而使含有边缘特征的部分子集被忽略,从而造成转换不充分问题。若被忽略的边缘特征可转换出较有效的新特征,同时这个更加具有参考价值的新特征只出现一次,则明显会对生成的概率向量产生一定影响。同时,随着级联森林层数的增加,影响逐渐变大,最终导致分类结果出现偏差。若样本的重要特征存在于数据两端,那么理论上,由此转换生成的新特征也会有较大的重要度。文献[2]通过随机抽样来解决这一问题,使每个特征有同样的机会被选中,但是也不能保证随机抽取得到的特征子集包含较大重要度的特征,还会由于每次随机抽到的特征不同造成分类准确率的起伏不定。如果特征属性很多而抽取的特征有限,就会使模型不够稳定,随机性较大,因此提出特征重新排序的方法应对此问题。由于深度森林模型的基本组件是随机森林和完全随机森林,都是根据基尼指数来划分特征属性,而随机森林的feature_importances_函数也是根据基尼指数来计算数据样本每个特征的重要度,因而可使用此函数挑选出原始样本中较重要的特征并将其尽量放在样本中间,使重要特征被多次选中并转换出具有较大重要度的新特征,提高生成新特征的质量,构建出较有效的新特征属性。由于图像和语音等数据特征之间彼此存在着密切联系,若进行特征重排序必定会打破原有特征之间的关联,起到相反的作用,故此算法不太适用于特征之间有关系的数据。具体方法如图4 所示。

Fig.4 Reorder scan forest图4 重排序扫描森林
首先通过随机森林分类器自带的封装函数feature_im⁃portances 来判定数据样本中每个特征的重要程度,然后根据特征属性的重要度进行重新排序,将重要度较高的特征尽可能地放到中间,使其能被多个特征子集包含,这样就提高了特征子集转换出的对应准确率,换言之在一定程度上提高了转换出的特征质量,为后续的级联打下基础。
3.2 加权级联森林
传统的深度森林模型在进行特征更新时,仅仅选取在前一个层级生成的类概率向量作为增强特征,未考虑到之前每一个层级生成的类概率向量,没有给予这些类概率向量足够的重视,文献[5]称此问题为疏通连贯性。为了防止信息削弱就级联之前每一层的类概率向量,但是随之引发的问题也很明显:随着层次的深入增加了额外的空间开销,降低了模型的运行效率,而且在最终的投票阶段依然是默认每个子分类器具有相同的权重,对各分类器的结果简单求和取平均。为解决此问题,提出一种加权级联森林,首先在选择增强特征时,为了进一步加强级联新特征的差异性,防止网络性能退化,算法会选取之前层次类概率的差作为增强的特征和原始特征级联,并且加入不同于树形分类器的逻辑回归分类器,加大了子分类器之间的差异;其次在汇总最终结果时引入softmax 层对分类器赋予不同的权重。原始赋值见式(1):

改进后见式(2):

其中,Ci(i=1,2,……,n)为子分类器权重,yi(i=1,2,……,n)是子分类器产生的类概率,Ci计算公式见式(3):

其中Zi是当前分类器的准确度,要确保概率和相加为1。
算法1 加权级联森林

Xs(i-1,…,0)代表(i-1)层概率向量减去之前每层向量的差,得到的概率差作为增强特征。第0 层的输入是多粒度森林输出,第1 层的输入是第0 层的输出和原始向量的拼接。从第2 层起,拼接前会求出与之前层的概率差,作为新的特征向量与原始向量拼接,进行特征更新。当模型的层数达到预先设置的阈值或准确率无明显提高时则停止生成下一层。投票时自动调整权重,过程如图5 所示。
算法2 完整RFDF
训练阶段:

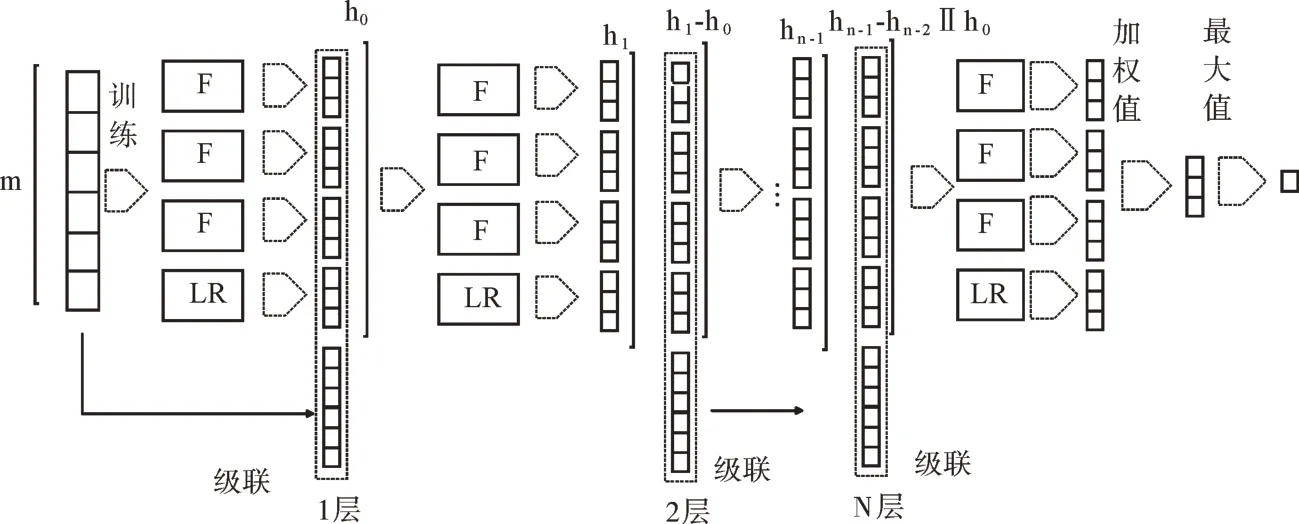
Fig.5 Weighted cascade forest图5 加权级联森林
4 实验
4.1 数据集和算法选择
高维数据集为二分类任务影评数据Imdb[18]数据集,人工数据集Madelon[19]数据集;低维数据集选择收入预测数据Adult[20],二分类;字母识别数据Letter[21],二十六分类;酵母菌种类预测数据Yeast[22],十分类,数据划分比例为0.8 和0.2。由于原数据集过大,故实验选择部分数据,如表1所示。
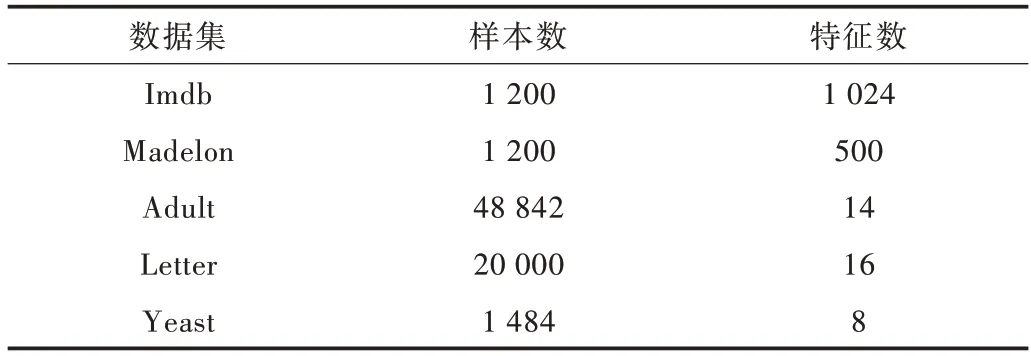
Table 1 Data sets used in the experiment表1 实验所用数据集
目前有多种深度森林改进算法,文献[2]和文献[3]对第一阶段改进,但后者仅对于处理图像数据时作出改进,适用性有限,故本文的对比实验选择文献[2]中提出的算法参与对比实验。高维数据集对比实验4 种算法,分别是DF 算法、文献[2]、文献[5]以及RFDF 算法。低维数据无须多粒度扫描。文献[2]和文献[4]的算法在级联阶段改进方法相同,仅在二分类任务时有所不同,故本实验在低维数据集上的算法共4 种,分别为DF 算法、文献[4]、文献[5]的算法以及RFDF。
4.2 实验参数
为了得到更好的排序效果,避免偶然性,在计算特征重要度时进行20 次计算,取交集特征,而且训练数据的样本量在可接受范围内,所以实验选取所有训练数据来计算特征属性的重要度。高维数据实验包括50 棵子树,随机森林随机选取的特征数为√d(d 为特征数量)。公平起见,实验采用与传统模型同样的窗口设置,数据集的窗口大小分别为d/4、d/8、d/16,且文献[2]模型每次抽取的窗口大小和抽取窗口次数都应与传统深度森林模型相同。多粒度扫描森林中,随机森林和完全随机森林个数为1,3 折交叉验证;低维数据级联森林中,每层包含2 个随机森林、2 个完全随机森林和一个逻辑回归分类器,随机森林包括100 棵子树,数据均采用5 折交叉验证。窗口设置如表2 所示。

Table 2 High-dimensional data set window size表2 高维数据集窗口大小
4.3 实验平台
计算机配置如下:软件环境为Windows 10 系统下的Python3.5,Intel(R)Pentium(R)Gold G5400,3.70GHz,8GB内存。
4.4 实验结果
4.4.1 高维数据结果
高维数据原始样本的特征重要度分布如图6、图7所示。
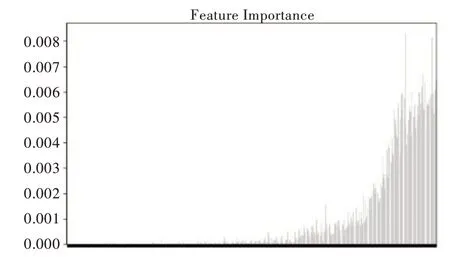
Fig.6 Imdb data feature importance(Ⅰ)图6 Imdb 数据特征重要度(一)
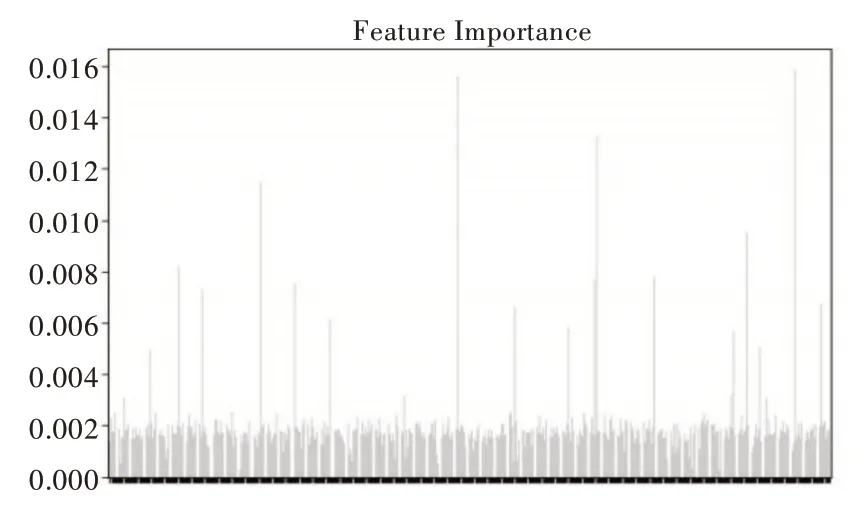
Fig.7 Madelon data feature importance(Ⅰ)图7 Madelon 数据特征重要度(一)
从图6、图7 中可直观地看出,Imdb 数据集较重要的特征大多数集中在后面部分,Madelon 数据集中特征重要度分布不均,两端同样有少许较重要特征。在经过特征重排序后样本的特征重要度分布如图8、图9 所示。
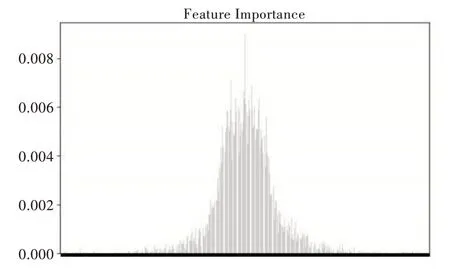
Fig.8 Imdb data feature importance(Ⅱ)图8 Imdb 数据特征重要度(二)
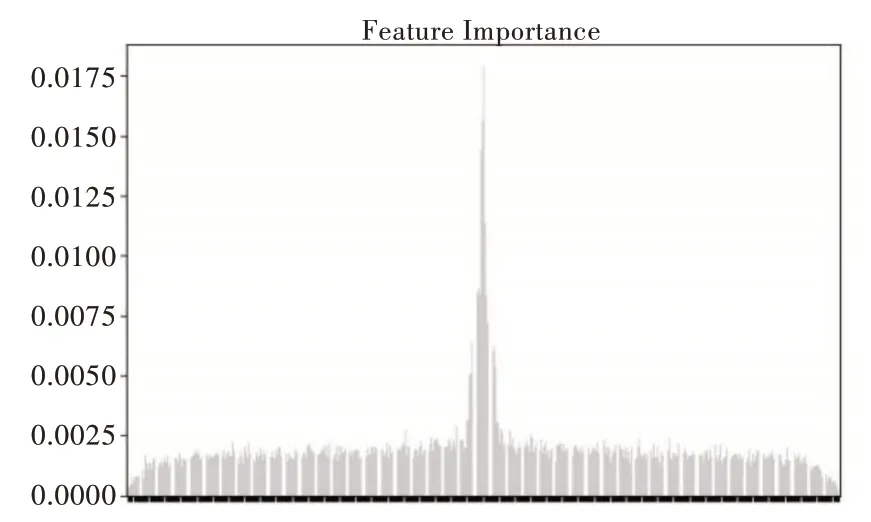
Fig.9 Madelon data feature importance(Ⅱ)图9 Madelon 数据特征重要度(二)
图8、图9 表明,经过排序之后,较重要的样本数据特征被尽可能地排在了中间部分。

Fig.10 Comparison of the accuracy of Imdb data图10 Imdb 数据准确率对比
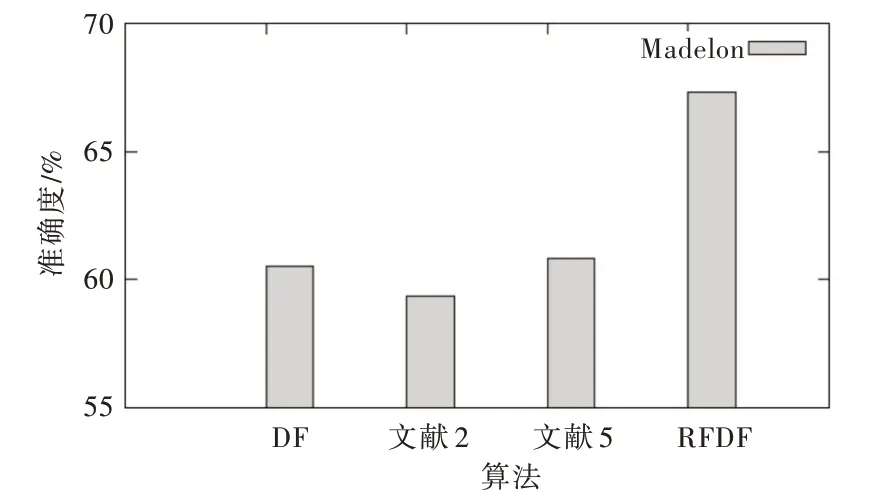
Fig.11 Comparison of the accuracy of Madelon data图11 Madelon 数据准确率对比
图10、图11 表明,Imdb 数据集在传统深度森林模型上的准确率约为49.67%,文献[2]模型上的准确率约为47.83%,文献[4]模型上的准确率约为49.92%,所提算法最高可达51.63%;Madelon 数据集在传统深度森林模型上的准确率约为60.50%,文献[2]模型上的准确率约为59.34%,文献[4]模型上的准确率约为60.83%;所提算法最高可达67.34%。文献[2]算法的准确率较低,究其原因是因为随机抽取模型特征,数据样本维数越多模型的随机性就会越大,对模型的影响也越大,进而导致模型的准确率起伏不定。RFDF 算法将较重要特征放在中间,增加了其在特征子集中出现的次数,一定程度上提高了新特征质量,文献[4]和传统算法基本持平的原因在于二者在扫描阶段时方法相同,故转换的特征向量也基本相同,所以模型性能提高有限。
4.4.2 低维数据结果
图12-图14 为低维数据结果。
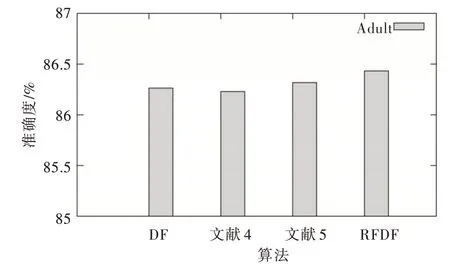
Fig.12 Accuracy of Adult data图12 Adult 数据的准确率

Fig.13 Accuracy of Letter data图13 Letter 数据的准确率

Fig.14 Accuracy of Letter data图14 Yeast 数据的准确率
图12-图14 表明,低维数据集在4 种算法上的准确度基本持平,约为86.26%、86.32%、86.23%、86.43%;Letter 数据集在4 种算法上的准确度约为97.31%,97.38%,97.45%,97.44%;Yeast 数据集在4 种算法上的准确度约为61.62%,61.58%,61.28%,61.61%,并且波动较大,主要原因是此数据集的特征维数较少,并且训练样本不够多;大量实验发现,传统DF 在原始特征和类概率首次拼接时,准确率会得到较明显提升。深入之后的层级总体呈现下降趋势,出现网络退化现象;而RFDF 由于加大了特征差异以及引入加权思想,故一定程度上缓解了此现象。准确率最高的层数如表3 所示。

Table 3 Number of layers with the highest accuracy表3 准确率最高的层数
实验结果显示,传统的深度森林模型平均第2 层最准确,文献[4]的模型平均为3 层,文献[5]算法平均为2.3 层,RFDF 平均为2.3 层。由此可知,对于低维数据,4 种改进模型性能都较高,文献[4]的算法收敛略慢。总体来说,低维数据自身的维数较少,特征不够有效,不能较准确地对相似数据进行有效分类。实验结果如表4、表5 所示。

Table 4 High-dimensional data experiment results表4 高维数据实验结果 (%)
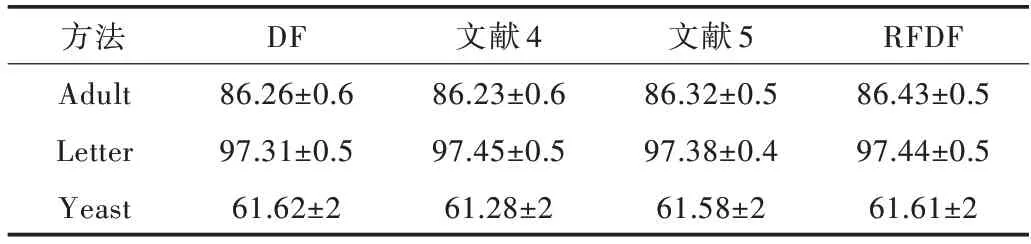
Table 5 Low-dimensional data experiment results表5 低维数据实验结果 (%)
5 结语
针对传统深度森林算法在两个阶段的不足分别进行改进,提出一种特征重排序的加权深度森林。首先将重要度较大的特征属性尽量排在中间部分,增加重要特征被选中的次数,以此转换出质量较高的新特征;级联时加入逻辑回归分类器,提高分类器的差异性,然后把概率类向量的差值作为增强特征,使新特征的差异性进一步增大,并在最终投票时引入softmax 层来根据子分类器的准确率自动调整权值。在数据集上的实验证明,此方法一定程度上能够提高深度森林模型性能。但是模型也存在不足,如在多粒度扫描森林之前会首先计算数据样本的特征重要度并且重新排序,这无疑增加了时空复杂度;对于低维数据模型性能提高有限。后续将在如何降低扫描阶段的时空复杂度以及如何更有效地提高模型处理低维数据的准确度上展开研究。
